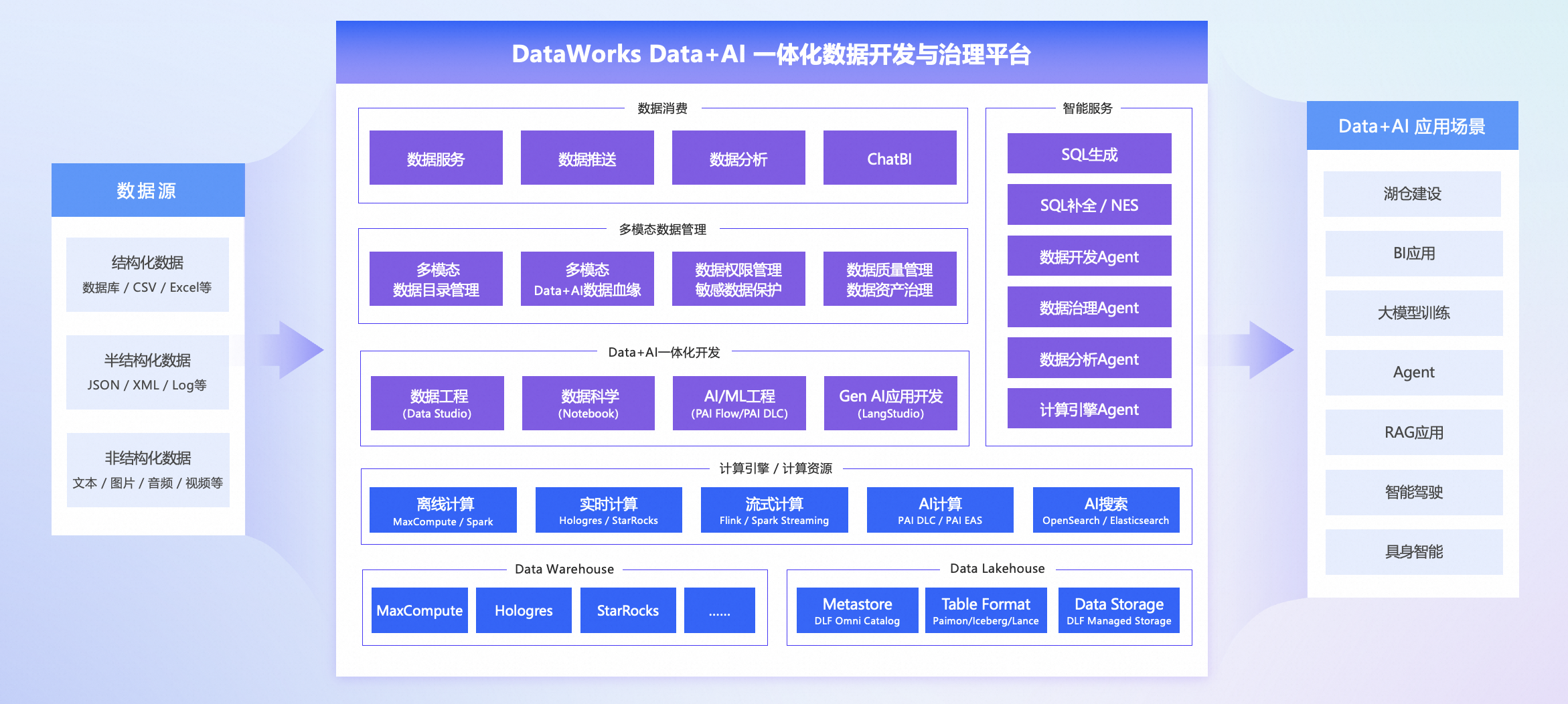
云栖实录 | DataWorks 发布下一代 Data+AI 一体化平台,开启企业智能数据新时代
DataWorks 从传统数据平台工具,进化为面向 AI 时代的 “智能数据中枢”,致力于帮助企业应对多模态数据爆发、AI 模型和 AI 应用迭代频繁、组织协同复杂等挑战,实现“Data+AI”的深度融合与高效协同。
本文根据 2025 云栖大会 DataWorks 产品年度发布实录整理而成
演讲人:田奇铣,阿里云智能集团计算平台事业部 DataWorks 产品负责人
DataWorks 下一代 Data+AI 数据开发与治理平台,全面迈向“数据驱动智能、智能反哺数据”的新阶段。作为中国大数据平台公有云市场份额和中国数据治理平台市场份额连续四年排名第一的领军产品,DataWorks 不仅见证了企业数字化转型过程,更在生成式 AI 浪潮中,构建起支撑企业智能化升级的核心数据基础设施。
此次发布标志着 DataWorks 从传统数据平台工具,进化为面向 AI 时代的 “智能数据中枢”,致力于帮助企业应对多模态数据爆发、AI 模型和 AI 应用迭代频繁、组织协同复杂等挑战,实现“Data+AI”的深度融合与高效协同。
为什么需要 Data+AI?企业智能化升级的关键路径
过去十五年,DataWorks 持续为阿里巴巴集团及数万家云上企业客户提供稳定可靠的数据底座,支撑了从互联网、电商、金融到制造、政务等广泛场景的数据平台建设。然而,在生成式 AI 快速落地的今天,我们正面临一个全新的技术挑战:
-
数据类型多元化:除结构化数据之外,文本、图像、音视频、传感器数据等非结构化与多模态数据激增;
-
AI工作流复杂化:数据标注、数据合成、大模型预训练、微调、推理、Agentic AI、Physical AI 构建等场景对数据供给提出更高要求;
-
不确定性加剧:AI 时代异构数据、技术路线、AI 应用路径、组织协同等均处于快速演变中,极易形成新的“烟囱式”架构,造就新的“数据孤岛”。
与此同时,越来越多客户明确提出:“要用 AI 提升数据建设效率”,甚至设定“通过 AI 将数仓开发效率提升50%”的目标。整个数据平台的Data+AI 演进,既是技术发展的必然趋势,也是企业走向智能化的关键路径。
因此,DataWorks 提出 “Data+AI一体化”战略——让数据平台不仅是 AI 的“燃料供应商”,更是其“发动机与调度中心”,真正实现数据与 AI 的双向赋能,打造企业在 AI 时代的数据中枢。
全面升级:三大核心能力构筑 Data+AI 数智平台基石
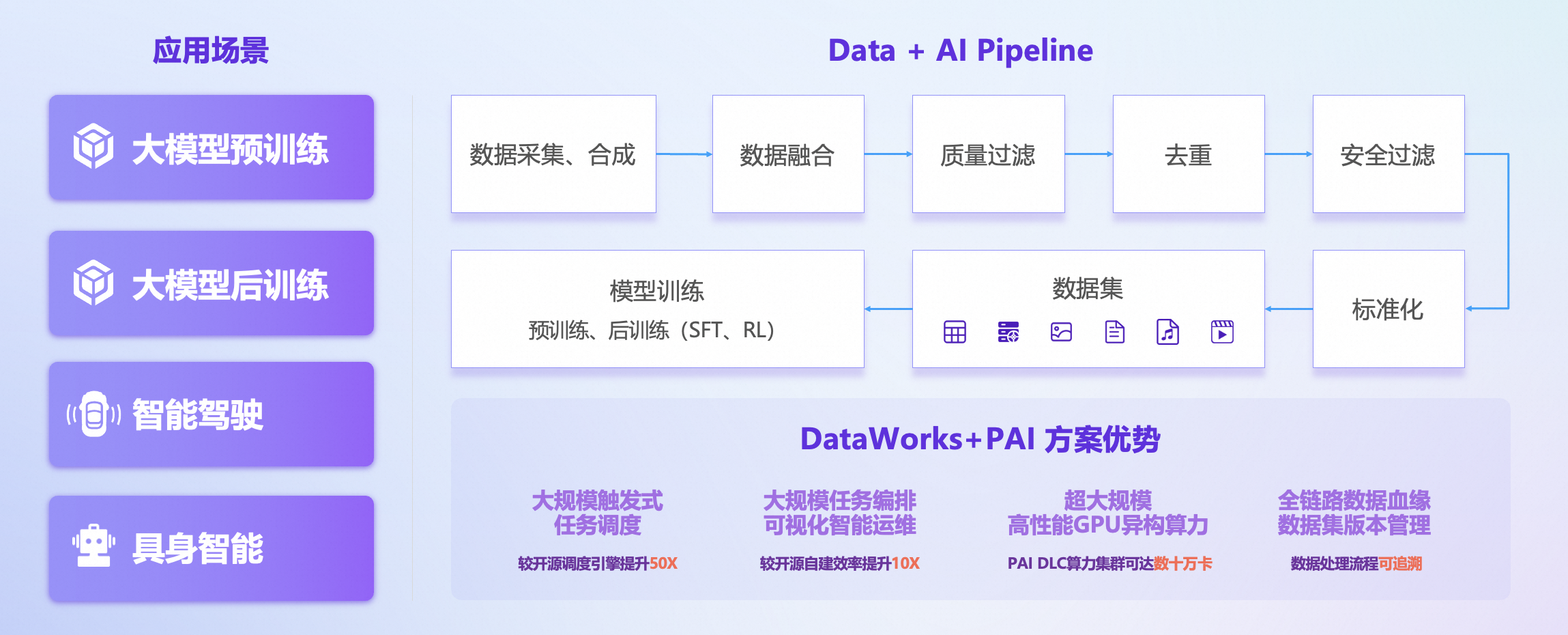
1、DataWorks Data+AI一体化开发平台:打通数据工程与 AI 工程的全链路 Pipeline
为解决数据科学、AI 工程与传统数据开发割裂的问题,DataWorks 实现了与阿里云人工智能平台 PAI 的深度集成,打造统一的 Data+AI 一体化开发环境,覆盖从数据准备、数据处理到模型训练的完整闭环。
-
