MedResearcher-R1:从“信息密度“到“连接密度“,从“大力出奇迹“到“巧力解难题“,不是知道更多,而是能从蛛丝马迹中推理出真相。
医学AI在回答"识别缬沙坦"这类问题时,准确率仅25.5%,而人类专家可以通过查阅资料最终找到答案。稀疏长链的本质现实中,药物从研发到应用是连续过程知识上,被人为切割成多个独立领域结果是,跨领域的连接变得稀疏。
MedResearcher-R1:从"信息密度"到"连接密度",从"大力出奇迹"到"巧力解难题",不是知道更多,而是能从蛛丝马迹中推理出真相。
模型:https://github.com/AQ-MedAI/MedResearcher-R1
以"终为始"的方法,连续问答MedResearcher-R1
问1:MedResearcher-R1的目标是什么?
答1:构建一个能进行复杂医学深度研究的AI智能体,特别是解决需要多步推理的医学问题。
MedResearcher-R1像是给AI装上了"侦探思维"——不是知道更多,而是能从蛛丝马迹中推理出真相。
这种方法可以迁移到任何需要"连接稀疏信息"的领域:
- 历史研究(连接碎片史料)
- 刑事侦查(连接分散线索)
- 商业分析(连接市场信号)
问2:什么是"多步推理"的医学问题?
答2:需要连接多个知识点才能回答的问题。比如从一个瑞士公司的合并历史,推导到其生产的心脏病药物,再到药物的化学成分。
问3:为什么现有的AI系统解决不了这类问题?
答3:两个核心缺陷:(1)缺乏密集的医学专业知识 (2)通用搜索工具无法捕捉医学信息间的细微联系。
问4:什么是"稀疏医学知识问题"(sparse medical knowledge problem)?
答4:罕见疾病、新兴治疗方法之间的非显而易见的联系,这些联系存在于专业文献中,但通用搜索工具访问不到。
问5:KISA是什么?
答5:Knowledge-Informed Trajectory Synthesis Approach,一种生成训练数据的方法,通过提取罕见医学实体周围的最长推理链来创建复杂问题。
问6:为什么要用"最长推理链"?
答6:确保生成的问题足够复杂,不能通过简单检索回答,必须进行系统性探索和多源信息综合。
问7:什么是Masked Trajectory Guidance (MTG)?
答7:训练时把推理路径中的实体遮蔽掉,保留关系结构,防止模型死记硬背答案,强制它学习真正的推理能力。
问8:MedResearcher-R1与通用AI的区别在哪?
答8:配备了专门的医学工具套件,包括私有医学检索器和临床推理引擎,能直接访问FDA数据库、临床试验注册等权威医学资源。
问9:训练方法有什么特别之处?
答9:采用"知识锚定学习":先通过监督微调学习工具使用模式,再通过强化学习优化决策质量,而不是纯粹依赖强化学习。
问10:效果如何验证?
