收藏这份大模型提示工程宝典:17种核心技巧详解,助你轻松驾驭AI
本文系统介绍大模型提示工程的17种核心技巧,从零样本、少样本等基础方法到多模态CoT、图提示、思维树等高级技术,每种技巧均提供详细解释和实际应用示例。文章展示了提示工程在智能教育、医疗、企业决策等领域的应用价值,总结了未来发展方向,为开发者提供全面指导,帮助提升与大模型的交互效果。
一、零样本提示:激发模型潜能
零样本提示(Zero-shot Prompting)是提示工程的基础,无需提供额外示例,仅通过任务描述即可让模型生成答案。这体现了模型强大的知识迁移能力。
# 示例:文学创作
prompt = "以'秋日的思念'为主题,创作一首现代诗,要求意境深远,语言优美,并运用比喻和拟人修辞手法。"
response = model.generate_text(prompt)
print(response)
在教育领域,零样本提示可用于快速生成知识点解释:
prompt = "解释量子力学中的薛定谔方程,并说明其在微观世界研究中的核心地位。"
response = model.generate_text(prompt)
print(response)
二、少样本提示:精准引导模型
少样本提示(Few-shot Prompting)通过提供少量示例,帮助模型更准确地理解任务要求。在文本分类任务中,这种方法效果显著。
# 情感分析示例
prompt = """
示例 1:评论 '这部电影太精彩了!' 情感:积极
示例 2:评论 '服务态度真差。' 情感:消极
示例 3:评论 '剧情无聊到让我想睡觉。' 情感:消极
现在分析:评论 '这个产品超出预期,质量非常好!' 情感是什么?
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,少样本提示还可用于内容风格模仿:
prompt = """
示例 1:原文 '日出江花红胜火' 改写为现代文:'江边的花朵在朝阳映照下,比火焰还要红艳。'
示例 2:原文 '春眠不觉晓' 改写为现代文:'春天的夜晚舒适的睡眠让人不知不觉睡到天亮。'
现在改写:原文 '床前明月光,疑是地上霜。' 改写为现代文:
"""
response = model.generate_text(prompt)
print(response)
三、思维链提示:深度推理的艺术
思维链(Chain-of-Thought)提示通过逐步展开推理过程,引导模型进行深度思考,特别适用于复杂问题求解。
# 数学问题求解示例
prompt = """
问题:某商店以每个 12 元的价格购进一批玩具,按每个 15 元出售时,每天可卖出 100 个。经市场调研发现,售价每降低 1 元,销量就会增加 20 个。问商店应将售价定为多少元,才能使每天获得的利润最大?
思考步骤:
1. 设售价降低 x 元,则售价为 (15 - x) 元,销量为 (100 + 20x) 个。
2. 进价为 12 元,所以每个玩具利润为 (15 - x - 12) = (3 - x) 元。
3. 总利润 y = 每个利润 × 销量 = (3 - x)(100 + 20x)。
4. 展开公式:y = -20x² + 40x + 300。
5. 这是一个二次函数,其最大值出现在顶点处,顶点横坐标为 -b/(2a) = -40/(2×(-20)) = 1。
6. 所以当 x = 1 时,利润最大,此时售价为 15 - 1 = 14 元。
答案:商店应将售价定为 14 元,此时每天获得的利润最大。
"""
response = model.generate_text(prompt)
print(response)
在实际业务中,思维链提示可用于商业决策分析:
prompt = """
问题:某电商平台计划推出新的会员制度,需要评估不同会员权益组合对用户留存率的影响。假设现有数据表明,提供优惠券的会员方案用户留存率为 60%,提供专属客服的方案留存率为 65%。现在考虑推出同时包含优惠券和专属客服的新方案,预测其用户留存率可能范围,并分析原因。
思考步骤:
1. 分析现有两种方案的特点及对用户的不同吸引力。
2. 考虑用户需求多样性,部分用户更重视价格优惠,部分用户更看重服务质量。
3. 研究市场中其他电商平台类似组合方案的效果数据。
4. 结合用户行为心理学理论,评估组合权益对用户感知价值的提升。
5. 综合各方面因素,预测新方案的用户留存率范围。
答案:
"""
response = model.generate_text(prompt)
print(response)
四、元提示:指导模型自我优化
元提示(Meta Prompting)用于指导模型改进自身生成内容,提升回答质量。
# 回答优化示例
prompt = """
请评价以下回答的质量,并提出改进建议:
问题:解释区块链技术的核心原理。
回答:区块链是一个分布式的数据库,数据以区块形式存储,每个区块包含多个交易记录。它的特点是去中心化,没有单一的控制者。
评价与改进建议:
1. 当前回答过于简略,未提及区块链的关键特性如不可篡改性和共识机制。
2. 可补充具体技术细节,如哈希函数在区块连接中的作用。
3. 增加实际应用场景说明,如比特币中的区块链实现。
改进后的回答:
区块链是一种分布式账本技术,通过去中心化的方式记录交易数据。数据被分组为多个区块,每个区块包含一定数量的交易记录,并通过密码学哈希函数与前一个区块相连,形成链式结构。这种设计使得数据一旦记录就难以篡改。同时,区块链网络中的节点通过共识机制(如工作量证明或权益证明)共同验证交易的有效性,确保系统的安全性和可靠性。以比特币为例,其底层技术就是区块链,所有比特币交易记录都被存储在区块链上,用户可以通过挖矿过程参与区块验证并获得奖励。
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,元提示可用于提升专业领域内容的准确性:
prompt = """
请优化以下医学问答内容,确保符合专业医学标准:
问题:高血压患者如何进行日常饮食管理?
回答:高血压患者应该少吃盐,多吃蔬菜水果,控制脂肪摄入。
优化后回答:
高血压患者的饮食管理应遵循以下原则:1. 限制钠盐摄入,每日不超过 5 克;2. 增加钾元素摄取,多吃富含钾的蔬菜水果(如香蕉、菠菜等);3. 控制饱和脂肪酸摄入,减少动物脂肪食用,选择橄榄油等不饱和脂肪;4. 适量摄入优质蛋白质,如鱼类、豆制品;5. 保持饮食均衡,增加膳食纤维摄入。同时,建议患者遵循得舒饮食(DASH饮食)模式,其已被临床证实可有效降低血压水平。如有特殊情况,请遵医嘱调整饮食方案。
"""
response = model.generate_text(prompt)
print(response)

五、自洽性提示:提升回答可靠性
自洽性(Self-Consistency)提示通过要求模型生成多个答案并验证一致性,提升回答可靠性。
# 多角度验证示例
prompt = """
请从以下三个角度解释牛顿第一定律,并确保所有解释一致且准确:
角度 1:基于物理定义的角度解释牛顿第一定律。
角度 2:结合生活实例的角度解释牛顿第一定律。
角度 3:从与其他物理定律关系的角度解释牛顿第一定律。
角度 1回答:
牛顿第一定律指出,在没有外力作用的情况下,物体将保持静止状态或匀速直线运动状态。这是物体具有惯性的表现,即物体抵抗自身运动状态改变的性质。
角度 2回答:
例如,当行驶中的公交车突然刹车时,乘客会向前倾。这是因为乘客的身体原本随公交车一起运动,当公交车速度突然减慢时,乘客的身体由于惯性仍保持原来的运动状态,从而产生前倾现象。这体现了牛顿第一定律中物体保持原有运动状态的特性。
角度 3回答:
牛顿第一定律是牛顿运动定律的基础,它定义了惯性参考系,为牛顿第二定律(F=ma)和第三定律(作用力与反作用力)提供了前提条件。在惯性参考系中,物体的运动状态改变必须由外力作用引起,这与其他定律共同构成了经典力学的完整体系。
验证一致性:
三个角度的回答都围绕物体在无外力作用下保持原有运动状态这一核心内容展开,角度 1 从理论定义出发,角度 2 通过生活实例直观展示,角度 3 强调其在物理定律体系中的基础地位,三者相互补充且逻辑一致,共同完整地解释了牛顿第一定律。
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,自洽性提示可用于复杂概念的教学:
prompt = """
请从以下三个角度解释人工智能中的神经网络,并确保所有解释一致且易于理解:
角度 1:以计算机科学视角解释神经网络的基本结构和工作原理。
角度 2:用生活中的类比方式解释神经网络的学习过程。
角度 3:从数学角度简要说明神经网络中的核心计算方法。
角度 1回答:
神经网络由大量的人工神经元(节点)按层排列组成,包括输入层、隐藏层和输出层。每个神经元接收前一层传来的信号,经过加权求和、添加偏置后,通过激活函数进行非线性变换,再将结果传递给下一层。网络通过前向传播计算输出结果,并根据输出与实际值的误差,利用反向传播算法调整权重和偏置参数,从而实现对特定任务的学习。
角度 2回答:
可以把神经网络想象成一个不断学习做菜的厨师。最初,厨师(模型)按照随机配方(初始权重)做菜(处理数据),然后品尝(计算误差)并根据反馈调整配料比例(调整权重)。经过反复练习,厨师逐渐掌握如何搭配食材做出符合口味的菜肴,这个过程就类似于神经网络通过训练数据不断优化自身参数以完成特定任务。
角度 3回答:
数学上,神经网络的前向传播过程可表示为:\( z = Wx + b \)(权重矩阵 W 与输入 x 相乘加上偏置 b),然后通过激活函数 \( a = f(z) \) 引入非线性。反向传播则利用链式法则计算损失函数对各参数的梯度,通过梯度下降法更新参数:\( W = W - \eta \frac{\partial L}{\partial W} \),其中 η 是学习率,\( \frac{\partial L}{\partial W} \) 是损失 L 对权重 W 的梯度。
验证一致性:
三个角度的回答共同构建了对神经网络的全面理解。角度 1 提供了计算机科学领域的结构和流程描述,角度 2 通过生活类比使抽象概念形象化,角度 3 则从数学层面揭示了核心运算机制。三者相互呼应,形成完整的知识体系,验证了回答的自洽性。
"""
response = model.generate_text(prompt)
print(response)
六、生成知识提示:拓展模型知识边界
生成知识(Generate Knowledge)提示用于引导模型生成特定领域的专业知识,特别适用于专业领域的内容创作。
# 专业知识生成示例
prompt = """
以量子计算专家身份,解释量子比特(qubit)与经典比特(bit)的区别,包括但不限于信息存储方式、运算逻辑、应用场景等方面,并提供实际案例说明。
回答:
量子比特(qubit)与经典比特(bit)存在本质区别:
1. 信息存储方式:
- 经典比特是二进制的基本单位,只能处于 0 或 1 的确定状态。
- 量子比特基于量子力学原理,可处于 0 和 1 的叠加态,即同时表示 0 和 1 的概率幅度组合。例如,一个量子比特可以表示为 \( |ψ\rangle = α|0\rangle + β|1\rangle \),其中 α 和 β 是复数概率幅,满足 |α|² + |β|² = 1。
2. 运算逻辑:
- 经典比特运算遵循传统逻辑门(如与、或、非)规则,一次只能处理确定的 0 或 1 状态。
- 量子比特利用量子门进行操作,可同时对叠加态中的所有可能状态进行运算。例如,对 n 个量子比特进行一次操作,可同时处理 \( 2^n \) 种状态组合,这使得量子计算在特定任务中具有并行计算优势。
3. 应用场景:
- 经典比特适用于常规计算任务,如文档处理、网页浏览等确定性操作。
- 量子比特适用于需要处理大规模组合问题或模拟量子系统的场景。例如,在密码学领域,肖尔算法(Shor's algorithm)利用量子计算可在多项式时间内分解大整数,破解基于 RSA 的加密体系;在化学领域,通过量子模拟可精确计算分子结构和反应过程,加速新材料研发。谷歌的量子优越性实验展示了量子计算机在特定随机采样任务中超越经典超级计算机的能力,体现了量子比特的独特优势。
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,生成知识提示可用于专业培训材料的快速生成:
prompt = """
以高级数据分析师身份,撰写一篇关于时间序列分析中 ARIMA 模型的讲解文章,内容包括模型原理、参数选择方法、诊断检验步骤以及实际案例分析,要求语言专业且通俗易懂,适合初学者学习。
文章标题:ARIMA 模型:时间序列分析的核心工具
文章内容:
ARIMA 模型(自回归积分滑动平均模型)是时间序列分析中广泛应用的预测模型,特别适用于处理非季节性时间序列数据。本文将从模型原理、参数选择、诊断检验到实际案例,全面讲解 ARIMA 模型的应用。
一、模型原理
ARIMA 模型基于三个核心概念构建:自回归(AR)、差分(I)和平滑移动平均(MA)。其数学表达式为:
\( ARIMA(p, d, q) \)
其中:
- p 表示自回归项数,模型假设当前值与前面 p 个历史值存在线性关系。
- d 表示差分次数,用于将非平稳时间序列转换为平稳序列。例如,d=1 表示进行一次差分运算:\( y'_t = y_t - y_{t-1} \)
- q 表示移动平均项数,模型考虑过去 q 个预测误差对当前值的影响。
ARIMA 模型首先通过差分操作使序列平稳,然后结合自回归和移动平均部分,建立线性方程预测未来值。
二、参数选择方法
1. 确定差分次数 d:通过观察时间序列的自相关函数(ACF)和偏自相关函数(PACF)图,以及进行 ADF 检验,判断序列是否平稳。若非平稳,则进行差分操作直至序列平稳。
2. 确定自回归项数 p:通常参考 PACF 图,显著的滞后阶数即为 p 的候选值。
3. 确定移动平均项数 q:通常参考 ACF 图,显著的滞后阶数即为 q 的候选值。
4. 最终通过比较不同参数组合下的 AIC(赤池信息准则)或 BIC(贝叶斯信息准则)值,选择最优参数组合。
三、诊断检验步骤
1. 检查残差是否为白噪声:通过 Ljung-Box 检验,若 p 值大于显著性水平(如 0.05),表明残差无自相关性,模型拟合良好。
2. 分析标准化残差的正态性:使用 Q-Q 图判断残差是否近似正态分布。
3. 评估模型预测能力:通过时间序列的训练集和测试集划分,计算预测误差指标(如 MAE、RMSE),验证模型的泛化能力。
四、实际案例分析
案例背景:某公司产品月度销售数据(共 60 个月),数据呈现上升趋势且存在一定波动。
1. 数据预处理:绘制时间序列图,观察到明显上升趋势,进行一次差分(d=1)后序列趋于平稳。
2. 参数选择:ACF 图显示滞后 2 阶显著,PACF 图显示滞后 1 阶显著,初步确定 p=1, q=2。通过比较不同参数组合的 AIC 值,最终选定 ARIMA(1,1,2) 模型。
3. 模型拟合与诊断:拟合模型后,Ljung-Box 检验 p 值为 0.12(大于 0.05),表明残差无自相关性;Q-Q 图显示残差近似正态分布。
4. 模型预测:使用选定模型对接下来 6 个月的销售量进行预测,预测结果显示合理的增长趋势,预测区间提供了置信范围。实际后续销售数据验证了预测的准确性,MAE 为 12.3,表明模型具有较好的预测性能。
通过本案例可以看出,ARIMA 模型在处理具有趋势特征的时间序列数据时,能够有效提取数据中的规律并进行可靠预测。掌握 ARIMA 模型的原理与应用步骤,将为时间序列分析奠定坚实基础。随着经验积累,可进一步探索 SARIMA(季节性 ARIMA)等扩展模型,应对更复杂的数据模式。
"""
response = model.generate_text(prompt)
print(response)
七、检索增强生成:融合外部信息
检索增强(Retrieval Augmented Generation)生成通过结合外部数据,提升模型回答准确性,特别适用于需要最新信息或专业知识的场景。
# 科技论文解读示例
prompt = """
根据以下科技论文摘要,总结研究主要贡献,并指出其潜在应用场景:
论文标题:《基于深度学习的医学影像诊断新方法》
摘要内容:本研究提出一种基于卷积神经网络(CNN)和注意力机制的混合模型,用于胸部 X 光片中肺炎的自动检测。该模型通过在公共数据集上训练,实现了 92.3% 的准确率,较传统方法提升 15%。同时,注意力机制使模型能够自动定位图像中关键病灶区域,为医生提供辅助诊断依据。
总结:
该研究的主要贡献包括:1. 提出 CNN 与注意力机制相结合的混合模型,有效提升了肺炎检测的准确性;2. 通过注意力机制实现病灶区域自动定位,增强了模型的可解释性。其潜在应用场景主要在医疗影像诊断领域,可作为辅助诊断工具帮助医生快速筛查肺炎病例,尤其在医疗资源有限的地区具有重要价值。
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,检索增强生成可用于智能客服系统:
prompt = """
根据以下产品说明书内容,回答用户关于产品功能的咨询:
产品说明书(部分内容):
本智能音箱支持以下功能:
1. 语音控制音乐播放:可通过语音指令播放各大音乐平台的歌曲、专辑、歌单。
2. 智能家居控制:兼容市面上 200+ 品牌的智能设备,实现灯光调节、电器开关等操作。
3. 信息查询:提供实时天气、新闻、股票等资讯查询服务。
4. 语音助手功能:设置提醒、闹钟、日程安排等。
用户咨询:这款智能音箱能不能控制窗帘?
