多目标问题优化实战项目---NSGAII(Python实现)
本文介绍了多目标优化问题及其核心概念,重点讲解了NSGA-II算法的原理和实现。主要内容包括: 多目标优化基础:解释了Pareto支配关系、Pareto最优解和Pareto前沿等核心概念。 NSGA-II机制:详细解析了快速非支配排序和拥挤距离计算两个核心机制,用于平衡解的收敛性和多样性。 算法流程:完整描述了NSGA-II的迭代过程,包括种群合并、非支配排序和精英选择策略。 代码实现:提供了Py
🌞欢迎来到人工智能的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
📆首发时间:🌹2025年10月11日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录

基础概念与目标
多目标优化问题
决策者需要同时优化(最小化或最大化)两个或两个以上目标函数的优化问题。
多目标问题有两个特点:
(1)目标冲突: 多个目标之间往往相互矛盾。例如:汽车设计中,我们希望最小化油耗(目标
1)的同时,希望最大化性能(目标 2)。提高性能通常会增加油耗,反之亦然。
(2)无唯一解: 由于目标冲突,不存在一个“完美解”能使所有目标同时达到最优。
Pareto 支配
由于没有唯一的最佳解,我们需要一种新的方式来比较两个解的优劣。这就是 Pareto 支配。
核心规则: 假设我们有两个解 X 和 Y,且所有目标均为最小化。
| 条件 | 描述 |
| 条件 1 (不差于) | 解 X 在所有目标上的值都不比解 Y 差。 (即 fi(X)≤fi(Y) 对所有目标 i 成立) |
| 条件 2 (严格更好) | 至少存在一个目标 j,解 X 的值严格优于解 Y。 (即 fj(X)<fj(Y) 对至少一个 j 成立) |
结论: 如果 X 同时满足条件 1 和条件 2,则称 X 支配 Y (X≻Y)。
如果我们的目标是最小化f1和f2,支配结果如下表所示:
| 解 | 目标值 (f1,f2) | 支配关系分析 | 结论 |
| A | (1,5) | 比较 A 和 E(5,6): f1(A)<f1(E) (1<5); f2(A)<f2(E) (5<6)。 | A 支配 E |
| B | (2,4) | 比较 B 和 E(5,6): f1(B)<f1(E) (2<5); f2(B)<f2(E) (4<6)。 | B 支配 E |
| A | (1,5) | 比较 A 和 B(2,4): f1(A)<f1(B) (1<2); f2(A)>f2(B) (5>4)。 | 互不支配 |
Pareto 最优解与 Pareto 前沿 (PF)
Pareto 最优解 (Pareto Optimal Solution):
如果一个解 X∗ 不被任何可行解支配,那么它就是 Pareto 最优解。
NSGA-II 中,这些解被称为非支配解,它们是算法在当前阶段能找到的最佳权衡解。
Pareto 最优解集 (Pareto Set):
所有 Pareto 最优解的集合。
Pareto 前沿 (Pareto Front, PF):
Pareto 最优解集在目标函数空间中的映射。
NSGA-II 算法的目标就是找到一个近似的 Pareto 前沿,要求:收敛性好: 尽可能靠近真实的
Pareto 前沿。多样性好: 在前沿上分布均匀。
核心机制解析
NSGA-II 通过两个机制来平衡多目标优化中最重要的两个特性:收敛性和多样性。
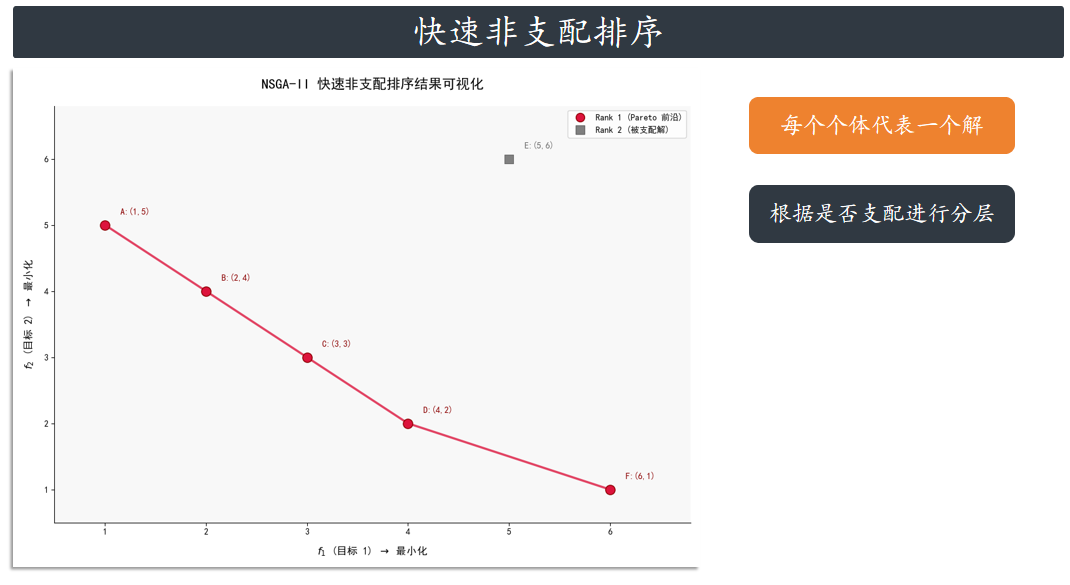
机制一:快速非支配排序 (Fast Non-dominated Sorting)
目的确定解的收敛性(即解的质量或优劣),确保算法向真实的 Pareto 前沿逼近。
核心对种群中的所有个体进行分层(即计算 Rank)。规则Rank (等级) 越小,解的质量越高,在
选择时越优先。 Rank 1 (或 F1) 包含所有当前种群中的 Pareto 最优解(非支配解)。
排序流程
给定一个种群 P,快速非支配排序将 P 划分为多个互不重叠的子集 F1,F2,F3,…:
确定 F1:
遍历所有解,找出不被任何其他解支配的集合,标记为 F1 (Rank 1)。
确定 F2:
将 F1 中的所有解暂时移除(或标记为已分层)。在剩余的解中,重新找出不被任何剩余解支配的
集合,标记为 F2 (Rank 2)。
重复:重复上述过程,直到种群中的所有解都被分层。
假设我们有6个个体,个体目标值 (f1,f2)
A(1,5) B(2,4) C(3,3) D(4,2) E(5,6) F(6,1)
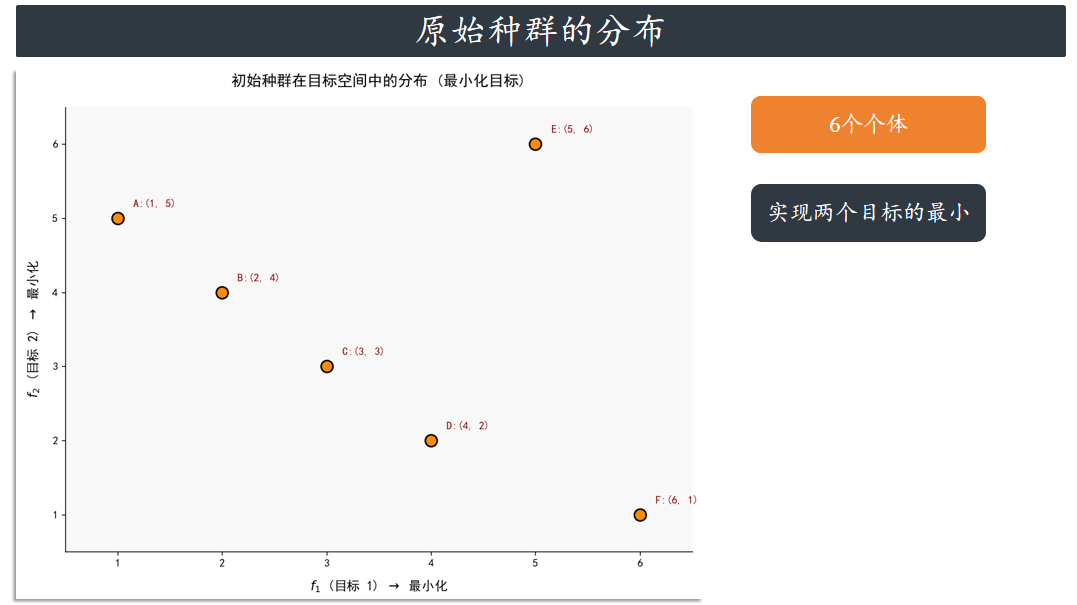
第一层(Rank 1):比较所有解,发现:
A(1,5) 被 B(2,4)支配?否(因为目标2:5>4,但目标1:1<2)。
A, B, C, D, E, F 两两比较后,A、B、C、D 互不支配(如A目标1最小,D目标2最小),且均支配
E(E的两个目标都差),F被D支配?否(目标2:1<2,但目标1:6>4)。
