AI简历筛选评分体系实战解析:如何兼顾能力、门槛与细节验证
【摘要】揭示AI简历筛选的核心,阐述如何通过“三维加权评分模型”与“动态权重自适应框架”相结合,构建一个兼顾能力、门槛与细节的科学评分体系,并深入探讨其工程化落地、治理闭环与未来演进。
【摘要】揭示AI简历筛选的核心,阐述如何通过“三维加权评分模型”与“动态权重自适应框架”相结合,构建一个兼顾能力、门槛与细节的科学评分体系,并深入探讨其工程化落地、治理闭环与未来演进。

引言
在AI技术浪潮席卷人力资源领域的今天,AI简历筛选已从一个前沿概念,逐渐成为许多企业提升招聘效率的标配工具。然而,工具的引入并不总能带来预期的效果。很多HR在使用AI筛选产品时,内心充满了矛盾,一方面期望AI能从堆积如山的简历中解放自己,另一方面又对AI的筛选结果心存疑虑,担心它错失了那些“看起来不符,实则优秀”的潜力股。
这种矛盾的根源,往往不在于简历解析的准确性,也不在于标签提取的全面性,而在于一个更深层次、更关乎产品灵魂的问题——评分体系如何搭建。
一个不透明的评分体系,会让HR觉得AI是个“黑盒子”,筛选结果无法解释,自然难以信任。一个过于死板的评分体系,无异于高级版的“关键词搜索”,只会机械地过滤掉那些简历表述方式不一、但实际能力卓越的人才。这不仅是技术实现的挑战,更是产品设计的“生死线”。
我个人在主导和参与AI简历筛选平台的建设过程中,深刻体会到,最难的环节恰恰是评分体系的设定。它直接决定了产品的筛选效率、用户体验,乃至企业人才战略的落地效果。
因此,我们确立了一个核心设计理念,让评分既能充分发挥AI强大的“语义理解能力”,又能严格遵守招聘流程中最基本的“硬性标准”。基于此,一套经过实战反复验证、不断迭代的解决方案浮出水面,它就是“三维加权评分模型”与“动态权重自适应框架”的结合体。
本文将系统性地拆解这套体系,从原理、实施、优化到未来展望,为致力于AI产品从0到1的朋友们,提供一份详尽的实战指南。
一、🎯 评分体系,为何是AI简历筛选的“生死线”

在深入模型细节之前,我们必须先回答一个根本问题,为什么评分体系如此重要?因为它试图解决传统简历筛选方式的两个核心痛点。
1.1 关键词匹配的天然局限
很多人对AI简历筛选的初步认知,还停留在“关键词搜索”的阶段。HR设定几个关键词,系统去简历里查找,匹配度高的就排在前面。这种方式虽然简单直接,但在实践中弊端丛生。
-
错失高潜力人才。语言是丰富多变的。一个优秀的候选人,可能因为没有使用JD中一模一样的“标准答案”词汇而被无情筛掉。例如,JD要求“精通增长黑客”,而一位候选人的简历详述了自己如何通过A/B测试、病毒营销和数据分析实现用户指数级增长,但全文未提“增长黑客”四字,他很可能就被错过了。
-
评分逻辑不透明,难以服众。简单的关键词计数无法真正衡量“能力”。匹配10个次要关键词的候选人,分数可能高于只匹配3个核心关键词的候选人,这显然不合理。当HR看到一个高分候选人却能力平平时,对整个系统的信任便会崩塌。
-
无法理解深层能力。关键词匹配是纯粹的文本游戏,它无法理解“主导了百万级用户的产品重构”与“负责小型应用的日常维护”之间质的区别,即便两者都包含了“产品”和“维护”等关键词。
1.2 “三类信号”缺一不可的招聘现实
一份有效的筛选评估,必须同时捕捉并权衡三类关键信号。这三类信号共同构成了对一个候选人完整、立体的判断。
-
语义理解信号(能力优先)。这是对候选人“能做什么”的实质性判断。它要求系统能读懂简历中的项目经验、工作职责和成果描述,并将其与JD的核心能力要求进行深层语义匹配。这是判断候选人是否“胜任”的根本。
-
