LazyLLM端到端实战:用RAG+Agent实现自动出题与学习计划的个性化学习助手智能体
这个高效AI Agent的实现,离不开 LazyLLM 框架的强大支撑:其低代码特性大幅降低了开发门槛,模块化设计让复杂的多智能体系统搭建变得简单,从环境配置到功能部署仅需少量代码和简单操作即可完成,无论是快速搭建聊天机器人,还是构建基于 RAG 技术的检索增强应用,都能轻松实现,充分体现了框架在易用性上的显著优势。经过多方比较,最终我使用LazyLLM制作了一个专属的学习助手Agent,这个Ag
1. 为什么做这个学习助手Agent?
最近,我在写一本关于Git和开源的技术书,这本书未来有个推广方向,就是面向高校作为教材使用。所以我需要在每一章结束在之后,设计若干道练习题,然后还需要为这本书编写配套的PPT以及学习计划,作为授课老师的参考资料。基于我在Git实际操作管理方面积累的经验以及参与各类开源项目竞赛的经历,书稿本身的撰写过程相对顺利,目前也已经完成了几个章节内容的编写。
真正的挑战在于如何通过精心设计的习题和学习计划,确保为读者提供最优质的学习体验,从而最大化地发挥这本书的价值。在这方面,我投入了大量的时间和精力。为了提高效率,我调研了一些AI Agent,希望通过AI辅助完成这部分工作。经过多方比较,最终我使用LazyLLM制作了一个专属的学习助手Agent,这个Agent可以基于我提供的书稿内容,为我快速并且高质量的完成出题和学习计划的规划任务,让我的写书之旅变的更加高效。
2. 快速认识LazyLLM
2.1 LazyLLM简介
LazyLLM是商汤科技推出的一款开源低代码大模型应用开发框架。该框架采用模块化设计理念,极大地简化了应用程序的开发流程,使开发者能够以最少仅需10行代码即可迅速构建出复杂的多智能体系统,如例如机器人、检索增强生成(RAG)和多模态应用。
此外,LazyLLM还支持通过统一接口调用在线服务如ChatGPT或本地部署的模型例如LightLLM,并且具备数据流管理及模型微调功能。一旦完成了智能体应用的组装,用户可以利用其提供的轻量化网关轻松地将其一键部署到诸如Web页面、企业微信等多种终端平台上,同时保证了对Windows/Linux操作系统以及不同类型计算资源的良好兼容性。
2.2 为什么选择LazyLLM
在LazyLLM中基于检索增强生成(RAG)开发检索应用,为我的技术书籍编写项目带来了显著的优势。首先,RAG方法巧妙地结合了检索和生成模型,能够极大地提升模型对上下文的理解能力,从而使得生成的回答不仅更加准确、相关,而且富有深度。这对于设计高质量的练习题和学习计划至关重要。
同时,LazyLLM还可以灵活的调整模型,可以根据Agent的实际表现进行动态的调整,使其灵活适应不同的场景。这种强大的检索能力和高度的灵活性,使LazyLLM成为我写书过程中的理想辅助工具。通过使用LazyLLM创建的学习助手Agent,我可以高效且高质量地完成出题及学习计划的制定工作,极大地提高了我的效率,使得我能够将更多的精力专注于书稿内容的撰写上。
3. 五分钟上手LazyLLM
得益于高度模块化封装和极简架构的设计,LazyLLM使用起来是非常简单的:
- 一条命令搭建开发环境:
<span style="color:#000000"><span style="background-color:#ffffff"><code class="language-bash">pip3 install lazyllm
</code></span></span>- 环境变量动态配置模型供应商:
<span style="color:#000000"><span style="background-color:#ffffff"><code class="language-bash"><span style="color:#ae7313">export</span> LAZYLLM_SENSENOVA_API_KEY=sk-******
</code></span></span>- 3行代码搭建聊天机器人:
<span style="color:#000000"><span style="background-color:#ffffff"><code class="language-python"><span style="color:#5f9182">import</span> lazyllm
chat = lazyllm.OnlineChatModule()
lazyllm.WebModule(chat, port=<span style="color:#ae7313">23333</span>).start().wait()
</code></span></span>- 10行代码搭建RAG Agent:
<span style="color:#000000"><span style="background-color:#ffffff"><code class="language-python"><span style="color:#5f9182">import</span> lazyllm
<span style="color:#6c6b5a"># 文档加载</span>
documents = lazyllm.Document(dataset_path=<span style="color:#7d9726">"/content/docs"</span>)
<span style="color:#6c6b5a"># 检索组件定义</span>