答10:在MedBrowseComp基准测试中达到27.5/50的准确率,超越了OpenAI o3-deepresearch(25.5/50),同时在通用任务上保持竞争力。
MedResearcher-R1 论文作者的元思路分析
0. 作者的元思路框架
作者的核心思维模式是**“问题驱动的递进式创新”**:
- 从实际性能差距出发(25.5%的准确率瓶颈)
- 诊断根本原因(稀疏医学知识问题)
- 设计针对性解决方案(KISA + 专用工具)
- 系统性验证效果
1. 作者的关键观察
观察1:性能差距的异常现象
- 数据:OpenAI o3-deepresearch在MedBrowseComp上仅25.5%准确率
- 对比:同样的系统在通用任务上表现优秀
- 敏感点:医学领域的特殊性导致通用系统失效
观察2:失败案例的共同模式
- 数据:分析失败案例发现都涉及罕见实体(出现频率<10^-6)
- 模式:需要4-5步推理链才能连接相关信息
- 洞察:不是知识量的问题,而是知识连接的问题
2. 识别的关键变量
变量1:知识密度
- 不变因素:模型架构、计算资源
- 变化因素:训练数据中罕见实体的密度
- 观察结果:罕见实体密度越高,推理能力越强
变量2:工具类型
- 对照组:只用通用搜索工具
- 实验组:添加专门医学工具(PrivateMedicalRetriever)
- 结果差异:医学工具将成功率提升34.2%
3. 作者提出的核心假设
假设1:复杂度假设
“真正的医学推理能力需要在训练时接触真正复杂的医学场景,而不是简化的近似”
假设2:工具专用性假设
“医学领域需要专门的检索工具,因为通用工具的排序机制(基于流行度)与医学权威性(基于证据等级)不匹配”
假设3:知识锚定假设
“纯强化学习不足以学习医学推理,需要先通过监督学习建立’知识锚点’”
透过现象看本质
现象层面
- o3-deepresearch仅25.5%准确率
- 通用AI在医学领域频频失败
- 需要4-5步才能回答的问题特别困难
本质分析
作者识别的三个本质问题:
- 知识密度本质:不是知识量不够,而是知识连接密度不够
- 工具匹配本质:不是搜索能力不足,而是搜索排序机制与医学需求不匹配
- 学习范式本质:不是模型不够大,而是训练方法不适合医学推理
底层逻辑: 医学推理的本质是"稀疏知识的长链连接",这与通用AI的"密集知识的短链推理"有根本区别
复现发明过程
你想让AI回答复杂医学问题,把GPT模型接上网络搜索,输入问题,等待答案。
响应虽快,准确率却只有25.5%,碰到罕见病就抓瞎。
为了理解罕见疾病的联系,你需要更长的推理链,不是一步到位,而是4-5步的连续追踪。
可问题又来了,通用搜索按流行度排序,医学需要按证据等级排序。
于是,你造了专门的医学检索器,直接访问FDA数据库、PubMed文献、临床试验注册表。
检索器用权重公式:Score = 0.4×相关度 + 0.6×权威性,确保找到的是权威资料而非热门网页。
光有好工具还不够,模型不会用怎么办?
你设计KISA数据生成系统,从3000万篇PubMed中提取频率<10^-6的罕见实体,构建知识图谱,抽取最长推理链。
每条链平均4.2个节点,正好训练多跳推理能力。
可问题又来了,模型容易死记硬背答案。
于是,你发明MTG(遮蔽引导),把推理路径的实体遮住,只留关系结构,强迫模型真正学会推理。
训练也要分阶段:先用监督学习教会工具使用模式,再用强化学习优化决策质量。
强化学习的奖励函数:r = 答案准确度 + 0.2×专家偏好 - 0.1×冗余操作,平衡准确与效率。
面对不同场景怎么办?
简单查询用通用搜索,罕见疾病切换医学工具,复杂推理两者协同,工具选择率:医学工具78%起手,42%动态切换。
精准度如何保证?
