零成本打造本地多引擎大模型与向量服务:Xinference 全栈部署 + 性能调优实战
本文介绍了Xinference框架的部署与应用,涵盖推理引擎选择、安装配置、模型管理与调用等关键环节。Xinference支持多引擎统一(vLLM/SGLang/llama.cpp等),提供OpenAI兼容API,便于现有项目迁移。文章详细展示了Embedding模型的管理流程、REST API调用示例,以及LLM模型(如qwen2.5-instruct)的启动与交互方法,同时介绍了集群部署模式和
上一篇:RAG 增强与向量基础篇:继续搭建“模型 + 向量 + 会话 + 工具”协同底座
适合想在本地/内网快速统一「LLM + Embedding + OpenAI 兼容接口」的开发者。本文集合安装、引擎选择、Embedding 调用、模型生命周期、集群与 Docker、性能优化及与现有 Java / LangChain4j / Spring AI 项目整合的实践建议。配合真实截图一步到位。
1. 为什么选 Xinference?
- 多后端推理引擎统一(vLLM / SGLang / llama.cpp / Transformers / MLX)
- 支持 LLM / Embedding / 各类量化 / 多源下载(HuggingFace、ModelScope 等)
- 提供 OpenAI 兼容 REST API,几乎零改造即可接入现有 SDK
- 模型生命周期管理(注册 / 启动 / 查询 / 终止)命令简洁
- 可扩展为 Supervisor + Worker 的分布式集群形态
- 与向量/RAG体系易整合:Embedding 输出维度、模型管理、路由统一
2. 推理引擎怎么选(速览)
| 场景 | 推荐引擎 | 典型优势 | 触发条件 / 注意点 |
|---|---|---|---|
| 高并发上下文窗口 & 长文本 | vLLM | KV Cache 高效 / 吞吐强 | Linux + CUDA,模型格式 pytorch 且量化满足条件 |
| 连续多调用复用 KV | SGLang | RadixAttention 复用提升性能 | 适合多轮长对话 / 代码生成 |
