大模型数据构建实战指南:Qwen3/Deepseek/Kimi等技术全解析,建议收藏!
本文详细解析了Qwen3、Deepseek、Kimi K2等主流大模型的数据构建技术。各模型在预训练阶段注重数据多样性与质量,通过多语言标注、数据合成与清洗构建大规模语料;后训练阶段则聚焦提升模型推理能力,采用query/response过滤、强化学习等技术。通用做法包括排除极端难度数据、训练专用模型生成清洗数据,以及精心设计数据合成prompt。不同模型根据自身特点采用差异化策略,共同推动了大模
简介
本文详细解析了Qwen3、Deepseek、Kimi K2等主流大模型的数据构建技术。各模型在预训练阶段注重数据多样性与质量,通过多语言标注、数据合成与清洗构建大规模语料;后训练阶段则聚焦提升模型推理能力,采用query/response过滤、强化学习等技术。通用做法包括排除极端难度数据、训练专用模型生成清洗数据,以及精心设计数据合成prompt。不同模型根据自身特点采用差异化策略,共同推动了大模型能力的提升。
一、Qwen3
1. Pre-training
- 微调 Qwen2.5-VL 从 PDF 中提取文本。提取的文本使用 Qwen2.5 进行提炼提高数据质量。
- 使用 Qwen2.5,Qwen2.5-Math,Qwen2.5-Coder 合成文本 / 问答对 /指令 / 代码片段等垂域数据。
使用特定垂域模型合成数据:Qwen2.5-Math 和 Qwen2.5-Coder 合成数学和代码数据。
- 合成多种语言数据扩充语料库。
- 开发了多语言标注系统增加数据质量和多样性。细粒度;优化数据混合比例。
这个系统在预训练数据的标注中起了很大作用。
最终构建了 36T tokens 数据,涵盖 119 种语言和方言。
训练分3步:1. 30T tokens 数据打基础;2. 5T tokens知识密集型数据训练 STEM;3. 4k -> 32K 文本长度。
2. Post-training
2.1 Long CoT Cold Start
构建了包含逻辑推理,STEM(Science, Technology, Engineering, and Mathematics)等多类问题数据,每条数据都有对应的参考答案或基于代码的测试用例。
- query 过滤
这有助于防止模型依赖肤浅的猜测,并确保只包括需要更深入推理的复杂问题。
-
用 Qwen2.5-72B-Instruct 标注每个 query 的 domain,保证数据集中 domain 分布平衡。
-
用 Qwen2.5-72B-Instruct 识别并过滤不易验证的问题。包含很多子问题;通用文本生成的 query。
-
过滤 Qwen2.5-72B-Instruct 不用 CoT 就能回答正确的 query。
- response 过滤
- 最终答案错误
- 存在大量重复内容
- 明显表现出猜测行为而缺乏充分推理(蒙对的)
- 思考过程与总结内容之间存在不一致
- 存在不当的语言混用或风格突变
- 和验证集过于相似
- 预留一个验证集,然后用 QwQ-32B 为剩余 query 生成 N 个 response。
- 当 QwQ-32B 模型无法生成正确解决方案时,将由人工标注员手动评估 response 的准确性。
- 对于 Pass@N 为正的查询,进行以下过滤:
然后从过滤后的数据集中选取一个子集,用于 Long CoT 冷启动。
此阶段的目标是向模型植入基础推理模式,而非过度强调即时的推理性能。这种方法可确保模型的潜力不受限制,使其在后续的 RL 阶段备更强的灵活性与提升空间。为有效实现这一目标,在该准备阶段,我们倾向于同时减少训练样本数量与训练步数。
2.2 RL
- 在冷启动阶段没用过
- 对冷启动模型是可学习的(有用的数据)