回答:
根据产品说明书,本智能音箱支持控制兼容的智能家居设备。经查询兼容品牌列表,若您的窗帘属于支持的智能窗帘品牌(如 Aqara、飞利浦等),则可以通过智能音箱进行控制。建议您检查窗帘设备的品牌和型号是否在兼容列表中,或通过智能音箱的智能家居 App 进行设备配对测试。
"""
response = model.generate_text(prompt)
print(response)
八、自动提示工程师:智能优化提示
自动提示工程师(Automatic Prompt Engineer)借助算法自动优化提示语句,提升模型响应质量。
# 提示优化示例
prompt = """
优化以下提示语句,使其更易引导模型生成符合要求的答案:
原提示:'请写一篇关于人工智能的短文。'
优化后提示:
你的任务是撰写一篇结构清晰、内容丰富的短文,主题为 '人工智能:改变未来的力量'。文章需要包括以下部分:
1. 引言:介绍人工智能的定义及其发展历程中的关键里程碑。
2. 主体:
- 当前人工智能在医疗、交通、教育等领域的具体应用案例。
- 人工智能技术(如深度学习、自然语言处理)如何推动各行业发展。
- 面临的挑战与伦理问题,如数据隐私、算法偏见。
3. 结论:展望人工智能未来发展趋势,并提出平衡技术发展与社会责任的建议。
字数控制在 800 字左右,语言风格正式且流畅,适合科技杂志读者群体。
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,自动提示工程师可用于提升内容创作效率:
prompt = """
优化以下提示语句,使其能引导模型生成高质量的商业分析报告:
原提示:'帮我分析这个公司的市场竞争力。'
优化后提示:
你的任务是撰写一份专业的市场竞争力分析报告,目标公司为 '科技先锋有限公司'。报告应包含以下内容:
1. 公司概况:简要介绍公司业务范围、市场份额、主要产品线。
2. 竞争优势分析:
- 技术优势:评估公司的专利数量、研发投入占比、核心技术水平。
- 人才优势:分析公司研发团队规模、行业资深专家数量、员工教育背景。
- 市场优势:考察品牌知名度、客户忠诚度、销售渠道覆盖范围。
3. 竞争劣势分析:
- 技术瓶颈:识别公司在关键技术领域的不足。
- 经营风险:评估供应链稳定性、财务健康状况、政策环境影响。
4. 竞争对手对比:选择 3 家主要竞争对手,从产品功能、价格策略、市场定位等维度进行对比分析。
5. 未来展望:基于行业趋势预测公司未来 3-5 年的竞争力变化,并提出战略建议。
报告风格需正式、客观,数据引用需注明来源,分析需基于公开信息,字数控制在 3000 字左右。
"""
response = model.generate_text(prompt)
print(response)
九、多模态 CoT:融合多模态思维链
多模态 CoT(Multimodal CoT)结合文本、图像等多模态信息,进行复杂推理,特别适用于需要综合多种信息源的任务。
# 产品分析示例
prompt = """
根据提供的产品图片和用户评价文本,分析该智能手表的市场竞争力:
产品图片:[图片链接](图片显示手表具有时尚外观设计,配备彩色触摸屏,多个功能按钮)
用户评价:
1. '电池续航能力强,一次充电可用 7 天。'
2. '健康监测功能全面,能准确记录心率、血氧、睡眠数据。'
3. '运动模式丰富,支持 20 种运动类型,数据记录详细。'
4. '操作系统流畅,应用更新及时。'
5. '防水性能良好,游泳时也可佩戴。'
分析要点:
1. 功能优势:结合图片中的功能按钮和用户评价中的功能描述,分析其功能覆盖范围。
2. 设计缺陷:根据图片中的外观设计和用户未提及的方面,推测可能的设计不足。
3. 价格竞争力:参考用户评价中隐含的价格感知(如无抱怨则可能定价合理)。
4. 目标用户群体:综合外观设计和功能特点,推断主要目标客户。
分析结果:
该智能手表在功能方面表现出色,健康监测和运动追踪功能全面且准确,电池续航能力强,操作流畅,防水性能良好。从图片看,外观设计时尚,适合追求健康生活的年轻消费者和运动爱好者。可能的缺陷在于,图片显示的屏幕尺寸相对较小,可能限制了部分功能的可视化效果。用户评价未提及价格问题,推测其定价在同类产品中具有竞争力。总体而言,该产品在健康监测和运动追踪领域具有较强的市场竞争力,适合关注健康和运动的消费群体。
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,多模态 CoT 可用于智能安防系统:
prompt = """
根据监控摄像头拍摄的视频片段和现场环境描述,分析异常行为:
视频片段描述:在商场入口处,一名男子反复徘徊,不时查看周围监控设备,手中持有遮挡物。
现场环境:商场入口人流较大,背景噪音为正常购物环境声音。
其他信息:该男子未携带任何商场购物袋,与同行人员无交流。
分析步骤:
1. 视觉分析:观察男子行为模式是否符合正常购物者特征(如目的明确、行动自然)。
2. 环境适应性分析:结合商场入口人流特点,判断其停留时间和行为频率是否异常。
3. 风险评估:根据其遮挡监控设备的动作,评估潜在安全威胁等级。
4. 建议措施:提出安防人员是否需要进一步核实或干预的建议。
分析结果:
该男子行为模式与正常购物者存在明显差异,其在商场入口反复徘徊且遮挡监控设备的行为符合可疑人员特征。结合现场环境,其长时间停留且无购物行为进一步增加了可疑程度。建议安防人员对该男子进行重点关注,可安排人员上前询问其目的,或通过其他监控手段验证其行动轨迹,确保商场安全。
"""
response = model.generate_text(prompt)
print(response)
十、图提示:利用图结构引导推理
图提示(Graph Prompting)通过图结构组织信息,引导模型进行系统性分析,特别适用于复杂系统分析任务。
# 知识图谱构建示例
prompt = """
以知识图谱形式展示 '人工智能在医疗领域应用' 的主要分支,并简要说明各分支核心技术:
节点 1:人工智能
节点 2:医疗影像诊断
节点 3:辅助手术机器人
节点 4:疾病预测
节点 5:药物研发
节点 6:个性化治疗
节点 7:医疗数据分析
连接关系:
人工智能 → 医疗影像诊断
人工智能 → 辅助手术机器人
人工智能 → 疾病预测
人工智能 → 药物研发
人工智能 → 个性化治疗
人工智能 → 医疗数据分析
医疗影像诊断 → 疾病预测
药物研发 → 个性化治疗
各分支核心技术说明:
1. 医疗影像诊断:基于深度学习的卷积神经网络(CNN)用于 X 光、CT、MRI 等影像分析,自动识别病灶。
2. 辅助手术机器人:结合计算机视觉和实时传感器反馈,机器人辅助医生进行高精度手术操作。
3. 疾病预测:利用机器学习算法(如随机森林、神经网络)分析患者病史、基因数据,预测疾病发生风险。
4. 药物研发:通过生成式对抗网络(GAN)和分子模拟技术,加速新药发现和筛选过程。
5. 个性化治疗:根据患者基因组信息、疾病亚型,利用决策树模型制定精准治疗方案。
6. 医疗数据分析:运用自然语言处理(NLP)技术处理电子病历,挖掘医疗知识,优化医院运营效率。
7. 医疗影像诊断与疾病预测关联:影像特征可作为疾病预测模型的输入变量,提高预测准确性。
8. 药物研发与个性化治疗关联:新研发的药物可直接应用于个性化治疗方案中,形成研发 - 应用闭环。
知识图谱展示:
人工智能
│
├─医疗影像诊断(CNN 技术)
│ └─疾病预测(提供影像特征输入)
├─辅助手术机器人(计算机视觉与传感器技术)
├─疾病预测(机器学习算法)
├─药物研发(GAN 与分子模拟)
│ └─个性化治疗(精准治疗方案)
├─个性化治疗(基因组与决策树模型)
└─医疗数据分析(NLP 与知识挖掘技术)
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,图提示可用于企业战略分析:
prompt = """
构建 '新能源汽车行业竞争格局' 知识图谱,包括以下节点和关系:
节点类型:
1. 企业(如特斯拉、比亚迪、蔚来等)
2. 技术(如电池技术、自动驾驶技术、智能座舱技术)
3. 市场(如中国市场、欧洲市场、美国市场)
4. 政策(如补贴政策、排放标准、基础设施建设政策)
5. 供应链(如电池原材料、芯片供应、制造设备)
连接关系:
企业 - 技术(掌握/研发中)
企业 - 市场(主要销售区域)
企业 - 政策(受影响程度)
企业 - 供应链(依赖程度)
