刚开源的VoxCPM火了!零样本克隆声音、上下文感知说话,一行代码就能用
VoxCPM开源语音合成模型引发热议,仅需几秒音频即可高精度克隆人声,完美复刻音色、语气和发音细节。该模型采用端到端扩散自回归架构,支持中英双语零样本克隆和语境感知合成,能自动调整新闻播报、诗歌朗诵等不同场景的语音风格。实测显示其错误率低于1.93%,相似度超72%,在普通显卡上即可速度是实时5倍。项目提供Python库、命令行和网页交互三种使用方式,适合各类用户。目前已在社区引发AI voice
最近语音合成圈炸出个狠角色。
一个叫VoxCPM的开源项目,刚上线就被狂扒——它能仅凭几秒音频,克隆出和原主几乎一模一样的声音,连语气、节奏甚至小口音都复刻得丝毫不差。更绝的是,给段文字,它能自动判断语境:读新闻时字正腔圆,讲笑话时带点俏皮,念散文时放缓节奏。
关键是这玩意儿还特好上手,小白也能分分钟玩起来。
项目地址:https://github.com/OpenBMB/VoxCPM
Demo体验:https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
凭什么说它是「TTS黑马」?
现在的语音合成工具不少,但VoxCPM一出手就显得不太一样。
传统TTS模型大多要先把声音切成「离散小碎块」(类似文字分词),再拼接合成。但这样一来,声音的连贯性容易打折,尤其是复杂语气(比如带哽咽的哭腔、带笑意的调侃)很难还原。
VoxCPM直接跳过了「切分」步骤——它用一种「端到端扩散自回归架构」,像人类说话一样,从文本直接生成连续的语音信号。就像写文章不打草稿直接下笔,流畅度自然甩开一截。
这带来两个「王炸级」能力:
一是零样本语音克隆,逼真到起鸡皮疙瘩
不用训练,给段10秒的参考音频(比如你爱豆的采访片段、家人的日常对话),VoxCPM能扒出声音里的「隐藏密码」:音色、语速、甚至习惯性的停顿。生成的新语音,熟人听了都得愣一下:「这不是本人录的?」
二是上下文感知,说话自带「理解能力」
给它一段《静夜思》,它会自动放慢语速,带点悠远感;给段体育新闻,它会读得铿锵有力;哪怕是夹杂中英文的文本(比如「这个AI项目叫VoxCPM,真的很秀」),也能自然切换语调,不生硬。
更惊喜的是效率。在普通RTX 4090显卡上,生成速度是真实说话速度的5倍多(RTF低至0.17),实时聊天、直播配音都能hold住。
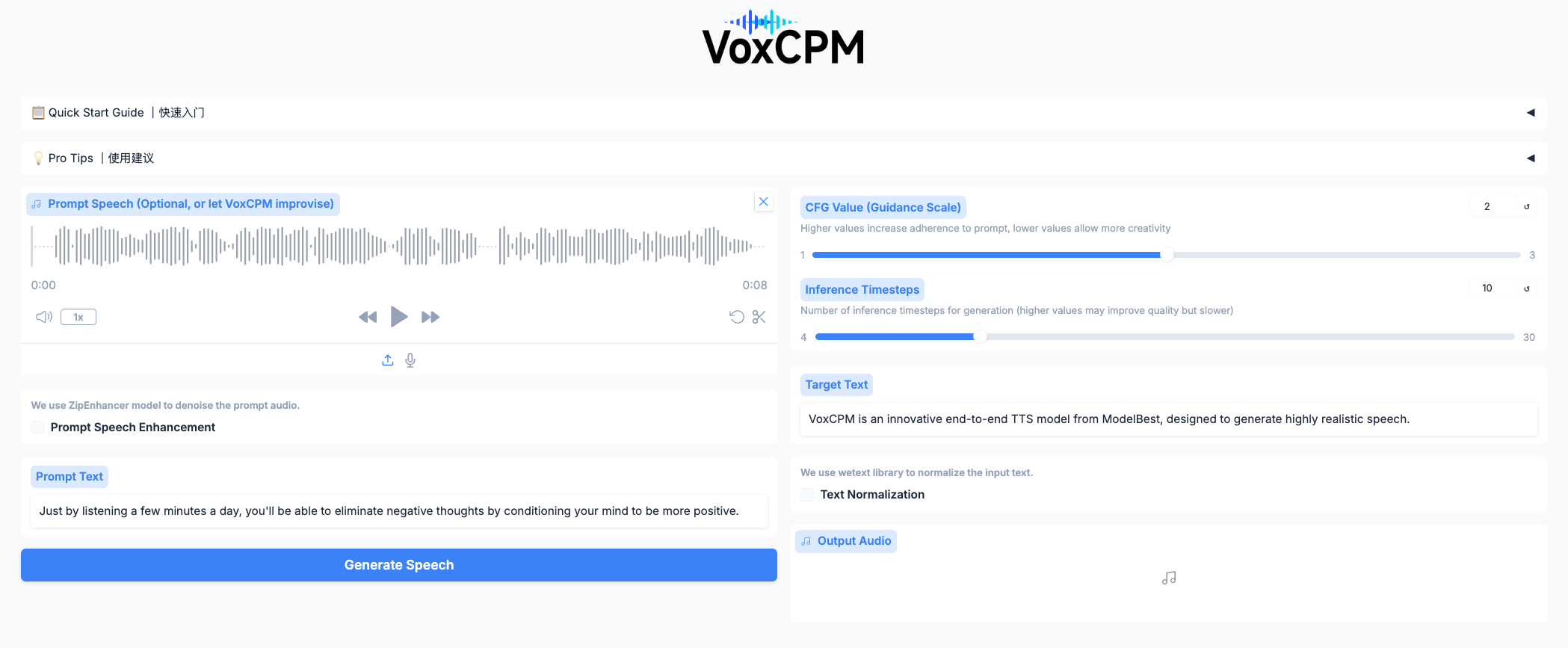
实测:3种玩法,小白也能快速上手
光说不练假把式。VoxCPM的开源团队把门槛压得极低,三种用法,总有一款适合你。
👉 最简单:装个库,一行代码生成语音
先通过pip安装:
pip install voxcpm
然后写几行Python代码,就能让它开口说话。比如生成一段介绍自己的语音:
import soundfile as sf
from voxcpm import VoxCPM
# 加载模型
model = VoxCPM.from_pretrained("openbmb/VoxCPM-0.5B")
