[学习总结]D1 自然语言处理&RNN(文字版)
摘要: 本文介绍了自然语言处理(NLP)的基础概念与流程。自然语言广义上指一切时序数据,需要通过分词、编码、向量化等步骤处理。重点对比了表格类数据、图形类数据和时序数据的特点,并详细解析了Count向量化、TF-IDF和Word Embedding三种向量化方法。最后引入RNN循环神经网络,说明其通过保留隐藏状态来处理序列数据的原理。这些知识为理解大模型的数据处理方式奠定了基础。(150字)
文章目录
前言
随着人工智能的不断发展,大模型这门技术也越来越重要。在进入大模型学习之前,我们需要一些前置知识,就是大模型处理的是什么数据,以及在大模型出现之前,都用什么算法来处理这些数据的。
1、什么是自然语言
狭义:人类日常交流的语言,比如:中文、法语、英语
广义:一切时序数据都可以看作自然语言,比如语言、语音、音乐、代码、数学公式…
时序数据:有逻辑前后顺序或时间顺序的数据。
在大模型看来,只在乎数据是否是时序数据。
总结:自然语言原来指人类日常交流的语言;后来指时序数据
2、什么是时序数据
上文中,给时序数据下了定义,即有逻辑前后顺序或时间顺序的数据都能成为时序数据;在这一章中,主要对比另外两种数据,来理解时序数据与常规数据的不同之处。
2.1 表格类数据
表格类数据是零维数据(改变位置不会改变处理结果),tabular data,相互独立,用机器学习和全连接网络处理。
以下为表格类数据示例(为探究学习成绩与几个特征的关联性数据集,几个特征分别为学习小时数、之前成绩、课外活动、睡眠时长、练习题卷数量):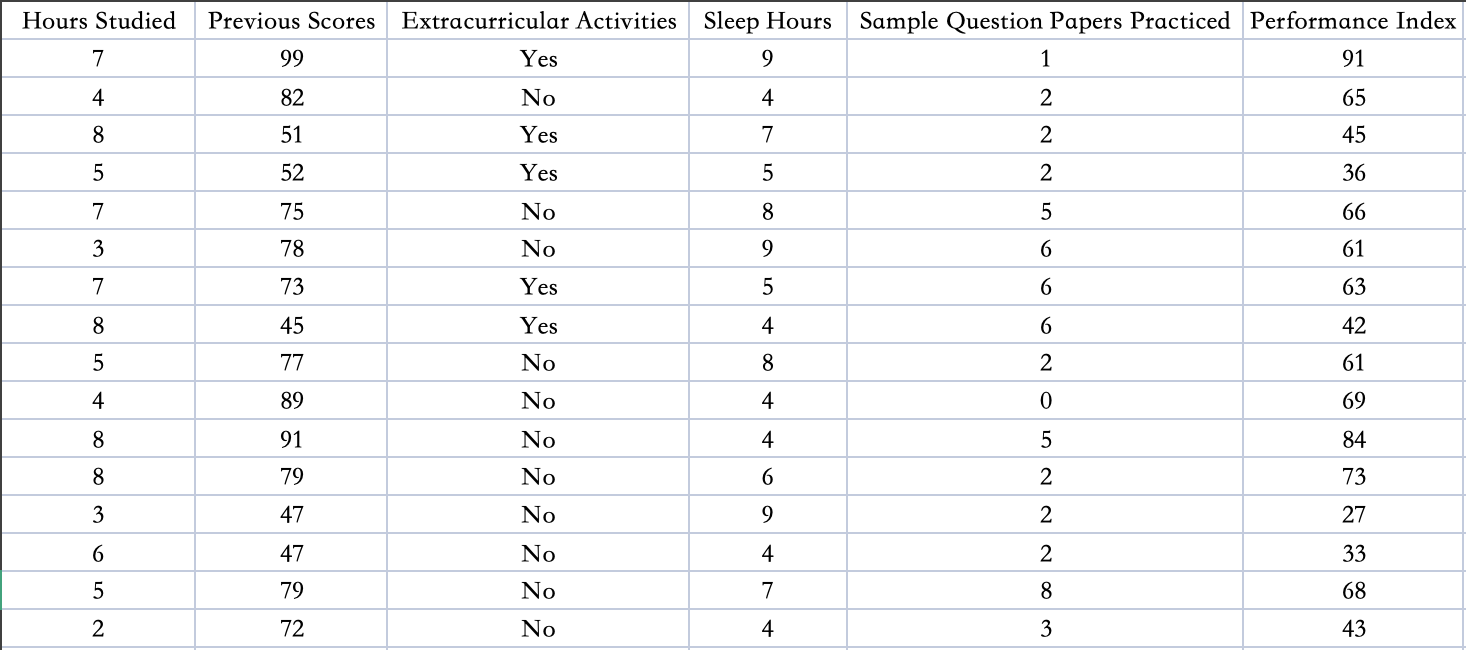
2.2 图形类数据
图形类数据是二维数据(h和w方向的数据打乱是不行的),image data,两个方向上互相依赖,用卷积网络处理。
以下为图像类数据示例(在照片中,每个像素点都有不同的信息值-即RGB值,这意味着,图像类数据,也是天然有直接数据记录信息的):
2.3 时序数据
猫|追|狗
狗|追|猫
时序类数据是一维信息,time series data,在一个方向上相互依赖,早期用RNN处理。