Data Studio 云原生 WebIDE + 个人开发环境 基于容器化技术,为每位开发者分配专属计算资源,支持 CPU 和 GPU 资源按需使用,支持自定义容器镜像。开发者可在云端获得接近本地 VS Code 的开发体验,直接运行 Python 代码、调试代码、执行 Notebook 任务,彻底告别“写完提交、等待运行”的低效模式。
-
"增强版" Notebook 支持 SQL 与 Python 融合编程 DataWorks Notebook 在 Jupyter Notebook 基础上深度优化,实现 SQL 查询结果与 Python 数据处理流程无缝衔接。例如,用户可通过 Spark SQL 查询 PB 级数据,再用 Python 进行数据处理、数据可视化或 AI 模型训练,并一键提交至 MaxCompute 分布式 Python 计算框架 MaxFrame 或 PAI DLC 大规模 GPU 算力集群进行分布式运行。
-
AI工程化编排与调度能力 Data Studio 内置文档切分、Embedding 等 AI 数据处理算子,可视化编排为 PAI Flow,帮助用户轻松构建 RAG 应用的数据处理链路。同时,与 PAI LangStudio 深度打通,DataWorks 构建的知识库可直接用于生成式 AI 应用开发,实现“数据更新 → 知识库同步 → AI 应用调用”的自动化联动。更为重要的是,DataWorks Data Studio可以直接编排 PAI DLC 任务,借助 DataWorks 自研的大规模任务调度引擎,实现 Data+AI 任务一体化、高效、稳定的调度。