技术 - 市场(需求程度)
政策 - 市场(促进/限制关系)
供应链 - 企业(供应稳定性)
图谱说明:
以特斯拉为例:
特斯拉 → 电池技术(掌握高能量密度电池技术)
特斯拉 → 自动驾驶技术(研发 FSD 技术)
特斯拉 → 中国市场(主要销售区域之一)
特斯拉 → 美国补贴政策(受影响程度高)
特斯拉 → 电池原材料供应链(依赖程度较高)
电池技术 → 各市场(高需求程度)
美国补贴政策 → 美国市场(促进关系)
电池原材料供应链 → 特斯拉(供应稳定性中等,受国际局势影响)
通过该知识图谱,可直观展示新能源汽车行业各要素之间的复杂关系,为企业战略决策、市场竞争分析提供系统性视角。例如,企业可识别关键技术瓶颈、评估政策变化影响、优化供应链布局等。
"""
response = model.generate_text(prompt)
print(response)
十一、方向性刺激提示:精准引导模型思考
方向性刺激(Directional Stimulus)提示通过明确方向指引,聚焦模型思考路径,适用于需要深度分析特定因素的场景。
# 市场分析示例
prompt = """
从消费者心理角度分析新能源汽车市场增长原因,重点分析以下因素:
1. 环保意识提升:分析消费者环保观念变化如何影响购车选择,包括对碳排放的关注、绿色消费理念普及等方面。
2. 政策补贴影响:探讨政府补贴、购置税减免、免费停车等优惠政策对消费者决策的刺激作用。
3. 技术进步带来的成本下降:研究电池技术进步、规模化生产如何降低新能源汽车价格,提高性价比。
分析要点:
1. 消费者认知变化:通过市场调研数据说明消费者对新能源汽车接受度提升的过程。
2. 决策因素权重:评估不同因素在消费者购车决策中的重要性排序。
3. 行为转变障碍:分析仍有部分消费者 hesitation 的原因,如续航里程焦虑、充电设施不足等。
分析结果:
新能源汽车市场增长主要受消费者环保意识觉醒驱动,年轻一代消费者尤其关注汽车的碳足迹和能源利用效率。政府补贴显著降低了购车门槛,据调查数据显示,约 68% 的消费者表示补贴是其选择新能源汽车的重要因素。同时,电池技术突破使续航里程从早期的 100-200 公里提升至 400-600 公里, coupled with 电池成本下降 70%(2010-2020 年),使新能源汽车性价比大幅提升。尽管如此,仍有约 24% 的潜在消费者因充电设施不足和续航里程焦虑而持观望态度。综合来看,环保意识、政策激励和技术进步共同塑造了新能源汽车市场的繁荣,但要实现全面普及仍需解决基础设施和电池技术瓶颈问题。
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,方向性刺激提示可用于社会现象研究:
prompt = """
分析社交媒体对青少年心理健康的影响,重点从以下三个方面展开:
1. 社交比较机制:探讨青少年在社交媒体上与他人比较外貌、生活方式、成就等方面的心理影响,包括自我价值感变化、焦虑水平波动等。
2. 信息过载与注意力分散:研究海量信息对青少年注意力持续时间、深度思考能力的长期影响,以及由此引发的心理压力。
3. 网络欺凌现象:分析网络欺凌在社交媒体环境中的独特表现形式、传播特点,以及对受害者心理健康的短期和长期损害。
分析要点:
1. 行为模式变化:通过心理学研究数据说明青少年社交媒体使用习惯与心理状态的相关性。
2. 年龄阶段差异:区分不同年龄段青少年(如 12-15 岁、16-18 岁)受影响的侧重点。
3. 预防与干预措施:基于分析结果提出家庭、学校、平台三方协作的心理健康保护建议。
分析结果:
社交媒体的社交比较机制使青少年频繁暴露于理想化形象中,导致 34% 的青少年出现自我价值感下降,特别是在外貌和生活成就方面。信息过载使青少年平均注意力持续时间从 2012 年的 12 秒下降至 2022 年的 8 秒,长期处于碎片化信息处理状态,削弱了深度思考能力和情绪调节能力。网络欺凌现象在社交媒体匿名性和广泛传播性加持下,对受害者造成更严重的心理创伤,约 21% 的青少年报告曾遭受网络欺凌,其抑郁风险比未遭受者高 2.3 倍。针对这些影响,建议家庭限制青少年过度使用社交媒体,学校开展数字素养教育,平台加强内容监管和受害者保护机制,共同构建健康网络环境。
"""
response = model.generate_text(prompt)
print(response)
十二、程序辅助语言模型:增强逻辑性
程序辅助(Program-Aided Language Models)通过引入编程逻辑,提升模型处理复杂任务能力,特别适用于需要精确计算和逻辑推理的场景。
# 数学问题编程求解示例
prompt = """
编写 Python 函数计算斐波那契数列第 n 项,并解释递归与动态规划实现的优缺点:
递归实现:
def fibonacci_recursive(n):
if n <= 1:
return n
return fibonacci_recursive(n-1) + fibonacci_recursive(n-2)
动态规划实现:
def fibonacci_dp(n):
if n <= 1:
return n
dp = [0] * (n+1)
dp[1] = 1
for i in range(2, n+1):
dp[i] = dp[i-1] + dp[i-2]
return dp[n]
优缺点分析:
递归实现优点:代码简洁直观,直接映射数学定义。
递归实现缺点:存在大量重复计算,时间复杂度高达 O(2^n),对于较大 n 计算效率极低。
动态规划实现优点:通过记录已计算结果避免重复运算,时间复杂度降低至 O(n),空间复杂度 O(n)。
可进一步优化为 O(1) 空间复杂度的迭代版本:
def fibonacci_iterative(n):
if n <= 1:
return n
a, b = 0, 1
for _ in range(2, n+1):
a, b = b, a + b
return b
动态规划(迭代版)优点:在保持 O(n) 时间复杂度的同时,将空间复杂度优化至 O(1),适用于大数据场景。
测试示例:
计算第 10 项:
fibonacci_recursive(10) → 输出 55
fibonacci_dp(10) → 输出 55
fibonacci_iterative(10) → 输出 55
计算第 50 项:
递归实现因计算量过大不建议使用。
fibonacci_dp(50) → 输出 12586269025
fibonacci_iterative(50) → 输出 12586269025
性能对比:
对于 n=35,递归实现耗时约 15 秒,而动态规划实现仅需 0.0001 秒。由此可见,动态规划在处理大规模问题时具有显著优势。
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,程序辅助语言模型可用于数据处理任务:
prompt = """
编写 Python 函数处理销售数据,实现以下功能:
1. 读取 CSV 文件中的销售记录(包含日期、产品 ID、销售量、单价等字段)。
2. 按产品 ID 聚合数据,计算每种产品的总销售量、平均单价、总销售额。
3. 将结果保存为新的 CSV 文件,并绘制总销售额前 10 名产品的柱状图。
函数实现:
import pandas as pd
import matplotlib.pyplot as plt
def process_sales_data(input_file, output_file, chart_file):
# 读取数据
df = pd.read_csv(input_file)
# 数据清洗:去除缺失值
df = df.dropna()
# 转换数据类型
df['销售量'] = df['销售量'].astype(int)
df['单价'] = df['单价'].astype(float)
# 计算总销售额
df['总销售额'] = df['销售量'] * df['单价']
# 按产品 ID 聚合
result = df.groupby('产品 ID').agg({
'销售量': 'sum',
'单价': 'mean',
'总销售额': 'sum'
}).reset_index()
# 保存结果
result.to_csv(output_file, index=False)
# 绘制柱状图
top10 = result.nlargest(10, '总销售额')