实际第一层:A, B, C, D, F(E被所有解支配)。简化理解:我们手动选出明显更好的解,如A(目
标1最优)和F(目标2最优)。
第二层(Rank 2):剩余解 E。
结果分层:
Rank 1: A, B, C, D, F
Rank 2: E
机制二:拥挤距离 (Crowding Distance)
目的确定解的多样性,确保种群均匀分布在 Pareto 前沿上。核心评估同一非支配层 Fi内个体周围
解的密度。规则拥挤距离越大,说明该个体周围越稀疏,其对多样性的贡献越大,在选择时越优
先。几何意义该个体与其在目标空间中最近的相邻解,在各个目标维度上构成的矩形周长。
计算流程
拥挤距离独立地对每一层 Fi进行计算:
边界处理: 将 Fi中,每个目标的最小和最大值对应的个体(即边界个体)的拥挤距离设为无穷大
(∞),以确保它们被保留。
中间个体:对于每个目标 j,将 Fi中的个体按 fj值排序。对于排序后的中间个体 I,其在目标 j 上的
拥挤贡献是其前后相邻个体的 fj值之差,除以该目标在整个 Fi上的范围(归一化)。
求和: 将所有目标上的贡献相加,得到该个体的总拥挤距离。
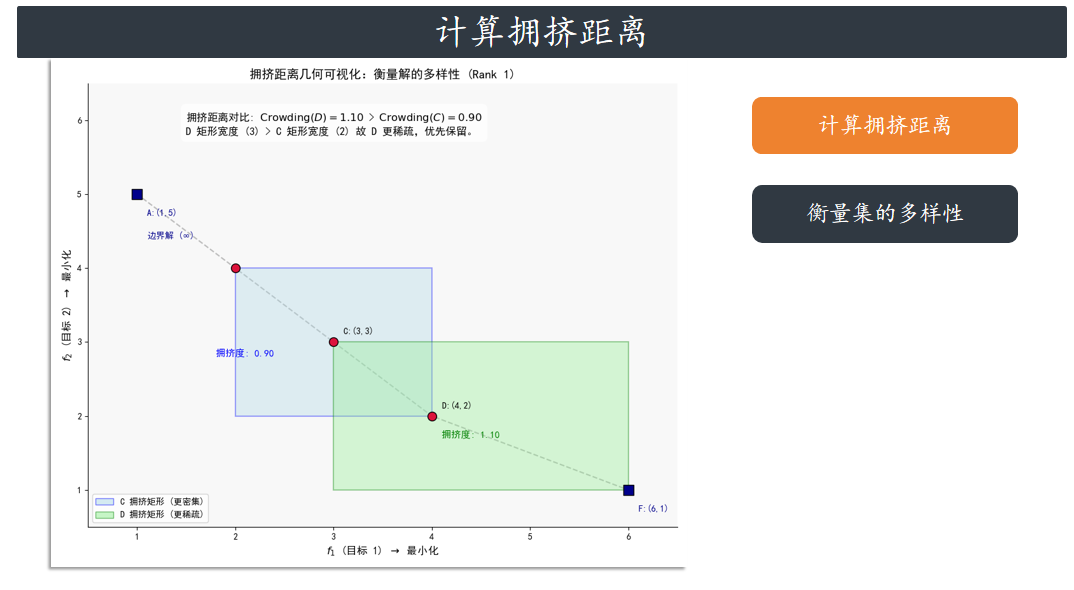
拥挤距离计算 (针对 F1)
我们只对 F1={A,B,C,D,F} 计算拥挤距离(Rank 2 的 E 只有一个,不需要计算)。
步骤 A:目标 1 排序与边界处理
| 序号 i | 解 | f1 值 |
| 1 | A | 1 |
| 2 | B | 2 |
| 3 | C | 3 |
| 4 | D | 4 |
| 5 | F | 6 |
f1,max=6, f1,min=1。 范围 R1=6−1=5
A 和 F 是 f1边界解,Crowding(A)=∞, Crowding(F)=∞
步骤 B:目标 2 排序与边界处理
| 序号 i | 解 | f2 值 |
| 1 | F | 1 |
| 2 | D | 2 |
| 3 | C | 3 |
| 4 | B | 4 |
| 5 | A | 5 |
f2,max=5,f2,min=1。 范围 R2=5−1=4
F 和 A 也是 f2 边界解(已处理)
步骤 C:计算中间解的拥挤距离
| 解 | f1 贡献 | f2 贡献 | 总拥挤距离 (未归一化) | 归一化拥挤距离 |
| B (2, 4) | (3−1)/5=2/5 | (5−3)/4=2/4 | 2+2=4 | 0.4+0.5=0.9 |
| C (3, 3) | (4−2)/5=2/5 | (4−2)/4=2/4 | 2+2=4 | 0.4+0.5=0.9 |
| D (4, 2) | (6−3)/5=3/5 | (3−1)/4=2/4 | 3+2=5 | 0.6+0.5=1.1 |
结论:
A 和 F 的拥挤距离为 ∞
D 的拥挤距离 (1.1) 大于 B 和 C (0.9)
物理意义: D(4,2) 在 f1 轴上的邻居距离(3)比 B,C(2)更远,说明 D 位于更稀疏的区域,因此
对多样性的贡献最大
完整的迭代流程与精英选择
整体流程回顾
NSGA-II 基于遗传算法的循环迭代,但关键的区别在于选择阶段。
-
初始化 Pt:随机生成 N 个个体(父代)。
-
生成 Qt:通过交叉、变异等操作生成 N 个子代。
-
合并 Rt:合并 Pt 和 Qt 得到 2N 个个体的种群。
-
排序 Rt:对 Rt 进行 快速非支配排序 →F1,F2,F3,…。
-
选择 Pt+1:从 F1 开始,逐层选择,直到新种群 Pt+1 达到 N 个个体。
核心步骤就在于第 5 步,即如何从 Rt 中选出 N 个精英个体。
精英选择规则 (Selection Rule)
NSGA-II 引入了一个精英保留策略,通过自定义的比较操作符 (≺n) 来指导选择过程。
对于两个个体 I1和 I2,我们称 I1 优于 I2 (I1≺nI2),当且仅当满足以下任一条件:
基于 Rank 优先 (收敛性):
Rank(I1)<Rank(I2)
(I1属于更低的非支配层,质量更高。)或
基于拥挤距离优先 (多样性):
Rank(I1)=Rank(I2)且Crowding(I1)>Crowding(I2)
(I1 和 I2 质量相同,但 I1 位于更稀疏的区域,多样性贡献更大。)
这个比较操作符决定了算法在每一次选择时,如何取舍个体。
构造下一代种群 Pt+1
目标是从 2N 个体的 Rt 中选出 N 个个体进入 Pt+1
按层加入: 从 Rank 1 (F1) 开始,将整层个体加入 Pt+1。然后是 F2,F3,…。
Pt+1=F1∪F2∪⋯∪Fl−1直到加入某一层 Fl 后,总个体数量会超过 N。
精英选择 (处理 Fl): 假设 Pt+1中已经有 M 个个体,我们还需要 K=N−M 个个体。
对 Fl中的所有个体计算拥挤距离。按拥挤距离降序排序 Fl 中的个体。选择排在前 K 位的个体加入
Pt+1。
案例应用:下一代选择计算
假设您的案例已经进入选择阶段,并且我们已经合并了父代和子代,得到了 R 种群:
| 个体 | (f1,f2) | Rank | 拥挤距离 |