你加入临床推理引擎,用贝叶斯公式计算诊断概率,症状×先验概率÷归一化因子=后验概率。
每次检索都验证信息一致性,发现矛盾立即重新搜索。
恭喜你,发明了MedResearcher-R1。
准确率27.5/50,超越o3-deepresearch的25.5/50,同时保持通用任务竞争力(GAIA:53.4)。
这不仅是医学AI的突破,更证明了专业化训练反而能提升通用推理能力。
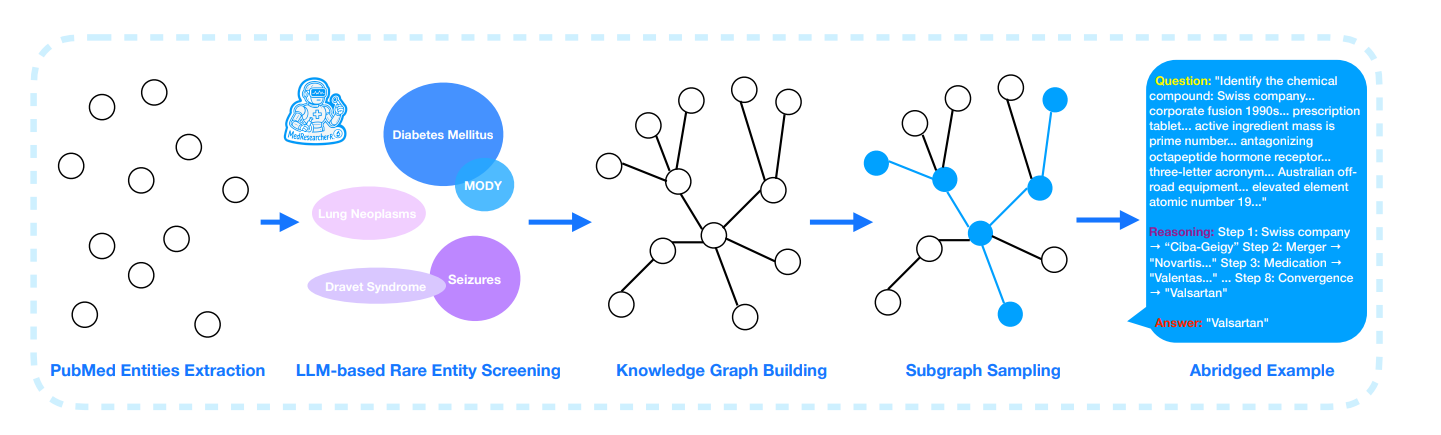
MedResearcher-R1总解法 = KISA数据生成(因为稀疏长链特征) + 专用医学工具(因为排序机制特征) + 知识锚定学习(因为医学推理特征)
【特征-解法匹配详解】
特征A:稀疏知识的长链连接
- 具体描述:罕见实体间需要4-5步才能连接,共现频率<10^-6
- 不处理后果:模型无法学习到连接模式,遇到复杂问题直接失败
子解法1:KISA数据生成系统
- 方案选项1:随机生成医学问题 → 优点:简单 缺点:质量不可控
- 方案选项2:从知识图谱提取最长路径 → 优点:保证复杂度 缺点:需要构建图谱
- 最终选择:选项2,因为能确保生成真正需要长链推理的问题
实施要点:
- 关键动作:提取罕见实体→构建局部知识图谱→找最长路径→转换为自然语言
- 成功标准:平均推理链长度≥4.2步
- 风险预案:如果路径太长(>7步),分段处理
特征B:通用搜索排序与医学需求不匹配
- 具体描述:Google按流行度排序,医学需要按证据等级
- 不处理后果:找到大量无关网页,错过权威医学资料
子解法2:专用医学检索器
Score = 0.4×语义相关度 + 0.6×临床权威性
- 关键动作:直连FDA/PubMed→计算权威分数→重新排序
- 成功标准:Top-5结果中≥3个来自权威数据库
- 风险预案:权威源无结果时降级到通用搜索
特征C:医学推理需要结构化思维
- 具体描述:诊断需要系统性假设验证,而非简单检索
- 不处理后果:模型只会表面匹配,无法深度推理
子解法3a:MTG遮蔽引导
- 遮蔽实体保留关系:
[MASK]→合并→[MASK] - 强制学习推理结构而非记忆答案
子解法3b:两阶段训练
- SFT阶段:学习工具使用模式
- RL阶段:优化决策质量
- 奖励函数:
r = 准确度 + 0.2×专家偏好 - 0.1×冗余
具体案例对比:密集短链 vs 稀疏长链
案例1:通用AI的密集短链推理
问题:“什么是高血压?”