- 有一定挑战性(有点难但可以学会)
- 覆盖广泛的 sub-domain
共构建了 3995 条 query-verifier 对作为 RL 阶段的训练数据。
作者观察到大的 Batch size,对每个 query 多次的 rollout,异策略提高采样效率等RL训练稳定的手段。在一次完整的强化学习训练过程中,无需任何超参数人工干预的情况下,实现了训练奖励和验证性能的持续提升。 例如,Qwen3-235B-A22B 在 AIME’24 上的得分在总共 170 步 RL 训练中从 70.1 提高到了 85.1。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、Qwen3-Coder
1. Pre-training
- 数据扩展:总计 7.5T(代码占比 70%),在保持通用与数学能力的同时,具备卓越的编程能力。
- 上下文扩展:256K 借助 YaRN 可扩展至 1M,强化 agent 能力。
- 合成数据扩展:利用 Qwen2.5-Coder 对低质数据进行清洗与重写,显著提升整体数据质量。
2. Post-training
与当前社区普遍聚焦于竞赛类代码生成不同,作者认为所有的代码任务天然适合基于执行进行驱动的大规模强化学习。
在更丰富的真实代码任务上扩展 Code RL 训练;通过自动扩展测试样例,构造了大量高质量的训练数据。
成功释放了强化学习的潜力:不仅显著提升了代码执行成功率,还对其他任务带来增益。这将鼓励我们继续寻找 Hard to Solve, Easy to Verify 的任务,作为强化学习的土壤。
三、Qwen3-Embedding
先进行大范围弱监督/无监督数据上的预训练;然后在高质量数据集上进行 SFT。 合成数据用于 Pre-training,高质量的子集用于 SFT。
1. Large-Scale Synthetic Data-Driven Weak Supervision Training
直接用大模型合成成对的数据,而不是开源社区收集(GTE;T5;BGE 等);设计不同的 prompt 提高生成数据的多样性和可靠性;共 150M 合成数据。
可以控制语言 / 生成长度 / 困难程度等,更好的管理生成数据的质量和多样性,特别是针对较少公开数据的场景和语言。
可能在包含口语化查询时效果不太好。
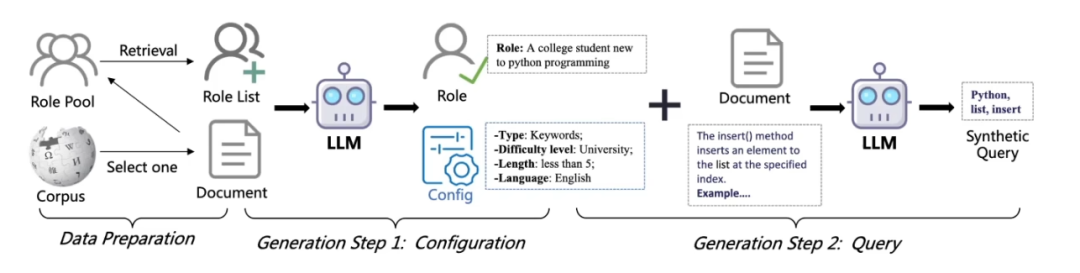
合成过程 - 以文本检索任务为例:
- 利用 Qwen3 的多语言预训练语料库进行数据合成。
- 为每个文档分配特定的角色,以模拟潜在用户查询该文档。
利用一个检索模型从一个角色库中找出每篇文档的前 5 个角色候选人,并将这些文档及其角色候选人一起呈现给 prompt。让模型生成最适合 query 生成的角色配置。
- 将角色配置给到 prompt,生成 query。
2. High-Quality Synthetic Data Utilization in Supervised Fine Tuning
用第一步合成数据的高质量子集(12M)和开源数据集(7M)进行监督微调。
余弦相似度计算来选择数据对,从随机采样的数据中保留余弦相似度大于0.7的数据对。
四、Deepseek V3
1. Pre-training
- 14.8T 多样化高质量的 tokens。
- 相比与 Deepseek V2,增加了数学和代码数据的占比。
- 扩充多语言数据。
- 数据处理 pipline 在保证数据多样性的基础上尽可能多的减少数据冗余。
用了 document packing 方法,但是没有加入跨样本的 mask。 PSM (Prefix-Suffix-Middle) 结构的 FIM (Fill-in-Middle)。
