构建AI智能体:五十二、反应式智能体:AI世界的条件反射,真的可以又快又稳
反应式智能体是一种基于"感知-行动"模式的智能系统,它不依赖复杂的内部模型,而是通过简单的条件-动作规则对环境做出即时响应。文章通过蜜蜂采蜜、膝跳反射等例子,阐述了反应式智能体的核心思想:快速、直接的刺激-反应机制。重点介绍了罗德尼·布鲁克斯提出的包容架构,该架构通过分层的行为模块和优先级仲裁机制,使简单规则组合产生复杂行为。以扫地机器人为例,展示了反应式设计在实时响应、避障导
一、初识反应式智能体
前一篇我们详细了解了深思熟虑智能体,今天我们讨论智能体的另一种类型,反应式智能体,想象一下,当我们的手不小心触碰到一个滚烫的杯子时,我们会瞬间缩回。这个过程中,我们的大脑甚至还没有意识到烫这个概念,手已经完成了动作。这种不经过深思熟虑、直接由刺激引发的快速反应,就是反应式智能体的核心思想。
反应式智能体是一种基于“感知-行动”模式的智能系统。它不依赖复杂的内部世界模型,不进行耗时的推理规划,而是像生物的条件反射一样,根据当前的环境输入直接产生行为输出。
一个简单的比喻:
- 反应式智能体:好比蜜蜂采蜜,蜜蜂看到花朵就飞过去,遇到障碍就转向,整个过程流畅自然
- 深思熟虑智能体:好比棋手下棋,每走一步都需要深思熟虑,考虑各种可能性
这种设计使得反应式智能体在需要快速响应的场景中表现出色,成为机器人学、自动驾驶、工业自动化等领域的基石技术,反应式智能体是一种基础且强大的智能体范式,它摒弃了复杂的内部世界模型和前瞻性规划,转而强调对环境的即时、直接响应。这种“刺激-反应”模式,使其在动态、快速变化的环境中表现出极高的效率和鲁棒性。
二、什么是反应式智能体
反应式智能体的设计源于对自然界(如昆虫)高效行为的观察,一只蜜蜂不需要构建整个花园的认知地图,它只需根据光线、花朵形状和气味等即时感官输入,就能做出飞向花蜜的决定。
1. 核心概念
反应式智能体是一种不依赖内部世界模型,也不进行复杂推理,其决策和行动直接由当前时刻的感知输入所决定的智能系统。它
2. 基本工作模式
反应式智能体的的工作模式可以概括为一个极其简化的公式:感知 → 反应。它的工作流程可以概括为一个极其简洁的循环:环境感知 → 条件匹配 → 动作执行 → 环境改变
这个循环的关键在于没有中间的思考环节,智能体不需要回答“我在哪里?”“我要去哪里?”这样的哲学问题,它只需要知道“现在该做什么”。
3. 条件-动作规则
反应式智能体的大脑由一系列简单的“如果-那么”规则组成:
规则集 = [
"如果(前方有障碍物) 那么(向左转)",
"如果(电量低于20%) 那么(返回充电)",
"如果(检测到目标) 那么(向前移动)",
"如果(无特殊情况) 那么(随机探索)"
]这些规则就像生物的神经反射弧,每个都负责处理特定的情境。当环境提供的感知输入匹配某个规则的条件时,对应的动作就会被立即触发。
4. 行为的涌现
单个规则可能很简单,但多个规则组合起来就能产生复杂的行为表现。这种现象被称为“涌现”——整体行为大于部分之和。