硬性门槛信号(合规基础)。这是对候选人“是否符合基本资格”的校验。学历、工作年限、所在城市、必要的证书等,构成了招聘的“护城河”。任何招聘都无法完全脱离这些硬性标准,它们是效率和合规的基础。
-
细节证据信号(技能实锤)。这是对特定技能掌握程度的“实锤”验证。尤其对于技术类岗位,仅仅说“精通”是不够的,简历中是否出现相关的工具、框架、库或平台名称,是判断其经验真实性的重要佐证。
传统的筛选方式,无论是人工还是简单的关键词系统,都很难同时高效、准确地处理这三类信号。而一个设计精良的AI评分体系,其核心价值就在于,能够将这三类信号有机地融合起来,在筛选的效率与准确性之间,找到那个微妙而关键的平衡点。
二、🎲 三维加权评分模型:能力、门槛、细节的三重保障
为了系统性地解决上述问题,我们设计并实践了“三维加权评分模型”。这个模型将对候选人的评估分解为三个独立的评分维度,再通过加权求和的方式,得到一个综合分数。它像一个三层的漏斗,层层筛选,确保最终呈现给HR的,是真正高质量的候选人。
2.1 第一层:向量模型评分(核心能力匹配,权重50%)
这是整个评分体系的“定方向”部分,也是我们认为最能体现AI价值的核心。它承载了对候选人核心能力的深层理解与匹配。
2.1.1 技术原理浅析
这一层的核心技术是文本向量化(Text Embedding)。简单来说,就是利用深度学习模型(如BERT、GPT等大语言模型),将岗位描述(JD)和简历中的文本内容,分别转换成高维空间中的数学向量。
这些向量能够捕捉文本的深层语义信息。在向量空间中,意思相近的词语、句子或段落,它们的向量在空间位置上也会更接近。因此,评判JD和简历的匹配度,就从一个复杂的文本理解问题,简化成了一个计算两个向量之间“距离”(通常使用余弦相似度)的数学问题。
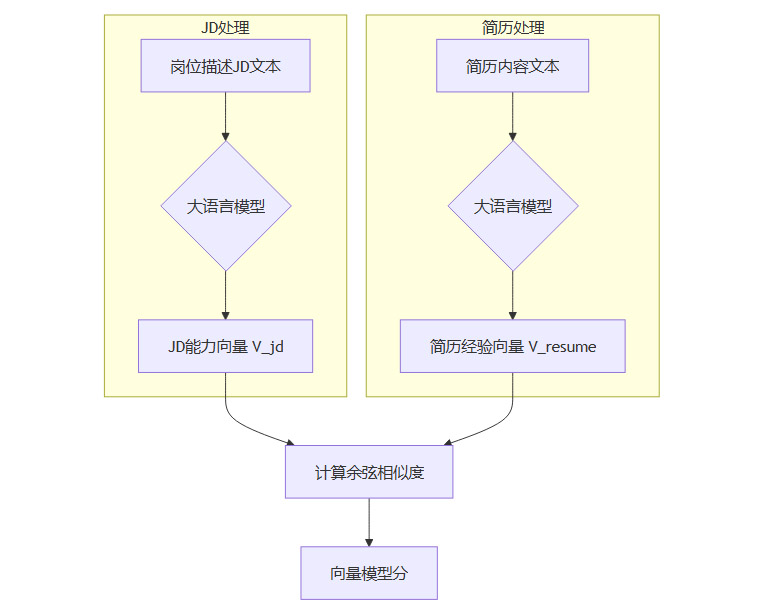
2.1.2 核心价值与案例
这种方法的巨大价值在于突破了关键词的束缚。它不再要求文本的字面完全一致,而是关注其背后的含义是否相同。
举个例子:
-
JD要求:“具备出色的财务分析和预算编制能力”。
-
候选人简历:“主导公司年度财务预算制定,并完成季度财务状况分析报告”。
在关键词匹配系统中,由于没有“财务分析”和“预算编制”这两个精确的词组,候选人可能得分很低。但在向量模型中,AI能够理解“主导...预算制定”与“预算编制能力”高度相关,同时“完成...财务状况分析报告”正是“财务分析能力”的具体体现。因此,AI会计算出两个文本向量之间极高的相似度,并给出一个高分。
这一层的价值在于:
-
发现隐藏的人才。它不会因为候选人没写“标准答案”,就错失真正能做事的人。
-
提升筛选的“质感”。评分结果更贴近人类专家的判断,优先筛选出那些能力高度匹配的候选人。
-
极大提升初筛效率。在简历量巨大的场景下,通过向量模型快速过滤掉能力明显不符的候选人,能让HR将精力聚焦在少数高匹配度的人身上。
2.2 第二层:结构化标签评分(硬性门槛校验,权重30%)
在能力方向基本对齐后,我们需要验证候选人是否满足岗位的硬性门槛。这一层通过从简历中抽取结构化的信息,并进行量化打分,来完成这一校验。
2.2.1 标签提取与评分规则
我们通常会关注以下几类结构化标签,并通过自然语言处理中的**命名实体识别(NER)**技术进行提取。
|
标签维度 |
提取内容示例 |
价值说明 |
|---|---|---|
|
学历 |
博士、硕士、本科、大专 |
基础教育背景的门槛要求 |
|
工作城市 |
北京、上海、远程 |
地域匹配度,影响候选人稳定性 |
|
技能掌握 |
Java, Python, SQL, PMP |