retriever = lazyllm.Retriever(doc=documents, group_name=<span style="color:#7d9726">"CoarseChunk"</span>, similarity=<span style="color:#7d9726">"bm25_chinese"</span>, topk=<span style="color:#ae7313">3</span>)
<span style="color:#6c6b5a"># 生成组件定义</span>
llm = lazyllm.OnlineChatModule(source=<span style="color:#7d9726">"sensenova"</span>, model=<span style="color:#7d9726">"SenseChat-5-1202"</span>)
<span style="color:#6c6b5a"># prompt 设计</span>
prompt = <span style="color:#7d9726">'You will act as an AI question-answering assistant and complete a dialogue task. In this task, you need to provide your answers based on the given context and questions.'</span>
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=[<span style="color:#7d9726">'context_str'</span>]))
<span style="color:#6c6b5a"># 推理</span>
query = <span style="color:#7d9726">"为我介绍下玉山箭竹"</span>
<span style="color:#6c6b5a"># 将Retriever组件召回的节点全部存储到列表doc_node_list中</span>
doc_node_list = retriever(query=query)
<span style="color:#6c6b5a"># 将query和召回节点中的内容组成dict,作为大模型的输入</span>
res = llm({<span style="color:#7d9726">"query"</span>: query, <span style="color:#7d9726">"context_str"</span>: <span style="color:#7d9726">""</span>.join([node.get_content() <span style="color:#5f9182">for</span> node <span style="color:#5f9182">in</span> doc_node_list])})
<span style="color:#ae7313">print</span>(<span style="color:#7d9726">f'With RAG Answer: {res}'</span>)
</code></span></span>关于LazyLLM的搭建步骤、使用方法、参考案例等可以参考LazyLLM公众号文章:《LazyLLM教程 | 第2讲:10分钟上手一个最小可用RAG系统》,推荐大家反复阅读学习,我就不再这里赘述了。
官方还推出了【20小时通关工业级RAG】系列视频课程,对AI、LLM、RAG、Agent等技术感兴趣的,可以关注下。
4. 实现个性化学习助手Agent
4.1 架构与流程图
检索增强生成(Retrieval-augmented Generation,RAG)是一种先进的大模型技术,它通过从大量文档中搜索相关信息来辅助文本生成或问题回答。这种方法结合了信息检索和文本生成的优点,使生成的内容更加准确且基于实际数据,从而提升了回答的质量和可靠性。简单说,就是RAG能让模型生成更精确、更有依据的文本。
一般来说 RAG 的流程如上图所示。其中:
- Document(文档集合):文档集合,存放着原始文档。对于我来说,这里的Document指的就是我的书稿原件。
- Query(用户指令):用户要查询的内容或者说用户指令。对于我来说,就是类似
<font style="color:rgba(0, 0, 0, 0.87);">生成题库</font>和<font style="color:rgba(0, 0, 0, 0.87);">生成个性化学习计划</font>这样的指令了。 - Retriever(检索器):文档集合中的文档一般都是一套大而全的资料,实际使用时不一定都和用户要查询的内容相关,此时,就需要使用Retriever从Document中筛选出和用户查询相关的文档。
- reranker(排序器):Retriever从文档集合筛选出和用户指令相关性比较高的文档后,对这些文档进行排序,选出更贴合用户指令的文档。这一步工作由Reranker来完成。
- llm(大模型):大语言模型,将用户指令和筛选出的相关文档组成dict,送给大模型进行推理。
- Answer(大模型推理结果):大模型推理完成后,按照用户要求返回的内容。
4.2 核心功能拆解
4.2.1 创建索引
这一步,是为pdf文档生成检索器,为后续的query检索做好准备。下面是核心的几个api调用。