| A | (1, 5) | 1 | ∞ |
| F | (6, 1) | 1 | ∞ |
| D | (4, 2) | 1 | 1.1 |
| B | (2, 4) | 1 | 0.9 |
| C | (3, 3) | 1 | 0.9 |
| E | (5, 6) | 2 | - |
假设种群容量 N=4
按层加入 Pt+1:
尝试加入 F1={A,B,C,D,F}
∣F1∣=5。由于 5>N=4,我们不能将 F1 全部加入,因此 F1 就是关键层 Fl。
Pt+1 中目前个体数 M=0,还需要 K=4−0=4 个个体。
对 F1 进行精英选择 (选择 4 个):
排序依据: 拥挤距离降序排列。
排序结果: A(∞)≻F(∞)≻D(1.1)≻B(0.9)∼C(0.9)
选择前 4 个:
选择 A (拥挤度 ∞)
选择 F (拥挤度 ∞)
选择 D (拥挤度 1.1)
选择 B (拥挤度 0.9) (注:B 和 C 拥挤度相同,实际算法中会随机选择一个,我们选B。)
最终 Pt+1 (下一代种群):
Pt+1={A,F,D,B}
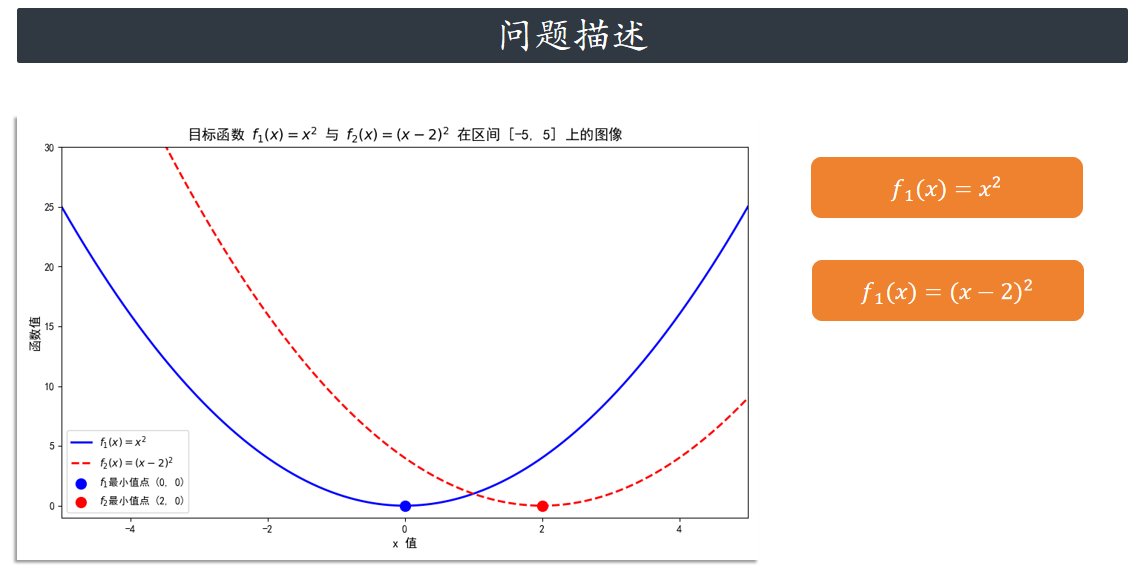
算法实战
比如我们的优化目标是:双目标函数的最小化

解集的输出和可视化
import numpy as np
import matplotlib.pyplot as plt
from pymoo.algorithms.moo.nsga2 import NSGA2
from pymoo.optimize import minimize
from pymoo.core.problem import ElementwiseProblem
import pandas as pd # 引入pandas,用于美观地格式化输出表格
# --- 解决中文显示问题 ---
try:
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
except:
pass
plt.rcParams['axes.unicode_minus'] = False
# -------------------------
# --- 1. 定义最简单的双目标问题 ---
class SimpleMOP(ElementwiseProblem):
def __init__(self):
super().__init__(n_var=1, n_obj=2, xl=np.array([-5.0]), xu=np.array([5.0]))
def _evaluate(self, X, out, *args, **kwargs):
x = X[0]
f1 = x**2
f2 = (x - 2)**2
out["F"] = [f1, f2]
# --- 2. 算法设置与执行 (保持不变) ---
problem = SimpleMOP()
algorithm = NSGA2(pop_size=100, n_offsprings=100, eliminate_duplicates=True)
termination = ('n_gen', 50)
print("--- NSGA-II 算法开始执行 (简单MOP) ---")
res = minimize(problem, algorithm, termination, seed=42, verbose=False) # 设为False,减少过程输出
print("--- NSGA-II 算法执行完毕 ---")
X_final = res.X # 最终的决策变量 x
F_final = res.F # 最终的目标函数值 (f1, f2)
# --- 3. 结果可视化 (美观定制,含中文) ---
plt.figure(figsize=(10, 8))
ax = plt.gca()
# 3.1 绘制真实的 Pareto 前沿 (PF)
f1_pf = np.linspace(0, 4, 100)
f2_pf = (np.sqrt(f1_pf) - 2)**2
plt.plot(f1_pf, f2_pf, color='black', linestyle='--', label='真实 Pareto 前沿 (PF)', linewidth=1.5)
# 3.2 绘制 NSGA-II 找到的近似 Pareto 前沿
sorted_F = F_final[np.argsort(F_final[:, 0])]
plt.scatter(sorted_F[:, 0], sorted_F[:, 1],
color='#1E90FF', s=70,
edgecolors='black', linewidths=0.8,
label='NSGA-II 最终解集')
# 3.3 突出关键点 (使用中文标签)
plt.scatter(0, 0, marker='*', s=300, color='gold', label='理想点 (0, 0)')
plt.scatter(0, 4, marker='D', s=100, color='red', label='极值点 (f1最优)')