专业技能的广度与匹配度 |
|
经验年限 |
8年、3年 |
工作经验的积累程度 |
|
岗位级别 |
专家、总监、经理 |
候选人当前的职业层级 |
每个标签都有独立的计分规则,并且这些规则应该是可配置的。以下是一个示例性的评分配置(总分100分):
|
标签项 |
分值权重 |
计分规则示例 |
|---|---|---|
|
学历 |
20分 |
博士=20, 硕士=18, 本科=15, 大专=10, 其他=5 |
|
城市 |
10分 |
目标城市=10, 非目标城市=0 |
|
技能 |
40分 |
(匹配JD技能数 / JD总要求技能数) * 40 |
|
经验 an> |
20分 |
年限达标=20, 差1年=15, 差2年=10, 其他=0 |
|
岗位级别 |
10分 |
级别匹配=10, 低一级=5, 其他=0 |
2.2.2 设计的弹性与价值
这一层的设计精髓在于**“保障基础,但不一刀切”**。它确保了招聘的基础合规性,比如一个明确要求硕士学历的科研岗位,不会推荐一个大专学历的候选人。
但同时,它也允许一定的弹性。例如,一个候选人可能学历只是本科,在学历上丢了5分,但他的项目经验丰富、技能匹配度极高,在其他维度上的高分完全可以弥补学历上的不足。更重要的是,在总分计算中,这一层的权重(30%)低于能力层(50%),这本身就传递了一个信号,我们更看重候选人的真实能力和经验。
这种设计,让那些有实力但某项硬指标稍有欠缺的候选人,依然有机会凭借综合实力进入HR的视野。
2.3 第三层:关键词评分(细节验证,权重20%)
最后一层,我们回归到关键词。但这并非简单的回归,而是作为语义匹配的补充和细节验证,尤其适用于对特定工具、技术或认证有刚性要求的岗位。
2.3.1 “硬证据”的价值
语义匹配有时会过于“宽容”,AI可能觉得两个概念差不多,但对于招聘方来说,这“差不多”之间可能隔着鸿沟。关键词评分就是为了提供“硬证据”,降低这种“看起来差不多、实际没做过”的误判风险。
举个例子:
一个芯片设计的岗位,JD中要求“精通静态时序分析(STA)”。
-
向量模型可能会将简历中“负责芯片后端时序收敛”这样的描述判定为高相关性。
-
关键词评分则会更进一步,去简历中寻找具体的STA工具名称,如“PrimeTime”、“Tempus”等。
如果简历中出现了这些具体的工具名,就在关键词维度上加分,这为候选人“精通STA”的论断提供了强有力的证据。如果没有出现,系统可以不扣分,但会生成一个“风险提示”,提醒HR在面试中重点考察候选人对具体工具的掌握情况。
23.2 知识图谱的应用
为了做好关键词评分,背后需要一个强大的领域知识图谱。这个图谱定义了技能、工具、平台、认证之间的关联关系。
|
核心技能 |
关联关键词(同义词、工具、平台) |
|---|---|
|
静态时序分析(STA) |
PrimeTime, Tempus, ETS, GoldTime |
|
Java后端开发 |
Spring Boot, Spring Cloud, MyBatis, Netty, JVM |
|
项目管理 |
PMP, PRINCE2, Agile, Scrum, Jira, Kanban |
|
云计算 |
AWS, Azure, GCP, Docker, Kubernetes (K8s) |
通过这个知识图谱,关键词评分不再是孤立的词语查找,而是基于知识网络的关联匹配,大大提升了验证的准确性和广度。
2.4 综合评分的合成逻辑
三层评分完成后,通过加权公式合成最终的总分。
总分 = (向量模型分 × 50%) + (结构化标签分 × 30%) + (关键词分 × 20%)