| 低资源 / 量化多 | llama.cpp (xllamacpp) | GGUF 量化灵活 | CPU / 较少显存 / 轻量部署 |
| 生态兼容广 | Transformers | 模型覆盖面最大 | 性能次于专用引擎,适合实验 |
| Apple Silicon | MLX | 原生优化 | 需支持的模型格式;不支持则退回 llama.cpp |
经验:能用 vLLM 先用 vLLM;低资源或 macOS M 系列尝试 MLX / llama.cpp;需要快速支持新模型时用 Transformers。
3. 安装矩阵(按需挑选)
最全依赖(不含 sglang 变更说明):
pip install "xinference[all]"
常用拆分:
# vLLM 高性能推理
pip install "xinference[vllm]"
# Transformers 通用覆盖
pip install "xinference[transformers]"
# llama.cpp / GGUF
pip install "xinference[llama_cpp]"
# SGLang 引擎
pip install "xinference[sglang]"
# MLX (Apple Silicon)
pip install "xinference[mlx]"
# 仅客户端(与远端服务版本匹配)
pip install xinference-client==${SERVER_VERSION}
可选 FlashInfer(部分模型滑动窗口优化):
pip install flashinfer -i https://flashinfer.ai/whl/cu124/torch2.4
4. 快速拉起本地服务
xinference-local --host 0.0.0.0 --port 9997
# 指定工作目录
XINFERENCE_HOME=/data/xinference xinference-local --host 0.0.0.0 --port 9997
访问:
- UI: http://127.0.0.1:9997/ui
- API Docs: http://127.0.0.1:9997/docs
模型源切换(示例 ModelScope):