实例说明:一个扫地机器人只有三个简单规则:
- 遇到障碍就转向
- 检测到灰尘就清扫
- 默认情况下直线前进
单独看每个规则都很简单,但组合起来后,机器人就能在房间里自主移动、避开家具、清扫灰尘,表现出相当复杂的智能行为。这种从简单规则中产生复杂行为的过程,正是反应式智能体的魅力所在。
5. 核心原则
- 紧耦合的感知-行动循环:智能体的行动直接由当前的感知输入触发,中间没有复杂的思考或规划过程。
- 无内部状态模型:反应式智能体不维护关于世界历史的内部模型,它的决策完全基于现在,这简化了设计并避免了因模型不准确导致的错误。
- 行为分解:复杂的行为不是通过一个庞大的程序实现的,而是通过一系列简单的、并行的行为模式组合而成。
- 涌现行为:智能体整体的、看似复杂的行为,是由多个简单行为在环境交互中涌现出来的,而非预先编程的。
6. 反应式智能体的优势
- 速度快: 响应延迟极低,适用于需要快速反应的任务,如避障。
- 鲁棒性强: 由于不依赖可能出错的内部模型,在部分传感器失效时,剩余的行为模式仍能保证基本功能。
- 设计简单: 模块化设计,易于实现、测试和调试。
7. 反应式智能体的劣势
- 智能受限: 无法进行需要记忆和规划的任务,如下棋、复杂决策。
- 可能陷入局部循环: 例如,一个机器人可能会在两个障碍物之间来回摆动。
8. 一个生活化的比喻:膝跳反射
医生用小锤敲击你的膝盖,你的小腿会不受控制地向前踢出。这个过程:
- 感知:膝盖肌腱被敲击。
- 处理:脊髓层面的神经回路,无需大脑思考。
- 行动:小腿踢出。
这就是一个典型的反应式过程——快速、直接、不经过深思熟虑,反应式智能体正是将这种模式应用在了机器决策上。
三、反应式智能体的架构
1. 行为层次的概念
当多个规则可能同时被激活时,如何决定执行哪个动作?机器人学家罗德尼·布鲁克斯提出了包容架构来解决这个问题。
包容架构的核心思想是:将智能体分解为多个行为层,每个层都是一个独立的“感知-行动”模块。这些层并行运行,但通过优先级机制进行协调。
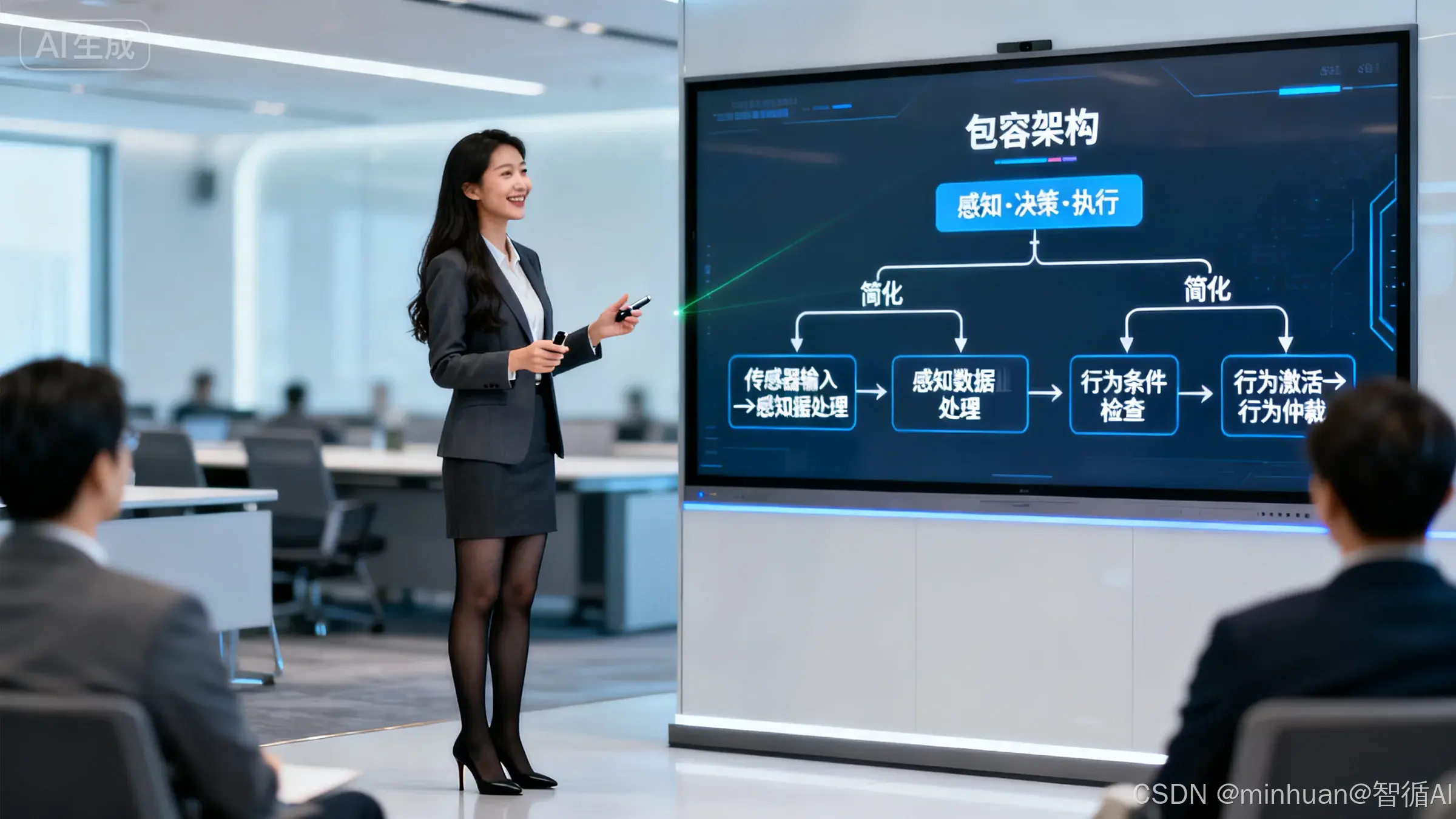
2. 流程详解
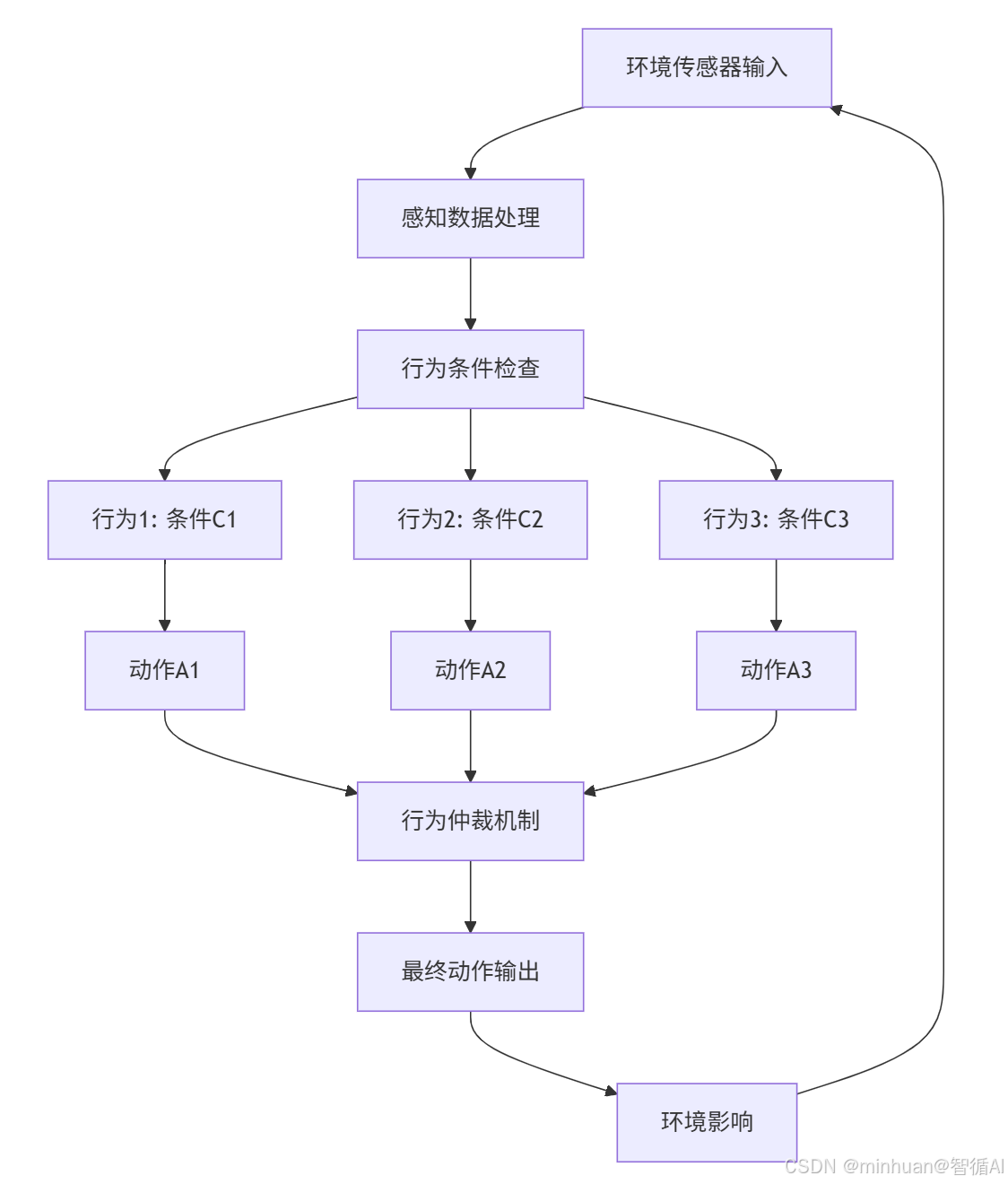
流程说明:
- 1. 感知阶段
- 环境传感器输入:通过摄像头、雷达等传感器收集环境数据
- 感知数据处理:对原始数据进行清洗、分析和理解
- 2. 决策阶段
- 行为条件检查:将处理后的数据与预设的行为条件进行匹配
- 行为激活:满足条件的行为被激活,生成对应动作
- 行为仲裁:当多个行为冲突时,选择最高优先级的动作执行
- 3. 执行阶段
- 最终动作输出:执行选定的动作
- 环境影响:动作改变环境,引发新的传感器输入
流程总结:
- 循环往复:整个过程形成一个连续的"感知-行动"循环
- 实时响应:不进行复杂思考,直接根据当前环境做出反应
- 并行处理:多个行为条件同时检查,提高响应速度
3. 关键组件
- 感知模块: 从传感器(如摄像头、激光雷达、触须)读取原始数据,并进行必要的预处理(如过滤噪声、识别特定特征)。