以上为原始的时序数据示例,可以看出,数据的位置信息能影响这个结果;同时,也能知道,时序类数据,和上面的两类数据不同–时序类原始数据,没有相应的底层数据来代表其相应的信息。
为了解决这个问题,我们要先将时序类数据转化为向量数据,才能进行下一步的处理,由此,我们需要引出自然语言处理的通用流程。
3、自然语言处理的通用流程*
相对之前的两种数据,时序数据要先进行数字化流程,以下为自然语言处理的通用流程: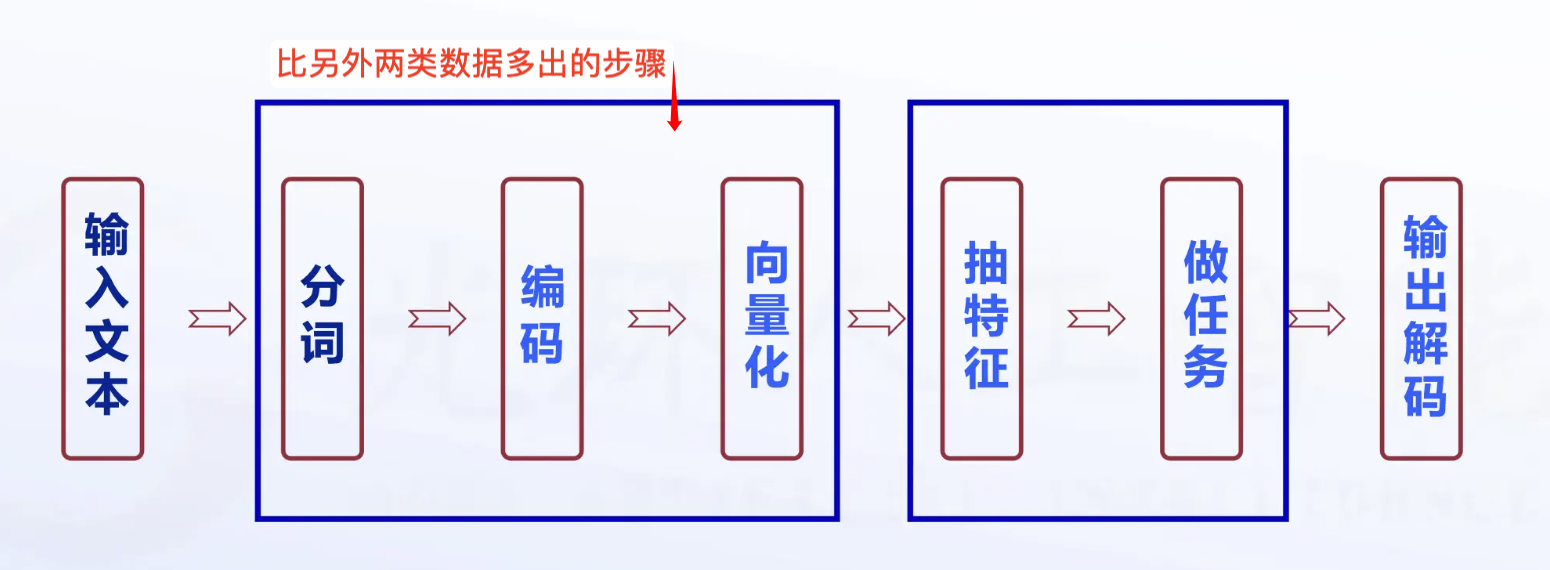
3.1 分词
- 本质:将连续的的文本拆分为为更小的、有意义的单元(称为“词元”、“标记”,token)的过程。(注意:这些单元可以是单词、子词、字符)
- 分词的经典算法:字符级分词、基于空格的分词、基于规则的分词、基于字典的分词、统计分词*、子词分词*(在这些算法中,统计分词和子词分词才是现在的主流,其余其余的已经过时)
- 统计分词*:基于统计模型(如隐马尔可夫模型、HMM、条件随机场)选择最优分词结果,其中中文分词工具(如Jieba)结合词典和统计方法。在大模型出现的今天,已经不需要这些传统的分词算法,但在传统的NLP处理要用(比如自己整理数据、自己训练模型)。
- 子词分词*:将词拆为更小的子词,如英文中,有千万级别的单词,如果要拆分,工作量会很大,大模型里用子词逻辑来做。主要在BERT、GPT等大模型使用WordPiece或BPE。
3.2 编码
- 本质:编码的核心是将离散的文本单元(如词、子词)转换为包含语义信息的中间表示。
- 要义:在编码时,需要建立双向映射,所谓双向映射是指,通过双向模型结构(如双向 RNN、双向 Transformer 编码器),让模型在处理每个文本单元时,既能 “回看” 前面的内容(左→右),也能 “前瞻” 后面的内容(右→左),并将两个方向的语义信息融合成一个更完整的编码结果。
3.3 向量化
- 本质:将离散的文本单元(词、子词、字符)转换为数值向量,完成 “符号→数值” 的基础映射,让计算机能够 “读得懂” 文本。
- 几种向量化方法:Count向量化(词袋模型)、TF-IDF向量化、Word Embedding(词嵌入)
3.3.1 Count 向量化