XINFERENCE_MODEL_SRC=modelscope xinference-local --host 0.0.0.0 --port 9997
5. Embedding 模型管理与调用(图解)
5.1 模型列表(可筛选)
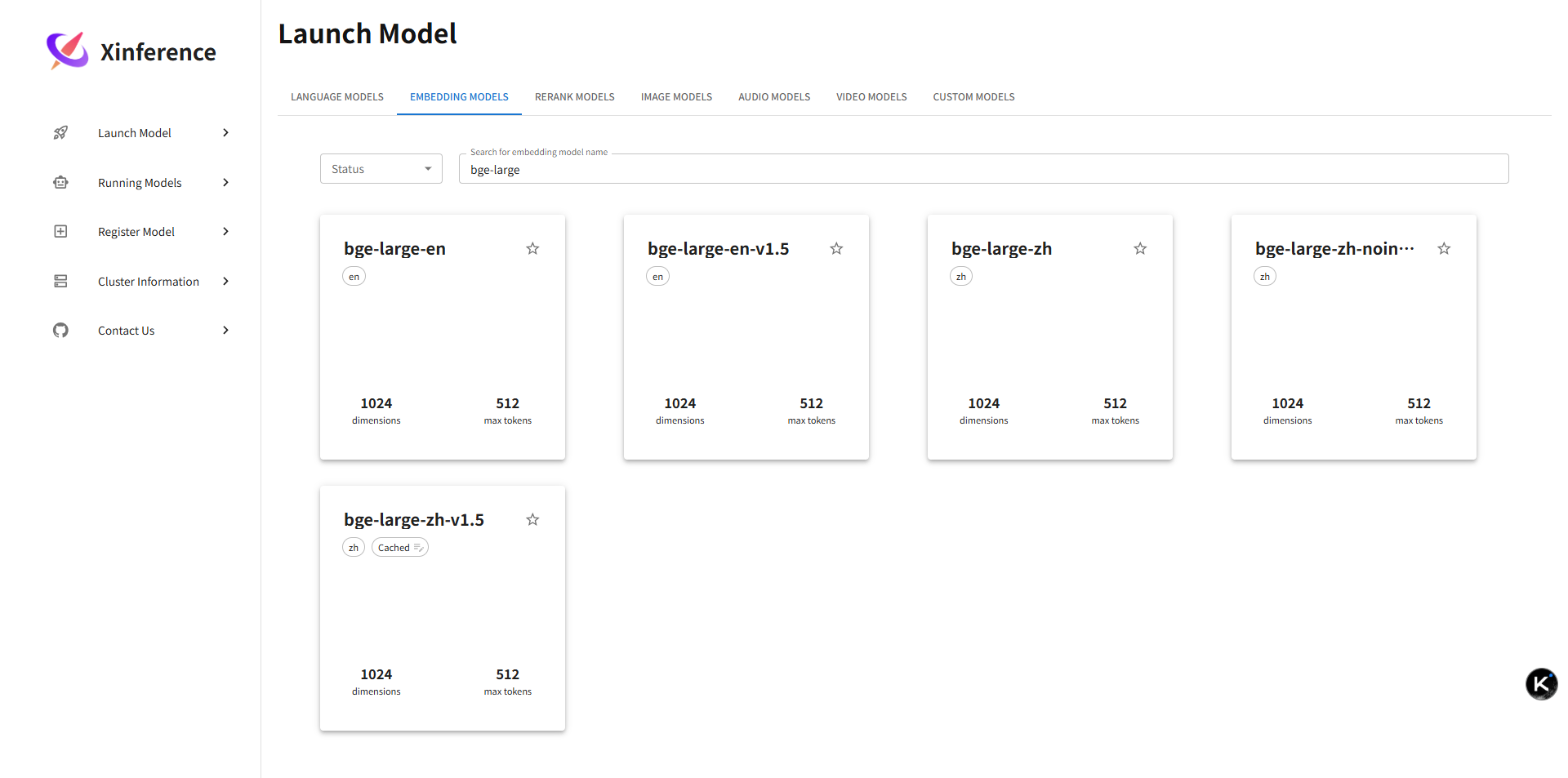
说明:左侧是模型类型筛选(LLM / Embedding 等),顶部可搜索模型名称或标签;每行展示模型名、源(HF / ModelScope)、规格标识、是否已下载。下载后才可运行;未下载的会显示进度条。夜间可批量预下载常用模型以减少白天首次等待。
5.2 模型详情与运行(CPU / GPU / 源切换 + 小火箭启动)
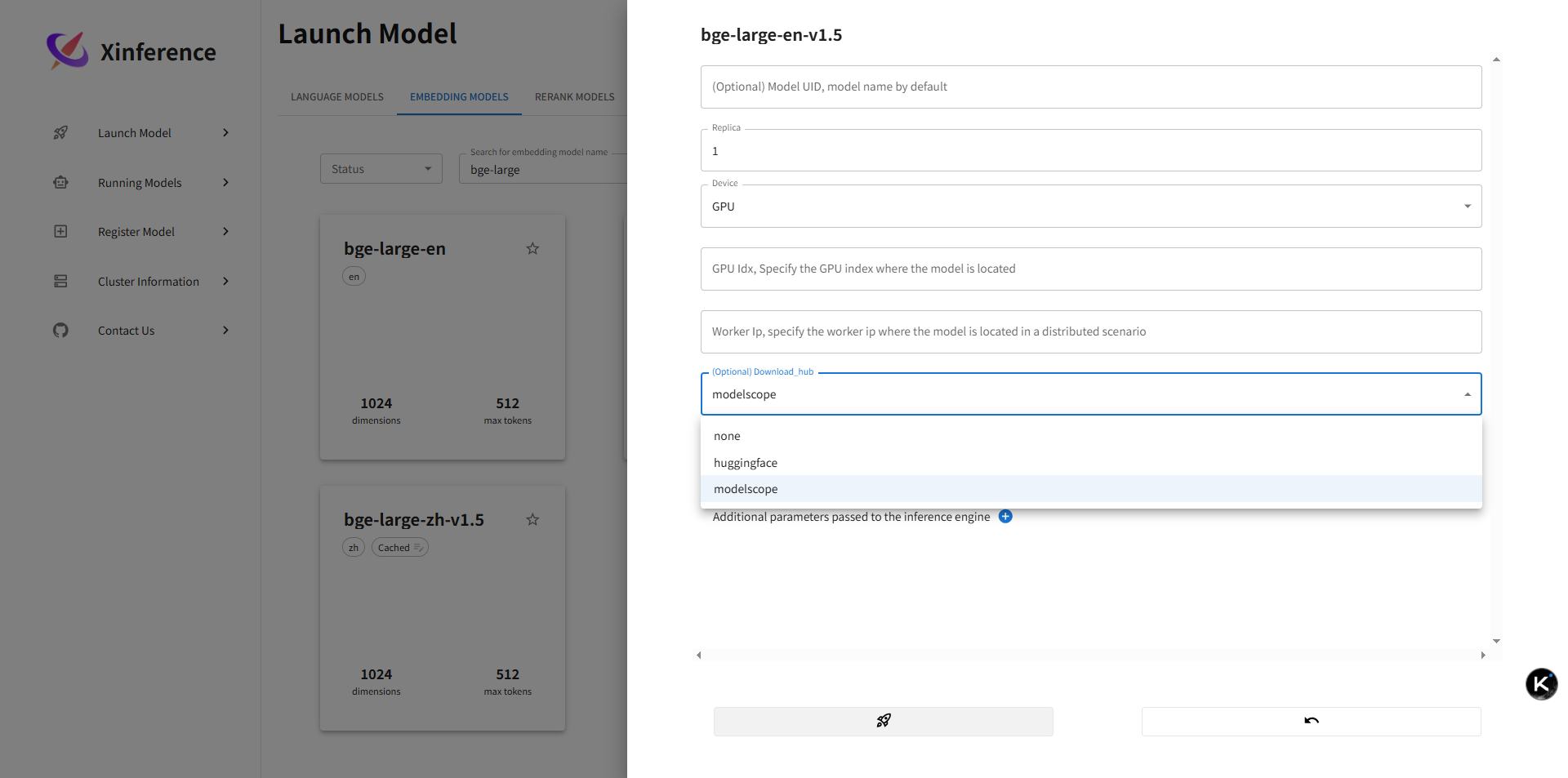
说明:详情页包含:
- 资源选择:CPU / GPU 切换;GPU 下可自动识别显存并判断是否可加载。
- 下载源:支持多源切换(HuggingFace / ModelScope 等),用于加速或满足内网镜像需求。
- 规格/量化:
-s参数对应的规格标签(如 small / base / large 或量化位宽)。 - 小火箭按钮:一键启动;启动后后台会拉起对应引擎进程(如 vLLM / llama.cpp)。
- 参数区:可自定义并发、上下文长度、GPU 利用率等(不同引擎参数略有差异)。
5.3 已运行实例监控(UID / 资源占用)
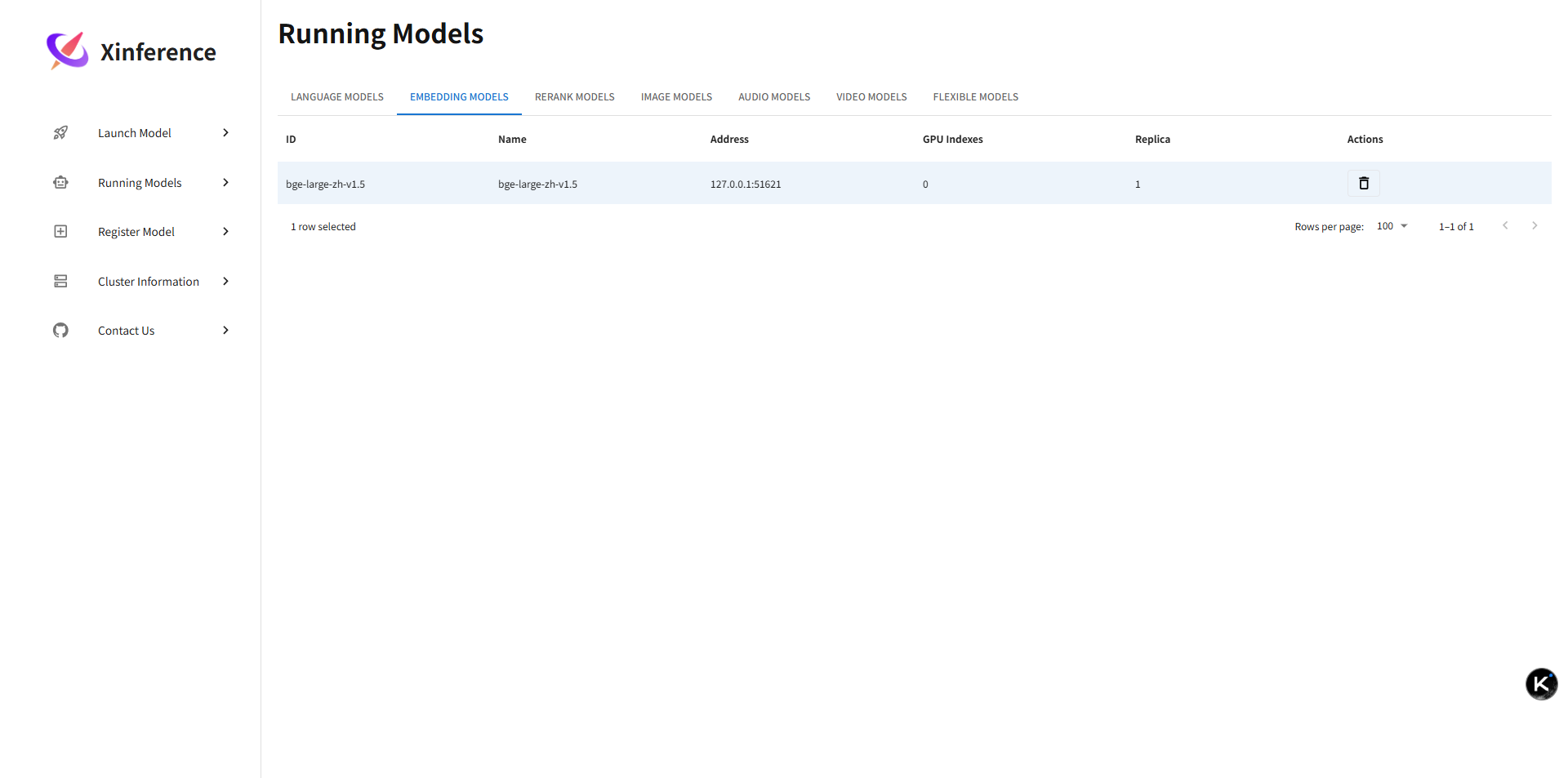
说明:运行列表展示当前激活的模型实例:
- UID:实例唯一标识,用于终止或调用指定实例。
- 引擎 / 格式:快速判断性能特性(例如 vLLM vs llama.cpp)。
- 资源:显存或内存占用估算,帮助做容量规划。
- 启动时间:可用于排查冷启动耗时和定期重载策略。
- 操作:终止 / 参数查看;建议结合审计记录调用次数与 token 使用量。
5.4 REST API(OpenAI 风格 Embeddings 兼容)
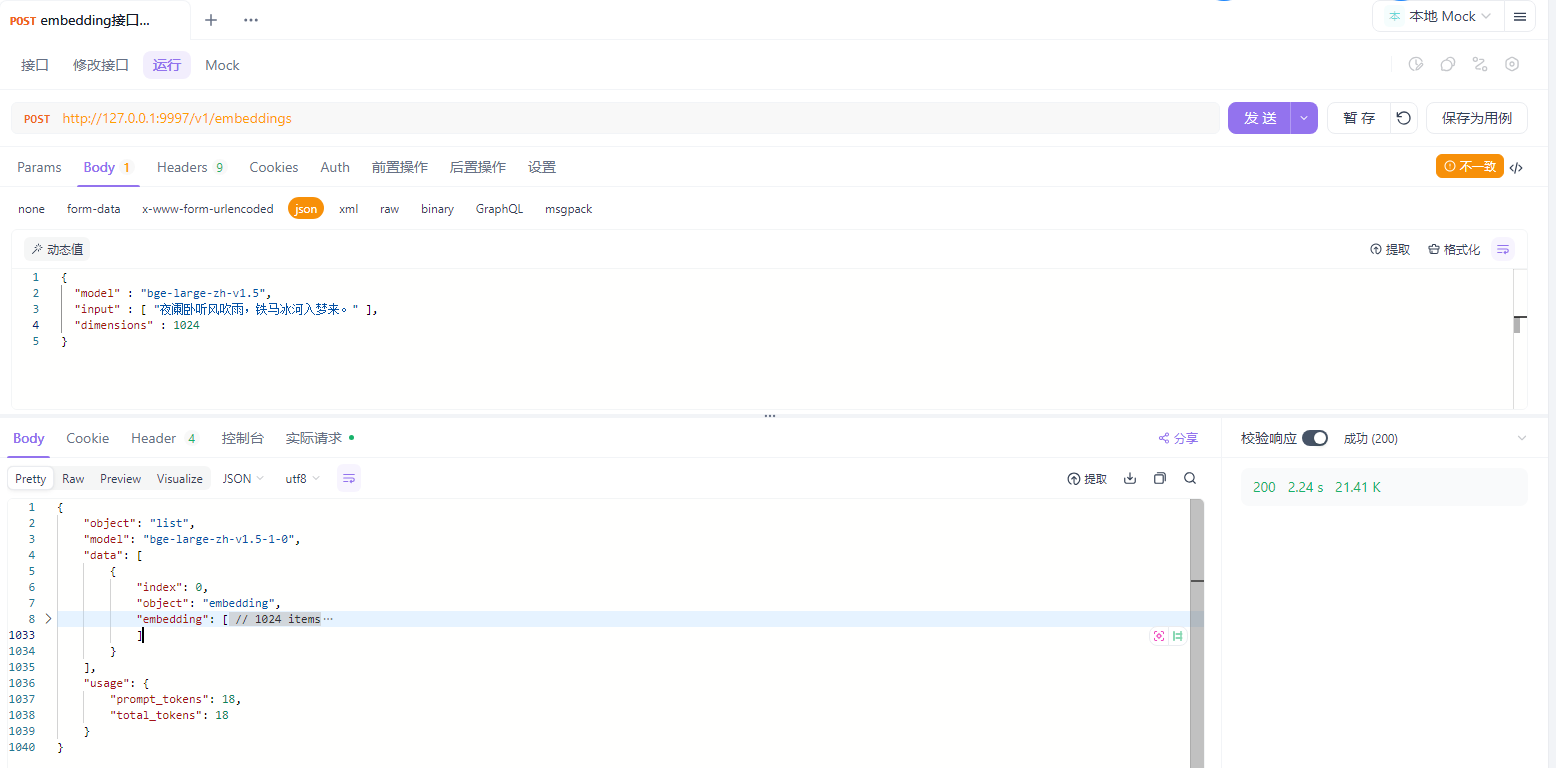
说明:界面展示了与 OpenAI Embeddings 几乎一致的请求/响应结构:
- Endpoint:
POST /v1/embeddings - Body:
model(模型名称或 UID)+input(字符串或字符串数组)。 - 响应:
data[0].embedding为浮点数组;可先打印长度写入你的向量库配置,避免维度不匹配。 - 性能建议:批量输入时控制单次文本总 tokens,过长可在发送前做分段切分策略(结合你 RAG 里的分块策略)。
调用示例(OpenAI 兼容):
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:9997/v1", api_key="not-used")
resp = client.embeddings.create(model="bge-small", input=["你好,向量检索", "Xinference 多引擎"])
print(resp.data[0].embedding[:8])
将 embedding 输出与向量库(Qdrant / Milvus / Elasticsearch)写入即可接入你现有的 RAG 管线。
6. 运行一个 LLM(qwen2.5-instruct 示例)
首运行需下载权重(缓存后复用):
xinference launch --model-engine vllm -n qwen2.5-instruct -s 0_5 -f pytorch --gpu_memory_utilization 0.9
参数说明:
--model-engine: 指定推理后端(vllm / sglang / transformers …)-s 0_5: 精度或量化/规格标签(源文档定义)-f pytorch: 模型格式--gpu_memory_utilization: vLLM 内存比率
交互(Chat Completion):
curl -X POST http://127.0.0.1:9997/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen2.5-instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain vector databases in 1 sentence."}
]
}'
7. OpenAI 兼容 API 快速迁移
