大模型-训练-【篇三:微调】
PEFT(参数高效微调)是一种在不调整全部模型参数的情况下将预训练语言模型适配下游任务的技术库。它通过微调少量参数显著降低计算和存储成本,同时保持与全参数微调相当的性能。主流方法包括AdapterTuning、PrefixTuning、PromptTuning、LoRA等,其中LoRA通过低秩矩阵模拟全参数微调,在推理时无额外计算开销。P-Tuning及其改进版本通过多层提示编码提升小模型表现。这
简介
PEFT(Parameter-Efficient Fine-Tuning)是一个用于在不微调所有模型参数的情况下,有效地将预先训练的语言模型(PLM)适应各种下游应用的库。PEFT方法只微调少量(额外)模型参数,显著降低了计算和存储成本,因为微调大规模PLM的成本高得令人望而却步。最近最先进的PEFT技术实现了与完全微调相当的性能。
大模型训练的微调方法包括:Adapter Tuning、Prefix Tuning、Prompt Tuning、LoRA、P-tuning和AdaLoRA等。如下:
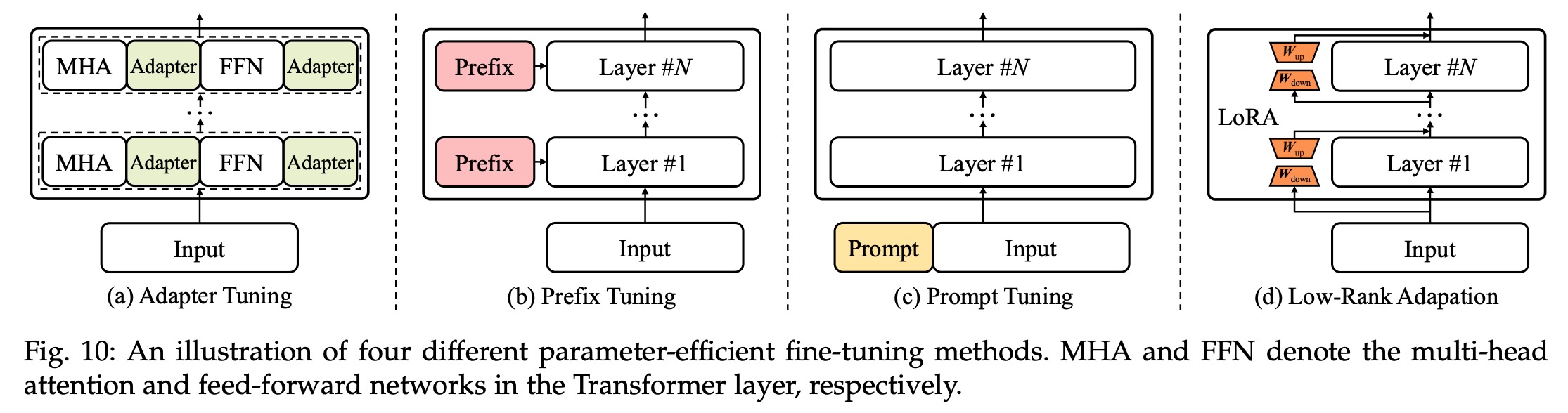