- 核心思想:有一个公共字典,假如s0、s1、s2都是输入文本,给s0、s1、s2做分词,在公共字典上做统计,那么就会得到3个一样长度的向量(向量长度是公共字典的长度),这样就解决了文本数据结构化的问题了(个人总结版)
- 转换思想:每一行都是字典长度,是稀疏矩阵;每一列值,是字典中该位置的词在本句话内出现的次数;如果字典中这个词没有出现,那么该位置的值为0;如果字典中这个词出现了N次,那么该位置的值就为N
- 特点:稀疏矩阵,大量的零,少量的有效数字;硬伤是丢失了词的顺序,这个模型又叫词袋模型;从句内词的重要性方向考察。
3.3.2 TF-IDF向量化
- 核心思想:这个词在这个句子中出现的越多、在其他句子中出现得越少,那么这个词对这个句子越重要。
- 特点:对count算法的一种改进;从句子间的角度考虑词是否重要;如果一个词,在所有句子中都出现,那么这个词对分类任务影响不大;数据的信息,体现在相对大小之中。
总结:以上两种方法,会丢失位置信息,处理时序数据效果不算很好。
3.3.3 Word Embedding向量化
- 本质:是将离散的对象(如单词、句子或其他类别)转换为连续的向量表示的过程。
(注意表述,已从原始的字符->数值,升级到了建立词与词之间的联系)
作用:
- 维度降低:将高维的稀疏数据(如独热编码)转换为低维的稠密向量,减少计算复杂度。
- 语义表示:嵌入向量可以捕捉单词之间的语义关系,例如“苹果”和“梨”之间的关系,比“苹果”和“汽车”之间的关系要近。
- 训练灵活性:嵌入向量是可训练的参数,随着模型的训练,向量会根据上下文的不同而调整,从而更好地表示单词的含义。
总结: 以上为自然语言从文本到向量化处理的流程,由于语言具有时序性,需要能处理时序信息的算法,以下引入RNN循环神经网络。
4、RNN循环神经网络
4.1 背景
猫|追|狗
狗|追|猫
在上面这两个句子中,词的顺序是不同的,表达出来的意思也是相反的。这表明,时序类数据,单词的顺序对于语句的理解有至关重要的作用。
处理时序语言,通常有以下两种方法:
- RNN(循环神经网络):通过循环结构来处理序列数据,能够记住之前的状态,从而捕捉时序关系。
- LSTM(长短期记忆网络) 和 GRU(门控循环单元):这些是 RNN 的升级版,能够更好地处理长距离依赖关系。