-
AI Function与大模型服务
在数据处理过程中经常需要借助 AI 来处理数据本身,如像文本打标、情感识别这些以前需要专业算法工程师才能实现的工作,现在只需简单的调用 AI Function 即可实现,并且可非常方便的集成到 ETL 工作流中。Data Studio 不仅可以直接使用各类计算引擎的 AI Function ,同时在数据集成和工作流中直接提供了AI Function,可进行 Embedding 和调用 LLM 进行数据处理。为了提供更高效的 AI Function 调用,DataWorks Serverless 资源组全新支持大模型服务一键部署,我们提供了包含 Qwen3、DeepSeek 系列模型及各类 Embedding 模型,提供了丰富的 GPU 规格,可通过 Serverless 资源组的 CU 进行按量抵扣,并且具备更低调用时延,更高调用性能。
2、智能调度引擎:从“周期性执行”到“事件驱动型调度”
传统大数据任务以 T+1 周期调度为主,而 AI 任务则更具动态性和响应性——当新数据到达、模型性能下降或业务指标波动时,系统应能自动触发数据更新或者重新训练。
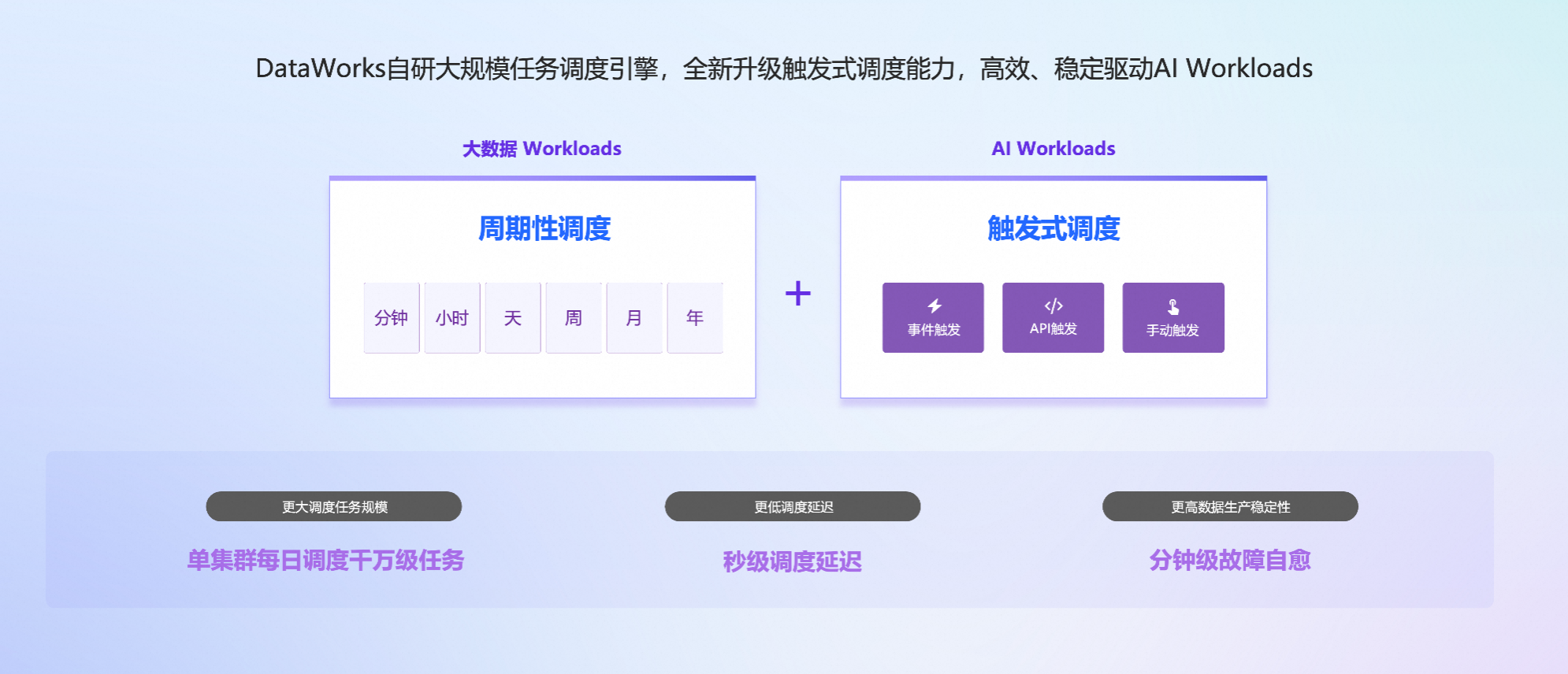
为此,DataWorks 对任务调度引擎进行了重大升级,全新升级了触发式调度的能力,用来高效稳定的驱动 AI 工作负载。
-
支持事件触发调度、API 触发调度、手动触发调度等多种触发式调用能力