<span style="color:#000000"><span style="background-color:#ffffff"><code class="language-python"><span style="color:#6c6b5a"># 创建文档对象</span>
self.document = Document(dataset_path=file_paths[<span style="color:#ae7313">0</span>] <span style="color:#5f9182">if</span> <span style="color:#ae7313">isinstance</span>(file_paths, <span style="color:#ae7313">list</span>) <span style="color:#5f9182">else</span> file_paths)
<span style="color:#ae7313">print</span>(<span style="color:#7d9726">"文档对象创建成功"</span>)
<span style="color:#6c6b5a"># 创建检索器</span>
self.retriever = Retriever(self.document,
group_name=<span style="color:#7d9726">"CoarseChunk"</span>,
similarity=<span style="color:#7d9726">"bm25_chinese"</span>,
topk=<span style="color:#ae7313">3</span>)
</code></span></span><font style="color:rgba(0, 0, 0, 0.85) !important;">Document()</font>:这是文档对象的构造函数,通过接收文件路径参数(可以是单个路径或路径列表,若为列表则取第一个路径)来加载文档,创建可供后续处理的文档实例。<font style="color:rgba(0, 0, 0, 0.85) !important;">Retriever()</font>:检索器的构造函数,基于前面创建的文档对象和指定的节点组("CoarseChunk")构建检索器。通过设置相似度算法("bm25_chinese")和返回结果数量(3),使检索器能够从文档中高效获取最相关的内容片段。
4.2.2 生成题库
基于用户的query,从检索器中获取相关的内容片段,然后基于用户指令和检索到的内容片段为完整的prompt,然后调用大语言模型生成练习题。
<span style="color:#000000"><span style="background-color:#ffffff"><code class="language-python"><span style="color:#6c6b5a"># 检索相关内容</span>
retrieved_nodes = self.retriever(topic)
<span style="color:#6c6b5a"># 构造生成题目的提示</span>
context = <span style="color:#7d9726">"\n"</span>.join([node.get_text() <span style="color:#5f9182">for</span> node <span style="color:#5f9182">in</span> retrieved_nodes]) <span style="color:#5f9182">if</span> <span style="color:#ae7313">isinstance</span>(retrieved_nodes, <span style="color:#ae7313">list</span>) <span style="color:#5f9182">else</span> retrieved_nodes
prompt = <span style="color:#7d9726">f"""
基于以下材料,为"{topic}"主题生成{num_questions}个练习题:
材料内容:
{context}
请生成不同类型的题目(选择题、判断题、简答题等),并提供答案。
以JSON格式返回,格式如下:
{{
"questions": [
{{
"type": "题型",
"question": "题目内容",
"options": ["选项A", "选项B", "选项C", "选项D"], # 选择题需要
"answer": "答案",
"explanation": "解析"
}}
]
}}
"""</span>
<span style="color:#6c6b5a"># 调用模型生成题目</span>
response = self.llm(prompt)
<span style="color:#5f9182">return</span> response
</code></span></span>4.2.3 生成学习计划
从技术链路上,是与生成题库一样的。也是基于用户的query,从检索器中获取相关的内容片段,然后基于用户指令和检索到的内容片段为完整的prompt,然后调用大语言模型生成学习计划。