plt.scatter(4, 0, marker='D', s=100, color='green', label='极值点 (f2最优)')
# 标注极值点
plt.annotate('f1 最优解 (x≈0)', (0.1, 4.2), color='red', fontsize=10, fontweight='bold')
plt.annotate('f2 最优解 (x≈2)', (4.1, 0.1), color='green', fontsize=10, fontweight='bold')
# 3.4 图表美化 (中文标题和轴标签)
plt.title('NSGA-II 解决简单双目标问题:$f_1=x^2, f_2=(x-2)^2$', fontsize=16, fontweight='bold', pad=20)
plt.xlabel('$f_1$ (目标 1) $\\rightarrow$ 最小化', fontsize=14)
plt.ylabel('$f_2$ (目标 2) $\\rightarrow$ 最小化', fontsize=14)
plt.xlim(-0.5, 5)
plt.ylim(-0.5, 5)
plt.grid(True, linestyle=':', alpha=0.6)
plt.legend(loc='upper right', fontsize=10)
plt.show()
# --- 4. 打印最终解集信息 (可选) ---
print("\n--- 最终解集信息 ---")
print(f"找到的非支配解数量: {len(F_final)}")
print("部分决策变量 x 和目标值 (f1, f2):")
extreme_f1 = sorted_F[0]
extreme_f2 = sorted_F[-1]
print(f" 接近f1最优解: f1={extreme_f1[0]:.4f}, f2={extreme_f1[1]:.4f}")
print(f" 接近f2最优解: f1={extreme_f2[0]:.4f}, f2={extreme_f2[1]:.4f}")
# --- 4. 详细输出最终的解集 (关键更改在这里) ---
# 创建一个DataFrame,将决策变量 X 和目标值 F 整合
results_df = pd.DataFrame({
'决策变量 X': X_final.flatten(),
'目标值 f1 ($x^2$)': F_final[:, 0],
'目标值 f2 ($(x-2)^2$)': F_final[:, 1]
})
# 按决策变量 X 排序,使结果更具逻辑性
results_df = results_df.sort_values(by='决策变量 X').reset_index(drop=True)
print("\n=======================================================")
print(f"| NSGA-II 找到的最终非支配解集 (共 {len(results_df)} 个解) |")
print("=======================================================")
# 仅输出部分关键解(例如头部、尾部和中间解),避免输出表格过长
print("\n--- 1. 极值解和中间权衡解 ---")
# 找到 f1 最优(x≈0)的解
f1_min_idx = results_df['目标值 f1 ($x^2$)'].idxmin()
# 找到 f2 最优(x≈2)的解
f2_min_idx = results_df['目标值 f2 ($(x-2)^2$)'].idxmin()
# 找到中间权衡的解(x≈1)
x_middle_idx = results_df['决策变量 X'].abs().sub(1).idxmin() # 找到 X 最接近 1 的行
summary_data = [
results_df.loc[f1_min_idx],
results_df.loc[x_middle_idx],
results_df.loc[f2_min_idx]
]
summary_df = pd.DataFrame(summary_data, index=['f1 最优权衡点', '中间权衡点 (x≈1)', 'f2 最优权衡点'])
# 格式化输出
pd.set_option('display.float_format', '{:.5f}'.format)
print(summary_df.to_string())
print("\n--- 2. 完整解集示例 (仅展示前 5 个和后 5 个) ---")
print("\n[解集头部 (接近 f1 最优, x≈0)]")
print(results_df.head(5).to_string(index=False))
print("\n[解集尾部 (接近 f2 最优, x≈2)]")
