AI Agent部署策略:从架构选择到落地实践的全景指南,非常详细收藏我这一篇就够了!
本文深入探讨了AIAgent的四种核心部署策略:批处理、流处理、实时和边缘部署,为技术决策者提供实用指南。批处理适用于金融风控等大规模数据处理;流处理实现工业物联网等实时分析;实时部署支撑智能客服等交互场景;边缘部署则保障医疗诊断等隐私敏感应用。文章通过具体案例、技术架构和实施细节,展示了不同部署模式的业务适配性、性能指标和优化技巧,并提供了混合部署建议。随着Serverless、联邦学习等新技术
在AI技术从实验室走向生产环境的关键阶段,AI Agent的部署策略已成为决定项目成败的核心环节。不同于传统软件的静态部署,AI Agent作为具备推理、决策和行动能力的动态系统,其部署模式直接影响响应速度、成本结构、数据安全性和用户体验。本文将深入剖析四种核心部署模式,通过真实案例、技术工具链和实施细节,为技术决策者提供可落地的部署指南。
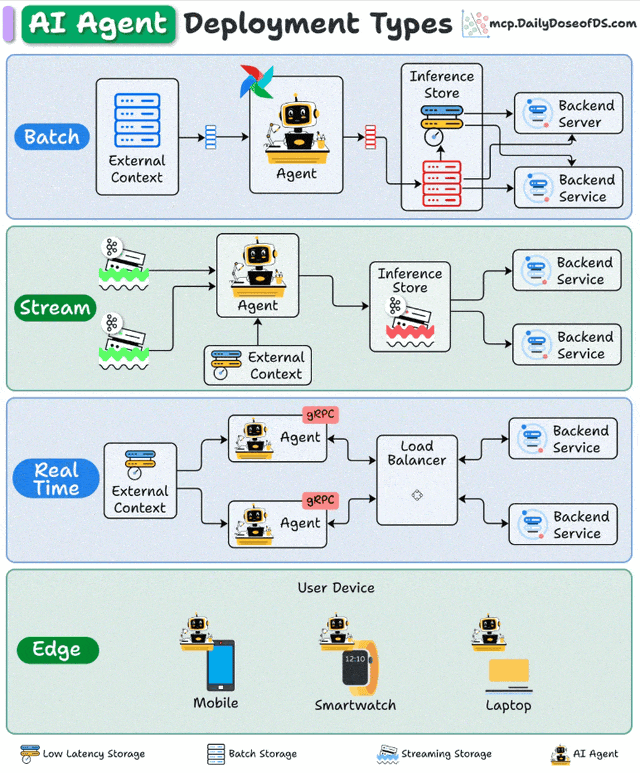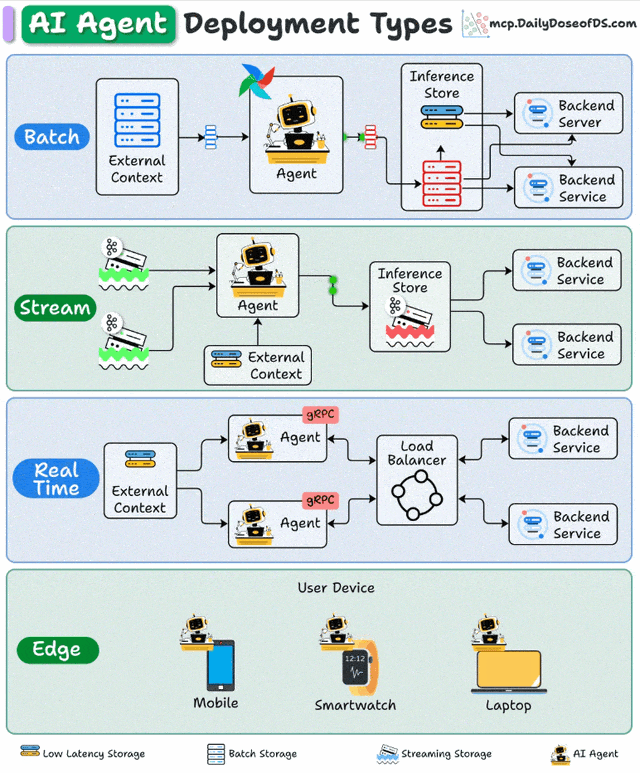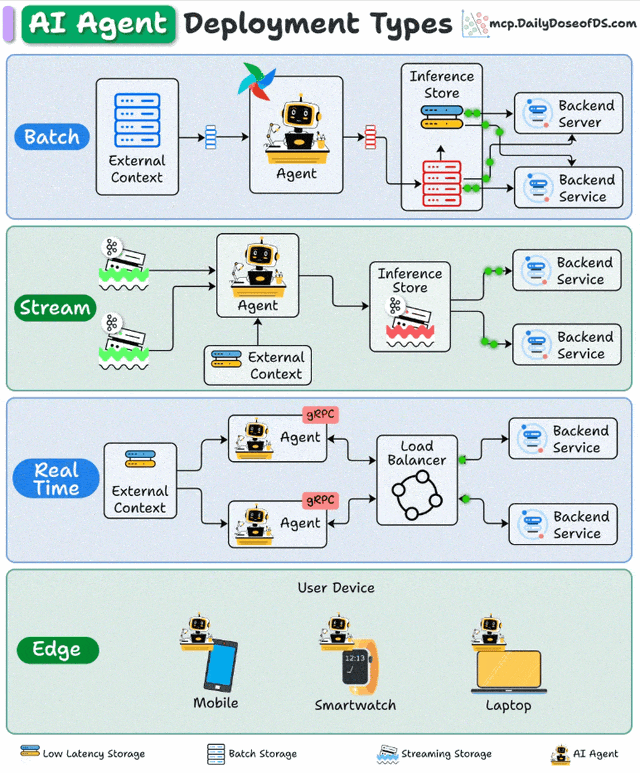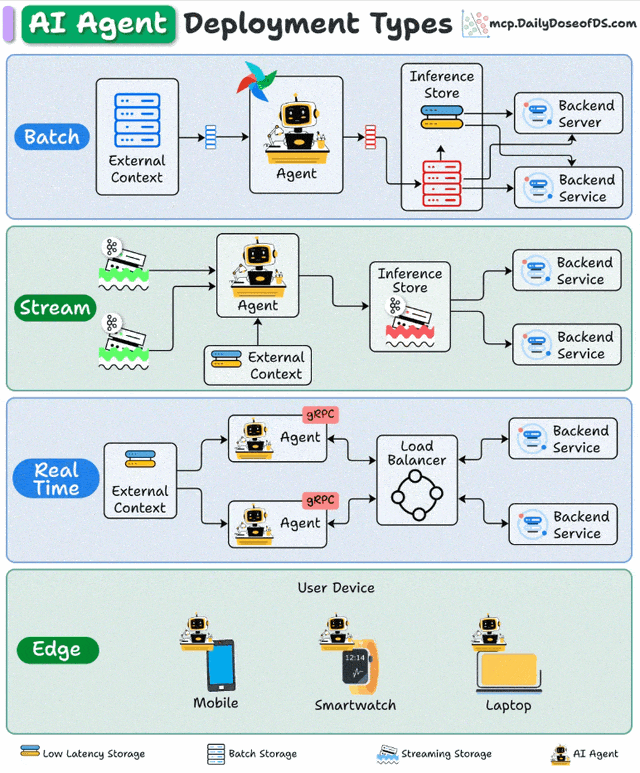
一、批处理部署:大规模数据处理的"幕后英雄"
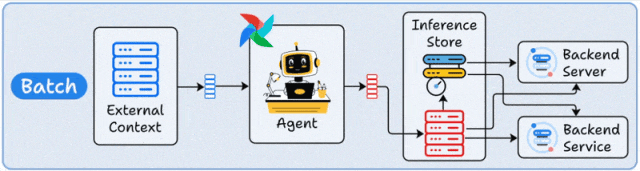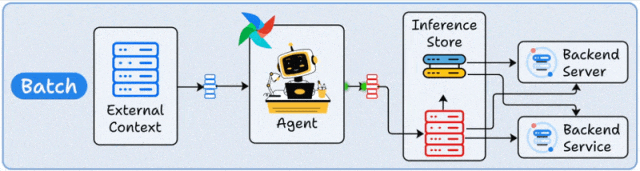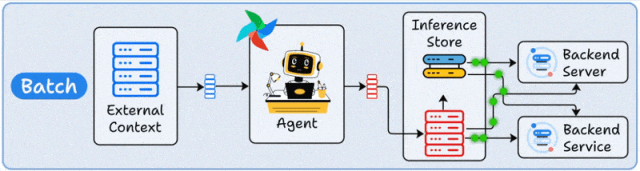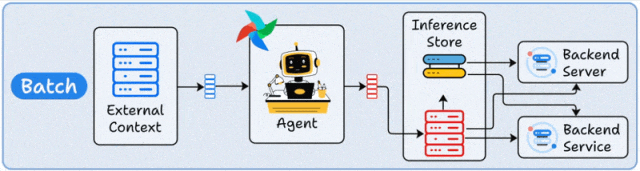
核心原理
批处理部署采用定时触发机制,Agent在预设时间窗口内集中处理累积数据。其架构通常包含调度器(如Airflow)、数据存储层(如S3/HDFS)和Agent计算集群,形成"数据采集→批量处理→结果存储"的闭环。
典型应用场景与案例
1. 金融风控系统
-
- 案例:某跨国银行每日凌晨2点启动Agent,分析前24小时全球交易记录
- 处理流程:
1)从交易数据库抽取TB级原始数据