- 行为集合: 一系列简单的“如果-那么”规则或函数。
- “如果”部分: 感知条件的布尔组合。
- “那么”部分: 要执行的动作或向量。
- 例如:如果 (前方有障碍物) 那么 (向左转)
- 仲裁机制: 当多个行为同时被激活时,仲裁机制决定哪个行为拥有控制权。常见策略包括:
- 固定优先级: 某些行为(如“避障”)永远比“探索”行为优先级高。
- 抑制结构: 高优先级行为可以抑制低优先级行为的输出。
- 向量求和: 将所有行为输出的动作向量(如速度、转向角)相加,得到最终动作。
在包容架构中,行为层被组织成不同的优先级:
- 高优先级:避障行为 ← 生命安全最重要
- 中优先级:任务行为 ← 完成主要任务
- 低优先级:探索行为 ← 默认行为
仲裁原则:高优先级行为可以抑制低优先级行为。就像在人类行为中,躲避危险的本能会压制其他所有想法。
4. 实际应用场景
考虑一个自动驾驶汽车的反应式系统:
行为层 = {
# 最高优先级:安全相关
"紧急制动": {"条件": "碰撞 imminent", "动作": "全力刹车"},
# 高优先级:避障
"主动避障": {"条件": "前方有障碍", "动作": "转向避让"},
# 中优先级:导航
"车道保持": {"条件": "偏离车道", "动作": "微调方向"},
# 低优先级:舒适性
"平稳驾驶": {"条件": "道路弯曲", "动作": "平滑转向"}
}当多个条件同时满足时,只有最高优先级的动作会被执行,这种设计确保了系统在任何情况下都能做出最安全的选择。
四、反应式智能体的构建 - 包容架构
如何将多个简单的“条件-动作”规则组合起来,形成复杂的行为?机器人学家罗德尼·布鲁克斯提出了经典的 “包容架构”。
1. 核心思想
包容架构将智能体分解为多个行为层,每个层都是一个简单的“条件-动作”模块。这些层并行运行,但通过 “抑制” 与 “抑制” 机制进行协调。
- 抑制:高优先级行为可以覆盖低优先级行为的输出信号。
- 抑制:高优先级行为可以阻断低优先级行为接收输入信号。
2. 一个机器人的行为层设计
假设我们要构建一个室内清扫机器人:
- 层一(最低优先级):充电行为
- 条件:电量 < 10%。
- 动作:向充电桩移动。
- 层二(中优先级):清扫行为
- 条件:检测到灰尘。
- 动作:启动刷子并前进。
- 层三(最高优先级):避障行为
- 条件:前方近距离检测到障碍物。
- 动作:停止,转向。
仲裁过程:当机器人正在清扫时(层二激活),如果突然前方出现障碍物,避障行为(层三)会立即抑制清扫行为(层二)的输出,让机器人先转向。避开障碍物后,避障行为条件不再满足,清扫行为重新取得控制权,这保证了机器人的安全。
3. 包容架构流程图
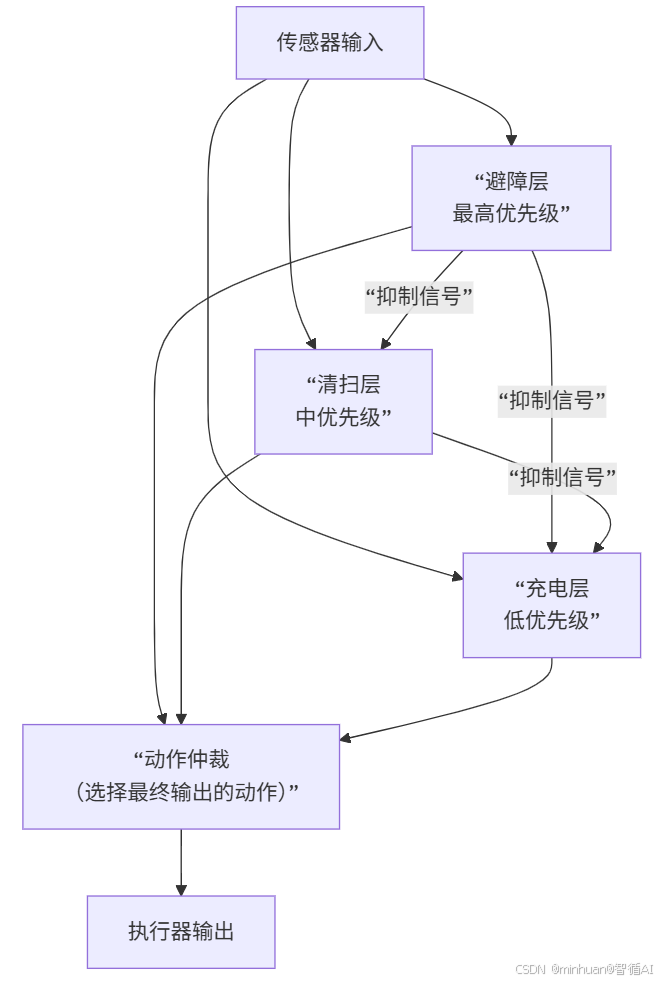
工作过程:
- 传感器输入同时传递给所有行为层
- 各层独立判断是否满足执行条件
- 抑制机制生效:
- 需要避障时,避障层抑制清扫和充电