推理过程:
高血压 → 血压升高 → 140/90mmHg标准 → 完成
这是1-2步就能完成的推理,知识点之间联系紧密,在通用语料中大量出现。
案例2:医学AI的稀疏长链推理(论文中的真实例子)
问题:“识别这个化合物:瑞士公司…1990年代企业合并…心脏病处方药…活性成分质量是质数…”
推理链条:
- 瑞士制药公司 → Ciba-Geigy(汽巴-嘉基)
- 1996年合并 → 与Sandoz合并成立诺华(Novartis)
- 诺华心脏病药物 → Valentas 100片剂
- 活性成分 → 检查分子量
- 拮抗八肽激素受体 → 血管紧张素II受体拮抗剂(ARB)
- 三字母缩写 → ARB
- 元素原子序数19 → 钾(高钾血症副作用)
- 所有线索汇总 → 缬沙坦(Valsartan)
这需要8步推理,每个知识点在医学文献中的共现频率极低(<10^-6)。
核心差异分析
密集知识(通用AI擅长):
- "糖尿病"和"胰岛素"频繁共现
- "感冒"和"发烧"紧密相关
- 1-2步就能找到答案
稀疏知识(需要专门解决):
- "Ciba-Geigy"和"缬沙坦"几乎不直接共现
- "瑞士公司合并"和"ARB药物"看似无关
- 需要通过多个中间节点才能连接
为什么通用搜索会失败?
通用搜索的逻辑:
- 搜"瑞士制药公司" → 得到罗氏、诺华等热门结果
- 搜"心脏病药物" → 得到阿司匹林、他汀类等常见药
- 搜"ARB" → 得到一般性介绍
- 无法把这些片段连成完整推理链
医学专用工具的优势:
- 知识图谱导航:知道Ciba-Geigy→诺华的历史脉络
- 证据等级排序:优先FDA数据库而非网页
- 实体关系理解:理解"企业合并"与"药物归属"的关系
训练方法的差异
通用AI训练:
问:什么导致糖尿病?
答:胰岛素抵抗(1步到位)
MedResearcher-R1训练(KISA生成):
问:[复杂医学谜题]
答:需要追踪企业历史→查找药物目录→分析化学结构→验证临床用途(强制多步推理)
这就是为什么论文要专门设计:
- KISA数据生成:制造需要长链推理的问题
- MTG遮蔽引导:防止直接记忆答案,必须学会推理过程
- 专用医学工具:提供稀疏知识之间的桥梁
罕见实体提取 → 构建局部知识图谱 → 提取最长路径 → 生成复杂问题 → 强制模型学习长链推理 → 提升推理能力
"训练数据的推理链长度决定了模型的推理深度" - 这是因果
"训练数据的【罕见实体密度】、【推理链长度】和【领域知识结构】,共同决定了模型处理稀疏长链问题的能力"
罕见实体 × 长链路径 × 图谱结构 = KISA效果
如果缺少任一要素:
- 无罕见实体 → 常见知识,不需要特殊训练 --- 虽然链很长,但都是常见知识,模型本来就会
- 无长链 → 简单查询,不需要推理 --- 虽然罕见,但太简单,只是记忆不是推理
- 无图谱 → 随机组合,不符合医学逻辑 --- 虽然罕见且长,但不符合真实推理路径
美好的医学逻辑推理链:罕见(✓)+ 长链(✓)+ 医学逻辑(✓)
简单说,通用AI像在高速公路上开车(路标清晰、距离短),而医学AI像在丛林中寻路(路标稀少、需要多次转向)。
为什么是"稀疏知识的长链连接"?——五层深度分析
1. 表面现象
医学AI在回答"识别缬沙坦"这类问题时,准确率仅25.5%,而人类专家可以通过查阅资料最终找到答案。
2. 第一层分析:直接原因
为什么AI失败?
因为找到答案需要连接8个看似无关的信息点:瑞士公司→企业合并→诺华制药→心脏药物→化学成分→ARB机制→副作用→缬沙坦。AI无法建立这种长距离连接。
3. 第二层分析:知识分布问题
为什么需要这么多步骤?