2) Agent调用反洗钱模型识别异常模式
3) 生成风险报告并自动冻结可疑账户
-
- 工具链:Apache Airflow调度 + LangChain Agent + Snowflake数据仓库
- 关键指标:单日处理1.2亿笔交易,误报率<0.3%
2. 医疗影像分析
案例:区域医疗中心夜间批量分析CT影像
- 技术实现
1) DICOM影像自动上传至对象存储
2) 多模态Agent(视觉+LLM)并行处理
3) 生成结构化诊断报告推送给医生
- 优化技巧:
1) 使用Ray分布式计算框架加速处理
2) 采用混合精度计算降低GPU占用率40%
技术栈推荐
|
组件类型 |
推荐工具 |
优势说明 |
|---|---|---|
|
任务调度 |
Apache Airflow, Prefect |
可视化DAG管理,支持重试机制 |
|
数据存储 |
Amazon S3, Snowflake |
弹性扩展,成本优化 |
|
Agent框架 |
LangChain Batch, LlamaIndex |
内置上下文管理,支持工具链 |
|
资源编排 |
Kubernetes + KubeFlow |
自动扩缩容,资源隔离 |
实施挑战与解决方案
- 数据倾斜问题:采用动态分区策略,按数据哈希值均匀分配任务
- 资源争用:设置优先级队列,关键任务抢占式调度
- 错误恢复:实现检查点机制(Checkpointing),支持断点续处理
二、流处理部署:实时数据流的"智能中枢"
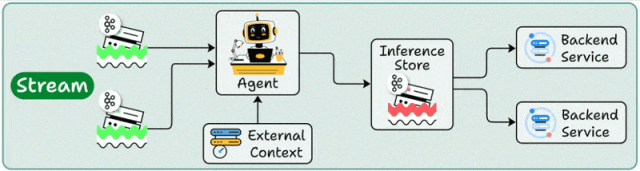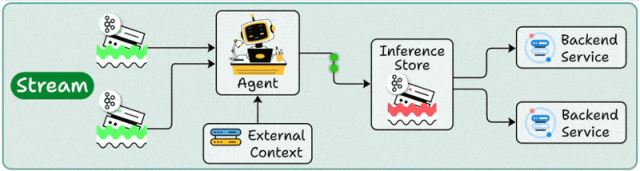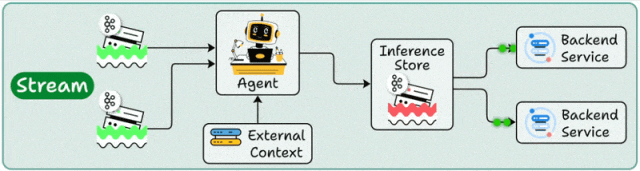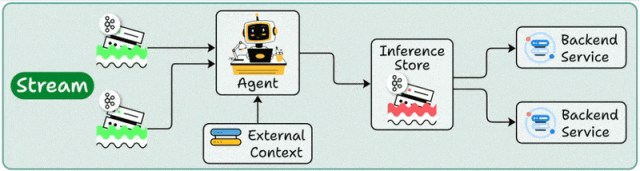
架构设计
流处理部署构建在事件驱动架构(EDA)之上,Agent作为流处理管道的"智能节点",持续消费Kafka/Pulsar等消息队列中的数据流,通过状态管理维护处理上下文。
行业应用深度解析
1. 工业物联网预测性维护
-
- 场景:半导体工厂设备监控
-
数据流:
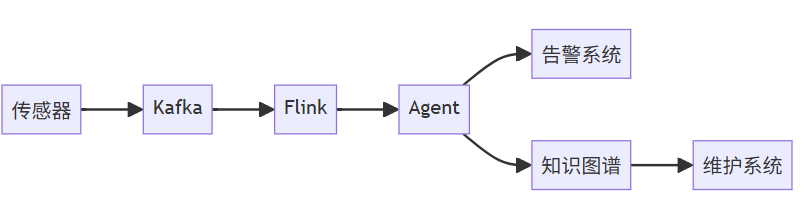
-
Agent 能力
1)实时分析10万+传感器数据流
2)结合设备历史故障知识图谱
3)提前72小时预测设备异常
- 性能指标:端到端延迟<500ms,准确率92%
2. 社交媒体舆情监控
-
-
案例:某快消品牌实时追踪产品口碑
- 技术实现:
-
Twitter API数据流接入
-
多语言Agent(支持28种语言)情感分析
-
触发自动化公关响应流程
-
- 工具组合:
-
Apache Kafka(消息队列)
-
Apache Flink(流处理引擎)
-
Custom Agent(集成BERT+GPT)
-
-
关键技术组件
# 流处理Agent伪代码示例class StreamingAgent:def __init__(self):self.kafka_consumer = KafkaConsumer('sensor_topic')self.state_store = RedisStateBackend()self.llm = OpenAI(model="gpt-4-turbo")def process_stream(self):for message in self.kafka_consumer:# 从状态存储获取历史上下文context = self.state_store.get(message.device_id)# 实时推理result = self.llm.predict(f"Context: {context}\nNew data: {message.payload}")# 更新状态并触发动作self.state_store.update(message.device_id, result)if result.anomaly:self.trigger_alert(result)
优化策略
- 背压控制:使用Kafka消费者组动态调节消费速率
- 状态管理:采用RocksDB实现本地状态缓存,减少外部存储访问
- 容错机制:通过Chandy-Lamport算法实现精确一次(Exactly-Once)处理
三、实时部署:交互式服务的"即时响应引擎"