print(results_df.tail(5).to_string(index=False))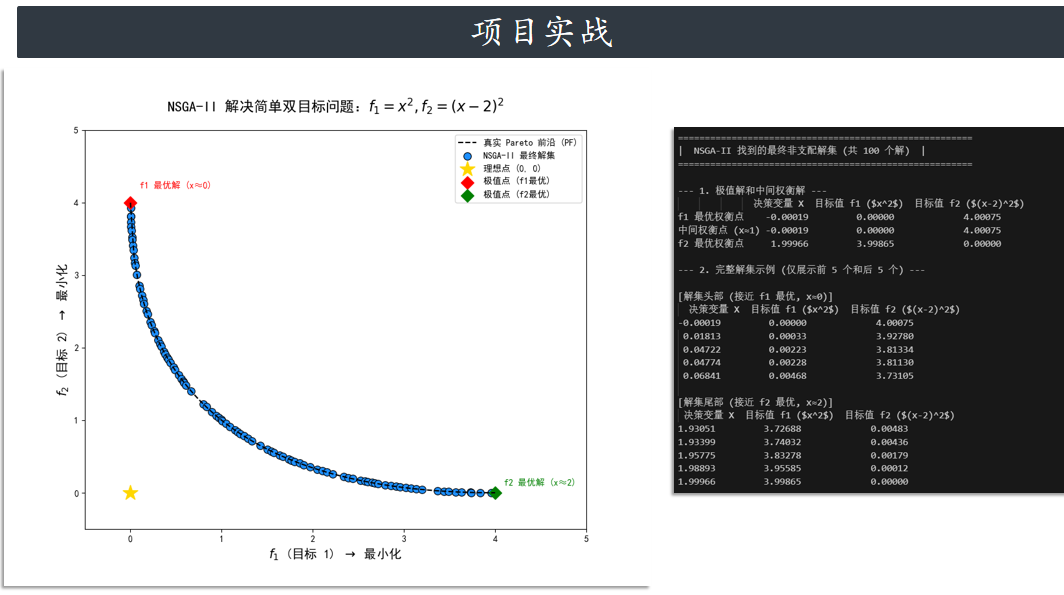
代码的详细解释
import numpy as np
import matplotlib.pyplot as plt
from pymoo.algorithms.moo.nsga2 import NSGA2
from pymoo.optimize import minimize
from pymoo.core.problem import ElementwiseProblem
import pandas as pd # 引入pandas,用于美观地格式化输出表格
# --- 解决中文显示问题 ---
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# -------------------------
# --- 1. 定义最简单的双目标问题 ---
class SimpleMOP(ElementwiseProblem):
def __init__(self):
super().__init__(n_var=1, n_obj=2, xl=np.array([-5.0]), xu=np.array([5.0]))
def _evaluate(self, X, out, *args, **kwargs):
x = X[0]
f1 = x**2
f2 = (x - 2)**2
out["F"] = [f1, f2]
# --- 2. 算法设置与执行 (保持不变) ---
problem = SimpleMOP()
algorithm = NSGA2(pop_size=100, n_offsprings=100, eliminate_duplicates=True)
termination = ('n_gen', 50)
print("--- NSGA-II 算法开始执行 (简单MOP) ---")
res = minimize(problem, algorithm, termination, seed=42, verbose=False) # 设为False,减少过程输出
print("--- NSGA-II 算法执行完毕 ---")
X_final = res.X # 最终的决策变量 x
F_final = res.F # 最终的目标函数值 (f1, f2)
sorted_F = F_final[np.argsort(F_final[:, 0])]
# --- 4. 打印最终解集信息 (可选) ---
print("\n--- 最终解集信息 ---")
print(f"找到的非支配解数量: {len(F_final)}")
print("部分决策变量 x 和目标值 (f1, f2):")
extreme_f1 = sorted_F[0]
extreme_f2 = sorted_F[-1]
print(f" 接近f1最优解: f1={extreme_f1[0]:.4f}, f2={extreme_f1[1]:.4f}")
print(f" 接近f2最优解: f1={extreme_f2[0]:.4f}, f2={extreme_f2[1]:.4f}")
# --- 4. 详细输出最终的解集 (关键更改在这里) ---
# 创建一个DataFrame,将决策变量 X 和目标值 F 整合
results_df = pd.DataFrame({
'决策变量 X': X_final.flatten(),
'目标值 f1 ($x^2$)': F_final[:, 0],
'目标值 f2 ($(x-2)^2$)': F_final[:, 1]
})
# 按决策变量 X 排序,使结果更具逻辑性
results_df = results_df.sort_values(by='决策变量 X').reset_index(drop=True)
print("\n=======================================================")
print(f"| NSGA-II 找到的最终非支配解集 (共 {len(results_df)} 个解) |")
print("=======================================================")
# 仅输出部分关键解(例如头部、尾部和中间解),避免输出表格过长
print("\n--- 1. 极值解和中间权衡解 ---")
# 找到 f1 最优(x≈0)的解
f1_min_idx = results_df['目标值 f1 ($x^2$)'].idxmin()
# 找到 f2 最优(x≈2)的解
f2_min_idx = results_df['目标值 f2 ($(x-2)^2$)'].idxmin()
# 找到中间权衡的解(x≈1)
x_middle_idx = results_df['决策变量 X'].abs().sub(1).idxmin() # 找到 X 最接近 1 的行
summary_data = [