-
单集群每日可驱动千万级任务实例,相比 Airflow 等开源方案,在同等资源下调度吞吐能力提升近50倍,可应对大规模AI数据生产任务;
-
调度延迟缩短至秒级,可应对实时性要求更高的 AI 数据生产场景;
-
故障恢复时间缩短至分钟级,保障高可用性;
这一能力已在多个客户场景中验证价值。例如,在自动驾驶领域,某车企利用该机制实现了“数据标注 → 数据合成 → 数据融合 → 模型训练”的全自动闭环,通过 DataWorks 替代原有的自建 Airflow 方案,实现单日处理 clips 突破百万级,显著加速模型迭代节奏。
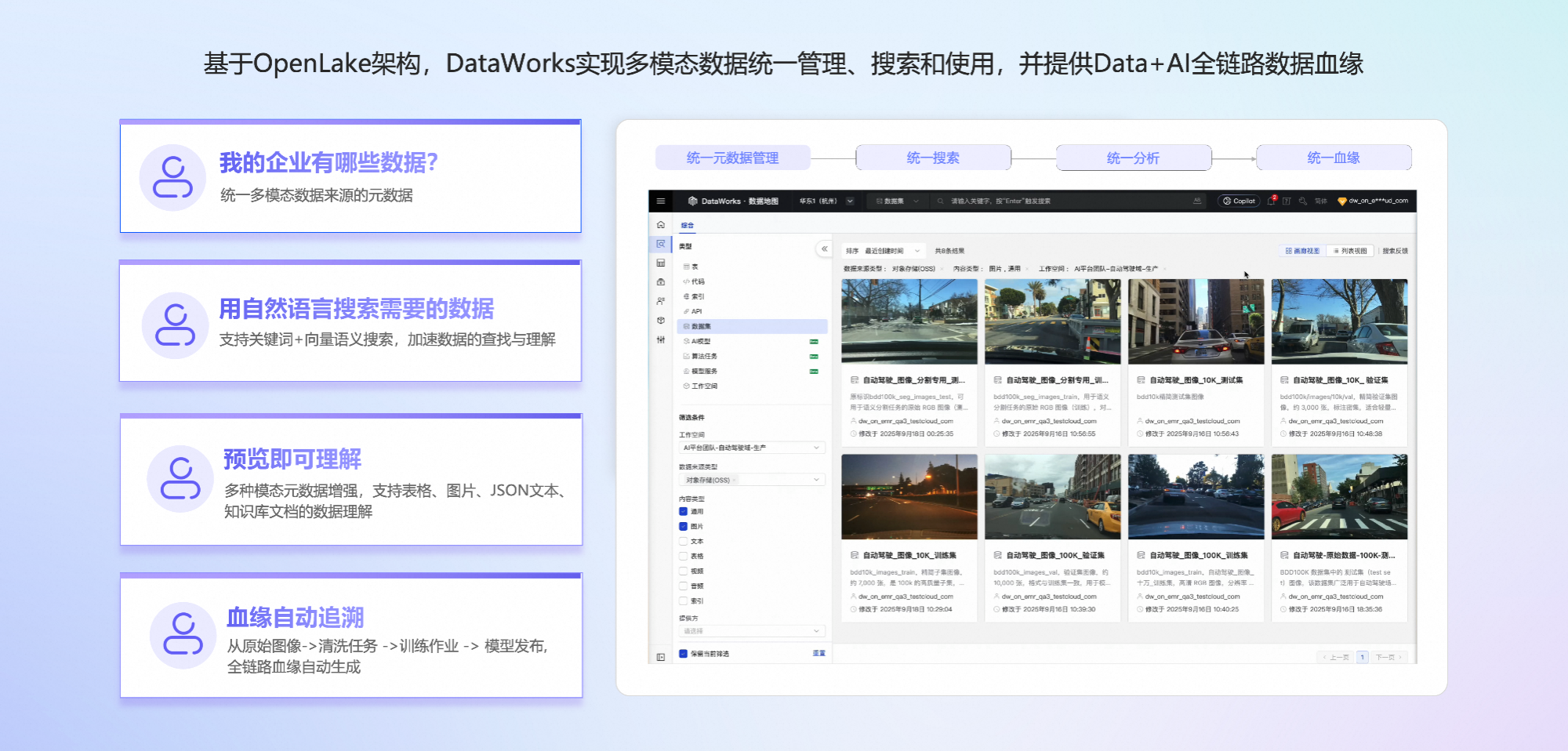
3、多模态数据管理:统一目录 + 语义检索 + 全链路血缘
面对日益增长的非结构化数据,DataWorks 推出全新 多模态数据管理体系,帮助企业实现“看得见、找得到、管得住”。
-
多模态统一数据目录(Data Catalog) 支持结构化表、AI 数据集、Lance Table 格式等多种资产类型,统一纳入 DataWorks 数据地图管理,实现跨源、跨域、跨团队的统一数据资产目录。
-
自然语言语义检索 可通过描述性自然语言(如“一辆黑色轿车正在斑马线前右转”)快速检索相关图片或视频片段,极大降低非结构化数据的使用门槛。
-
在线预览 支持表格、图像、文本、文档等多模态数据内容的在线浏览,帮助用户快速理解数据。
-