可直接将现有 OpenAI SDK 的 base_url 指向 Xinference:
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:9997/v1", api_key="unused")
client.chat.completions.create(
model="qwen2.5-instruct",
messages=[{"role":"user","content":"给我一个使用向量检索的应用架构"}]
)
支持:Chat / Completions / Embeddings;Anthropic 兼容端点也可通过基准 URL 切换。
8. 模型生命周期管理(CLI)
列出可注册模型:
xinference registrations -t LLM
查看已运行模型:
xinference list
终止释放资源:
xinference terminate --model-uid qwen2.5-instruct
引擎参数组合查询:
xinference engine -e http://127.0.0.1:9997 --model-name qwen-chat --model-engine vllm
9. 集群模式(Supervisor + Worker)
Supervisor:
xinference-supervisor -H 10.10.0.11
Worker:
xinference-worker -e http://10.10.0.11:9997 -H 10.10.0.12
Worker 节点按需扩展显存池;命令行交互需使用
-e指向 Supervisor 地址。
10. Docker 快速启动
GPU:
docker run --gpus all -p 9997:9997 \
-e XINFERENCE_MODEL_SRC=modelscope \
xprobe/xinference:latest xinference-local -H 0.0.0.0 --log-level debug
CPU:
docker run -p 9997:9997 xprobe/xinference:latest-cpu \
xinference-local -H 0.0.0.0 --log-level debug
