【每天一个知识点】零样本生成(Zero-shot Generation)
零样本生成是生成式AI无需专门训练即可完成新任务的能力,仅依靠预训练知识和用户提示就能输出结果。其优势在于降低数据依赖、提高通用性,但也面临质量不稳定、提示敏感等挑战。相比小样本和有监督学习,零样本更强调泛化能力。应用场景广泛,如客服、创作、教育等领域,推动AI从专用工具向通用助手发展。
1. 基本定义
零样本生成是生成式人工智能中的一个重要能力,指模型在没有任何该任务的标注样本或专门训练的前提下,仅依靠在预训练阶段所积累的知识和推理能力,就能够根据用户的提示(prompt)直接生成符合要求的结果。
这种能力体现了生成式模型的泛化能力和迁移能力:模型并不是死记硬背训练样本,而是学会了更普遍的语言模式、语义关系和世界知识,从而在新任务上“无师自通”。
2. 背景与原理
传统的机器学习和深度学习方法通常依赖大量带标签的数据进行训练。比如要让模型学会写新闻摘要,就必须提供成千上万条新闻与摘要的配对数据。
但零样本生成不同,它依靠的是:
-
大规模预训练:模型在海量文本、代码、图像数据上学习通用模式。
-
概率建模:学习到“在某种上下文下,什么样的输出最合理”。
-
提示词工程(Prompt Engineering):通过合适的提示,引导模型将已有知识迁移到新的任务上。
因此,零样本生成不需要“专门教”,只需要“正确问”。
3. 举例说明
-
自然语言处理
-
没有专门训练过“写邮件”的任务,但输入提示词:“请写一封向老师请假的电子邮件”,模型就能生成合适的邮件。
-
没有在“写对联”数据集上训练过,但输入:“请写一副关于春天的对联”,模型也能输出成对的句子。
-
-
跨语言翻译
-
假设模型没有在中文-西班牙语平行语料上训练过,但由于掌握了足够的中文和西班牙语语义知识,仍然能够直接进行翻译。
-
-
图像生成
-
输入一个前所未见的组合:“a panda playing violin in the snow”(一只在雪地拉小提琴的熊猫),模型虽然从未见过这种具体场景,但能生成合理的图像。
-
4. 优势与挑战
优势:
-
降低对大规模标注数据的依赖,节省成本。
-
提高了模型的通用性和灵活性,能快速适应新任务。
-
扩展了应用范围,比如用户随时可以提出“新问题”。
挑战:
-
生成结果的质量和可靠性可能不如专门训练的模型。
-
有时会出现“幻觉”(hallucination),即模型生成与事实不符的内容。
-
对提示词较为敏感,不同的提问方式可能导致结果差异很大。
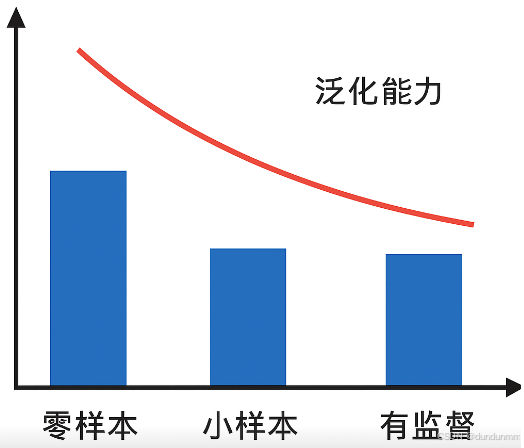
5. 与小样本(Few-shot)和有监督学习的比较
-
零样本(Zero-shot):不给模型示例,直接要求完成任务。
-
小样本(Few-shot):在提示中给少量示例,引导模型理解任务要求。
-
有监督(Supervised):提供大量样本,专门训练该任务。
这种比较可以总结为:
-
零样本强调“泛化”;
-
小样本强调“快速适应”;
-
有监督强调“专门化和高精度”。
6. 应用场景
-
智能客服与对话机器人:无需特定领域语料,就能回答常见问题。
-
内容创作:写文章、写故事、生成广告文案。
-
数据增强:自动生成多样化的训练样本。
-
教育领域:自动出题、写作文、生成学习案例。
-
医学、法律、科研等领域:快速生成摘要或初步报告(需人工审核)。
✅ 总结
零样本生成是生成式 AI 的一项核心能力,它体现了预训练+迁移+推理的威力,让模型在没有学过的任务上也能直接做出合理的生成。这一能力不仅拓展了人工智能的应用边界,也推动了人工智能从“专用工具”走向“通用助手”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)