全链路多模态数据血缘 追踪数据从采集、清洗、标注、训练到推理的完整流转路径,支持版本化管理。例如,可追溯某一模型效果变化是否源于特定批次的训练数据修改,助力模型可解释性与合规审计。
智能进化:从辅助编码到自主执行,迈向 Agentic AI 时代
如果说 Copilot 是“智能助手”,那么 Agent 则是“自主智能体”,是一个问题解决者,能够以目标驱动的方式自主进行任务规划并自动执行。DataWorks 正式推出 DataWorks Agent——面向数据开发与数据治理的 AI 智能体。
1、NL2SQL 全球领先,交互体验全面升级
DataWorks Copilot的 NL2SQL 服务在被誉为"最接近真实企业场景"的权威基准测试 Spider 2.0 榜单中位列全球第一。
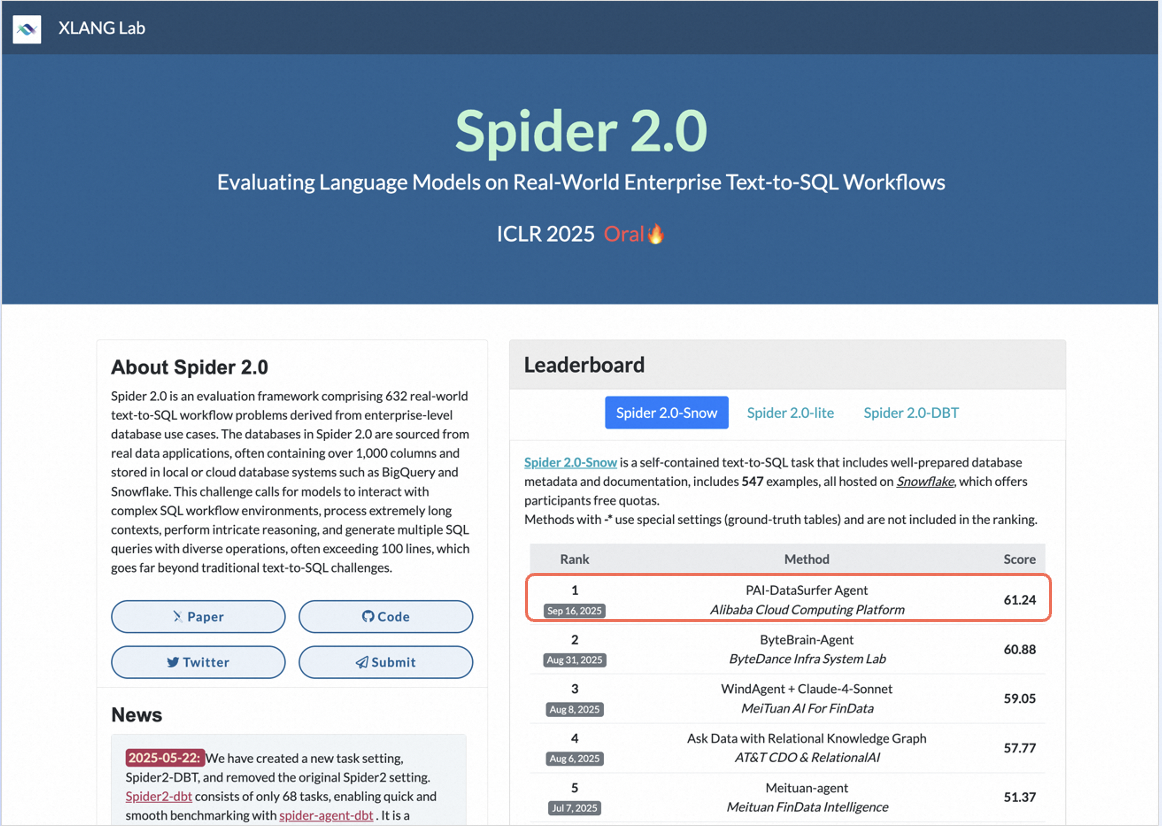
来源:Spider 2.0 官网,2025-10-13
在此基础上,智能 SQL IDE 进一步优化:
-
DataWorks Copilot 深度集成 SQL 编辑器,支持上下文感知(如当前打开的表结构、节点上下游关系、知识库内容);
-
SQL 编辑器全新推出 NES(Next Edit Suggestion)能力,当你在编辑器中编写和修改SQL代码, Copilot 会智能推荐下一步需要修改的代码位置并给出修改建议,显著提升 SQL Coding 效率和体验。
2、DataWorks Agent 加速“自动化”数据开发