建议挂载宿主缓存目录,避免重复下载:
-v ~/.xinference:/root/.xinference
11. 性能与成本优化建议
| 目标 | 策略 | 说明 |
|---|---|---|
| 吞吐 | vLLM + 调整 gpu_memory_utilization |
利用 KV Cache 与并发批处理 |
| 首 token 延迟 | SGLang / 量化(Int4 GGUF) | 减少加载与计算开销 |
| 内存占用 | llama.cpp + GGUF | 小型 CPU 场景稳定运行 |
| 长上下文 | 选择支持长上下文的模型(qwen2.5-instruct-1m) | 配合滑动窗口注意 FlashInfer 支持 |
| 多模型混用 | 拆分 Worker 显存池 | 避免单进程挤占资源 |
| Embedding 批量 | 聚合调用 + 控制 batch size | 结合向量库写入事务批量提交 |
12. 与 RAG / LangChain4j / Spring AI 集成思路
- Embedding:使用 OpenAI 兼容 Embeddings API → 统一适配现有 LangChain4j Embedding 接口(自定义 provider 封装 base_url)。
- 向量库:Embedding 结果直接写 Qdrant / Elasticsearch;Xinference 不替代向量库,只负责生成向量。
- 多模型路由:根据会话配置选择不同
model字段(与现有 sessionStore / ragServiceId 设计兼容)。 - 降级策略:vLLM 不可用 → 自动切换 transformers;统一重试封装。
- 监控:对每次调用记录耗时、tokens、engine、model-uid,进入日志与审计链路。
13. 常见问题速查
| 问题 | 可能原因 | 解决 |
|---|---|---|
| 首次加载速度慢 | 权重下载 + 解析 | 保持网络稳定;预热启动常用模型 |
| OOM / out of memory | 显存不足 / 参数不合适 | 降低 gpu_memory_utilization 或量化模型 |