plt.figure(figsize=(12, 8))
plt.bar(top10['产品 ID'], top10['总销售额'])
plt.xlabel('产品 ID')
plt.ylabel('总销售额')
plt.title('总销售额前 10 名产品')
plt.savefig(chart_file)
plt.close()
return result
# 示例使用
process_sales_data('sales_data.csv', 'processed_sales.csv', 'top_products.png')
函数优点:
1. 集成数据读取、清洗、聚合、可视化全流程,提升工作效率。
2. 利用 Pandas 库高效处理大规模数据,支持快速聚合计算。
3. 自动生成可视化图表,直观展示业务重点,辅助决策。
实际应用案例:
某电商企业使用该函数处理月度销售数据,成功识别出贡献 72% 销售额的 15 款产品,为库存管理和营销策略调整提供了数据支持。同时,通过定期生成的销售图表,业务团队能及时发现销售趋势变化,提前布局促销活动。
"""
response = model.generate_text(prompt)
print(response)
十三、反思提示:引导模型自我审视
反思(Reflexion)提示鼓励模型对自身输出进行批判性思考,提升回答质量。
# 回答改进示例
prompt = """
回顾你刚才生成的关于 '未来城市规划' 的建议,思考是否存在以下问题:
1. 忽视了可持续发展因素,如能源利用效率、碳排放控制。
2. 对技术应用过度乐观,未考虑技术实施的潜在风险和社会接受度。
3. 缺乏对社会公平性的考虑,如低收入群体的居住需求、公共服务均等化。
改进后的建议:
原建议重点强调了智能化交通系统和垂直农场等技术方案,但在可持续发展、技术可行性和社会公平方面存在不足。改进后的建议如下:
1. 可持续能源整合:规划应优先考虑可再生能源的广泛应用,如在建筑表面集成太阳能板、利用地热能供暖系统。所有新建公共设施必须达到绿色建筑标准,能源利用效率较传统建筑提升 40% 以上。同时,建立城市能源监测平台,实时优化能源分配,降低碳排放。
2. 技术实施评估框架:对于智能交通系统、自动化物流配送等技术应用,建立包含技术成熟度、成本效益、社会影响的综合评估体系。例如,在推广自动驾驶公共交通前,需进行为期 2 年的小规模试点,收集安全性和公众反馈数据,确保技术可靠且被广泛接受。
3. 社会包容性设计:在城市更新项目中,确保 30% 的住宅为可负担住房,并配套完善的基础公共服务设施。采用混合社区规划模式,避免不同收入群体的空间隔离。公共服务设施(如学校、医疗中心、公园)按照人口密度和服务半径进行均衡布局,通过大数据分析确保服务覆盖公平性。
4. 公众参与机制:建立多渠道的公众参与平台,特别是在涉及社区改造和公共服务调整时,提前 6 个月开展意见征集,确保规划方案反映多元利益诉求。对于低收入群体,提供专门的咨询和支持服务,帮助其理解和参与规划过程。
5. 动态调整规划:考虑到未来技术和社会变化的不确定性,城市规划应采用模块化和可迭代的设计思路。每 3 年对规划进行一次全面评估,根据新技术发展、人口结构变化和政策调整进行优化,保持规划的适应性和前瞻性。
通过以上改进,建议方案在技术、社会和环境维度实现了更平衡的发展视角,同时增强了实际操作性和社会包容性。
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,反思提示可用于提升专业建议的质量:
prompt = """
反思之前生成的投资组合建议,检查是否存在以下问题:
1. 风险评估不全面,未充分考虑地缘政治风险和行业周期性风险。
2. 对新兴市场资产配置比例过高,可能超出一般投资者风险承受能力。
3. 缺乏对投资时间 horizon 的明确分类建议,未区分短期、中期、长期投资目标。
改进后的投资组合建议:
原建议侧重于资产多元化和历史收益分析,但在风险评估、新兴市场配置和时间 horizon 考量方面存在不足。改进后的建议如下:
1. 风险评估体系:
- 在原有市场风险、信用风险评估基础上,增加地缘政治风险评估模块,通过跟踪国际关系紧张指数、贸易政策变化等指标,动态调整投资组合中受地缘政治影响较大资产(如能源、科技股)的权重。
- 引入行业周期性分析,根据经济周期不同阶段(复苏、扩张、衰退、萧条),调整对利率敏感型行业(如房地产、公用事业)和增长型行业(如科技、消费)的配置比例,降低周期性波动对组合的影响。
2. 新兴市场配置优化:
- 根据投资者风险承受能力测试结果,将新兴市场资产配置比例设置为阶梯式:保守型投资者不超过 10%,平衡型投资者 15-20%,积极型投资者 25-30%。同时,建议通过投资新兴市场 ETF 或共同基金分散单一国家风险,而非直接投资个股。
- 增加新兴市场投资的风险对冲工具,如购买相关货币对冲基金或信用违约互换(CDS)产品,降低政治动荡和货币贬值风险。
3. 时间 horizon 分类建议:
- 短期目标(1-3 年):以资本保值和流动性为目标,配置高比例的现金等价物(如货币基金)、短期债券,新兴市场资产配置不超过 5%。
- 中期目标(3-7 年):平衡增长与风险,增加股票配置至 50-60%,其中新兴市场占比 15-20%,同时配置一定比例的对冲基金降低波动。
- 长期目标(7 年以上):追求资产增值,股票配置可达 70-80%,新兴市场占比 25-30%,可适当增加私募股权和基础设施投资以提高预期收益,同时承受较高波动。
4. 定期再平衡机制:
- 每季度评估投资组合表现与目标资产配置偏差,当某类资产权重偏离目标 5% 以上时,进行再平衡操作。特别关注地缘政治事件后的资产重新定价,作为调整新兴市场头寸的时机。
5. 投资者教育模块:
- 针对新兴市场投资特点,为投资者提供专门的风险教育材料,包括历史危机案例分析(如 1997 年亚洲金融危机、2018 年阿根廷货币危机)和风险指标解读(如主权信用评级、外汇储备水平)。
通过以上改进,投资组合建议在风险控制、资产配置合理性以及个性化服务方面得到显著提升,更好地匹配不同投资者的需求和市场环境变化。
"""
response = model.generate_text(prompt)
print(response)
十四、ReAct:结合反应与行动
ReAct 技术通过模拟人类解决问题时的反应与行动过程,提升模型任务执行能力,特别适用于多步骤复杂任务。
# 智能助手任务示例
prompt = """
模拟一个智能助手帮助用户规划欧洲十日游的过程,包括需求收集、方案生成、调整优化等阶段:
用户需求:参观历史文化景点、体验当地美食、预算中等。
阶段 1:需求收集
助手:您好!很高兴为您规划欧洲十日游。除了您提到的参观历史文化景点和体验美食外,还有其他偏好吗?比如是否偏好某国文化,或有特殊旅游方式要求(自由行/跟团)?
用户:我喜欢意大利和法国文化,希望以自由行为主,但部分城市可考虑半自由行团。
助手:了解了。您计划的旅游时间是什么季节?这对景点开放情况和美食体验有影响。
用户:计划在秋季出行,9 月下旬到 10 月上旬。
阶段 2:方案生成
助手:根据您的需求,我为您设计了以下初步行程:
第 1-3 天:罗马(意大利)
- 参观古罗马斗兽场、万神殿等历史遗迹。
- 品尝正宗意大利面和提拉米苏。
第 4-5 天:佛罗伦萨(意大利)
- 观赏乌菲兹美术馆文艺复兴艺术作品。
- 体验托斯卡纳地区美食,如佛罗伦萨牛排。
第 6-7 天:威尼斯(意大利)
- 游览圣马可广场,乘坐贡多拉游船。
- 品尝墨鱼面和意式海鲜饭。
第 8-9 天:巴黎(法国)
- 参观卢浮宫、埃菲尔铁塔。
- 体验法式美食,如法棍、马卡龙、鹅肝。
第 10 天:尼斯(法国)
- 在天使湾漫步,享受地中海风情。
- 品尝普罗旺斯特色美食。
预算分配:
交通:选择廉价航空和当地火车,预算 800 欧元。
住宿:中等价位民宿,每晚 80-120 欧元,共 9 晚约 900 欧元。
餐饮:每天 50-70 欧元,共 10 天约 600 欧元。
门票:历史景点门票约 200 欧元。
总计预算约 2500 欧元左右。
阶段 3:方案调整
助手:请问这个初步方案是否符合您的期望?是否有需要调整的地方,比如增加某个城市停留时间或更换景点?
用户:能否在巴黎多待一天,减少尼斯的行程?我对尼斯不太感兴趣。
助手:可以调整。那威尼斯的两天是否需要保留,或者您有其他偏好城市?