这个权重分配是我们经过多轮实践和效果回归后,得出的一个相对普适的配置。它体现了清晰的设计取舍。
-
50% 权重给能力。这确立了“能力优先”的原则,让真正能干活的人排在前面。
-
30% 权重给门槛。这守住了招聘的底线,保证了基础的合规性和匹配度。
-
20% 权重给细节。这为筛选结果提供了事实依据,增加了HR的信任感。
这套三维加权评分模型,构成了一个从宏观能力到中观门槛,再到微观细节的完整评估体系,让AI简历筛选真正告别了“关键词”的原始时代。
三、🧬 动态权重自适应:让评分体系“懂业务、会进化”

一个固定的评分模型,即使设计得再精妙,也无法应对所有招聘场景。真实的招聘需求是复杂多变的,一个“万金油”式的权重配置,在某些场景下必然会导致结果失真。
3.1 权重为何不能“一刀切”
我们很快在实践中发现了这个问题。
-
招聘一个顶尖销售,过往的业绩、客户资源和行业经验,其重要性远超学历。此时,结构化标签中的“经验”和向量模型理解的“业绩描述”权重应该更高。
-
招聘一个初级研发工程师,扎实的计算机基础、对主流技术栈的掌握程度是核心。此时,关键词评分中的“工具/框架”和结构化标签中的“技能”权重应该被强调。
-
招聘一位事业部总经理,管理经验、战略视野和领导力是关键。向量模型对“战略规划”、“团队建设”等描述的理解,以及结构化标签中的“岗位级别”和“管理年限”应该占据主导。
如果所有岗位都套用50/30/20的权重,筛选结果必然会偏离业务部门的真实需求。因此,评分体系必须具备“随需而变”的灵活性。
3.2 三层自适应机制的构建
为了实现这种灵活性,我们在三维加权模型之上,构建了一个“动态权重自适应框架”。它包含三个层次,让评分体系从一个固定的计算器,进化成一个能理解业务、并持续学习的智能系统。
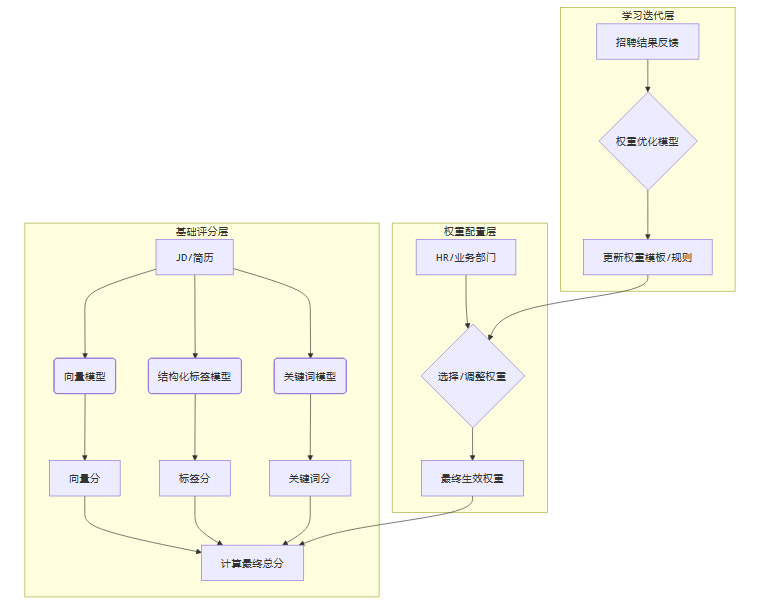
-
基础评分层。这一层保持不变,依然是三维加权评分模型。它提供了稳定、统一的底层评分能力,是整个框架的基石。
-
权重配置层。这是实现“灵活性”的关键。当HR发布一个新职位时,系统不再强制使用默认权重,而是提供多种选择。
-
选择模板。系统预置多种典型岗位的权重模板,如“技术研发岗”、“市场销售岗”、“职能管理岗”等。HR可以一键选用。
-
手动调整。在模板基础上,HR可以通过拖动滑块等方式,微调三个维度的权重,以更贴合当前岗位的特殊要求。
-
复用配置。系统允许HR复用历史上某个成功招聘案例的权重配置,这对于招聘同类型岗位非常高效。
-
-
学习迭代层。这是实现“智能化”的核心。系统不再是一个一次性交付的工具,而是一个能够通过数据反馈持续进化的生命体。
-
反馈信号收集。系统会追踪HR对候选人的操作行为(如查看、收藏、发起面试、发Offer)以及最终的招聘结果(如入职、试用期表现、绩效评级)。
-
权重自动优化。通过机器学习算法(如强化学习或简单的贝叶斯优化),分析哪些权重配置带来了更好的招聘结果(如更高的面试通过率、更优的绩效表现)。基于分析结果,系统会自动优化预置的权重模板,甚至为特定业务线生成定制化的推荐权重。
-
这个三层机制,让评分体系真正“懂业务、会进化”,从根本上解决了“一刀切”的问题。
3.3 典型岗位权重建议
为了让权重配置更具参考性,我们基于实践经验,总结了一套典型岗位的权重建议。这可以作为系统预置模板的初始值。
|
岗位类型 |
向量模型权重 |
结构化标签权重 |
关键词权重 |
核心考量点 |
|---|---|---|---|---|
|
研发技术岗 |
55% |
20% |
25% |