| OpenAI SDK 报 404 | base_url / 路径错误 | 使用 http://host:port/v1 前缀;检查接口拼写 |
| Embedding 维度不符 | 模型与向量库预期不同 | 先输出一次向量长度写入配置表再建集合 |
| Worker 无法注册 | 端口或防火墙限制 | 确认 -e 指向可达 Supervisor;开放 9997 端口 |
14. 进阶路线
- 加入 Prometheus 指标(请求耗时 / 并发 / 内存占用)
- 扩展调度:基于标签选择引擎(如低延迟 vs 高吞吐)
- 加入模型版本灰度(A/B 测试)
- 热升级:新 Worker 加载模型后切换流量
- 与企业级网关 / 鉴权(JWT / 签名)结合
- 多租户隔离:基于模型 UID 前缀或独立 Worker 组
15. 参考命令速记
# 列出运行模型
xinference list
# 启动 LLM (vLLM)
xinference launch --model-engine vllm -n qwen2.5-instruct -s 0_5 -f pytorch
# 启动 Embedding 模型(示例)
xinference launch -n bge-small -f pytorch
# 终止
xinference terminate --model-uid bge-small
# 引擎参数查询
xinference engine -e http://127.0.0.1:9997 --model-name qwen-chat
16. 总结
借助 Xinference,可以在单机到集群不同拓扑下统一管理多种 LLM 与 Embedding 模型,并复用 OpenAI 兼容客户端降低接入成本。结合合理的引擎选择与资源调优,可在研发阶段获得接近生产的性能体验,为后续 RAG、工具调用(MCP)、审计治理打下基础。
如果本文对你有帮助:点个赞、收藏、转发,后续将更新《Xinference 集群调度与动态扩缩容实战》、《vLLM 与 SGLang 性能对比基准》。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 34
34 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)