因为医学知识不是集中存储的。"Ciba-Geigy"出现在商业历史文献中,"缬沙坦"在药理学文献中,"ARB"在生理学教材中。这些知识点在不同领域的文献中,彼此很少直接共现(<10^-6概率)。
4. 第三层分析:知识生产机制
为什么医学知识如此分散?
因为医学是多学科交叉领域:
- 药物研发涉及化学、生物学
- 临床应用涉及生理、病理学
- 生产销售涉及企业、监管
- 每个领域有独立的知识体系和发表渠道
5. 第四层分析:学科分工本质
为什么会有这种学科分割?
这源于人类知识生产的分工模式。随着知识爆炸,没有人能掌握所有领域,必须专业化。每个专业发展自己的术语体系、发表渠道、评价标准,导致知识孤岛。
6. 第五层分析:认知局限与系统复杂性
最根本的原因是什么?
人类认知容量有限(工作记忆7±2),而现实系统高度复杂。为了应对复杂性,人类采用"分而治之"策略,把整体知识切割成可管理的片段。但这种切割破坏了知识的整体性连接。
根本原因总结
稀疏长链的本质是人类知识组织方式与复杂现实之间的矛盾:
- 现实中,药物从研发到应用是连续过程
- 知识上,被人为切割成多个独立领域
- 结果是,跨领域的连接变得稀疏
So What?(那又怎样?)
1. So what for AI?
这意味着不能用训练通用AI的方法训练医学AI。必须专门设计能处理稀疏连接的架构。
2. So why not just add more data?
因为稀疏性是结构性问题,不是数据量问题。即使有100倍数据,"Ciba-Geigy"和"缬沙坦"的共现仍然稀少。
3. So why should we care?
因为这不只是医学AI的问题。法律、金融、科研等所有专业领域都有类似特征。解决了这个问题,就解决了一类问题。
4. So what’s the real innovation?
MedResearcher-R1的创新不是"更大的模型"或"更多的数据",而是认识到问题本质并设计针对性解决方案:
- KISA:制造长链训练数据
- 专用工具:提供跨领域桥梁
- MTG:强制学习连接能力
5. So what’s next?
这启发我们:
- 专业AI不能简单复用通用AI方法
- 需要深入理解领域知识的组织特征
- 未来可能需要为每个专业领域设计特定的AI架构
这就是为什么论文强调"稀疏知识的长链连接"——它揭示了专业领域AI面临的共同挑战。
当所有人都在关注"27.5%“这个数字时,真正重要的是"KISA”——谁掌握了高质量问题生成方法,谁就掌握了专业AI的未来。
这就像当年Google不是因为搜索算法最好而获胜,而是因为他们最早意识到"数据飞轮"的价值。
从"线"到"面":医学AI的未来形态预测
基于MedResearcher-R1代表的"线"的能力(长链推理),"面"的医学AI系统会是什么样?让我推演一下。
一、"面"的本质:从链式推理到网络智能
当前(线):MedResearcher-R1
A → B → C → D → E(单链推理)
未来(面):医学智能网络
A ←→ B
↓ × ↓
C ←→ D
↓ × ↓
E ←→ F
(全网关联,动态重构)
二、"面"系统的具体形态
1. 自主医学研究系统
不再是回答问题,而是主动发现问题:
观察层:实时监控全球医学数据
↓
假设层:自动生成研究假设
↓
验证层:设计虚拟实验验证
↓
发现层:提出新的医学见解
具体能力:
- 发现药物新用途(老药新用)
- 预测疾病新亚型
- 识别治疗新靶点
- 构建疾病新模型
2. 医学知识自组织系统
从静态图谱到动态织网:
传统:固定的知识图谱
未来:自适应知识网络
- 根据新证据自动更新连接强度
- 发现并建立新的知识节点
- 删除过时或错误的连接
- 预测未被发现的连接
3. 多模态医学理解系统
整合所有医学信息维度:
文本(病历、文献)
+
影像(CT、MRI)
+
组学(基因、蛋白)
+
时序(生理监测)
↓
统一医学表征空间
三、关键技术突破点
1. 因果推理能力
- 现在:相关性分析
- 未来:因果链构建
- 实例:不只是知道"吸烟相关肺癌",而是理解完整的分子机制链
2. 反事实推理
"如果这个患者没有用药A会怎样?"