深度能力匹配和具体技术栈掌握是核心,硬性门槛相对次要。 |
|
销售商务岗 |
40% |
40% |
20% |
过往经验(年限、级别、行业)与能力同样重要,业绩描述是关键。 |
|
产品/运营岗 |
50% |
35% |
15% |
能力匹配是基础,工作经验和项目成果的量化指标非常重要。 |
|
中高管岗 |
45% |
40% |
15% |
战略思维、管理经验(级别、年限)和领导力是重点,权重均衡。 |
需要强调,这只是一个起点。最佳的权重配置,一定是在持续的业务实践和数据反馈中,动态演化出来的。
四、🛠️ 工程化落地与治理闭环

一个优秀的模型,从理论到产生稳定的业务价值,中间还隔着漫长的工程化道路。在AI简历筛选的场景下,除了算法本身,我们还必须构建一套完整的工程与治理体系,来保障系统的稳定性、可信性、公平性和持续迭代能力。
4.1 数据与向量底座建设
-
简历解析与结构化。这是所有上层应用的基础。需要一个高精度的简历解析引擎,能准确地从各种格式(PDF, Word, JPG)的简历中提取出教育背景、工作经历、项目经验等模块,并将其结构化。
-
JD标准化。JD的质量直接影响匹配效果。需要引导HR填写更规范、更结构化的JD,或者通过AI辅助生成和优化JD,提取核心能力要求。
-
向量服务。将JD和简历文本向量化的服务,需要考虑性能(QPS、延迟)和成本。对于高频使用的模型,可以本地部署;对于更强大的大模型,则通过API调用。
-
知识库扩充。持续扩充同义词、别名词库和领域知识图谱,是提升模型召回率和覆盖率的关键,这需要算法、业务和运营的长期协作。
4.2 评分与阈值管理
-
打分卡配置后台。为HR或管理员提供一个可视化的后台,可以灵活配置不同岗位的结构化标签计分规则和三维权重。
-
动态阈值自适应。简单的“80分以上”作为面试门槛是不科学的。一个优秀的系统应该采用动态阈值。例如,当简历投递量巨大时,可以只看Top 10%的候选人;当岗位非常紧急且候选人稀少时,可以放宽到Top 30%。阈值应该与简历量、岗位紧急度、历史转化率等因素联动。
4.3 可解释性与信任机制
这是赢得HR信任的“最后一公里”。AI不能是一个黑盒。
-
生成“评分解读卡片”。对于每一份简历的得分,系统都应给出一份可解释的报告。
-
高分原因。展示简历中的哪些段落或句子,与JD的哪些要求在语义上高度匹配。
-
硬性门槛 checklist。清晰列出学历、年限、城市等硬性指标的达标情况。
-
关键技能证据。高亮显示简历中命中的关键工具或技术词。
-
潜在风险提示。指出哪些关键要求在简历中未能找到明确证据,建议面试时关注。
-
通过这种方式,HR能清楚地知道AI为什么给出这个分数,从而建立起对系统的信任。
4.4 稳定性与兜底策略
任何在线服务都可能出现异常。
-
服务降级。当核心的向量模型服务因网络或API问题暂时不可用时,系统不应崩溃。它应该能自动降级,启用“结构化标签+关键词”的双维模型进行兜底评分,保证基础的筛选功能可用。
-
分数归一化。不同模型或不同版本的模型,其输出的分数分布可能不同。需要对所有分数进行归一化处理(如Min-Max Scaling或Z-Score),防止因模型切换导致排序的剧烈波动。
4.5 合规与算法公平性
算法的使用必须遵循法律法规和道德伦理。
-
敏感属性隔离。在简历解析和评分环节,必须严格剔除性别、民族、年龄(在法律允许范围外)、籍贯等敏感属性,确保它们不以任何形式进入评分模型,防止产生歧视。
-
偏见缓解。对学历、院校等可能引发社会争议的标签,可以设置权重上限,或引入“公平性”作为模型优化的目标之一,避免算法过度偏爱某些背景的候选人。