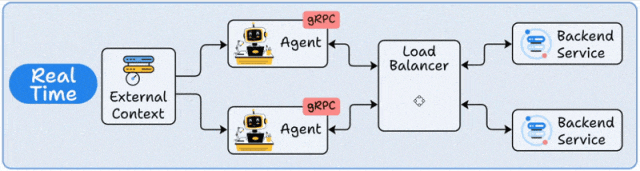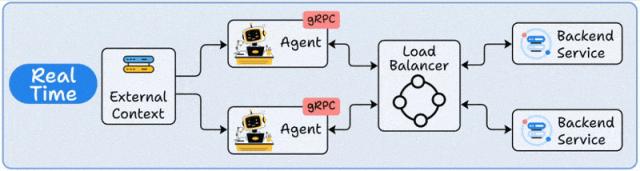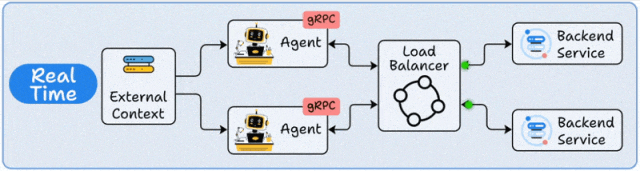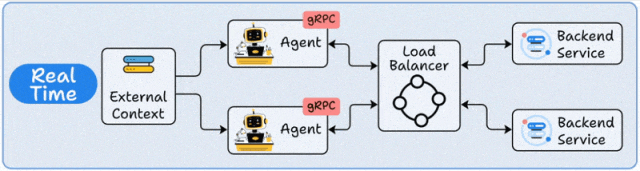
系统架构
实时部署采用微服务架构,Agent封装为REST/gRPC API服务,通过负载均衡器(如Nginx/Envoy)分发请求,配合缓存层(Redis)和推理加速(TensorRT)实现亚秒级响应。
核心应用场景
1. 智能客服系统
案例:某航空公司订票助手
交互流程:
用户查询 → API网关 → Agent集群 →[知识库检索] + [意图识别] →[多轮对话管理] → 响应生成
- 性能表现:
-
并发支持5000 QPS
-
P99延迟<800ms
-
问题解决率提升至85%
-
2. 游戏NPC动态交互
-
- 技术突破:
-
使用Unreal Engine集成Agent服务
-
NPC实时响应玩家行为
-
动态生成剧情分支
-
- 架构亮点:
-
边缘计算节点部署(全球32个节点)
-
WebRTC实现低延迟通信
-
模型蒸馏技术压缩推理模型
-
- 技术突破:
技术实现细节
// Go语言实现的Agent服务端示例func (s *AgentServer) HandleQuery(ctx context.Context, req *pb.QueryRequest) (*pb.QueryResponse, error) {// 1. 从缓存获取用户上下文context := s.redis.Get(ctx, req.UserID).String()// 2. 调用LLM推理response, err := s.llmClient.Complete(ctx, llm.Request{Prompt: fmt.Sprintf("%s\n%s", context, req.Query),MaxTokens: 500,Temperature: 0.7,})// 3. 异步更新对话历史go s.updateHistory(req.UserID, req.Query, response.Text)return &pb.QueryResponse{Answer: response.Text}, nil}