<span style="color:#000000"><span style="background-color:#ffffff"><code class="language-python"><span style="color:#6c6b5a"># 检索相关内容</span>
retrieved_nodes = self.retriever(subject)
<span style="color:#6c6b5a"># 构造生成学习计划的提示</span>
context = <span style="color:#7d9726">"\n"</span>.join([node.get_text() <span style="color:#5f9182">for</span> node <span style="color:#5f9182">in</span> retrieved_nodes]) <span style="color:#5f9182">if</span> <span style="color:#ae7313">isinstance</span>(retrieved_nodes, <span style="color:#ae7313">list</span>) <span style="color:#5f9182">else</span> retrieved_nodes
prompt = <span style="color:#7d9726">f"""
基于以下材料,为"{subject}"制定一个从{start_date}到{end_date}的学习计划,总时长{total_hours}小时:
材料内容:
{context}
请考虑以下要点:
1. 将内容分解为多个学习模块
2. 合理分配时间
3. 提供每日/每周学习建议
4. 包含复习建议
以JSON格式返回,格式如下:
{{
"study_plan": {{
"subject": "学科",
"total_hours": 总时长,
"period": "学习周期",
"modules": [
{{
"module_name": "模块名称",
"content": "学习内容",
"hours": 学习时长,
"schedule": "时间安排建议"
}}
],
"review_plan": "复习计划"
}}
}}
"""</span>
<span style="color:#6c6b5a"># 调用模型生成学习计划</span>
response = self.llm(prompt)
<span style="color:#5f9182">return</span> response
</code></span></span>5. 案例实战演示
5.1 完整源码
<span style="color:#000000"><span style="background-color:#ffffff"><code class="language-python"><span style="color:#5f9182">import</span> os
<span style="color:#5f9182">import</span> lazyllm
<span style="color:#5f9182">from</span> lazyllm.tools <span style="color:#5f9182">import</span> Document, SentenceSplitter, Retriever
<span style="color:#5f9182">from</span> lazyllm.tools.agent <span style="color:#5f9182">import</span> FunctionCallAgent
<span style="color:#5f9182">from</span> lazyllm.tools.rag.doc_node <span style="color:#5f9182">import</span> DocNode
<span style="color:#5f9182">import</span> json
<span style="color:#5f9182">class</span> <span style="color:#36a166">StudyAssistantAgent</span>:
<span style="color:#5f9182">def</span> <span style="color:#36a166">__init__</span>(<span style="color:#ae7313">self</span>):
<span style="color:#6c6b5a"># 初始化模型</span>
self.llm = lazyllm.OnlineChatModule(stream=<span style="color:#ae7313">True</span>)
<span style="color:#ae7313">print</span>(<span style="color:#7d9726">"模型初始化成功"</span>)
<span style="color:#6c6b5a"># 创建文档处理组件</span>
self.document = <span style="color:#ae7313">None</span>
self.retriever = <span style="color:#ae7313">None</span>
<span style="color:#6c6b5a"># 工具列表</span>