2. Post-training
2.1 SFT
数据集包括跨越多个 domain 的 1.5M 条数据,每个 domain 采用不同的数据创建方法,以适应其特定的需求。
也用了 document packing 方法,但是有 mask。
2.1.1 Reasoning Data
用 Deepseek R1 生成数据存在的问题:准确率高,但存在过度思考,格式较差和长度过长的问题。 用 SFT + RL 结合的 pipeline 训练针对特定 domain 的专家模型来生成数据。
每个 domain 都会单独训练一个专家模型。例如 数学 / 代码 / 通用推理等。
- 为每条数据生成两种 SFT 样本
<problem, original response> <system prompt, problem, R1 response> system prompt 经过精心设计,包含引导模型生成 “富含反思与验证机制” 的 response 的指令
- RL 阶段采用 high-temperature 采样生成 response。
即便在没有明确 system prompt 的情况下,这些 response 也能融合 R1 生成数据与原始数据中的模式。 经过数百步 RL 训练后,中间 RL 模型将学会融入 R1 的思考模式,从而有策略地提升整体性能。
用训练好的专家模型作为数据生成源,通过拒绝采样来为最终模型提供高质量的 SFT 数据。
2.1.2 Non-Reasoning Data
对于非推理数据,如创意写作、角色扮演、简单问答等,使用 DeepSeek V2.5 生成 response。然后人工验证数据的准确性。
2.2 RL
额外增加了一些偏好数据 数据包含最终奖励和与奖励有关的 CoT
五、 Deepseek R1
用数千条冷启动数据微调 Deepseek V3 Base,然后执行与 DeepSeek-R1-Zero 类似的面向推理的强化学习。在 RL 接近收敛时,用 RL checkpoint 通过拒绝采样构造新的 SFT 数据,并结合 DeepSeek V3 在不同 domain 的监督数据,然后重新训练 DeepSeek V3 Base,然后再接一个 RL。
1. Cold Start
收集了数千条冷启动的 Long CoT 数据。
Few shot (Long CoT)prompt,让 Deepseek R1 Zero 生成带反思和验证的答案;然后人工后处理进行精炼和清洗。 可读性;推理潜力(作者认为对于推理模型,迭代训练是一种更好的方式)。
2. Rejection Sampling and Supervised Fine-Tuning
当推理导向的 RL 收敛时,用 checkpoint 收集 SFT 数据用于下一轮微调。与最初的冷启动数据主要侧重于推理不同,该阶段结合了其他领域的数据,以增强模型在写作、角色扮演和其他通用方面的能力。
2.1 Reasoning data
- 前面的 RL checkpoint 拒绝采样来构建 response prompt 和 reasoning trajectories。
之前的步骤只包含的可以用基于规则的奖励验证的数据,这个步骤扩展了可以通过生成式奖励模型验证的数据。
- 筛除语言混杂的 CoT、过长段落的 CoT 以及包含代码块的 CoT。
对每个 prompt 生成多个 response,只保留正确的那一个。 最后收集了 600K reasoning 相关的训练样本。
2.2 Non-Reasoning data
- 使用 Deepseek V3 pipeline,重用一部分 Deepseek V3 的 SFT 数据。
- 对于确定的 non-reasoning 任务,通过设计 prompt,让 Deepseek V3 在回答问题之前生成一些潜在的 CoT。