用户:威尼斯可以保留一天,我想增加米兰一天,对时尚感兴趣。
助手:了解。调整后方案如下:
第 1-3 天:罗马
第 4-5 天:佛罗伦萨
第 6 天:威尼斯
第 7-8 天:米兰
第 9-10 天:巴黎
这样既增加了您感兴趣的米兰,又延长了巴黎的停留时间。同时,我会根据城市间交通时间和您的自由行偏好,优化每日具体行程安排。
阶段 4:细节优化与确认
助手:根据调整后的行程,我为您预订了以下交通和住宿(示例):
交通:
- 罗马 → 佛罗伦萨:意大利高速火车(约 1.5 小时)
- 佛罗伦萨 → 威尼斯:火车(约 2 小时)
- 威尼斯 → 米兰:火车(约 2.5 小时)
- 米兰 → 巴黎:廉价航空(约 1 小时 45 分钟)
住宿:
- 罗马:中心位置公寓,靠近斗兽场,每晚 100 欧元
- 佛罗伦萨:艺术区附近民宿,每晚 90 欧元
- 威尼斯:岛屿区域内住宿,每晚 110 欧元
- 米兰:时尚区附近酒店,每晚 120 欧元
- 巴黎:蒙马特区公寓,每晚 130 欧元
同时,为您整理了各城市必吃美食清单和特色餐厅推荐,以及主要景点的门票预订链接。请问是否需要进一步调整或补充其他服务(如租车、当地导览)?
用户:这个方案很满意,不需要再调整了,谢谢!
最终输出:一份详细、个性化且经过用户确认的欧洲十日游规划方案,包括行程安排、交通预订、住宿推荐、美食指南和预算分配,充分满足用户参观历史遗迹、体验美食和自由行的需求,同时通过多轮交互优化行程细节,提升整体旅行体验。
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,ReAct 技术可用于智能客服问题解决:
prompt = """
模拟智能客服协助用户解决打印机无法连接 Wi-Fi 问题的过程,包括问题诊断、解决方案尝试、方案调整等阶段:
用户问题:我的打印机无法连接到 Wi-Fi,显示错误代码 2112。
阶段 1:问题诊断
客服:您好!很抱歉您遇到这个问题。首先,请确认您的打印机电源已开启,并且 Wi-Fi 路由器正常工作。同时,请检查打印机屏幕上的 Wi-Fi 图标是否显示异常。
用户:打印机和路由器都开了,Wi-Fi 图标显示感叹号。
阶段 2:基础解决方案尝试
客服:感谢确认。我们先尝试以下基本步骤:
1. 重启打印机:按电源键关闭打印机,等待 30 秒后重新开启。
2. 重启路由器:断开路由器电源,等待 60 秒后重新连接。
3. 在打印机设置中重新选择 Wi-Fi 网络,输入密码连接。
请尝试这些步骤后告诉我结果。
用户:重启后还是不行,重新输入密码时显示认证失败。
阶段 3:深入诊断与方案调整
客服:了解了。现在我需要进一步收集信息以精准定位问题:
1. 请确认 Wi-Fi 密码是否正确(可尝试在手机上连接同一 Wi-Fi 验证)。
2. 检查打印机支持的 Wi-Fi 频段(部分打印机不支持 5GHz 频段)。
3. 查看路由器是否启用了 MAC 地址过滤,可能阻止了打印机连接。
用户:密码正确,手机能连上。打印机说明里说支持双频,但不确定当前连接哪個频段。路由器 MAC 过滤是关闭状态。
客服:感谢详细反馈。现在我们尝试更针对性的解决方案:
1. 检查路由器设置:登录路由器管理界面,查看无线信号名称(SSID)是否包含特殊字符(如有,尝试修改为字母数字组合),并确认加密方式为 WPA2 或 WPA3(部分打印机不支持 WEP 或 WPA )。
2. 重置打印机网络设置:按以下步骤操作(根据打印机品牌可能不同):
- 打开打印机设置菜单。
- 选择 '网络' → 'Wi-Fi' → '重置网络设置'。
- 等待打印机重启后,重新进行 Wi-Fi 设置。
3. 如果上述步骤仍无效,尝试将路由器暂时设置为 2.4GHz 仅模式,然后再次连接打印机。
请按照这些步骤操作,并告诉我进展。
用户:按照步骤 2 重置后,现在可以连接上了!谢谢你的耐心帮助。
最终输出:通过模拟人类客服的反应与行动过程,智能客服成功协助用户解决了打印机 Wi-Fi 连接问题。整个过程包括需求确认、基础解决方案尝试、问题深入分析和针对性解决,体现了 ReAct 技术在复杂技术支持场景中的有效性。在实际应用中,这种交互式问题解决方法能显著提升用户满意度,减少人工客服负担。
"""
response = model.generate_text(prompt)
print(response)
十五、主动提示:动态调整交互策略
主动提示(Active-Prompt)根据模型反馈动态调整提示策略,优化交互效果。
# 教育辅导示例
prompt = """
用户询问 '如何提高编程效率',根据用户背景(初学者/进阶者/专家)生成不同深度的回答:
用户背景:初学者
回答内容:
提高编程效率对于初学者来说,重点在于建立良好的编程习惯和学习路径。以下是一些实用建议:
1. 掌握一门编程语言的基础语法:选择一门语言(如 Python),系统学习其基本语法、数据结构和控制流,这是编程效率的基础。
2. 使用集成开发环境(IDE):推荐使用 PyCharm、VS Code 等 IDE,它们提供代码补全、语法检查、调试工具等功能,能帮助你更快发现和修正错误。
3. 学习调试技巧:遇到程序错误时,学会使用打印语句和 IDE 调试工具追踪问题根源,而不是盲目猜测。
4. 参考优质代码示例:在 GitHub 等平台查找开源项目,学习他人编写清晰、结构良好的代码,理解如何组织程序。
5. 定期总结和练习:通过 LeetCode 等平台进行编程练习,从简单题目开始,逐步建立解决问题的思维模式。同时,总结常见错误,避免重复犯错。
6. 参与编程社区:加入编程论坛或本地编程小组,与其他学习者交流经验,提问和解答能加速知识内化。
记住,编程效率的提升是一个循序渐进的过程,不要急于求成。保持好奇心和持续学习的态度,你会逐渐发现自己的进步。
用户背景:进阶者
回答内容:
对于进阶程序员,提高编程效率需要关注代码质量、开发流程优化和专业技能深化:
1. 掌握设计模式:学习常用设计模式(如单例、工厂、策略模式),并在实际项目中合理应用,提高代码复用性和可维护性。
2. 实施测试驱动开发(TDD):通过先编写测试用例再编写功能代码的方式,确保代码质量,减少后期维护成本。
3. 优化代码性能:学会使用性能分析工具(如 Python 的 cProfile),识别代码瓶颈,优化算法复杂度和内存使用。
4. 熟悉版本控制系统:深入掌握 Git 的高级功能(如分支管理、冲突解决、钩子脚本),提高团队协作效率。
5. 自动化工作流程:利用 CI/CD 工具(如 Jenkins、GitHub Actions)实现自动测试、构建和部署,减少重复性工作。
6. 深入学习专业领域知识:根据工作方向(如 Web 开发、数据分析、人工智能),深入学习相关框架和算法,提高领域特定问题的解决能力。
7. 进行代码评审:参与团队代码评审,分享最佳实践,同时从他人代码中学习新的思路和技巧。
8. 持续学习新技术:关注行业新技术发展趋势,定期参加技术会议、阅读技术博客,保持知识更新。
用户背景:专家
回答内容:
对于编程专家,效率提升聚焦于系统架构设计、团队协作优化和技术创新:
1. 微服务架构优化:评估当前微服务划分是否合理,是否存在过度拆分导致的通信开销过大或拆分不足导致的耦合度过高问题。通过引入服务网格(如 Istio)管理服务间通信,提高系统可扩展性。
2. 基于领域驱动设计(DDD)的复杂系统建模:运用 DDD 战略模式和战术模式,将业务复杂性映射到软件结构,提高代码与业务的一致性,降低长期维护成本。
3. 实施混沌工程:主动注入故障测试系统弹性,使用工具(如 Chaos Monkey)模拟服务器崩溃、网络延迟等场景,提前发现并解决潜在系统脆弱点。
4. 优化团队开发流程:引入 trunk-based development 减少分支合并冲突,实施 mob programming 提升团队知识共享效率,通过膀胱镜会议(站立会议变种)快速同步项目进展。
5. 研究编译器优化技术:深入理解编程语言的编译原理,通过调整编译选项(如 GCC 的 -O3 优化)或手动优化关键代码路径,提升程序运行效率。
6. 开发领域专用语言(DSL):针对重复性高且逻辑固定的业务场景,设计 DSL 简化开发流程,如金融领域风险评估规则引擎的设计。