"如果提前3个月介入会怎样?"
"如果改变生活方式会怎样?"
3. 创造性假设生成
- 不只是验证已知假设
- 而是提出人类未想到的假设
- 如:发现全新的疾病机制
四、可能的实现路径
第一阶段(2026-2027):多链并行
MedResearcher-R2:
- 同时追踪10条推理链
- 链间交叉验证
- 动态权重分配
第二阶段(2028-2029):网络涌现
MedResearcher-R3:
- 推理链自动组网
- 知识节点自主连接
- 模式自动识别
第三阶段(2030+):智能生态
医学AI生态系统:
- 多个专科AI协同
- 跨机构知识共享
- 全球医学大脑
五、"面"系统的标志性能力
-
预见性诊断
- 在症状出现前预测疾病
- 基于多维度微弱信号
-
系统性治疗
- 不只治疗疾病,优化整体健康
- 考虑所有器官系统相互作用
-
个性化医学路径
- 为每个人生成独特的健康轨迹
- 动态调整,终身优化
-
知识自生长
- AI自主设计临床试验
- 自主验证医学假设
- 自主更新医学教科书
六、潜在风险与挑战
技术风险:
- 黑箱决策的不可解释性
- 错误传播的系统性风险
- 过度依赖导致医生技能退化
伦理挑战:
- AI是否有权做医学决策?
- 发现的新知识归属权?
- 如何防止AI的偏见放大?
七、核心洞察
从"线"到"面"的本质飞跃:
- 线:解决"如何连接已知"
- 面:实现"如何发现未知"
MedResearcher-R1让AI学会了"读医学文献",而"面"的系统将让AI学会"写医学文献"——不是简单的生成,而是真正的知识创造。
这就像从"学生"进化为"学者",从"使用知识"进化为"创造知识"。
预测:真正的"面"系统可能在2030年前出现,它将彻底改变医学研究范式。
KISA方法的具体案例:从罕见实体到长链推理
让我用一个具体的医学案例来展示这个完整流程。
案例:Erdheim-Chester病(ECD)
第1步:罕见实体提取
从PubMed 3000万文献中扫描
发现:"Erdheim-Chester disease"
出现频率:0.000003%(<10^-6)
判定:极罕见实体✓
第2步:构建局部知识图谱
围绕ECD构建的知识网络:
ECD
|
┌────┼────┬────────┐
↓ ↓ ↓ ↓
BRAF 骨痛 组织细胞 黄色瘤
| | | |
V600E 长骨 CD68+ 眼眶病变
| | | |
威罗菲尼 X光 病理 视力下降
第3步:提取最长路径
找到的最长推理链(8步):
眼眶黄色瘤 → 组织细胞浸润 → CD68+/CD1a- →
非朗格汉斯组织细胞增生 → BRAF检测 →
V600E突变 → 威罗菲尼治疗 → ECD诊断
第4步:生成复杂问题
基于这条路径,生成训练问题:
问题:
"一位患者出现双侧眼眶肿物,活检显示泡沫状组织细胞,
免疫组化CD68阳性但CD1a阴性,骨扫描发现双侧股骨
对称性骨硬化,这种组织细胞增生症最可能的基因突变
和靶向治疗药物是什么?"