过于简单的 query 不提供 CoT,例如 Hello
最后收集了 200K non-reasoning 的数据。 然后用这 800K 微调 Deepseek V3 Base ;epoch=2。
六、 Kimi K2
1. Pre-training
Kimi K2 相对于 Kimi K1.5 在预训练数据上的一个关键进步是引入了合成数据生成策略来提高 token 利用率。具体来说,一个精心设计的 重写 pipeline 被用来放大高质量 token 的容量(尽可能榨干),而不会引起显著的过拟合。(相当于一种数据增强方法)主要针对 Knowledge 和 Math 领域。
高质量的人类数据越来越难获取。作者认为 token 利用率(token-efficient,每个 token 可以获得多大的性能提升)在后续的大模型扩展中会越来越重要。
1.1 Knowledge Data Rephrasing
对于大量的 Knowledge 数据,1 个 epoch 学不全,多个 epoch 又容易过拟合。所以构建了一个数据合成重写框架(synthetic rephrasing framework)。
- prompt:设计了不同的语言,风格,视角的多样化 prompt,来对原始 Knowledge 进行改写。
- 分块自回归生成:为了保持全局连贯性,避免长文本中的信息丢失,作者采用了基于块的自回归重写策略。文本被分割成多个块,每个块单独重写,然后拼接在一起,形成完整的段落。作者说该方法减轻了 LLMs 通常存在的隐式输出长度限制。(但是我觉得还是有一定限制的)
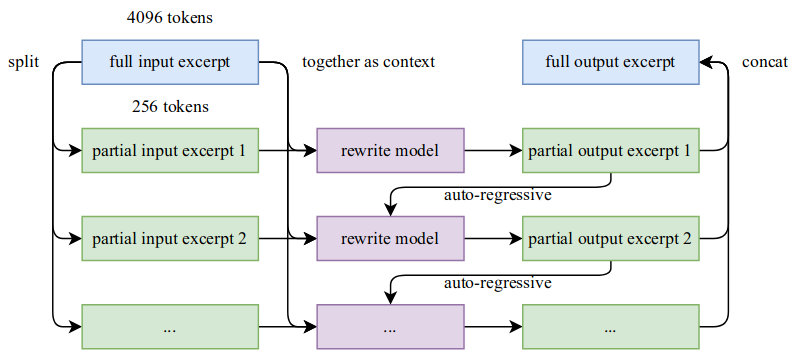
- 质量保障:对比每个重写内容和原始内容,保证都符合要求。
- 结果对比:在 SimpleQA 上对 3 种重写策略进行了对比。

1.2 Mathematics Data Rephrasing
将高质量的数据改写成数学笔记的形式。参考的 SwallowMath 的方法。为了扩充数据多样性,将多种其他语言的数学材料转成英文。
作者认为使用合成数据作为持续扩展的策略仍然是一个活跃的研究领域。其中的核心挑战包括:在不影响事实准确性的前提下,将该方法推广到不同的源领域;最大限度地减少幻觉现象与非预期的有害内容;以及确保该方法能够扩展应用于大规模数据集。
2. Post-training
2.1 SFT
2.1.1 Large-Scale Agentic Data Synthesis for Tool Use Learning
开发了一套针对不同任务领域的数据生成 pipeline。
用 K1.5 和其他内部的领域专家模型来为各种任务生成候选 response,然后由 LLMs 或 人工进行质量评估和过滤。
以最大化提示多样性和保证高响应质量这两个核心原则为指导,构建了一个跨不同领域的大规模指令微调数据集。
2.1.2 Agent 数据合成
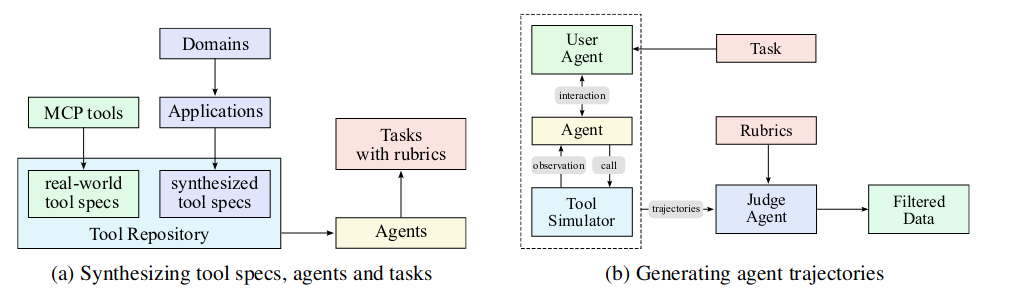
受 ACEBench 的综合数据合成框架的启发,我们开发了一个 pipeline,可以大规模地模拟真实世界的工具使用场景,从而能够生成数以万计的多样化和高质量的训练实例。
- 工具生成:真实世界工具(3K+)和 LLM 合成工具(2w+)构建了一个大型的工具规格说明库。
- Agents 和任务生成:从工具库中采样的工具集,设计 system prompt 生成一个多领域多行为的 Agent 来使用工具集,并基于规则生成相应的带有“label”的任务。
- Trajectories 生成:对于每个 agent 和任务,通过调用工具得到 agent 完成任务的 trajectory。