DataWorks Agen t能够理解需求、自主规划、自动执行,轻松串联多种工具,解决传统 GUI 工具来回跳转操作的低效问题,并且支持接入第三方 MCP Server ,轻松扩展 Agent 的能力边界。
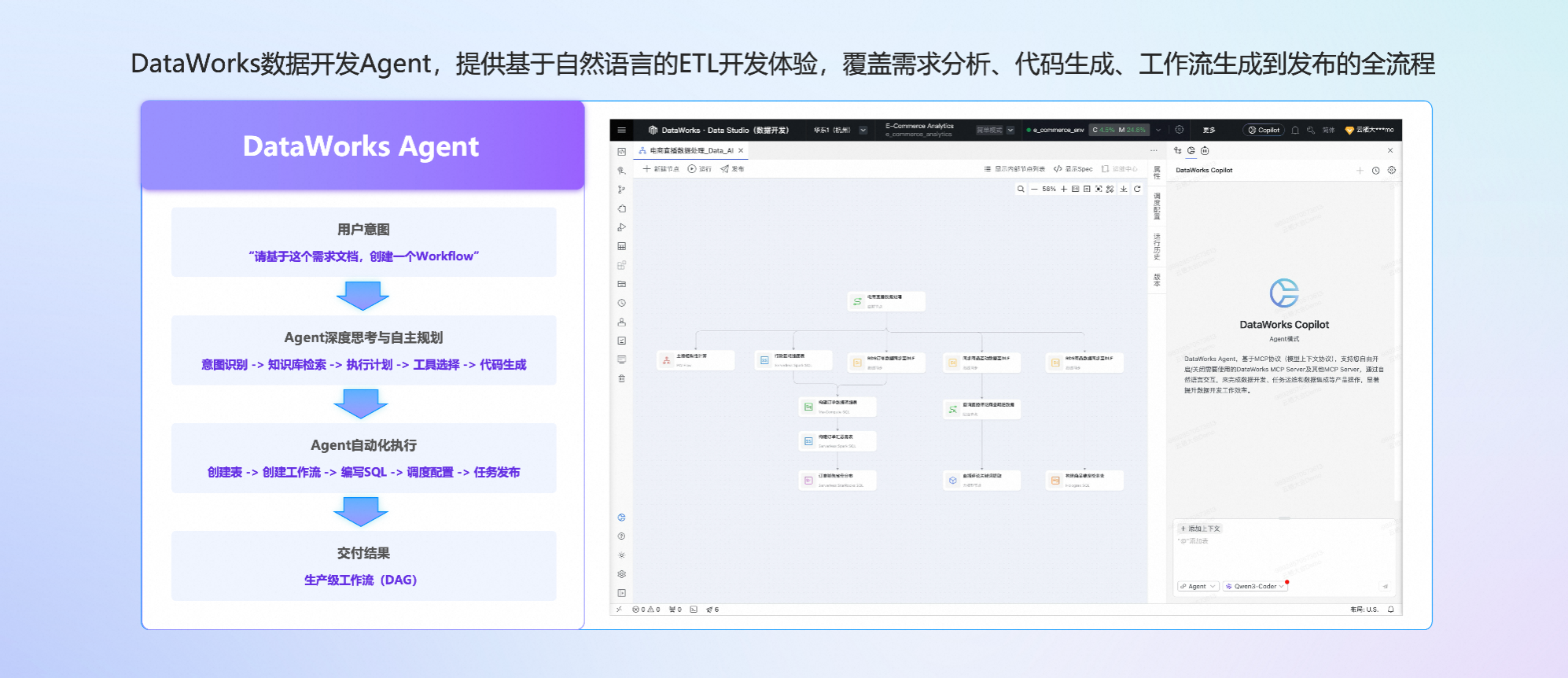
DataWorks 数据开发 Agent,可实现输入 ETL 需求文档,输出 ETL 工作流。用户只需输入自然语言需求或者需求描述文档,DataWorks Agent 可以理解用户意图,深度思考和自主制定规划,然后自动化执行规划,最终生成所需 ETL 工作流及任务代码。让 ETL 工程师从繁复的 SQL 开发和工具操作中解放出来,有更多时间来思考业务本身。
3、DataWorks Agent 驱动“自主式”数据治理
在大模型广泛落地之前,DataWorks 数据治理提出了治理健康分、主动式数据治理等方法论和产品能力,并得到了广泛认同,帮助上千家企业实现主动式数据治理。今天,DataWorks 借助 Agentic AI 技术,将驱动企业数据治理从“主动式”迈向“自主式”数据治理的新阶段。
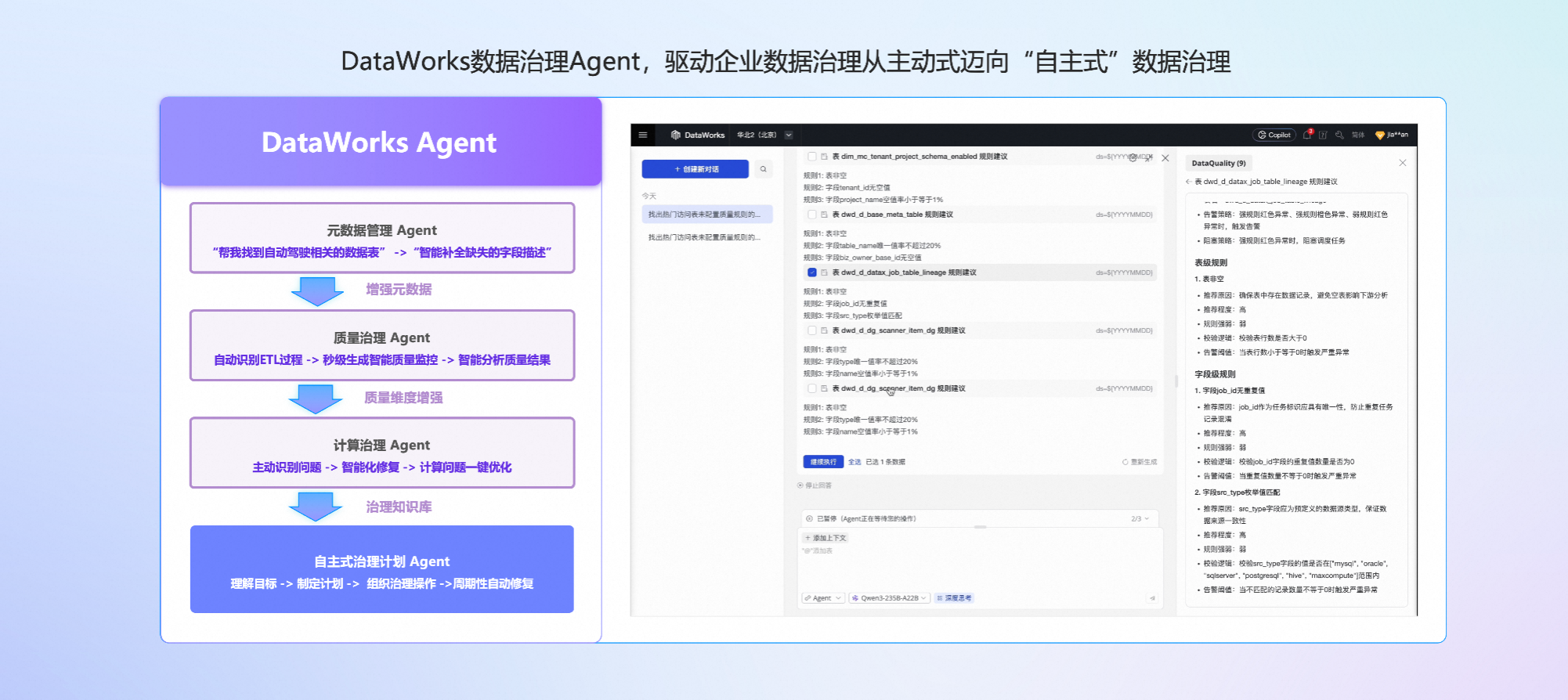
DataWorks 数据治理Agent将 AI 深度融入数据治理全流程:
-
AI 搜索与元数据增强:通过对话查找数据资产,AI自动补全字段说明、业务口径等缺失信息;
-
数据质量 Agent:基于 SQL 逻辑、历史运行日志与元数据特征,自动批量生成质量规则,并对质量检测异常结果进行根因分析;
-