4.2 RNN的简介
循环神经网络(Recurrent Neural Network,简称RNN)是一种能够处理序列数据的神经网络模型。循环神经网络属于深度学习神经网络(DNN),与传统的前馈神经网络不同,RNN在处理每个输入时都会保留一个隐藏状态,该隐藏状态会被传递到下一个时间步,以便模型能够记忆之前的信息。
4.3 RNN的结构
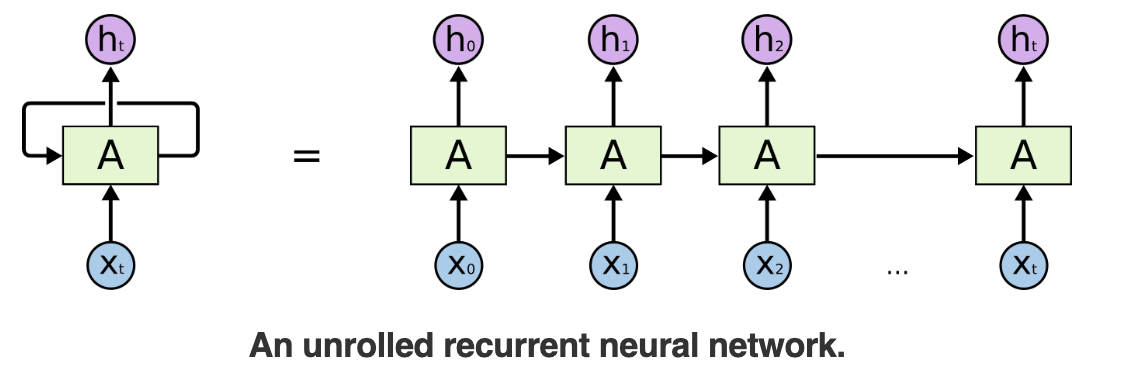
图片来源:https://colah.github.io/posts/2015-08-Understanding-LSTMs/
图示说明:
- X t :当前时间步的输入向量。 X_t :当前时间步的输入向量。 Xt:当前时间步的输入向量。
- A :连接输入层和隐藏层的权重矩阵。 A:连接输入层和隐藏层的权重矩阵。 A:连接输入层和隐藏层的权重矩阵。
- h t :当前时间步的隐状态,包含上下文信息。 h_t:当前时间步的隐状态,包含上下文信息。 ht:当前时间步的隐状态,包含上下文信息。
例如:猫追狗。
x 0 = “猫”, x 0 输入到权重矩阵 A 中,得到隐藏态 h 0 x_0=“猫”,x_0 输入到权重矩阵A中,得到隐藏态h_0 x0=“猫”,x0输入到权重矩阵A中,得到隐藏态h0
x 1 = “追”, x 1 输入到权重矩阵中结合上一步得到的 h 0 ,得到 h 1 x_1=“追”,x_1输入到权重矩阵中结合上一步得到的h_0,得到h_1 x1=“追”,x1输入到权重矩阵中结合上一步得到的h0,得到h1
x 2 = “狗”, x 2 输入到权重矩阵中结合上一步得到的 h 1 ,得到 h 2 x_2=“狗”,x_2输入到权重矩阵中结合上一步得到的h_1,得到h_2 x2=“狗”,x2输入到权重矩阵中结合上一步得到的h1,得到h2
…
最终得到 h n , h n 就是序列的上下文信息 最终得到h_n,h_n就是序列的上下文信息 最终得到hn,hn就是序列的上下文信息
总结

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)