self.tools = []
self._register_tools()
<span style="color:#ae7313">print</span>(<span style="color:#7d9726">"工具注册完成"</span>)
<span style="color:#6c6b5a"># 创建Agent</span>
self.agent = FunctionCallAgent(self.llm, self.tools)
<span style="color:#ae7313">print</span>(<span style="color:#7d9726">"Agent创建成功"</span>)
<span style="color:#5f9182">def</span> <span style="color:#36a166">_register_tools</span>(<span style="color:#ae7313">self</span>):
<span style="color:#7d9726">"""
注册学习助手所需工具
"""</span>
<span style="color:#ae7313"> @lazyllm.fc_register(<span style="color:#ae7313"><span style="color:#3388aa">"tool"</span></span>)</span>
<span style="color:#5f9182">def</span> <span style="color:#36a166">import_material</span>(<span style="color:#ae7313">file_paths: <span style="color:#ae7313">list</span></span>) -> <span style="color:#ae7313">str</span>:
<span style="color:#7d9726">"""
导入课件/教材材料
Args:
file_paths (list): 文件路径列表
"""</span>
<span style="color:#ae7313">print</span>(<span style="color:#7d9726">f"导入文件路径: {file_paths}"</span>)
<span style="color:#5f9182">try</span>:
<span style="color:#6c6b5a"># 创建文档对象</span>
self.document = Document(dataset_path=file_paths[<span style="color:#ae7313">0</span>] <span style="color:#5f9182">if</span> <span style="color:#ae7313">isinstance</span>(file_paths, <span style="color:#ae7313">list</span>) <span style="color:#5f9182">else</span> file_paths)
<span style="color:#ae7313">print</span>(<span style="color:#7d9726">"文档对象创建成功"</span>)
<span style="color:#6c6b5a"># 创建检索器</span>
self.retriever = Retriever(self.document,
group_name=<span style="color:#7d9726">"CoarseChunk"</span>,
similarity=<span style="color:#7d9726">"bm25_chinese"</span>,
topk=<span style="color:#ae7313">3</span>)
<span style="color:#ae7313">print</span>(<span style="color:#7d9726">"检索器创建成功"</span>)
<span style="color:#5f9182">return</span> <span style="color:#7d9726">f"成功导入材料,共处理 {<span style="color:#ae7313">len</span>(file_paths)} 个文件"</span>
<span style="color:#5f9182">except</span> Exception <span style="color:#5f9182">as</span> e:
<span style="color:#5f9182">return</span> <span style="color:#7d9726">f"导入材料失败: {<span style="color:#ae7313">str</span>(e)}"</span>
<span style="color:#ae7313"> @lazyllm.fc_register(<span style="color:#ae7313"><span style="color:#3388aa">"tool"</span></span>)</span>