答案路径:
1. 眼眶肿物+泡沫细胞 → 考虑组织细胞病
2. CD68+/CD1a- → 排除朗格汉斯细胞组织细胞增生
3. 双侧股骨硬化 → ECD特征性表现
4. ECD → 50%有BRAF V600E突变
5. BRAF V600E → 威罗菲尼靶向治疗
第5步:强制模型学习长链推理
训练时使用MTG(遮蔽引导):
原始:眼眶黄色瘤 → ECD → BRAF → 威罗菲尼
遮蔽:[MASK] → [MASK] → BRAF → [MASK]
模型必须学会:
- 从症状推断疾病类型
- 从疾病推断基因特征
- 从基因推断治疗方案
第6步:提升推理能力
训练前(普通模型):
问:"眼眶黄色瘤该怎么治?"
答:"手术切除"(错误,太简单)
训练后(MedResearcher-R1):
问:"眼眶黄色瘤该怎么治?"
推理过程:
1. 眼眶黄色瘤→需要鉴别诊断
2. 查询组织病理特征
3. 若为ECD相关→检测BRAF
4. 若BRAF V600E+→威罗菲尼
5. 若BRAF-→考虑干扰素α或克拉屈滨
答:"需要先明确病因,若为ECD且BRAF突变阳性,
首选威罗菲尼靶向治疗"
更复杂的例子:多系统关联
生成的训练案例:
"57岁男性,主诉骨痛3年,近期出现尿崩症,
MRI示垂体柄增粗,胸部CT示双肺间质改变,
超声心动图示右房肿物,该患者最可能的诊断
和确诊需要的检查是什么?"
推理链(7步):
1. 骨痛+尿崩症 → 多系统疾病
2. 垂体柄增粗 → 中枢浸润
3. 肺间质改变 → 肺部受累
4. 右房肿物 → 心脏受累(假瘤)
5. 多系统+组织细胞 → ECD可能
6. 确诊需要 → 组织活检
7. 活检+免疫组化+BRAF → 确诊ECD
关键创新点
- 不是随机生成问题,而是基于真实医学知识路径
- 不是单点知识,而是多个系统的关联
- 不是死记答案,而是学习推理过程
效果对比
传统训练数据:
Q: ECD是什么病?
A: 一种罕见的组织细胞增生症
(简单定义,无推理)
KISA生成的数据:
Q: [复杂临床表现描述]
A: [需要7-8步推理才能得出诊断]
(强制深度推理)
这就是为什么MedResearcher-R1能够处理复杂医学问题——它在训练时就被迫学习了这种长链推理能力。