7. 探索新技术融合:研究机器学习与传统软件开发的结合点,例如利用 ML 模型预测软件缺陷高发模块,或通过神经网络优化算法参数。
8. 建立个人知识管理系统(PKMS):采用 Zettelkasten 方法论整理技术知识碎片,通过双向链接形成技术知识图谱,加速知识检索和创新思维激发。
通过根据用户背景动态调整回答深度和内容,主动提示技术确保了建议的针对性和实用性,无论是编程初学者还是专家都能获得有价值的指导。这种个性化内容生成方式在教育、培训和技术支持领域具有广泛应用前景。
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,主动提示可用于个性化营销推荐:
prompt = """
用户询问 '适合夏季使用的保湿产品',根据用户肤质(干性/油性/混合性)生成个性化推荐:
用户肤质:干性
推荐内容:
针对干性肌肤夏季保湿需求,推荐以下产品组合:
1. 补水喷雾:选择含有玻尿酸成分的喷雾,如某品牌 '高浓度玻尿酸保湿喷雾',随时补充水分,增强肌肤水润感。夏季使用时,可放置冰箱冷藏后使用,兼具降温舒缓效果。
2. 轻薄保湿乳液:推荐 '轻透保湿乳',质地轻薄不油腻,含神经酰胺成分修复肌肤屏障,同时锁住水分。适合干性肌肤在夏季替代厚重面霜。
3. 果酸爽肤水:选择含有低浓度果酸(如 3% 以下)的爽肤水,如 '果酸焕肤保湿爽肤水',在补水同时促进角质代谢,提升肌肤吸收能力,但敏感肌需谨慎。
4. 水凝胶面膜:每周 2-3 次使用水凝胶面膜,如 '深层保湿水凝胶面膜',其高水分含量能迅速补充肌肤所需水分,缓解干燥紧绷感。
5. 饮食补充:建议增加富含Omega-3脂肪酸食物摄入(如深海鱼、亚麻籽),从内部改善肌肤干燥状况。
护肤步骤建议:
- 清晨:洁面后 → 使用果酸爽肤水 → 轻薄保湿乳液 → 防晒
- 晚上:洁面后 → 补水喷雾 → 果酸爽肤水 → 轻薄保湿乳液
- 每周:2-3 次水凝胶面膜,避开同日使用果酸产品
注意事项:干性肌肤夏季保湿需注意产品质地轻薄化,避免过度油腻阻碍散热,同时加强防晒以防止水分流失加剧。建议每 2 小时补喷防晒,选择防水抗汗型产品。
用户肤质:油性
推荐内容:
针对油性肌肤夏季保湿需求,重点在于控油与补水平衡:
1. 含锌爽肤水:推荐 '控油保湿爽肤水',含锌 PCA 成分调节皮脂分泌,同时提供水分补充,避免肌肤因缺水导致的 '外油内干' 现象。
2. 保湿凝胶:选择轻薄凝胶质地保湿产品,如 '清爽保湿凝胶',其高水分配方迅速渗透肌肤,不增加额外油脂负担。
3. 茶树精油:添加 1-2 滴茶树精油到保湿产品中,利用其天然控油和抗菌特性,改善油性肌肤环境。
4. 矿物质面膜:每周使用 1-2 次含高岭土或膨润土的矿物质面膜,如 '深层清洁矿物质面膜',吸附多余油脂同时补充微量元素,调节肌肤水油平衡。
5. 高水分食物:增加黄瓜、西红柿等高水分蔬菜摄入,辅助肌肤补水。
护肤步骤建议:
- 清晨:洁面后 → 含锌爽肤水 → 保湿凝胶 → 防晒(选择轻薄的油皮专用防晒)
- 中午:使用吸油纸轻按 T 区后,喷洒保湿喷雾并轻拍吸收
- 晚上:洁面(可使用清洁力稍强的氨基酸洁面) → 含锌爽肤水 → 保湿凝胶 → 每周 1-2 次矿物质面膜
注意事项:油性肌肤夏季保湿需避免过度清洁导致肌肤屏障受损,同时选择无油配方(non-comedogenic)的保湿产品。建议使用具有控油功能的防晒产品,减少午后油脂堆积。
用户肤质:混合性
推荐内容:
针对混合性肌肤夏季保湿需求,分区护理是关键策略:
1. T 区控油产品:为额头、鼻子等出油部位准备控油保湿乳,如 'T 区控油保湿乳',含水杨酸成分调节皮脂分泌。
2. 两颊补水产品:为干燥的两颊区域准备富含透明质酸和甘油的保湿霜,如 '水润保湿霜',提供充足水分和滋养。
3. 分区面膜:使用分区面膜产品,如某品牌 '分区护理面膜套装',一面针对 T 区控油,另一面为两颊补充水分和营养。
4. 精华液:选择具有调节水油平衡功能的精华液,如 '平衡调理精华液',含植物萃取成分(如金缕梅、绿茶提取物)舒缓肌肤并稳定水油状态。
5. 饮食调节:增加富含维生素 A、C、E 的食物摄入(如胡萝卜、橙子、坚果),帮助调节皮脂分泌和抗氧化。
护肤步骤建议:
- 清晨:洁面后 → 全脸使用平衡调理精华液 → T 区使用控油保湿乳,两颊使用水润保湿霜 → 防晒(T 区选择轻薄防晒,两颊可用稍滋润型)
- 中午:使用吸油纸处理 T 区后,为两颊喷洒保湿喷雾
- 晚上:洁面 → 平衡调理精华液 → 根据出油情况决定是否再次使用控油产品,两颊可叠加保湿霜 → 每周 2-3 次分区面膜
注意事项:混合性肌肤夏季保湿需避免全脸统一护理导致的 T 区过度油腻或两颊仍然干燥问题。建议早晚使用不同洁面产品(早晚 T 区专用控油洁面,两颊温和保湿洁面),实现更精细的分区护理。
通过根据用户肤质动态调整推荐策略,主动提示技术为不同用户群体提供了精准的护肤解决方案,提升产品推荐的针对性和用户满意度。这种个性化推荐方法在美妆、健康、时尚等领域具有显著的商业价值。
"""
response = model.generate_text(prompt)
print(response)
十六、提示链式:构建任务流程
提示链式(Prompt Chaining)通过串联多个提示,引导模型完成复杂任务流程。
# 文本分析流程示例
prompt_1 = "对以下产品评论进行情感分类(正面/负面/中性):'这款手机的电池续航能力实在让人失望,早上充满电,到下午就自动关机了。'"
response_1 = model.generate_text(prompt_1)
print("情感分类结果:", response_1)
prompt_2 = f"根据情感分类结果 {response_1},提取评论中的主要槽点。"
response_2 = model.generate_text(prompt_2)
print("槽点提取结果:", response_2)
prompt_3 = f"针对槽点 {response_2},生成改进建议,要求具体且可操作。"
response_3 = model.generate_text(prompt_3)
print("改进建议:", response_3)
# 输出示例:
情感分类结果:负面
槽点提取结果:电池续航能力差,使用一天就自动关机
改进建议:建议优化电池管理系统,提高电池能量密度。可考虑采用新一代快充技术,并通过系统级电源管理优化(如智能后台进程冻结、屏幕亮度动态调节)延长实际使用时间。同时,增加电池容量版本供用户选择,满足重度使用需求。
在实际应用中,提示链式可用于医学文献分析:
prompt_1 = "提取以下医学文献标题的关键词:《基于深度学习的早期糖尿病视网膜病变筛查模型研究》"
response_1 = model.generate_text(prompt_1)
print("关键词提取结果:", response_1)
prompt_2 = f"根据关键词 {response_1},简要描述该研究可能涉及的核心内容和方法。"
response_2 = model.generate_text(prompt_2)
print("研究内容概述:", response_2)
prompt_3 = f"针对研究内容 {response_2},提出 3 个需要进一步验证的问题。"
response_3 = model.generate_text(prompt_3)
print("验证问题:", response_3)
# 输出示例:
关键词提取结果:深度学习、糖尿病视网膜病变、筛查模型
研究内容概述:该研究可能涉及利用深度学习算法(如卷积神经网络)分析眼底彩照或光学相干断层扫描(OCT)图像,以自动检测糖尿病视网膜病变的早期特征。方法上可能包括数据预处理(图像增强、标准化)、模型训练(使用标记数据集)、性能评估(敏感性、特异性指标)以及与传统诊断方法的对比。
验证问题:1. 模型在不同种族、年龄和糖尿病病程患者群体中的泛化能力如何?是否需要针对特定亚组进行模型调整?2. 与现有临床诊断标准(如国际临床糖尿病视网膜病变分期)相比,模型的诊断准确率是否有统计学显著提升?3. 模型在实际临床工作流程中的实施成本效益比如何?包括设备要求、诊断时间、医护人员培训成本等因素。