Low-Rank Adaptation:即LoRA
典型应用
- ChatGLM-Tuning :一种平价的chatgpt实现方案,基于清华的 ChatGLM-6B + LoRA 进行finetune。
- Alpaca-Lora:使用低秩自适应(LoRA)复现斯坦福羊驼的结果。Stanford Alpaca 是在 LLaMA 整个模型上微调,而 Alpaca-Lora 则是利用 Lora 技术,在冻结原模型 LLaMA 参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅微调的成本显著下降,还能获得和全模型微调类似的效果。
- BLOOM-LORA:由于LLaMA的限制,我们尝试使用Alpaca-Lora重新实现BLOOM-LoRA。
微调
Adapter Tuning
提出时间:2019年
微调范式:将Adapter 结构嵌入 Transformer 的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构进行微调。
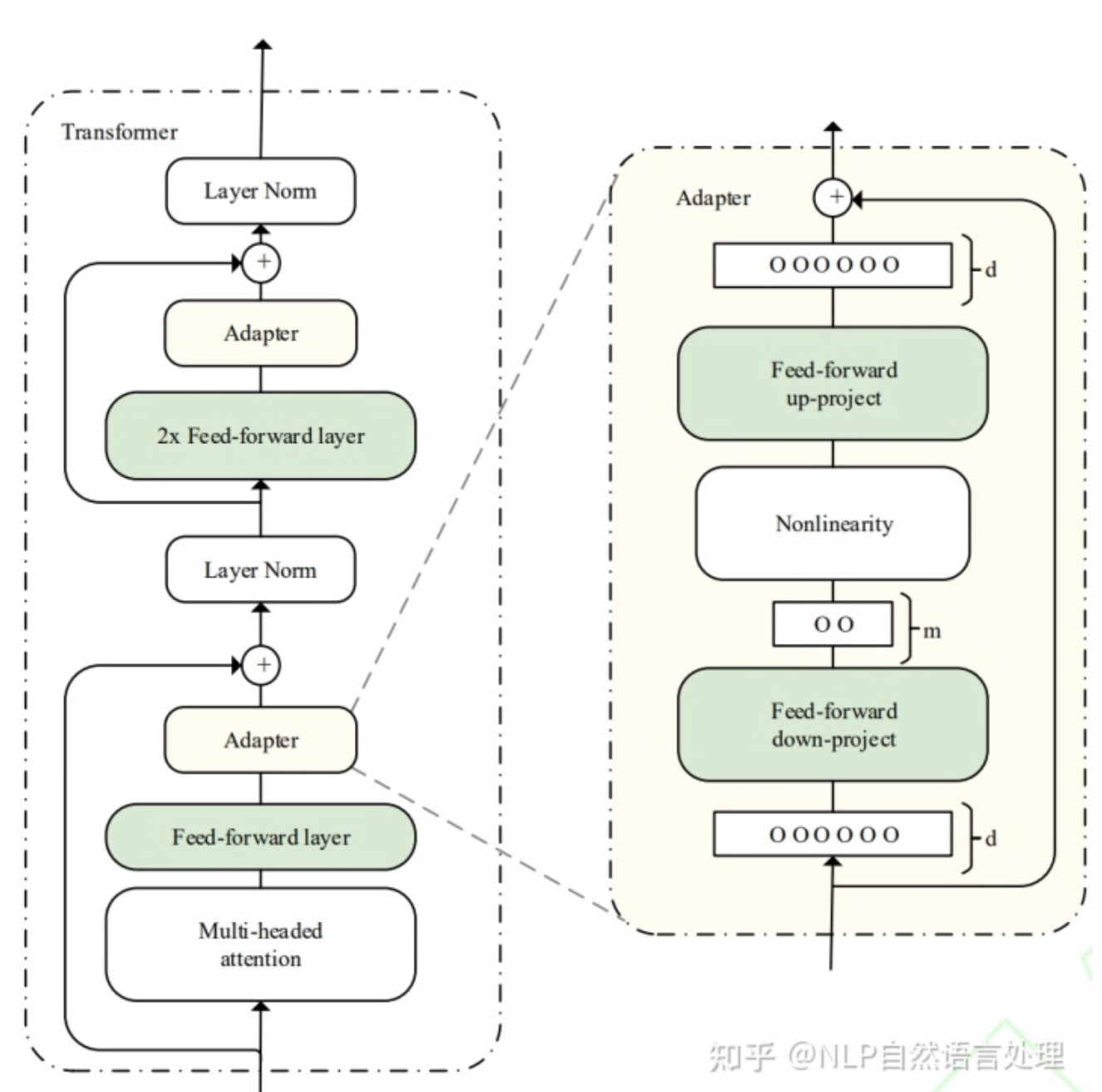
Adapter算法改进:
如:2020年,Pfeiffer J等人对Adapter进行改进,「提出AdapterFusion算法,用以实现多个Adapter模块间的最大化任务迁移」。
具体改进:详见Adapter Tuning - 搜索结果 - 知乎
不足:
Adapter和Prompt中连续模板的构造需要在预训练模型的基础上添加参数,并在训练过程中对参数进行优化。与全模型微调方法相比,虽然降低了训练成本,但是在模型中新添加了参数,会导致模型在推理过程中效率的降低,在实际中应用中这个缺点会被放大。
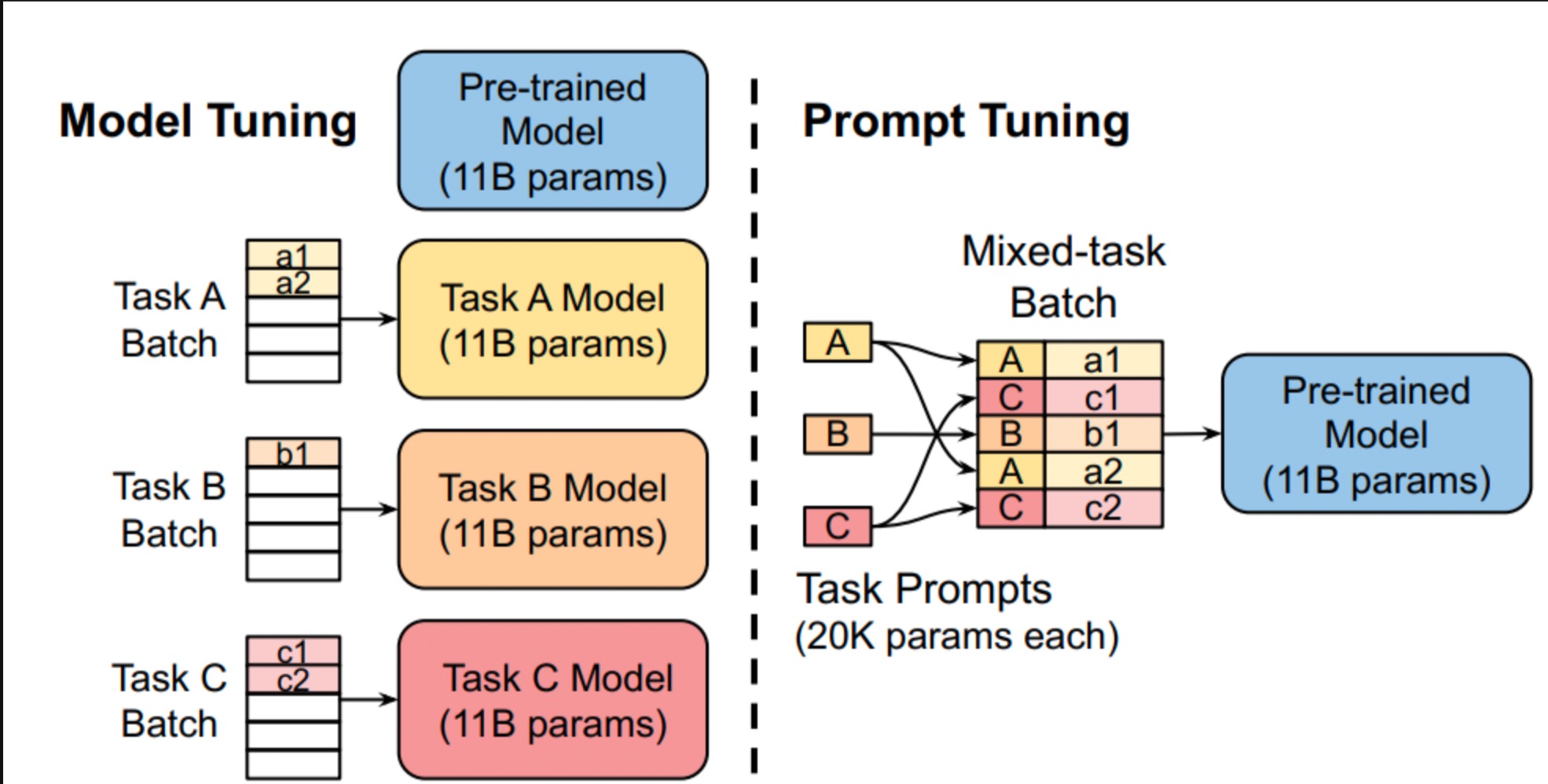
Prompt Tuning
提出时间:2021.03
微调范式:固定预训练参数,为每一个任务额外添加一个或多个embedding,之后拼接query正常输入LLM,并只训练这些embedding。
效果:
- 显著优于使用GPT-3进行fewshot prompt设计。
- 当参数达到100亿规模与全参数微调方式效果无异。