results_df.loc[f1_min_idx],
results_df.loc[x_middle_idx],
results_df.loc[f2_min_idx]
]
summary_df = pd.DataFrame(summary_data, index=['f1 最优权衡点', '中间权衡点 (x≈1)', 'f2 最优权衡点'])
# 格式化输出
pd.set_option('display.float_format', '{:.5f}'.format)
print(summary_df.to_string())
print("\n--- 2. 完整解集示例 (仅展示前 5 个和后 5 个) ---")
print("\n[解集头部 (接近 f1 最优, x≈0)]")
print(results_df.head(5).to_string(index=False))
print("\n[解集尾部 (接近 f2 最优, x≈2)]")
print(results_df.tail(5).to_string(index=False))定义函数
这里会定义一个类,有几个参数,几个目标函数,以及参数的边界
# -------------------------
# --- 1. 定义最简单的双目标问题 ---
class SimpleMOP(ElementwiseProblem):
def __init__(self):
super().__init__(n_var=1, n_obj=2, xl=np.array([-5.0]), xu=np.array([5.0]))
def _evaluate(self, X, out, *args, **kwargs):
x = X[0]
f1 = x**2
f2 = (x - 2)**2
out["F"] = [f1, f2]算法设置与执行
定义问题,定义算法(种群大小、每代产生的子代数量、是否自动去除重复解)、设置终止条件
(算法将运行 50 代后停止)
problem = SimpleMOP()
algorithm = NSGA2(pop_size=100, n_offsprings=100, eliminate_duplicates=True)
termination = ('n_gen', 50)minimize是 pymoo 库的核心函数,专门用于求解单目标 / 多目标优化问题。对于多目标问题(如
本例),它会驱动算法(NSGA-II)迭代搜索,最终返回包含 “非支配解集”“算法运行信息” 等的完
整结果对象。
| 参数名 | 含义与作用 |
|---|---|
problem |
传入之前定义的问题实例 |
algorithm |
传入之前配置的算法实例(NSGA2(...)的对象)。告诉函数 “用什么方法求解”,包括种群大小、子代数量、去重机制等(从 NSGA-II 配置中读取)。 |
termination |
传入之前定义的终止条件(('n_gen', 50))。告诉函数 “何时停止迭代”,本例中为 “运行 50 代后停止”。 |
seed=42 |
随机种子(Random Seed)。设置固定种子(如 42)可让算法每次运行的初始种群、交叉 / 变异随机过程完全一致,确保结果可复现(否则每次运行结果可能不同)。 |
verbose=False |
是否输出迭代过程信息。False表示关闭过程输出(仅在运行结束后返回结果);若设为True,会实时打印每一代的种群大小、目标函数均值等信息(适合调试,但会增加输出冗余)。 |
X_final里面是100个决策变量 x,F_final 里面是100个最终的目标函数值 (f1, f2),将多目标优化
结果按第一个目标f1的优劣重新排列。
res = minimize(problem, algorithm, termination, seed=42, verbose=False) # 设为False,减少过程输出
X_final = res.X # 最终的决策变量 x
F_final = res.F # 最终的目标函数值 (f1, f2)
sorted_F = F_final[np.argsort(F_final[:, 0])]
print(sorted_F.shape)
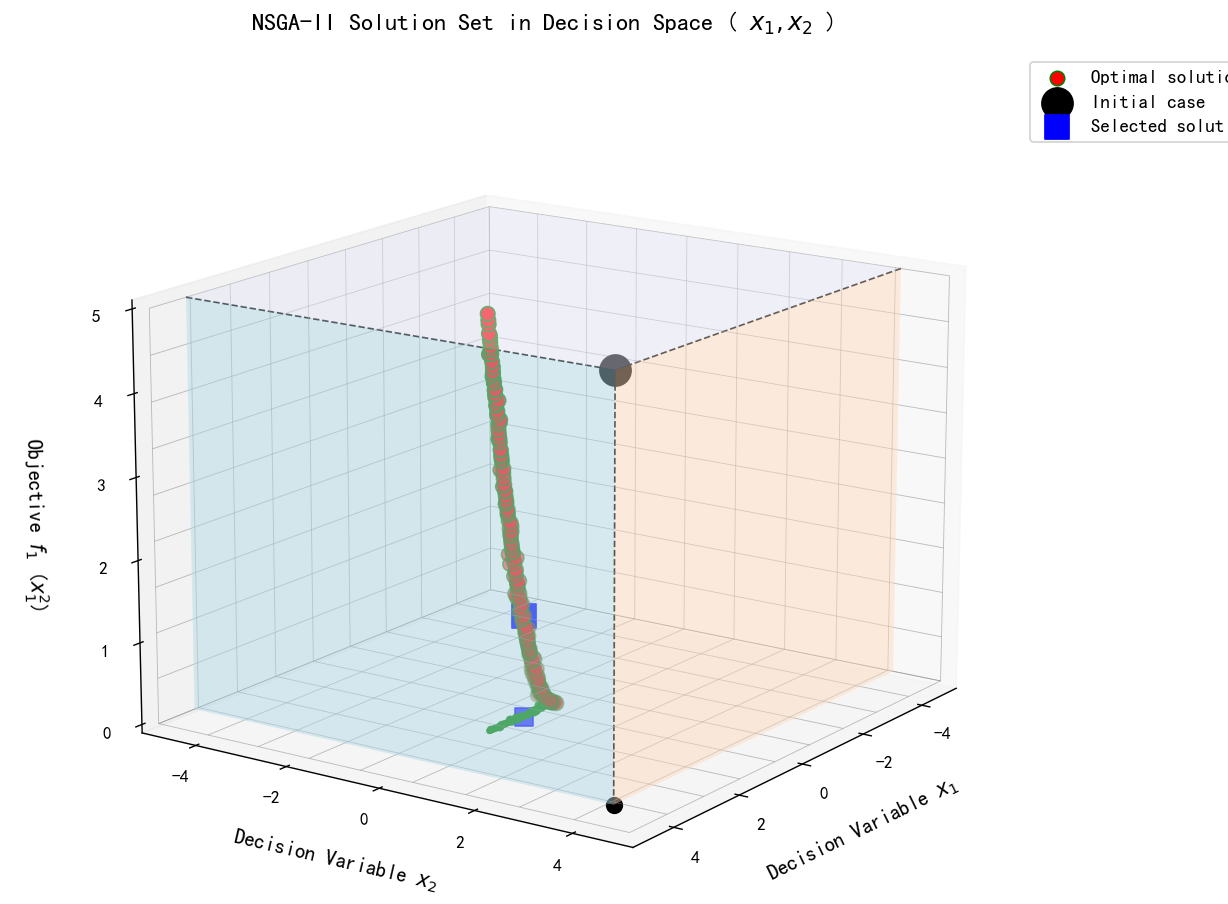
print(sorted_F)3D图形
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from pymoo.algorithms.moo.nsga2 import NSGA2
from pymoo.optimize import minimize
from pymoo.core.problem import ElementwiseProblem
# ---------- 中文显示(可选) ----------
try:
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
except:
pass
plt.rcParams['axes.unicode_minus'] = False