用户模拟:LLM 生成的具有不同沟通风格和偏好的用户角色与智能体进行多轮对话,形成自然主义的交互模式。 工具执行环境:一个复杂的工具模拟器 (功能上等价于一个世界模型) 执行工具调用并提供逼真的反馈。模拟器在每次工具执行后都会维护和更新状态,实现复杂的多步骤交互,且效果具有持久性。它引入受控的随机性,以产生不同的结果,包括成功、部分失败和边缘案例。结合了真实执行环境。 没有说最终生成了多少 trajectory
2.2 RL
2.2.1 Verifiable Rewards Gym
a. STEM 和 逻辑推理
遵循两个原则。多样性和难度适中。
**多样性:**STEM:专家标注,内部 QA 提取pipeline,开源数据集获取高质量 QA 对。逻辑推理:包含结构化数据任务和逻辑谜题等。
**难度适中:**用 SFT 模型的 pass@k 准确率来评估每个问题的难度,只选择难度适中的问题。
b. 复杂指令遵循
有效的指令遵循不仅需要理解明确的约束条件,还需要应对隐含要求、处理边缘情况,并在长时间对话中保持一致性。
混合规则验证
-
通过代码解释器对具有可验证输出的指令进行确定性评估。
-
对需要细致入微地理解约束的指令用 LLM 进行评估。
加入额外的 hack - check 层解决模型的潜在对抗行为。
多源指令生成
- 由数据团队编写的专家级复杂条件提示与评分标准。
- 受 AutoIF 启发的 agent 类型指令扩充。
- 微调专用模型,用于生成可以探测特定的失效模式或边缘情况的额外指令。
c. 真实性
训练了一个句子级别的真实度判断奖励模型,对没有上下文证据支持的情况下做出事实声明进行惩罚。
d. 编码与软件工程
- 竞赛级编程能力:从开源数据集和合成数据中收集问题及其评测标准。合成数据的评测标准纳入了从预训练数据中提取的高质量人工编写单元测试。
- 软件工程任务:从 GitHub 收集了大量拉取请求和问题,构建了包含用户提示/问题及可执行单元测试的软件开发环境。 该环境基于稳健的沙箱基础设施构建,借助 Kubernetes 实现可扩展性和安全性。
e. 安全性
- 攻击模型:迭代生成旨在诱使目标大语言模型(LLM)产生不安全响应的对抗性提示。
- 目标模型:对这些提示作出响应,模拟潜在的漏洞。
- 评判模型:评估交互过程,以判断对抗性提示是否成功绕过安全机制。
每次交互都会根据特定任务的评分标准进行评估,使评判模型能够给出成功/失败的二元标签。
2.2.2 Beyond Verification: Self-Critique Rubric Reward
K2 actor 生成 response,由 K2 critic 对成对的 response 进行打分。
核心评估标准:清晰性和相关性;对话流畅度与参与感;客观务实的互动方式
指定的评估标准(减少 reward hacking):禁止初始赞美;明确的合理性说明
针对特定场景人工标定的评估标准
七、GPT-OSS
1. Pre-training
- 主要包含 STEM,code 和 通用知识
- 特别强调安全,用 GPT-4o 的 CBRN 过滤器过滤掉了不安全数据,特别是生物安全。
八、MiMo-7B
1. Pre-training
为了提高小模型推理能力,Pre-training 做了很多工作。(强调数据质量/多样性,提高小模型的数学和代码能力)
包含:网页,论文,书籍,项目代码,合成数据。
- 开发优化的 HTML 提取工具 和 PDF 解析工具。
- URL 去重 和 MinHash 去重。
- 通过微调一个小模型来进行高质量数据过滤。
普遍的基于规则的过滤会筛除一些数学和代码数据。
- 合成数据
- 选择高推理深度的 STEM 数据,提示模型对其进行深入分析和思考。
- 整合数学和代码问题,提示模型解决他们。