- 需要清扫时,清扫层只抑制充电
- 都不需要时,执行充电层
- 动作仲裁选择最终要执行的动作
核心机制:
- 三层并行处理:避障、清扫、充电三个行为层同时接收传感器输入
- 优先级抑制:高优先级行为可以抑制低优先级行为
- 行为仲裁:最终只有一个动作被输出执行
4. 完整构建步骤
- 1. 定义任务和目标: 明确智能体需要完成什么。例如:“在房间里漫游而不撞到任何东西”。
- 2. 识别相关情境: 列出智能体在执行任务时可能遇到的所有关键场景。例如:“前方有障碍物”、“左侧有障碍物”、“右侧空旷”、“发现目标”。
- 3. 设计行为模式: 为每个情境设计一个简单的、直接的行为。
- 避障行为: 如果前方近处有障碍,则后退并转向。
- 沿墙行为: 如果左侧有障碍物且距离适中,则保持平行前进。
- 漫游行为: 如果没有特定输入,则随机或直线前进。
- 4. 设定行为优先级: 确定行为的轻重缓急。通常,生存相关(如避障)的行为优先级最高。
- 5. 实现仲裁机制: 编写代码将行为组合起来,确保在任何时刻,最高优先级的有效行为主导智能体的行动。
- 6. 迭代测试与调优: 在模拟或真实环境中反复测试,调整行为的参数(如探测距离、转向速度),以优化性能。
五、示例:最简单的清洁机器人
这是一个简单的扫地机器人智能控制系统,完美展示了反应式设计。
- 感知: 当前位置的传感器(脏 或 干净)。
- 行为:
- 清洁行为: 如果 (当前位置是脏的) 那么 (吸尘)
- 移动行为: 如果 (当前位置是干净的) 那么 (随机移动到一个相邻格子)
- 仲裁: “清洁行为”的优先级高于“移动行为”。
- 分析: 机器人没有地图,不知道哪些地方清洁过。它的行为完全基于当前的局部感知,但长期来看,它最终能清洁整个区域。
在代码运行后体现几大功能点:
- 机器人自主导航:在没有地图的情况下避开所有障碍物
- 智能行为切换:根据环境自动在避障、沿墙、探索间切换
- 实时决策显示:动态显示当前行为和传感器状态
- 轨迹分析:通过颜色可以看到不同行为对应的运动模式
1. 代码重点部分
1.1 传感器模拟原理
def get_sensor_readings(self, obstacles):
readings = []
for sensor_angle in self.sensor_angles:
sensor_dir = np.array([
np.cos(self.angle + sensor_angle), # 传感器方向向量x分量
np.sin(self.angle + sensor_angle) # 传感器方向向量y分量
])
min_distance = self.sensor_range # 初始化为最大探测距离
for obstacle in obstacles:
# 计算机器人到障碍物的向量
obstacle_pos = np.array([obstacle[0], obstacle[1]])
robot_pos = np.array([self.x, self.y])