# --- 定义问题 ---
class TwoVarMOP(ElementwiseProblem):
def __init__(self):
super().__init__(n_var=2, n_obj=2, xl=np.array([-5.0, -5.0]), xu=np.array([5.0, 5.0]))
def _evaluate(self, X, out, *args, **kwargs):
x1 = X[0]
x2 = X[1]
f1 = x1**2
f2 = (x1 - 2)**2 + x2**2
out["F"] = [f1, f2]
problem = TwoVarMOP()
algorithm = NSGA2(pop_size=200, n_offsprings=200, eliminate_duplicates=True)
termination = ('n_gen', 100)
res = minimize(problem, algorithm, termination, seed=42, verbose=False)
X_final = res.X
F_final = res.F
x1_data = X_final[:, 0]
x2_data = X_final[:, 1]
f1_data = F_final[:, 0]
# ---------- 绘图函数 ----------
def plot_style_like_reference(x1_data, x2_data, f1_data, scale_z=True):
if scale_z:
z_vis_max = 5.0
f1_min, f1_max = f1_data.min(), f1_data.max()
f1_scaled = (f1_data - f1_min) / (f1_max - f1_min) * z_vis_max
else:
f1_scaled = f1_data.copy()
z_vis_max = max(1.0, f1_scaled.max())
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# 轴范围
x_min, x_max = problem.xl[0], problem.xu[0]
y_min, y_max = problem.xl[1], problem.xu[1]
z_min, z_max = 0, z_vis_max
# ---------- 灰色方格背景墙 ----------
grid_res = 10
xg = np.linspace(x_min, x_max, grid_res)
yg = np.linspace(y_min, y_max, grid_res)
zg = np.linspace(z_min, z_max, grid_res)
# 底面 XY
Xb, Yb = np.meshgrid(xg, yg)
Zb = np.zeros_like(Xb)
ax.plot_wireframe(Xb, Yb, Zb, color='gray', alpha=0.5, linewidth=0.5)
# 背面 YZ(x = x_min)
Yb2, Zb2 = np.meshgrid(yg, zg)
Xb2 = np.full_like(Yb2, x_min)
ax.plot_wireframe(Xb2, Yb2, Zb2, color='gray', alpha=0.5, linewidth=0.5)
# ✅ 左侧 XZ 平面网格(y = y_min)
Xb3, Zb3 = np.meshgrid(xg, zg)
Yb3 = np.full_like(Xb3, y_min)
ax.plot_wireframe(Xb3, Yb3, Zb3, color='gray', alpha=0.5, linewidth=0.5)
# ---------- 最优解(红点 + 绿色边框) ----------
ax.scatter(x1_data, x2_data, f1_scaled, c='red', s=70, edgecolors='green',
linewidths=0.9, label='Optimal solution', zorder=6)
ax.scatter(x1_data, x2_data, np.zeros_like(f1_scaled),
c='green', marker='.', s=30, alpha=0.8, zorder=5)
# ---------- 初始点(Initial case) ----------
x1_init, x2_init = 4.0, 4.0
# 大黑球
ax.scatter(x1_init, x2_init, z_max, c='black', s=320, marker='o', zorder=10, label='Initial case')