高可用设计
- 多级缓存:本地缓存(Caffeine) + 分布式缓存(Redis) + CDN
- 熔断机制:Hystrix实现服务降级(超时/错误率>阈值时返回预设响应)
- 弹性伸缩:Kubernetes HPA基于CPU/内存/请求队列深度自动扩缩容
四、边缘部署:隐私优先的"端侧智能"
技术架构
边缘部署将Agent直接嵌入终端设备,通过模型压缩(量化/剪枝)、本地知识库和轻量级推理引擎,实现"设备端自主决策"。
典型应用场景
1、移动医疗诊断
- 案例:糖尿病视网膜病变筛查App
- 端侧实现:
-
模型:MobileNetV3+蒸馏版GPT-2(仅12MB)
-
流程:
-
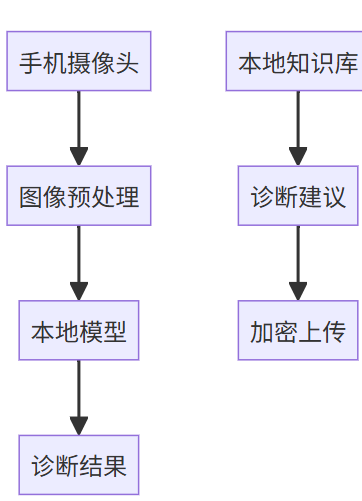
-
-
隐私保护:原始影像永不离开设备
-
- 性能指标:单次分析<3秒,准确率89%
2、车载语音助手
技术方案:
-
部署位置:车载娱乐系统(Android Automotive)
- 关键技术:
-
TensorRT加速推理
-
本地NLU引擎(Rasa)
-
离线命令库支持200+基础操作
-
-
数据安全:行车记录仅在本地处理
边缘优化技术栈
|
技术方向 |
解决方案 |
效果提升 |
|---|---|---|
|
模型压缩 |
量化(INT8)+知识蒸馏 |
模型体积缩小70% |
|
推理加速 |
Core ML, TensorRT, NNAPI |
延迟降低至1/3 |
|
端侧数据库 |
SQLite, Realm |
本地知识检索<50ms |
|
设备适配 |
ONNX格式 + 硬件加速指令 |
跨平台兼容性提升 |
实施挑战应对
- 设备异构性:采用MLIR编译器生成多平台目标代码
- 资源限制:动态加载模型模块(按需激活功能)
- 版本同步:使用差分更新技术减少OTA流量消耗
五、部署策略决策框架
关键决策因素
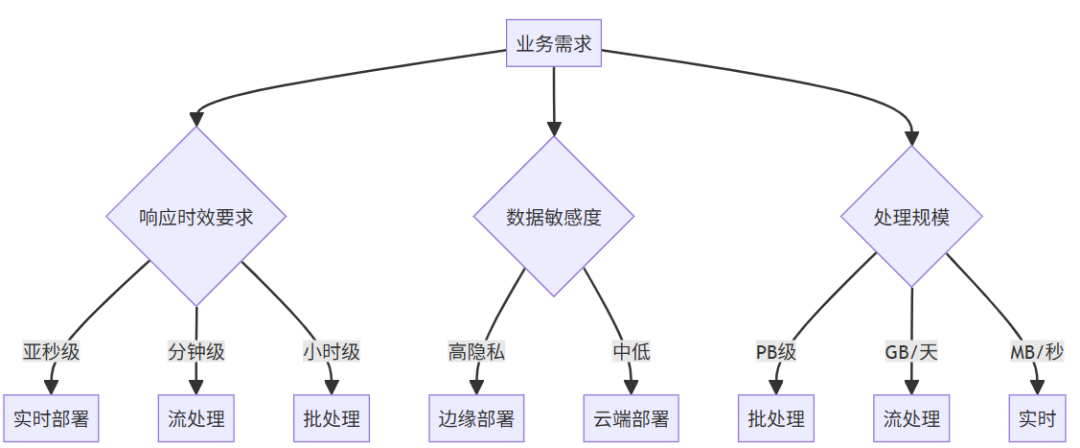
成本效益分析模型
|
部署模式 |
基础设施成本 |
运维复杂度 |
典型ROI周期 |
|---|---|---|---|