to_obstacle = obstacle_pos - robot_pos
# 向量投影:判断障碍物是否在传感器前方
projection = np.dot(to_obstacle, sensor_dir)
if projection > 0: # 障碍物在传感器前方
# 计算障碍物到传感器射线的垂直距离
distance_to_ray = np.linalg.norm(to_obstacle - projection * sensor_dir)
if distance_to_ray < obstacle[2]: # 如果距离小于障碍物半径
# 计算实际的碰撞距离
hit_distance = projection - np.sqrt(obstacle[2]**2 - distance_to_ray**2)
if 0 < hit_distance < min_distance:
min_distance = hit_distance
readings.append(min_distance)
return readings- sensor_dir:计算每个传感器的方向向量
- projection > 0:确保只检测前方的障碍物
- distance_to_ray < obstacle[2]:判断是否与障碍物相交
- 返回5个传感器的距离读数列表
1.2 反应式决策核心
def reactive_control(self, sensor_readings):
# 传感器分组:左2个、前1个、右2个
left_readings = sensor_readings[:2] # 左侧传感器
front_readings = sensor_readings[2] # 前方传感器
right_readings = sensor_readings[3:] # 右侧传感器
# 计算各方向的最小距离
min_front = min(front_readings, self.sensor_range)
min_left = min(left_readings)
min_right = min(right_readings)
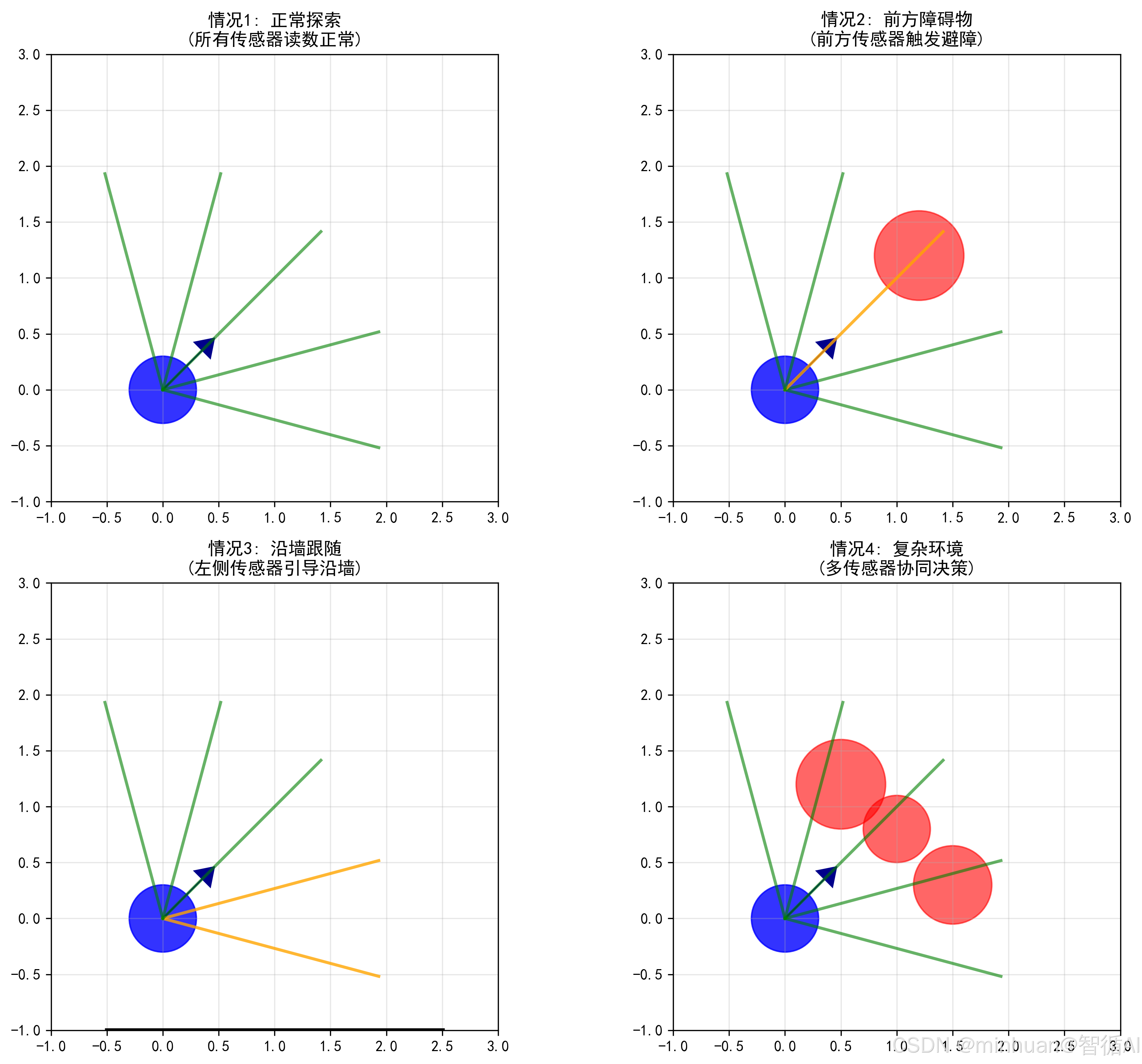
# 行为1: 紧急避障 (最高优先级)
if min_front < 0.8: # 前方很近有障碍
self.speed = 0.3 # 减速
# 选择更空旷的一侧转向
if min_left > min_right:
self.angle -= np.pi/4 # 向右转45度
else:
self.angle += np.pi/4 # 向左转45度
self.current_behavior = "紧急避障"
return self.current_behavior
# 行为2: 预防性避障 (中优先级)
elif min_front < 1.5: # 前方较近有障碍
self.speed = 0.4
if min_left > min_right:
self.angle -= np.pi/8 # 向右转22.5度
else:
self.angle += np.pi/8 # 向左转22.5度
self.current_behavior = "预防避障"
return self.current_behavior
# 行为3: 沿墙跟随 (低优先级)
elif min_left < 1.2 or min_right < 1.2: # 侧面有墙
self.speed = 0.6
if min_left < min_right: # 左侧有墙
self.angle -= 0.1 # 向右微调
else: # 右侧有墙
self.angle += 0.1 # 向左微调
self.current_behavior = "沿墙跟随"
return self.current_behavior
# 行为4: 随机探索 (默认行为)
else:
self.speed = 0.8 # 正常速度
# 加入随机扰动,避免陷入局部循环
self.angle += random.uniform(-0.2, 0.2)
self.current_behavior = "随机探索"
return self.current_behavior- 固定优先级:紧急避障 > 预防避障 > 沿墙跟随 > 随机探索
- 距离阈值:不同距离触发不同行为
- 转向策略:总是转向更空旷的一侧
- 速度调节:危险时减速,安全时加速
1.3 位置更新逻辑
def update_position(self, obstacles, area_bounds):
# 1. 感知:获取传感器数据
sensor_readings = self.get_sensor_readings(obstacles)
# 2. 决策:反应式控制
behavior = self.reactive_control(sensor_readings)
# 3. 行动:更新位置
dx = self.speed * np.cos(self.angle) * 0.1 # x方向位移
dy = self.speed * np.sin(self.angle) * 0.1 # y方向位移
new_x = self.x + dx
new_y = self.y + dy
# 边界检查:防止跑出环境
if (area_bounds[0] < new_x < area_bounds[2] and
area_bounds[1] < new_y < area_bounds[3]):
self.x = new_x
self.y = new_y
# 记录轨迹(最多100个点)
self.trajectory.append((self.x, self.y))
if len(self.trajectory) > 100:
self.trajectory.pop(0) # 移除最旧的点
return behavior, sensor_readings1.4 环境创建与障碍物设置