# 三条竖线(引到三个平面)
ax.plot([x1_init, x1_init], [x2_init, x2_init], [z_min, z_max], '--k', lw=1)
ax.plot([x_min, x1_init], [x2_init, x2_init], [z_max, z_max], '--k', lw=1)
ax.plot([x1_init, x1_init], [y_min, x2_init], [z_max, z_max], '--k', lw=1)
# 彩色三面墙
color_yz = '#ADD8E6' # 淡蓝
color_xz = '#FFDAB9' # 淡橙
color_xy = '#E6E6FA' # 淡紫
alpha_plane = 0.45
# 面1:平行 yz 面
yy = np.linspace(y_min, x2_init, 2)
zz = np.linspace(z_min, z_max, 2)
YY, ZZ = np.meshgrid(yy, zz)
XX = np.full_like(YY, x1_init)
ax.plot_surface(XX, YY, ZZ, color=color_yz, alpha=alpha_plane, shade=False)
# 面2:平行 xz 面
xx = np.linspace(x_min, x1_init, 2)
zz = np.linspace(z_min, z_max, 2)
XX, ZZ = np.meshgrid(xx, zz)
YY = np.full_like(XX, x2_init)
ax.plot_surface(XX, YY, ZZ, color=color_xz, alpha=alpha_plane, shade=False)
# 面3:平行 xy 面
xx = np.linspace(x_min, x1_init, 2)
yy = np.linspace(y_min, x2_init, 2)
XX, YY = np.meshgrid(xx, yy)
ZZ = np.full_like(XX, z_max)
ax.plot_surface(XX, YY, ZZ, color=color_xy, alpha=alpha_plane, shade=False)
# 投影点(顶 & 底)
ax.scatter(x1_init, x2_init, z_min, c='black', s=80, marker='o', zorder=9)
# ---------- 选定解(Selected solution) ----------
x1_ideal = 1.0
idx_sel = np.argmin(np.abs(x1_data - x1_ideal))
x1_sel, x2_sel, f1_sel = x1_data[idx_sel], x2_data[idx_sel], f1_scaled[idx_sel]
ax.scatter(x1_sel, x2_sel, f1_sel, c='blue', marker='s', s=180, label='Selected solution', zorder=10)
ax.scatter(x1_sel, x2_sel, z_min, c='blue', marker='s', s=100, alpha=0.8, zorder=9)
# ---------- 坐标轴与样式 ----------
ax.set_title('NSGA-II Solution Set in Decision Space ( $x_1, x_2$ )', fontsize=14, pad=12)
ax.set_xlabel('Decision Variable $x_1$', fontsize=12, labelpad=12)
ax.set_ylabel('Decision Variable $x_2$', fontsize=12, labelpad=12)
ax.set_zlabel('Objective $f_1$ ($x_1^2$)', fontsize=12, labelpad=12)
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
ax.set_zlim(z_min, z_max)
ax.view_init(elev=22, azim=-60)
ax.legend(loc='upper left', fontsize=11, framealpha=0.85, bbox_to_anchor=(1.02, 1.0))
ax.grid(False)
plt.tight_layout()
plt.show()
# 调用绘图函数
plot_style_like_reference(x1_data, x2_data, f1_data, scale_z=True)


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 25
25 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)