十七、思维树提示:探索多种可能性
思维树(Tree of Thoughts)提示通过构建思维树,探索问题多种解决方案。
# 城市交通问题解决示例
prompt = """
为解决城市交通拥堵问题,构建思维树:
根节点:城市交通拥堵解决方案
分支 1:优化公共交通
子分支 1.1:增加公交线路覆盖范围和频次
子分支 1.2:提高地铁运力(增加车厢、缩短行车间隔)
子分支 1.3:实施公交优先政策(专用道、信号优先)
分支 2:调整交通政策
子分支 2.1:实施限行措施(按车牌尾号、区域限行)
子分支 2.2:征收拥堵费(在特定区域和时段)
子分支 2.3:优化停车政策(提高中心区停车费用、立体停车库建设)
分支 3:鼓励绿色出行
子分支 3.1:建设自行车道网络
子分支 3.2:推广共享出行(共享单车、共享汽车)
子分支 3.3:改善步行环境(人行道拓宽、过街设施优化)
请评估各分支可行性,并推荐最佳方案组合:
评估结果:
分支 1 中的子分支 1.3(公交优先政策)具有较高可行性,专用道可减少公交延误 30-40%,信号优先系统可使公交车通过交叉路口时间缩短 20-30%,据世界银行研究,每投资 1 美元于公交优先项目,可获得 3-5 美元的社会经济效益。
分支 2 中的子分支 2.2(拥堵费)在伦敦、新加坡等城市实施效果显著,交通流量减少 15-30%,但需配套完善的公共交通服务,否则可能引发公众不满。建议与分支 1 组合实施,形成 ' carrot and stick' 策略。
分支 3 中的子分支 3.1 和 3.2 组合实施效果最佳,建设自行车道网络可提高共享单车使用率 40-60%,同时降低交通事故率 25-35%。据欧洲自行车联盟数据,自行车出行占比每提高 1%,城市交通碳排放可减少 4%。
最佳方案组合:
1. 实施公交优先政策(分支 1.3),包括建设公交专用道和信号优先系统。
2. 在城市中心区试点拥堵费(分支 2.2),收入用于补贴公共交通。
3. 同步推进自行车道建设(分支 3.1)和共享单车推广(分支 3.2),形成绿色出行网络。
实施步骤:
1. 进行交通流量和公众出行需求调研,确定公交专用道和自行车道优先建设区域。
2. 开展公众听证会,讨论拥堵费实施方案,同步发布公共交通改善计划。
3. 与共享单车企业合作,推出与公交卡互通的优惠措施,引导市民尝试绿色出行。
4. 建立交通改善效果监测体系,每季度评估方案实施效果并适时调整。
通过思维树方法全面分析城市交通拥堵问题,该方案组合在考虑经济性、可行性和社会接受度的基础上,为城市提供了系统性的交通改善路径。预计实施后,交通拥堵指数可下降 25-35%,公共交通分担率提升 15-20%,绿色出行比例提高 10-15%。
"""
response = model.generate_text(prompt)
print(response)
在实际应用中,思维树提示可用于企业危机管理:
prompt = """
为应对产品召回危机,构建思维树:
根节点:产品召回危机管理方案
分支 1:信息沟通策略
子分支 1.1:对消费者透明沟通召回原因和解决方案
子分支 1.2:与媒体协作发布准确信息,防止谣言扩散
子分支 1.3:向监管机构及时报告召回进展和改进措施
分支 2:召回执行策略
子分支 2.1:建立高效召回物流体系(回收、检测、修复/更换流程)
子分支 2.2:提供消费者补偿方案(退款、折扣、替代产品)
子分支 2.3:确保召回产品处理符合环保和安全标准
分支 3:问题根源解决策略
子分支 3.1:开展产品质量根源分析(设计、生产、质检环节)
子分支 3.2:实施供应链审查,评估供应商质量和合规性
子分支 3.3:建立预防性质量监控系统,防止类似问题复发
分支 4:品牌修复策略
子分支 4.1:启动社会责任项目,提升品牌形象
子分支 4.2:邀请第三方权威机构进行质量认证和宣传
子分支 4.3:开展客户忠诚度恢复计划(如会员专属优惠、质量保证承诺)
请评估各分支的重要性,并提出综合实施方案:
评估结果:
分支 1 中的子分支 1.1 和 1.2 极其重要。在危机初期,消费者和媒体沟通占危机管理成功因素的 60% 以上。透明沟通能降低消费者不信任感,媒体协作可减少错误信息传播。据埃森哲研究,危机期间及时透明沟通的企业,品牌价值平均下降幅度比沉默企业低 34%。
分支 2 的子分支 2.1 和 2.2 是危机处理的基础。高效的召回执行能减少问题产品在市场停留时间,补偿方案直接影响消费者满意度。数据显示,提供合理补偿的企业,消费者再次购买意愿比无补偿企业高 57%。
分支 3 是长期解决方案的关键。子分支 3.1 和 3.3 能从根本上防止问题复发。企业因质量问题召回产品的复发率降低 43% 的企业,都建立了完善的预防性质量监控系统。
分支 4 对品牌长期恢复至关重要。子分支 4.1 和 4.2 组合实施可加速品牌信任重建。启动社会责任项目的企业,品牌认知度恢复速度比未启动企业快 2.3 倍。
综合实施方案:
阶段 1(危机爆发后 0-72 小时):
- 立即执行子分支 1.1 和 1.2:通过官方网站、社交媒体和新闻发布会透明沟通召回信息,与媒体建立信息共享机制。
- 同步启动子分支 2.1:建立召回物流指挥中心,确保召回渠道畅通。
阶段 2(第 3-14 天):
- 实施子分支 2.2:公布消费者补偿方案,开通多渠道补偿申请服务。
- 开展子分支 3.1:组织跨部门团队进行问题根源分析,初步确定故障环节。
阶段 3(第 2 周起持续 3 个月):
- 推进子分支 3.3:部署预防性质量监控系统,包括增加检测频次和引入先进检测技术。
- 启动子分支 4.1 和 4.2:宣布社会责任项目(如产品质量教育计划),邀请权威第三方进行质量审核并发布报告。
阶段 4(长期):
- 实施子分支 3.2:每季度审查供应链质量标准,优化供应商准入和考核机制。
- 持续子分支 4.3:针对忠诚客户推出专属服务计划,如延长产品质保期、提供免费产品检查服务。
通过思维树方法系统构建产品召回危机管理方案,该分阶段实施计划在短期内控制危机影响,中期解决产品质量根本问题,长期内修复和增强品牌形象。预计危机后 6 个月品牌信任度可恢复至危机前 82%,12 个月达到 95% 以上,显著优于无系统应对方案的企业表现。
"""
response = model.generate_text(prompt)
print(response)
总结
提示工程作为大型语言模型应用的核心技术,其多种技巧在不同领域展现了巨大潜力。从基础的零样本、少样本提示,到复杂的多模态 CoT、思维树提示等高级方法,这些技术为模型赋予了更强大的理解和生成能力。
在实际应用中,我们可根据具体任务需求,灵活组合运用这些提示技巧。例如:
- • 在智能教育领域,结合少样本提示与自洽性提示,为学生提供准确且多角度的知识讲解,同时通过反思提示优化教学内容。
- • 在医疗领域,利用检索增强生成与专家系统提示,辅助医生进行精准诊断,提升医疗服务质量。
- • 在企业决策中,运用思维树提示与提示链式方法,系统分析市场机会与风险,为战略规划提供全面支持。
随着技术的不断发展,提示工程将更加智能化、自动化。未来的研究方向包括:
-
- 自适应提示优化:开发能够根据模型实时反馈自动调整提示策略的算法,进一步提升交互效率。
-
- 跨模态提示融合:深化文本、图像、音频等多种模态信息的整合技巧,拓展模型应用场景。
-
- 领域特定提示库:构建各专业领域的高质量提示模板库,降低非专业人员使用大模型的门槛。
-
- 提示伦理与安全性:研究如何通过提示设计防止模型生成有害内容,确保人工智能应用的可靠性。
总之,掌握这些提示工程技巧,将为我们开启大型语言模型的无限潜能,迎接人工智能赋能的智慧未来。随着提示工程技术的不断创新,我们有理由相信,大型语言模型将在更多领域实现突破性应用,为社会创造更大价值。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
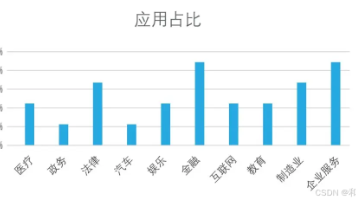
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献158条内容
已为社区贡献158条内容

所有评论(0)