# 生成语音(不指定参考音频,用默认音色)
wav = model.generate(
text="VoxCPM是一个超厉害的语音合成模型,能克隆声音还能理解语境哦~",
cfg_value=2.0, # 数值越高,越贴近文本内容
inference_timesteps=10 # 数值越高,音质越好(稍慢)
)
# 保存成音频文件
sf.write("output.wav", wav, 16000)
想克隆声音?加两行参数就行。比如用example.wav里的声音读新文本:
wav = model.generate(
text="我在用VoxCPM克隆声音~",
prompt_wav_path="examples/example.wav", # 参考音频路径
prompt_text="这是参考音频对应的文本" # 参考音频的文字内容
)
👉 更直接:用命令行批量生成
如果不想写代码,直接用命令行也能操作。比如批量处理文本文件里的内容:
# 批量生成语音(每行一个文本)
voxcpm --input 你的文本文件.txt --output-dir 输出文件夹
# 批量克隆声音
voxcpm --input 你的文本文件.txt --output-dir 输出文件夹 \
--prompt-audio 参考音频.wav \
--prompt-text "参考音频的文字内容"
参数还能调:想快点出结果就减小inference-timesteps,想音质更好就调大cfg-value,新手直接用默认值也够用。
👉 最直观:开个网页界面点点鼠标
嫌代码麻烦?运行一句命令启动网页demo:
python app.py
浏览器里会出现一个操作界面:上传参考音频、输入要合成的文本,点「生成」就能听到结果。界面里还能调各种参数,实时试听效果,对小白友好度拉满。
性能硬不硬?数据说话
VoxCPM在公开基准测试Seed-TTS-eval上的表现,已经超过了不少同参数模型。
在英文测试里,它的词错误率(WER)低至1.85%,相似度(SIM)高达72.9%;中文测试更猛,字符错误率(CER)0.93%,相似度77.2%——简单说,生成的语音不仅准,还像真人说的。
更关键的是,它只有0.5B参数,比很多动辄几亿参数的模型轻便得多,普通电脑也能跑起来。
现在社区已经有人用它做了各种有意思的工具:ComfyUI插件(给AI绘画配语音)、WebUI扩展(批量生成角色语音),甚至有人用它克隆自己的声音做播客旁白。
最后说句大实话
VoxCPM虽然厉害,但也有要注意的地方:目前主要支持中英双语,其他语言效果一般;极端长文本可能偶尔「卡壳」;最最重要的是,语音克隆功能别乱用,避免侵犯他人权益。
不过团队已经在迭代了,下版本计划支持更高采样率(音质会更好),后续还可能开放更多可控参数(比如调情绪、语速)。
最后想问:如果有了这工具,你最想克隆谁的声音?用它来做什么?评论区聊聊~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)