|
批处理 |
$ |
★★☆ |
6-12个月 |
|
流处理 |
$$ |
★★★☆ |
3-6个月 |
|
实时 |
$ |
★★★★ |
1-3个月 |
|
边缘 |
$$ |
★★★★★ |
12-24个月 |
混合部署最佳实践
某电商平台采用"边缘+实时"混合架构:
- 边缘层:移动端个性化推荐(保护用户隐私)
- 实时层:云端实时库存查询(保证数据新鲜度)
- 批处理层:夜间用户行为分析(优化推荐算法)
- 流处理层:实时订单状态跟踪(提升用户体验)
六、未来演进趋势
-
Serverless Agent
-
AWS Lambda+Agent框架实现按秒计费
-
典型场景:突发流量处理(如抢购系统)
-
-
联邦学习部署
-
多设备协同训练,模型更新不上传原始数据
-
案例:跨医院医疗Agent协作诊断
-
-
量子-经典混合部署
-
量子计算机处理复杂推理,经典设备执行简单任务
-
应用:药物发现Agent的分子模拟
-
-
自愈式部署
-
Agent自动检测部署异常并修复
-
技术:结合Chaos Engineering实现弹性自恢复
-
结语:部署策略决定AI价值天花板
AI Agent的部署绝非简单的技术选型,而是业务需求、技术约束和成本效益的精密平衡。批处理模式在成本敏感场景中不可替代,流处理架构持续释放实时数据价值,实时部署支撑交互体验革命,边缘计算则开创隐私计算新范式。未来随着异构计算、联邦学习等技术的发展,部署策略将向更智能、更弹性、更安全的方向演进。技术决策者需要建立"业务场景→技术架构→工具链→持续优化"的全局视野,才能真正释放AI Agent的生产力潜能。在AI从实验室走向产业深水区的关键阶段,科学的部署策略将成为企业数字化转型的核心竞争力。
AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以点扫描下方👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!
01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献405条内容
已为社区贡献405条内容

所有评论(0)