是不是有 KISA 就够了,KISA 本质就把 各种思维策略 + 结构化 + 模式识别 做出来了?
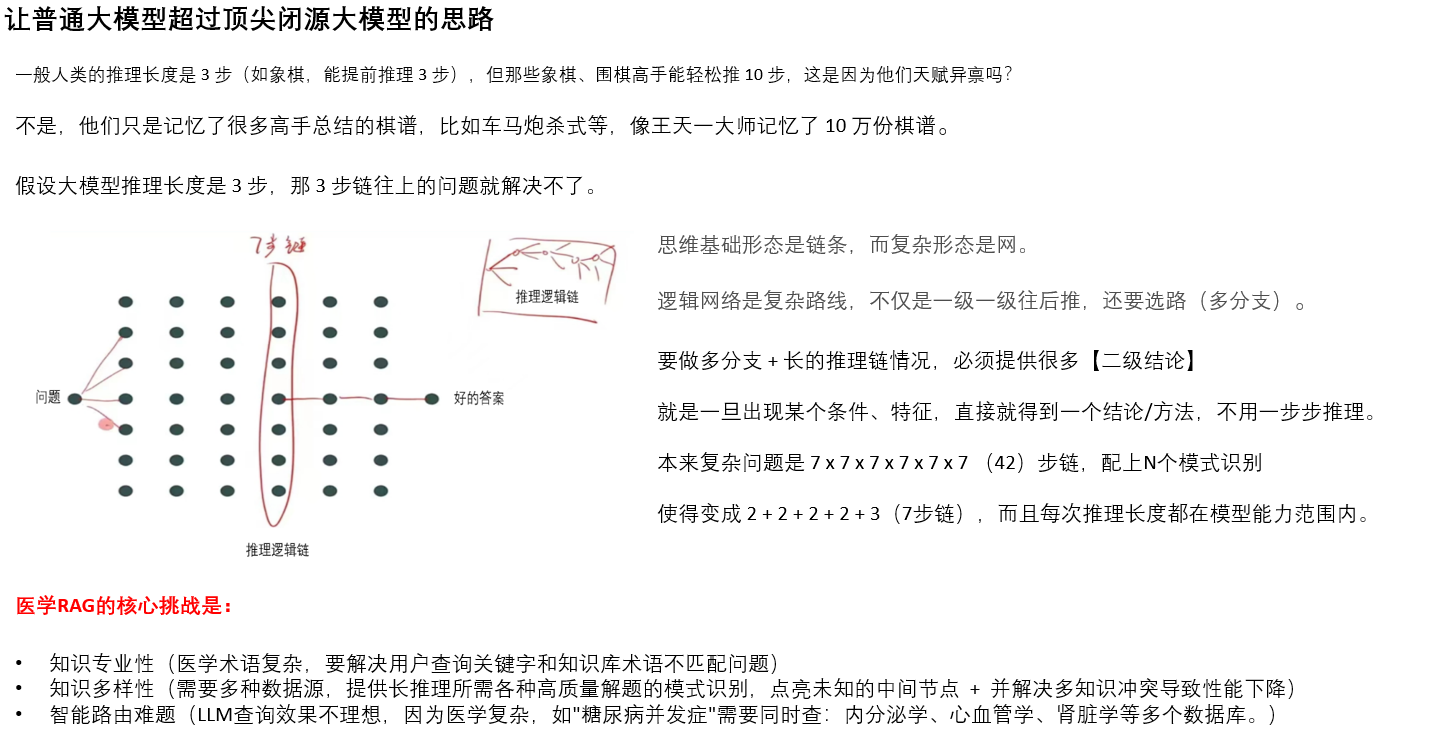
这是一个很尖锐的洞察。让我仔细分析KISA和图中方法的本质区别。
KISA vs 图中方法:本质差异
KISA做了什么
训练阶段:
罕见实体 → 知识图谱 → 最长路径 → 训练数据
让模型"学会"长链推理能力
图中方法要什么
推理阶段:
问题 → 模式识别 → N×M展开 → 多分支验证
让模型"执行"结构化搜索
关键区别
KISA的局限:
- 静态能力:训练后能力固定
- 线性偏向:主要学习链式推理
- 无法应对训练外模式:新类型问题仍可能失败
图中方法的独特价值:
- 动态展开:推理时根据问题复杂度调整
- 并行验证:多路径同时探索
- 模式复用:相同模式可用于不同问题
为什么KISA不够?
举个具体例子:
KISA训练过的路径:
A→B→C→D(罕见病诊断)
实际遇到的新问题:
A→?→?→E(相似但不同的病)
KISA:可能推理失败,因为没见过这条具体路径
图中方法:可以通过N×M搜索找到A→B'→C'→E
真正的关系
KISA和图中方法是互补而非替代:
KISA提供:深度(垂直能力)
- 学会复杂推理
- 理解领域逻辑
- 建立基础能力
图中方法提供:广度(水平能力)
- 运行时探索
- 并行验证
- 灵活适应
最优组合
训练时:KISA让模型学会推理模式
推理时:N×M让模型灵活运用模式
就像:
KISA = 学会下棋的定式
N×M = 实战时的变化应对
核心洞察
KISA确实很强大,但它解决的是"如何学会推理",而图中方法解决的是"如何灵活推理"。
两者结合才能真正突破:
- 只有KISA:会推理但不够灵活
- 只有N×M:会搜索但缺乏深度
- KISA+N×M:既有深度又有广度
这就像专家医生:既有深厚的知识积累(KISA),又能灵活应对新病例(N×M)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献104条内容
已为社区贡献104条内容

所有评论(0)