治理检查项实时诊断与优化:将数据资产治理的检查项、治理项深度集成到 SQL IDE 中的代码检查功能中,在你编写 SQL 代码过程中,实时检测代码中的语义错误、代码规范、SQL 性能等问题,实时诊断分析和给出修复建议。
-
数据治理计划 Agent:设定目标(如“提升高频访问表的质量健康分至90以上”),系统自动识别治理对象、制定周期性计划并执行,实现“目标 → 分析 → 执行 → 验证”的闭环治理。
4、DataWorks ChatBI:AI 原生,人人皆可洞察数据价值
为了让数据分析能力惠及每一位业务人员,DataWorks 推出 ChatBI——一款轻量级、AI 原生的数据洞察产品。
-
个人用户可上传本地 Excel、CSV 文件,通过自然语言提问(如“今年销售额下降有哪些可能的原因”),即时获得数据洞察报告。
-
企业管理员可预先连接数据仓库、设置权限策略、注入企业知识库(如指标定义、组织架构),授权给销售、运营等角色后,他们即可“开箱即用”,无需依赖数据团队取数问数。
DataWorks ChatBI 的核心理念是让每个人都能用最朴素的方式——说话,从数据中获取洞见。
展望未来:AI时代的数据中枢
15年来,DataWorks 始终坚持“让数据产生价值”的初心,数万家阿里云客户信赖和选择 DataWorks 来构建企业数据平台。今天,我们正站在一个新的起点——让数据平台成为 AI 时代的数据中枢,让企业加速智能化升级,助力企业在市场中赢得竞争优势。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)