-
审计与申诉通道。系统应记录每一次的评分决策轨迹,便于问题复盘和审计。同时,应为候选人或HR提供对结果提出异议的通道,这是构建负责任AI的必要环节。
46. 评估与持续迭代的闭环
一个AI系统交付不是结束,而是开始。
-
离线评估。在模型上线前,通过历史数据进行离线评估。常用的指标包括。
-
AUC (Area Under Curve)。衡量模型整体的排序能力。
-
Precision/Recall@K。评估在Top K个推荐结果中的准确率和召回率。
-
NDCG (Normalized Discounted Cumulative Gain)。衡量排序质量,越好的结果排在越前面,得分越高。
-
-
在线A/B实验。新模型或新权重上线时,通过A/B测试,在真实流量中比较其与旧版的业务效果,如HR采纳率、面试转化率等。
-
业务指标跟踪。长期跟踪更深层次的业务指标,如面试率、录用率、试用期转正率、入职后一年内的绩效表现等。
-
反馈闭环。将这些在线的、深度的业务指标,作为“学习迭代层”最重要的反馈信号,回灌给权重优化模型,驱动整个评分体系的持续进化,形成一个完整的、数据驱动的治理闭环。
五、🔭 全链路人才管理的未来延展
今天我们深入讨论的简历筛选评分体系,其价值远不止于招聘这一个环节。当它与动态权重、反馈闭环和数据沉淀深度结合后,完全可以延展成为企业全链路人才管理的底层能力。
-
招聘前。基于历史成功招聘的岗位画像和评分模型,系统可以结合公司未来的业务规划,智能预测新的人才缺口,并自动生成高度精准的岗位画像和JD,甚至主动在人才库中激活潜在候选人。
-
招聘中。动态权重与自适应阈值,能确保在不同的招聘阶段(如海量校招、紧急社招、高端猎聘),系统都能提供稳定且高质量的候选人供给,成为业务部门最可靠的“弹药库”。
-
招聘后。这是一个真正激动人心的方向。通过将候选人入职后的绩效数据、晋升记录、培训成果等与招聘时的评分进行关联分析,我们可以回答一些终极问题。
-
当初评分高的候选人,是否真的成为了高绩效员工?
-
哪些维度的评分,对长期绩效的预测性最强?
-
我们是否应该调整模型,更侧重于预测“潜力”而非“当前匹配度”?
-
通过回答这些问题,AI模型将不再仅仅是“匹配”现在,而是在“预测”未来。它将形成一个从“招得准”,到“留得住”,再到“发展好”的完整人才管理闭环,成为支撑企业长期人才战略的、不可或缺的底层基础设施。
总结
回顾全文,我们可以看到,构建一个先进的AI简历筛选系统,其核心挑战在于评分体系的设计与治理。简单地拥抱“大模型”或停留在“关键词”是远远不够的。
我们必须从招聘的本质出发,构建一个能够同时兼顾能力理解、门槛校验和细节验证的“三维加权评分模型”。
我们必须承认业务的复杂性和多变性,通过“动态权重自适应框架”,让模型懂业务、会进化。
我们还必须正视工程的复杂性和治理的重要性,建立起从数据底座到可解释性,再到公平合规的全方位治理闭环。
这条路充满挑战,需要算法、工程、产品和业务的深度融合。但一旦建成,它带来的将不仅仅是招聘效率的提升,更是一种全新的、数据驱动的人才决策能力。这种能力,将帮助企业在激烈的人才竞争中,真正做到“慧眼识珠”,沉淀下最宝贵的战略资产。
📢💻 【省心锐评】
抛弃“关键词”的路径依赖,拥抱“语义+规则”的混合智能。这套三维评分与动态权重体系,是AI筛选从“能用”到“好用”的必经之路,它让AI真正成为HR的决策参谋,而非简单的过滤器。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献237条内容
已为社区贡献237条内容

所有评论(0)