def create_environment():
# 障碍物格式:(x坐标, y坐标, 半径)
obstacles = [
(3, 2, 0.8), # 中心区域的大障碍物
(6, 4, 1.0), # 右侧的大障碍物
(8, 2, 0.6), # 右上角的小障碍物
(4, 6, 0.7), # 中部偏上的障碍物
(7, 7, 0.9), # 右上角的大障碍物
(2, 8, 0.5), # 左上角的小障碍物
(9, 9, 0.6), # 最右上角的障碍物
(5, 3, 0.4) # 中心区域的小障碍物
]
# 环境边界:(x_min, y_min, x_max, y_max)
area_bounds = (0, 0, 10, 10)
return obstacles, area_bounds- 复杂路径:障碍物分布形成曲折的通道
- 大小混合:不同大小的障碍物增加导航难度
- 边界限制:10x10的封闭环境
1.5 动态动画的核心逻辑
def animate(frame):
ax.clear()
# 更新机器人位置(第一帧除外)
if frame > 0:
behavior, sensor_readings = robot.update_position(obstacles, area_bounds)
# 绘制传感器(颜色编码)
for i, (sensor_angle, reading) in enumerate(zip(robot.sensor_angles, sensor_readings)):
sensor_dir = np.array([np.cos(robot.angle + sensor_angle),
np.sin(robot.angle + sensor_angle)])
sensor_length = min(reading, robot.sensor_range)
end_x = robot.x + sensor_length * sensor_dir[0]
end_y = robot.y + sensor_length * sensor_dir[1]
# 颜色编码:绿色(安全) → 橙色(警告) → 红色(危险)
if reading > 1.5:
color = 'green' # 安全距离
elif reading > 0.8:
color = 'orange' # 警告距离
else:
color = 'red' # 危险距离
ax.plot([robot.x, end_x], [robot.y, end_y], color=color,
linewidth=2, alpha=0.7)- 实时更新:每帧重新绘制所有元素
- 颜色编码:用颜色直观显示传感器状态
- 轨迹显示:保留历史轨迹显示运动路径
1.6 反应式智能体的核心特征
特征1:无内部状态模型
# 机器人没有记忆环境地图,只依赖当前传感器数据
def reactive_control(self, sensor_readings): # 只使用当前传感器读数