<span style="color:#5f9182">def</span> <span style="color:#36a166">generate_question_bank</span>(<span style="color:#ae7313">topic: <span style="color:#ae7313">str</span>, num_questions: <span style="color:#ae7313">int</span> = <span style="color:#ae7313">5</span></span>) -> <span style="color:#ae7313">str</span>:
<span style="color:#7d9726">"""
根据指定主题生成题库
Args:
topic (str): 题目主题
num_questions (int): 题目数量
"""</span>
<span style="color:#ae7313">print</span>(<span style="color:#7d9726">f"生成题库主题: {topic}, 数量: {num_questions}"</span>)
<span style="color:#5f9182">if</span> <span style="color:#5f9182">not</span> self.retriever:
<span style="color:#5f9182">return</span> <span style="color:#7d9726">"请先导入材料"</span>
<span style="color:#5f9182">try</span>:
<span style="color:#6c6b5a"># 检索相关内容</span>
retrieved_nodes = self.retriever(topic)
<span style="color:#6c6b5a"># 构造生成题目的提示</span>
context = <span style="color:#7d9726">"\n"</span>.join([node.get_text() <span style="color:#5f9182">for</span> node <span style="color:#5f9182">in</span> retrieved_nodes]) <span style="color:#5f9182">if</span> <span style="color:#ae7313">isinstance</span>(retrieved_nodes, <span style="color:#ae7313">list</span>) <span style="color:#5f9182">else</span> retrieved_nodes
prompt = <span style="color:#7d9726">f"""
基于以下材料,为"{topic}"主题生成{num_questions}个练习题:
材料内容:
{context}
请生成不同类型的题目(选择题、判断题、简答题等),并提供答案。
以JSON格式返回,格式如下:
{{
"questions": [
{{
"type": "题型",
"question": "题目内容",
"options": ["选项A", "选项B", "选项C", "选项D"], # 选择题需要
"answer": "答案",
"explanation": "解析"
}}
]
}}
"""</span>
<span style="color:#6c6b5a"># 调用模型生成题目</span>
response = self.llm(prompt)
<span style="color:#5f9182">return</span> response
<span style="color:#5f9182">except</span> Exception <span style="color:#5f9182">as</span> e:
<span style="color:#5f9182">return</span> <span style="color:#7d9726">f"生成题库失败: {<span style="color:#ae7313">str</span>(e)}"</span>
<span style="color:#ae7313"> @lazyllm.fc_register(<span style="color:#ae7313"><span style="color:#3388aa">"tool"</span></span>)</span>
<span style="color:#5f9182">def</span> <span style="color:#36a166">generate_study_plan</span>(<span style="color:#ae7313">subject: <span style="color:#ae7313">str</span>, total_hours: <span style="color:#ae7313">int</span>, start_date: <span style="color:#ae7313">str</span>, end_date: <span style="color:#ae7313">str</span></span>) -> <span style="color:#ae7313">str</span>:
<span style="color:#7d9726">"""
生成个性化学习计划
Args:
subject (str): 学科主题
total_hours (int): 总学习时长(小时)
start_date (str): 开始日期(YYYY-MM-DD)
end_date (str): 结束日期(YYYY-MM-DD)
"""</span>
<span style="color:#ae7313">print</span>(<span style="color:#7d9726">f"生成学习计划主题: {subject}, 总时长: {total_hours}小时, 从 {start_date} 到 {end_date}"</span>)
<span style="color:#5f9182">if</span> <span style="color:#5f9182">not</span> self.retriever:
<span style="color:#5f9182">return</span> <span style="color:#7d9726">"请先导入材料"</span>
<span style="color:#5f9182">try</span>:
<span style="color:#6c6b5a"># 检索相关内容</span>
retrieved_nodes = self.retriever(subject)
<span style="color:#6c6b5a"># 构造生成学习计划的提示</span>
context = <span style="color:#7d9726">"\n"</span>.join([node.get_text() <span style="color:#5f9182">for</span> node <span style="color:#5f9182">in</span> retrieved_nodes]) <span style="color:#5f9182">if</span> <span style="color:#ae7313">isinstance</span>(retrieved_nodes, <span style="color:#ae7313">list</span>) <span style="color:#5f9182">else</span> retrieved_nodes
prompt = <span style="color:#7d9726">f"""
基于以下材料,为"{subject}"制定一个从{start_date}到{end_date}的学习计划,总时长{total_hours}小时:
材料内容:
{context}
请考虑以下要点:
1. 将内容分解为多个学习模块
2. 合理分配时间
3. 提供每日/每周学习建议
4. 包含复习建议
以JSON格式返回,格式如下:
{{
"study_plan": {{
"subject": "学科",
"total_hours": 总时长,
"period": "学习周期",
"modules": [
{{
"module_name": "模块名称",
"content": "学习内容",
"hours": 学习时长,
"schedule": "时间安排建议"
}}
],
"review_plan": "复习计划"
}}
}}
"""</span>
<span style="color:#6c6b5a"># 调用模型生成学习计划</span>
response = self.llm(prompt)
<span style="color:#5f9182">return</span> response
<span style="color:#5f9182">except</span> Exception <span style="color:#5f9182">as</span> e:
<span style="color:#5f9182">return</span> <span style="color:#7d9726">f"生成学习计划失败: {<span style="color:#ae7313">str</span>(e)}"</span>
<span style="color:#6c6b5a"># 添加工具到工具列表</span>
self.tools = [<span style="color:#7d9726">"import_material"</span>, <span style="color:#7d9726">"generate_question_bank"</span>, <span style="color:#7d9726">"generate_study_plan"</span>]
<span style="color:#5f9182">def</span> <span style="color:#36a166">chat</span>(<span style="color:#ae7313">self, query: <span style="color:#ae7313">str</span></span>) -> <span style="color:#ae7313">str</span>:
<span style="color:#7d9726">"""
与学习助手对话
Args:
query (str): 用户查询
"""</span>
<span style="color:#5f9182">try</span>:
<span style="color:#5f9182">return</span> self.agent(query)
<span style="color:#5f9182">except</span> Exception <span style="color:#5f9182">as</span> e:
<span style="color:#5f9182">return</span> <span style="color:#7d9726">f"处理查询时出错: {<span style="color:#ae7313">str</span>(e)}"</span>
<span style="color:#5f9182">def</span> <span style="color:#36a166">main</span>():
<span style="color:#5f9182">try</span>:
<span style="color:#6c6b5a"># 创建学习助手实例</span>
assistant = StudyAssistantAgent()
<span style="color:#6c6b5a"># 启动Web界面</span>
lazyllm.WebModule(assistant.chat, port=<span style="color:#ae7313">23456</span>, title=<span style="color:#7d9726">"Alex的个性化学习助手"</span>).start().wait()
<span style="color:#5f9182">except</span> Exception <span style="color:#5f9182">as</span> e:
<span style="color:#ae7313">print</span>(<span style="color:#7d9726">f"启动学习助手失败: {e}"</span>)
<span style="color:#ae7313">print</span>(<span style="color:#7d9726">"请确保已正确配置模型或API密钥"</span>)
<span style="color:#5f9182">if</span> __name__ == <span style="color:#7d9726">"__main__"</span>:
main()
</code></span></span>从上述源码可以看到,我为个性化学习助手Agent设计了3个工具,分别是
- import_material:用于上传课件/教材材料。
- generate_question_bank:根据指定主题生成题库。
- generate_study_plan:生成个性化学习计划。
然后,通过FunctionCallAgent注册给了大模型。后续根据我给的指令,由大模型来按需调用对应工具实现对应的功能。
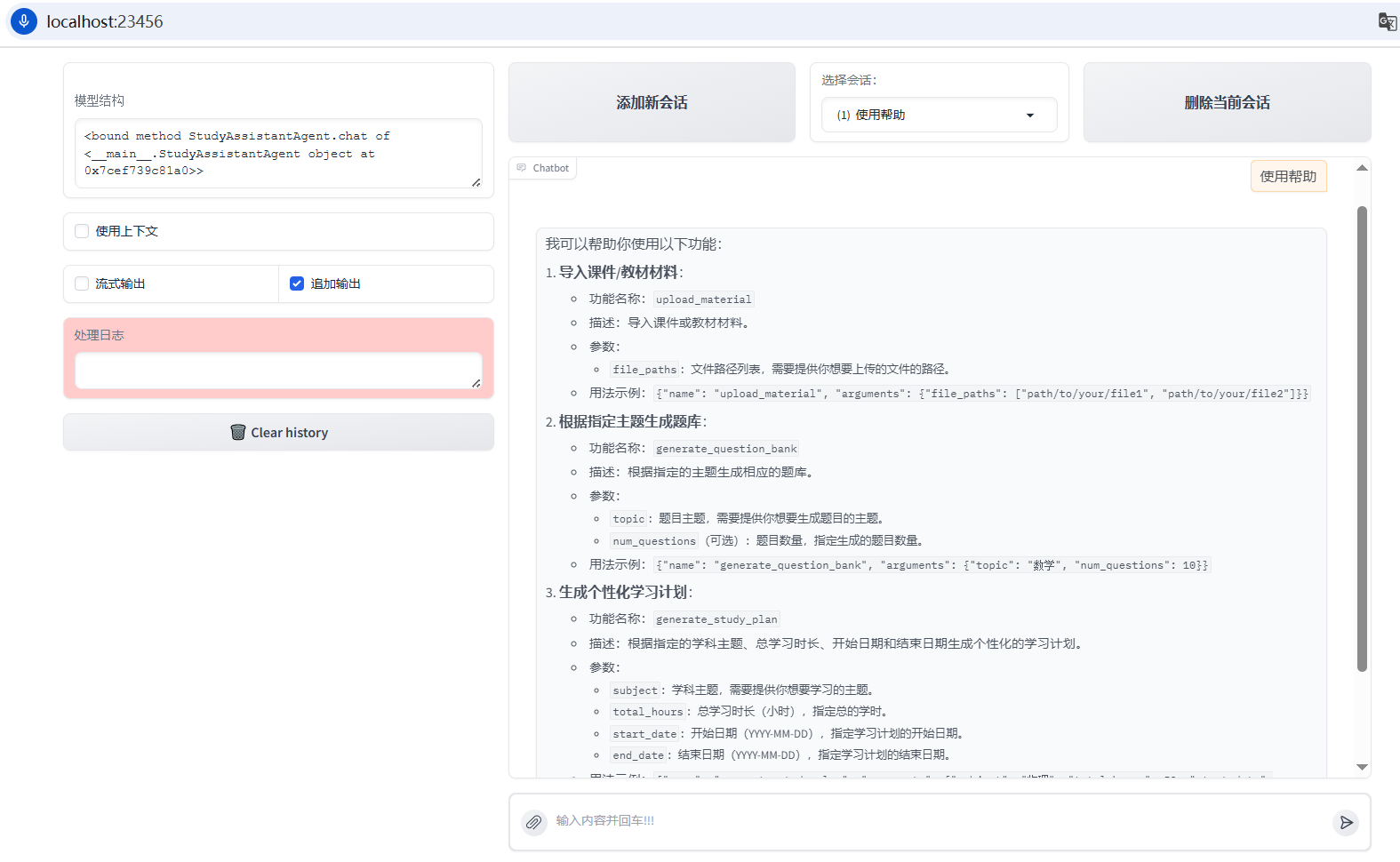
使用python3 study.py命令启动Agent,LazyLLM会使用Gradio为我们创建一个常见的聊天机器人页面,并自动部署到本机的23456端口。

我们使用浏览器访问http://localhost:23456/就可以看到Agent页面了。如下图所示,可以看到,我们设计的3个工具都已经成功注册给大模型。
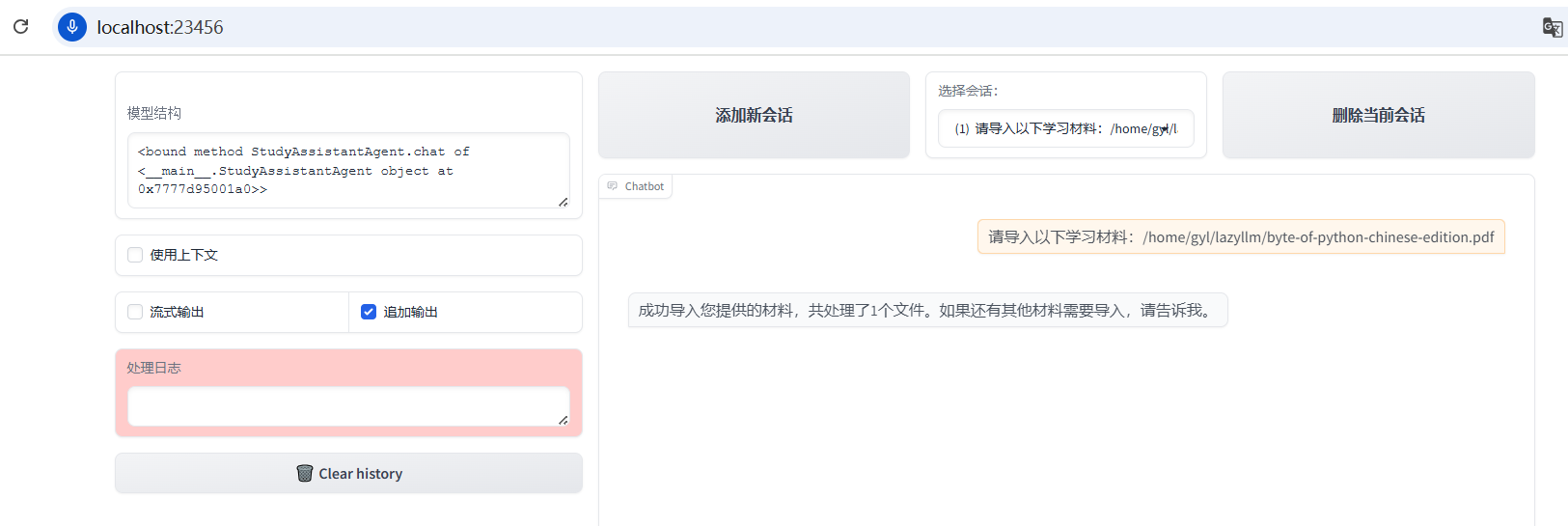
5.2 导入教材/课件
由于我的书稿还没出版,所以这里我就先拿网络上一个免费共享的python教程电子书:《简明python教程》进行演示。第一步,先导入文档,创建索引。使用的prompt:请导入以下学习材料:/home/gyl/lazyllm/byte-of-python-chinese-edition.pdf,效果如下图所示。
5.3 生成题库
导入材料之后,就可以下指令让Agent给我们生成题库了。使用的prompt:为"面向对象编程"章节生成6道不同类型的题目,包括选择题和简答题。效果如下图所示。
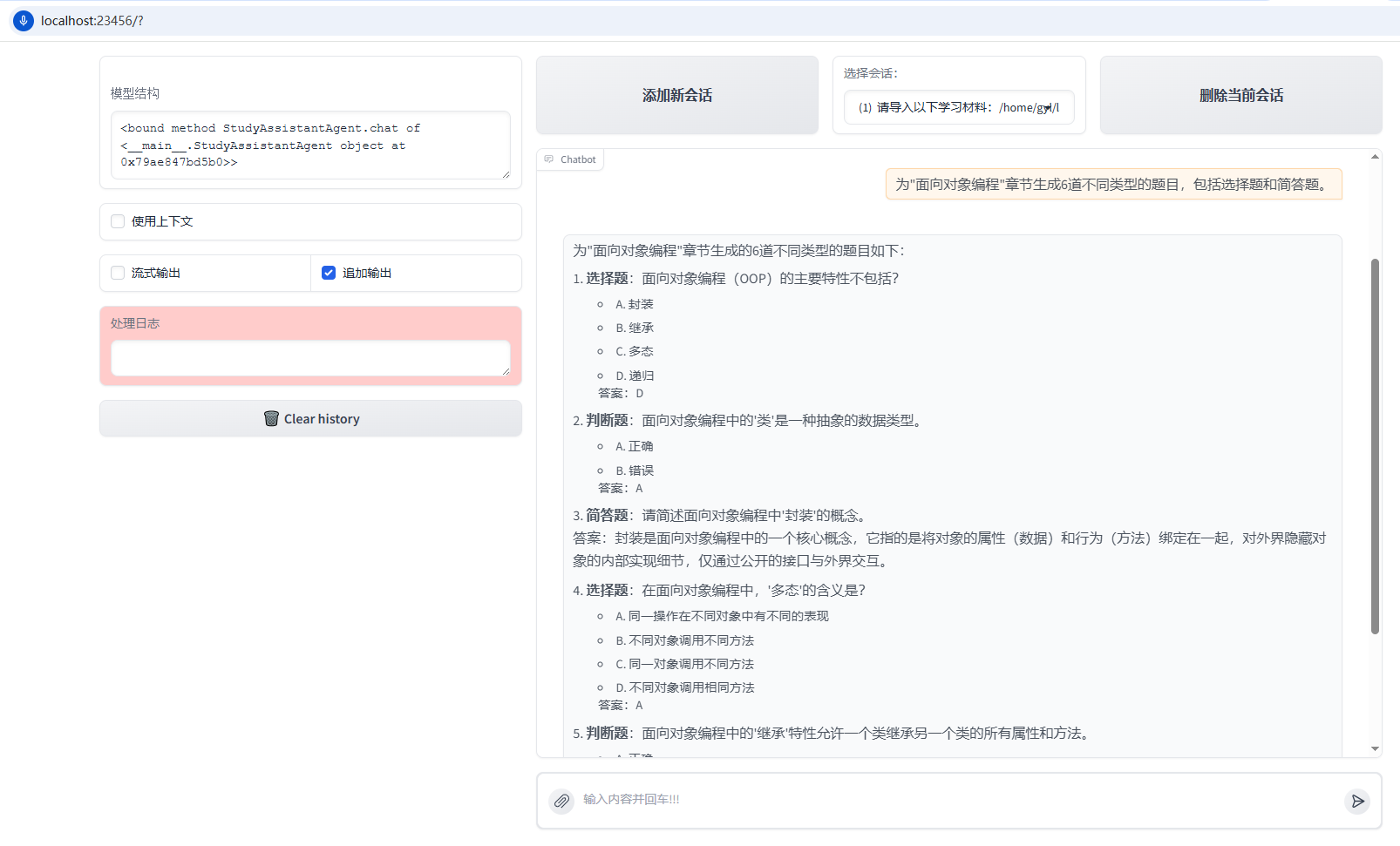
5.4 生成学习计划
同时,还可以让Agent为我们生成一个学习计划。使用的prompt:请制定一个学习计划,主题是python数据结构,总时长5小时,从2025-10-01到2025-10-05。效果如下图所示。
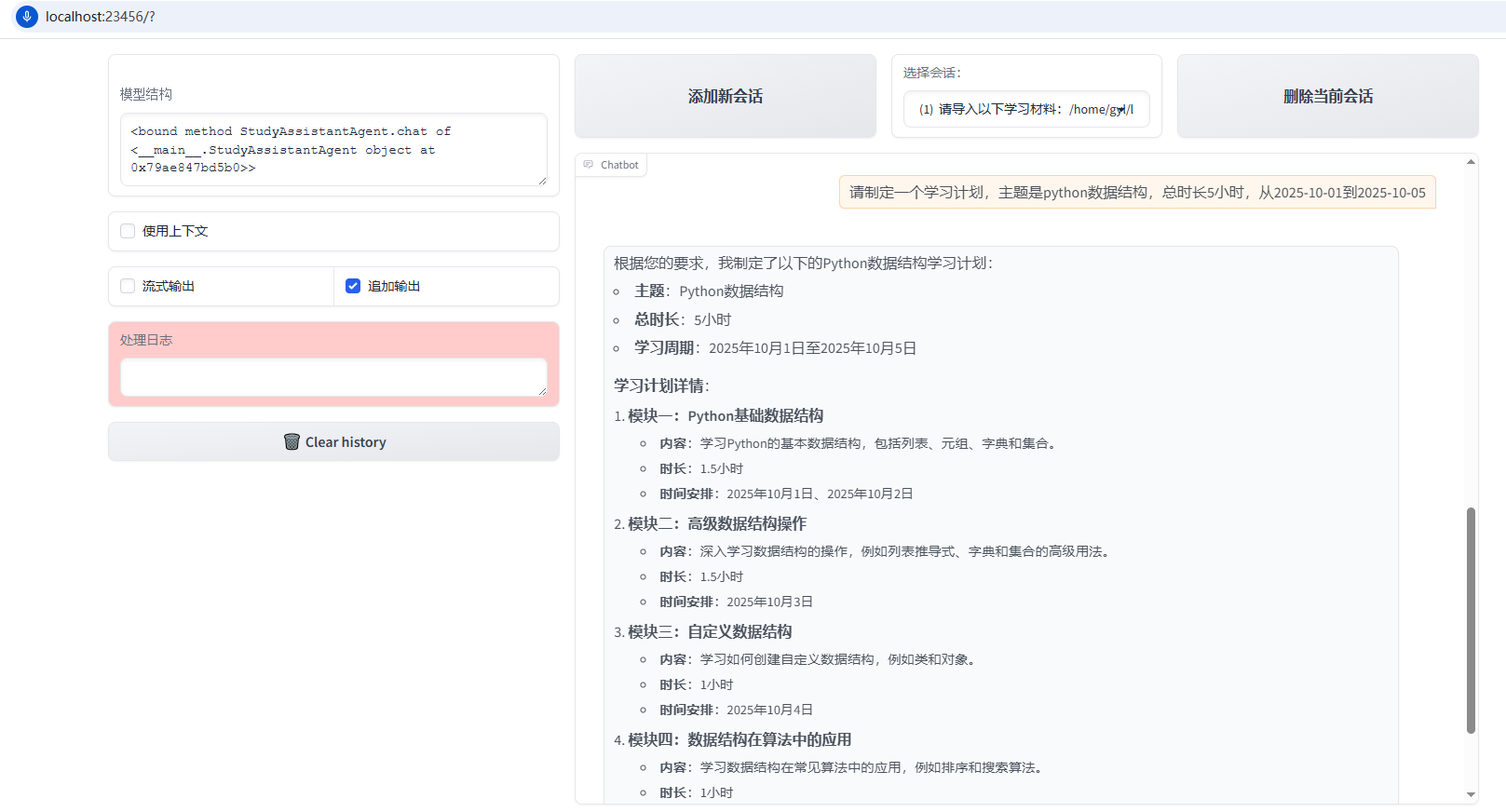
6. 总结
通过一段时间的实践,我发现这个学习助手Agent在内容创作领域有非常高的应用价值,无论是为教材章节设计多样化习题、制定科学的学习计划,都能基于原始文档精准生成符合需求的内容,有效解决了我在写书中配套资源开发效率低的问题。
这个高效AI Agent的实现,离不开 LazyLLM 框架的强大支撑:其低代码特性大幅降低了开发门槛,模块化设计让复杂的多智能体系统搭建变得简单,从环境配置到功能部署仅需少量代码和简单操作即可完成,无论是快速搭建聊天机器人,还是构建基于 RAG 技术的检索增强应用,都能轻松实现,充分体现了框架在易用性上的显著优势。正是这样的框架赋能,让个性化 AI 工具的开发和落地变得触手可及,为各类场景下的效率提升提供了有力支持。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)