- 结合了通用领域的 query,比如创意写作任务。
合成的推理数据可以训练很多 epoch 而不过拟合
Three-Stage Data Mixture
- 整合除了从推理任务合成的推理数据外的所有数据。过度表述(夸大其词)的内容及知识密度与推理深度不足的数据进行下采样,同时针对专业领域的高质量数据进行上采样。
- 将数学和代码数据比例提升至 ~70%。
- 引入 ~10%的数学、代码和创意写作的合成推理数据。
2. Post-training
2.1 SFT
- 去除了训练 query 中和测试集有 16-gram 重合的数据,防止数据泄漏。
- 排除了混合语言或不完整回答的样本。
- 每个 query 的 response 限制在 8 个。 最终 500K SFT 数据。
2.2 RL
130K 可以用规则进行验证的数学和代码问题作为 RL 训练数据。
高质量问题数据对 RL 训练的稳定和模型的推理能力至关重要。
-
数学数据
通过 LLM 过滤基于证明和多项选择的问题,来避免 RL 过程中的 reward hacking(常见方法是修改问题,让答案是数字)。
这一过程从原始问题集中移除了约 50% 的简单问题。
-
全局 n-gram 去重。
-
过滤不能被先进推理模型解决的问题,和那些过于困难或包含错误答案的问题。
-
对于剩余的问题,使用 MiMo-7B 的 SFT 版本进行 16 次推理,剔除通过率超过90%的问题。
-
开源数据集;收集的竞赛水平的数据。
经过数据清洗后,建立了一个包含 100K 个问题的数学训练集。
- 代码数据
- 过滤没有测试case的数据。
- 对于有标准答案的问题,排除那些标准答案无法通过所有测试用例的问题。
- 对于没有标准答案的问题,排除那些在先进推理模型的 16 次推理中没有任何测试用例能够被解决的问题。
- 用 MiMo-7B 的 SFT 版本来过滤掉在所有 16 次推理中都被解决的简单问题。 经过数据清洗后,建立了一个包含 30K 个问题的代码训练集。
九、总结
数据构造过程中的通用做法
- 排除特别难和特别简单的数据
- 往往会单独训练一个用于数据生成或清洗的模型
- 数据合成过程中的 prompt 设计
- Pre-training 主要关注数据的多样性和质量;Post-training 则大多注重模型推理能力
| 模型 | 是否微调 / 训练模型 | Pre-training 数据量 | Pre-training 特点 | Post-training 特点 |
|---|---|---|---|---|
| Qwen3 | ✅ | 36T | 开发了多语言标注系统 | query & response 过滤 |
| Qwen3-Coder | ✅❌ | 7.5T | YaRN 扩展上下文长度 | Hard to Solve, Easy to Verify |
| Qwen3-Embedding | ✅❌ | 150M | 仅使用合成数据 | 余弦相似度大于 0.7 的数据 |
| Deepseek V3 | ✅ | 14.8T | 减少数据冗余 | 用专家模型来生成数据 |
| Deepseek R1 | ❌ | \ | Deepseek V3 Base + SFT + RL + SFT + RL | |
| Kimi K2 | ✅ | 15.5T | 通过重写提高 token 利用率 | 大范围 Agent 数据合成流程 |
| GPT-OSS | ? | \ | 强调安全 | |
| MiMo-7B | ✅ | 25T | 数据混合策略 | 数据清洗 |
十、AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献373条内容
已为社区贡献373条内容

所有评论(0)