# 不访问历史数据,不维护环境模型
# 决策完全基于当前的sensor_readings特征2:固定优先级仲裁
# 明确的优先级顺序
if min_front < 0.8: # 1. 紧急避障 (最高)
elif min_front < 1.5: # 2. 预防避障
elif min_left < 1.2 or ... # 3. 沿墙跟随
else: # 4. 随机探索 (最低)特征3:实时响应
# 每帧都重新感知和决策
def update_position(self, obstacles, area_bounds):
sensor_readings = self.get_sensor_readings(obstacles) # 实时感知
behavior = self.reactive_control(sensor_readings) # 实时决策
# 立即执行动作特征4:行为涌现
# 简单规则组合产生复杂行为
# 单个规则很简单,但组合后能:
# - 自主避开所有障碍物
# - 沿着墙壁行走
# - 探索未知区域
# - 不会陷入死循环2. 输出结果
反应式机器人的动态路径:
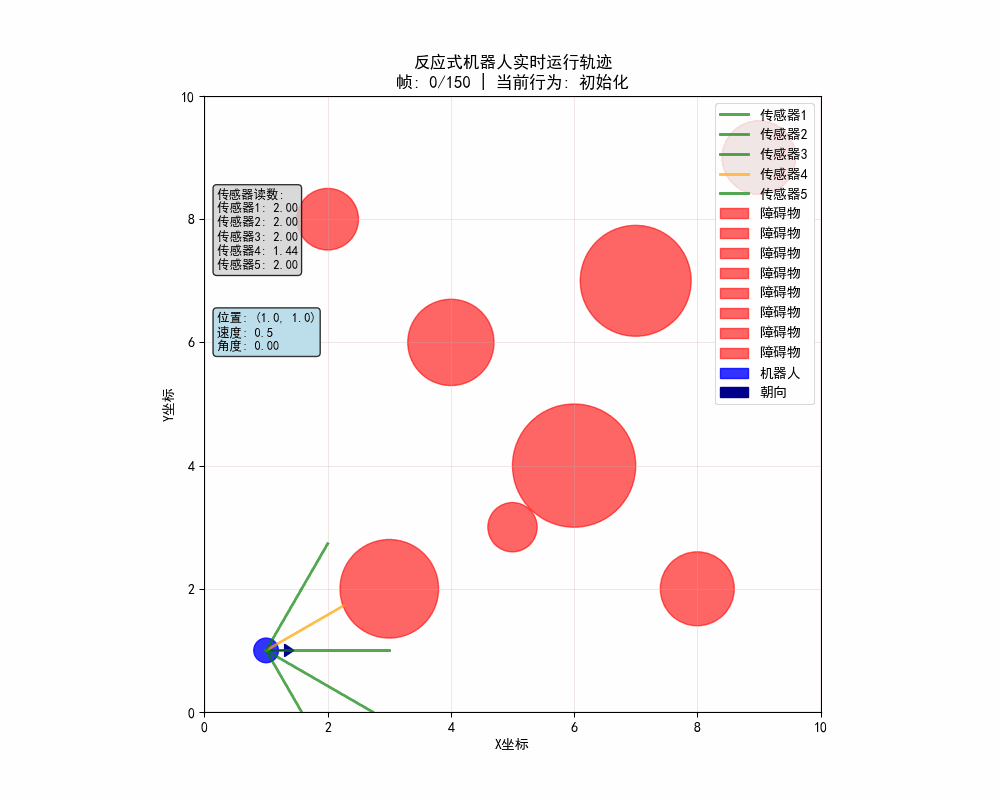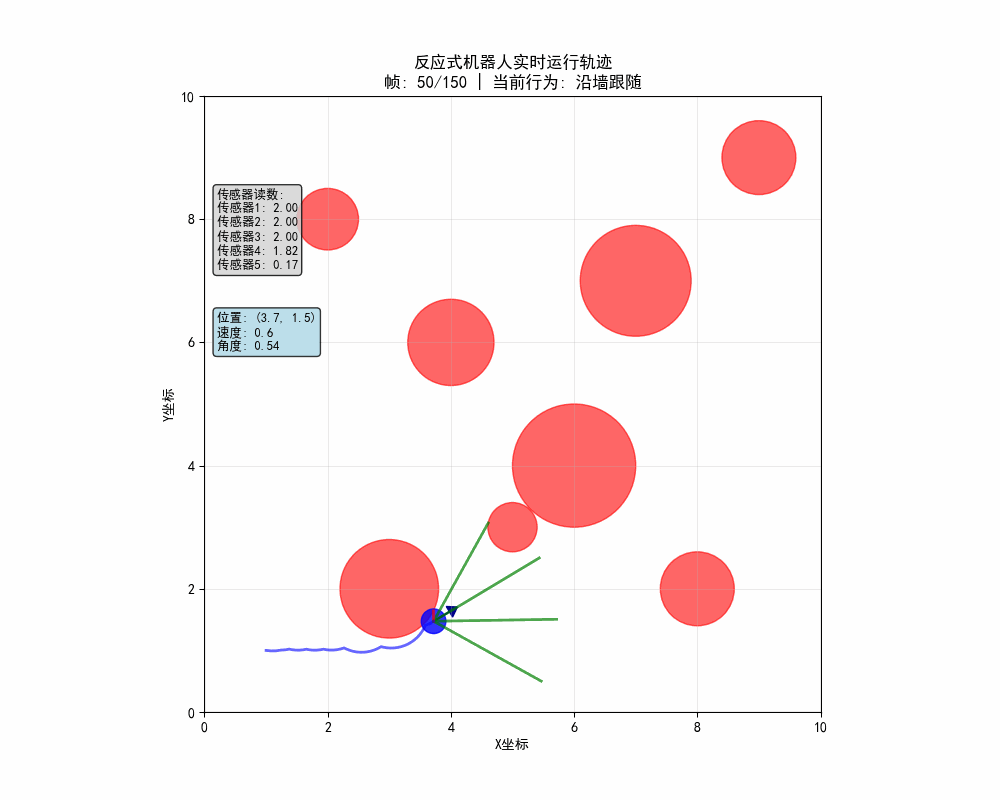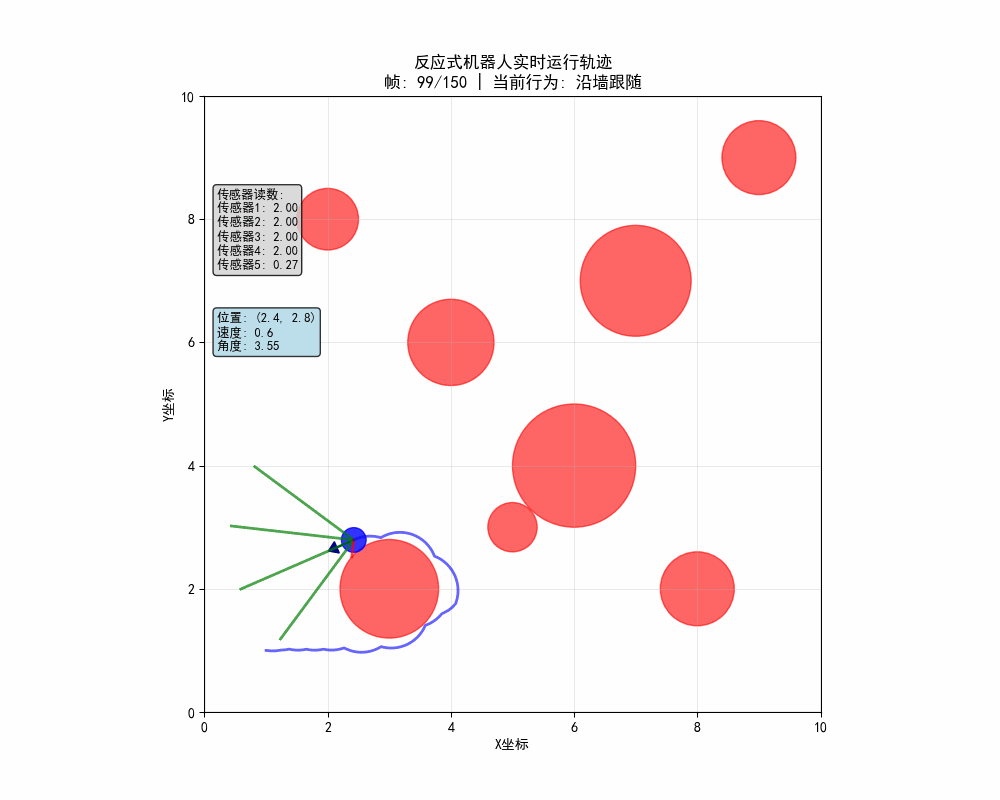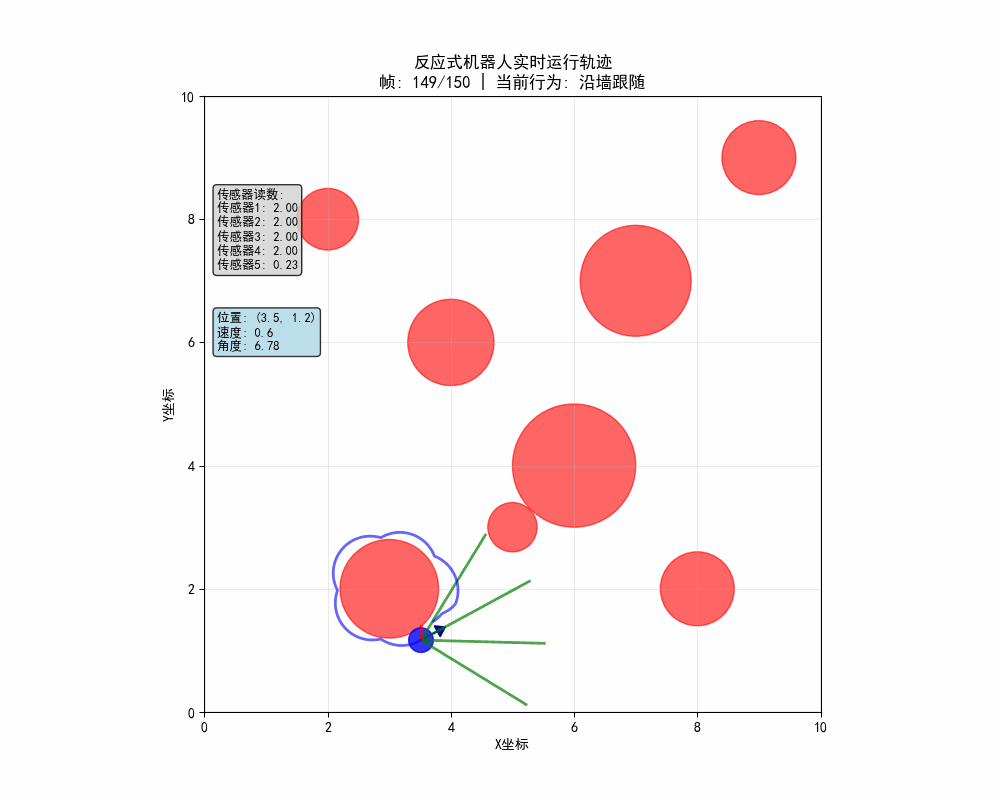
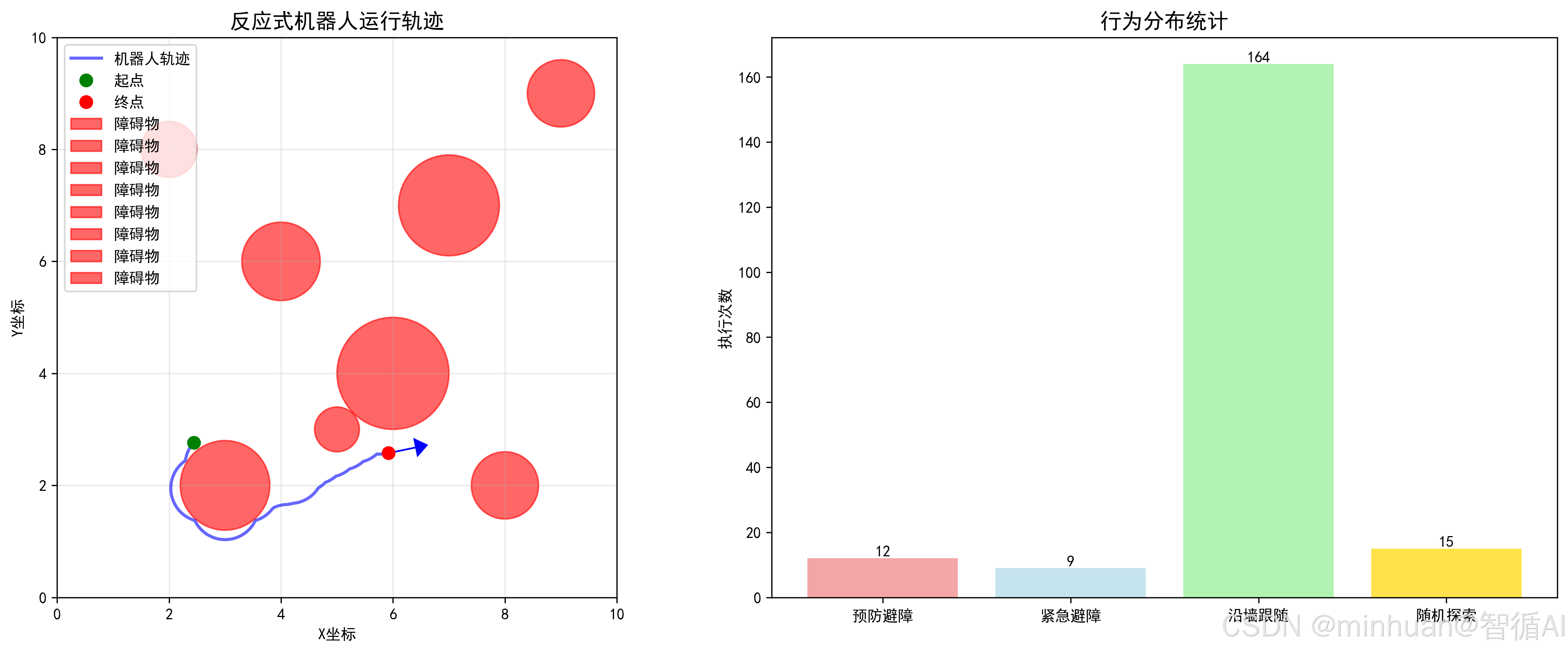
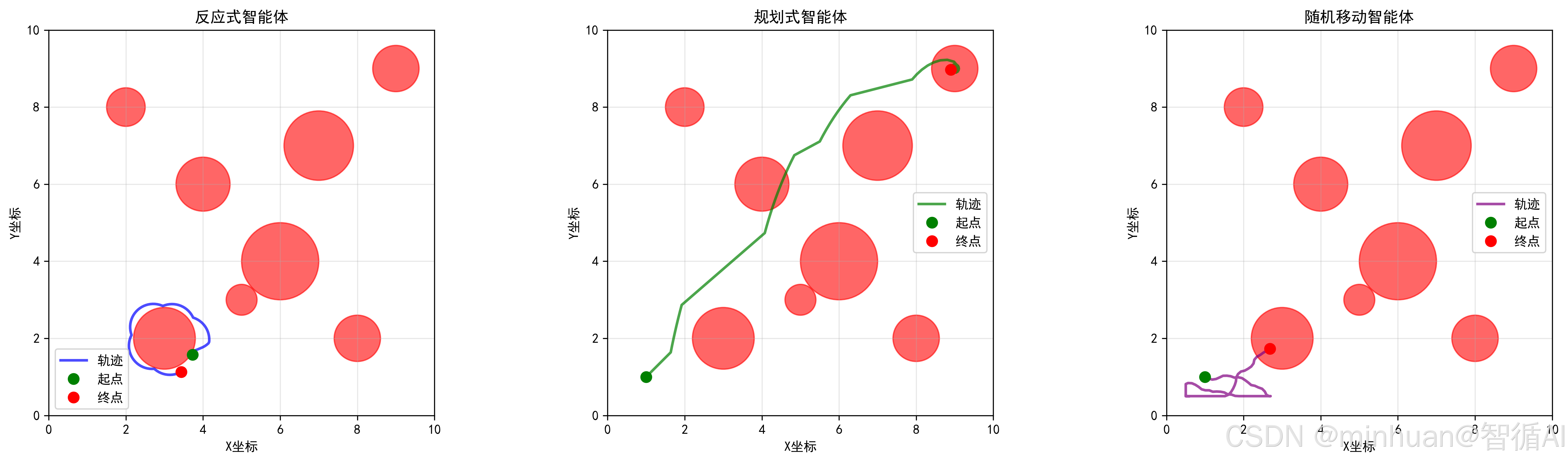
反应式机器人的静态轨迹图:
反应式机器人的传感器工作原理:
反应式机器人的智能体对比:
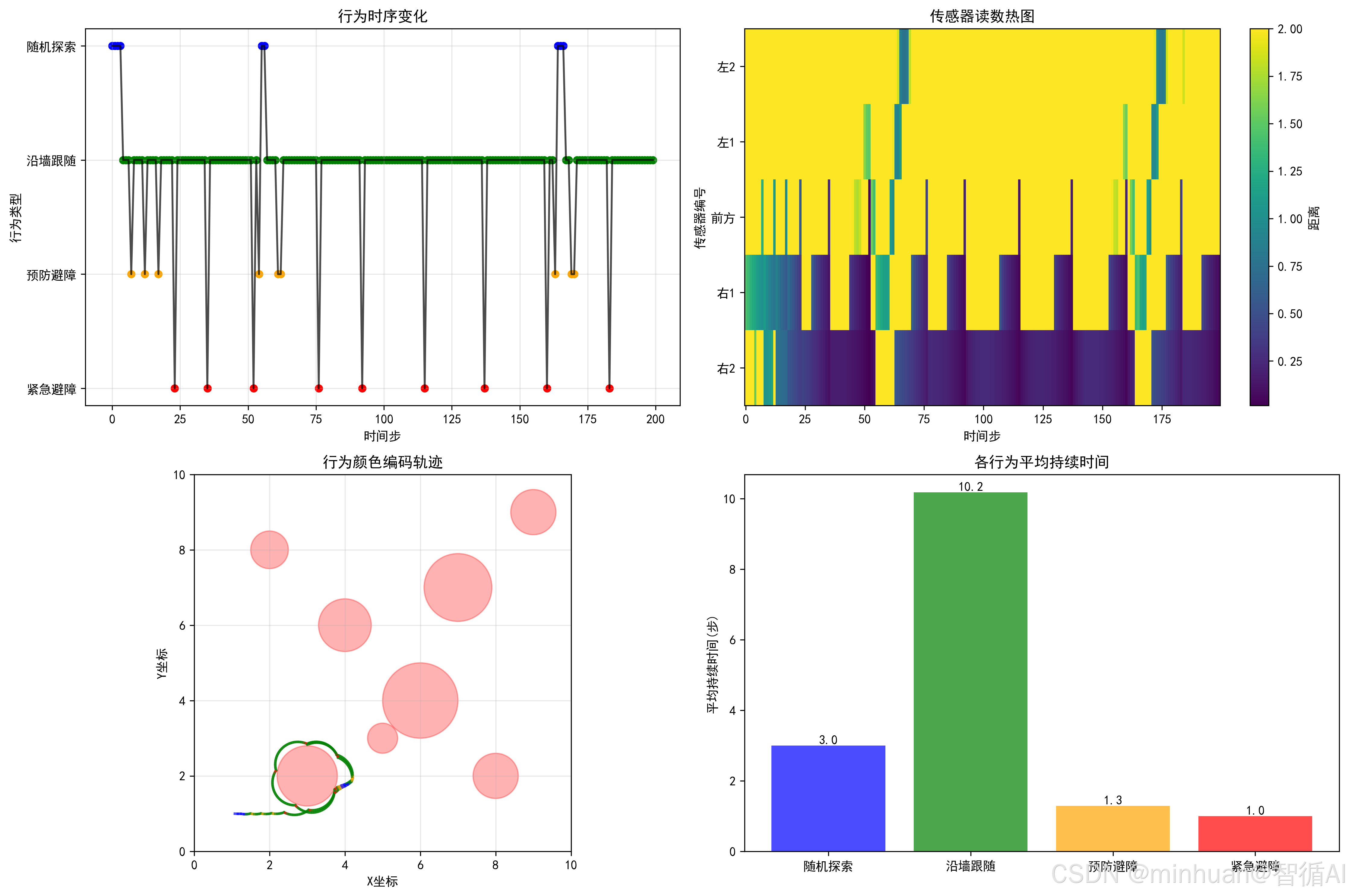
 反应式机器人的行为分析:
反应式机器人的行为分析:
六、总结
反应式智能体以其简单、快速、可靠的核心优势,在AI领域占据了不可替代的一席之地。它完美地诠释了“简单规则产生复杂行为”的涌现智慧。
- 它的主要优势在于:响应延迟极低、对传感器错误不敏感、开发和调试相对简单。
- 它的主要局限在于:缺乏长远规划能力,在需要深思熟虑的任务中显得愚蠢。
反应式智能体代表的是一种工程哲学:用简单、可靠、可验证的组件构建复杂的智能系统。它提醒我们,有时候最有效的解决方案不一定是最复杂的。
就像自然界中的蚂蚁,每个个体都遵循简单的规则,但整个蚁群却展现出令人惊叹的集体智慧。反应式智能体教会我们:智能不一定源于复杂的计算,也可以来自简单规则与环境之间的巧妙互动。
在追求更复杂AI技术的今天,理解反应式智能体的原理和价值,不仅有助于我们构建更可靠的实时系统,也为我们理解智能的本质提供了重要的视角。有时候,后退一步,采用更简单的方法,反而能够走得更远。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)