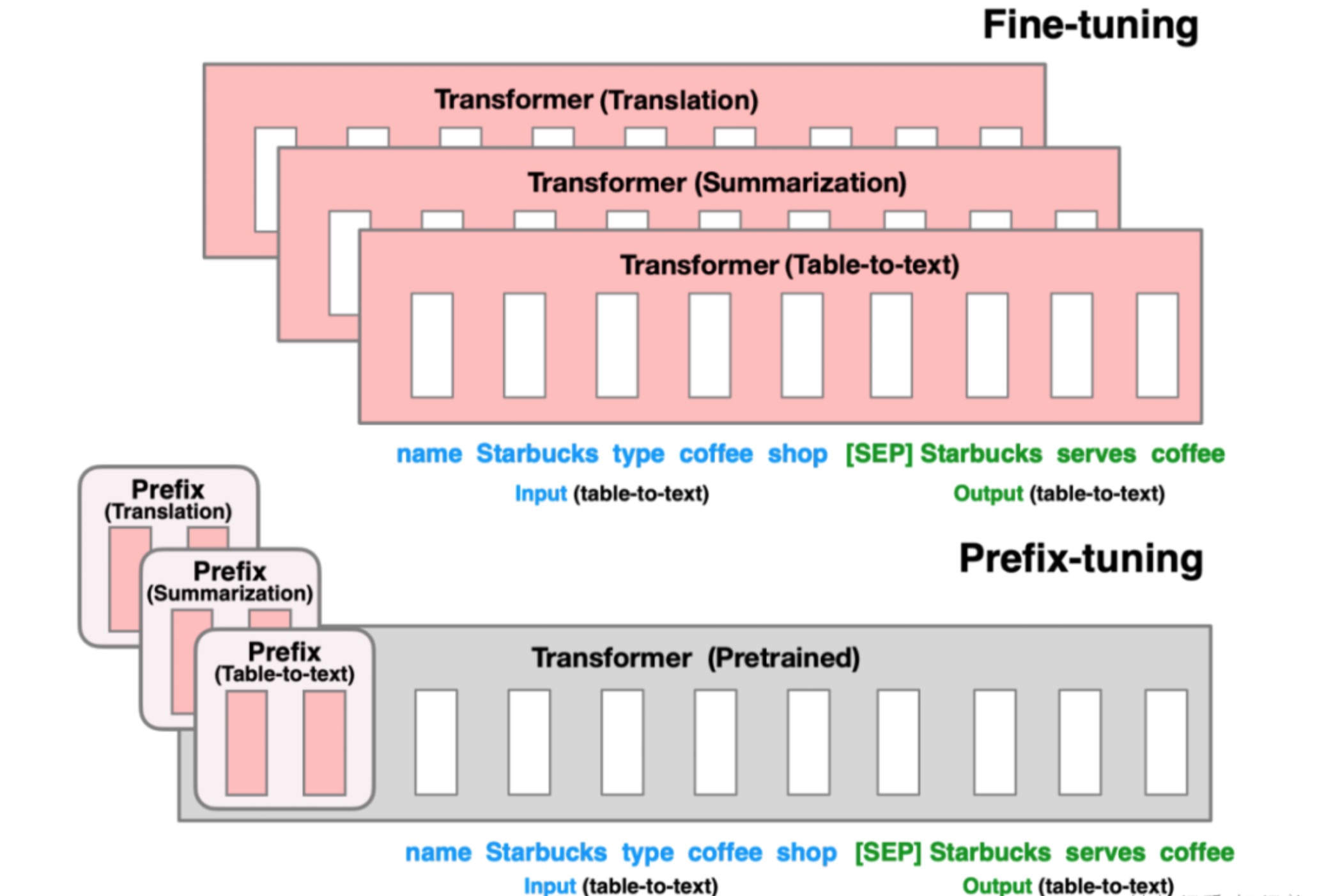
Prefix Tuning
提出时间:2021.08.01
微调范式:固定预训练参数,但除为每一个任务额外添加一个或多个embedding之外,利用多层感知编码prefix,注意多层感知机就是prefix的编码器,不再像prompt tuning继续输入LLM。
效果:
- 与全参数微调方式效果无异。
LoRA Tuning
提出时间:2021.08.16
现存在问题:由于增加了模型的深度从而额外增加了模型推理的延时,如 Adapter 方法Prompt 较难训练,同时减少了模型的可用序列长度,如 Prompt Tuning、Prefix Tuning、P-Tuning 方法往往效率和质量不可兼得,效果差于 full-finetuning
微调范式:Low-Rank Adaption(LoRA),设计了如下所示的结构,在涉及到矩阵相乘的模块,引入 A、B 这样两个低秩矩阵模块去模拟 Full-finetune 的过程,相当于只对语言模型中起关键作用的低秩本质维度进行更新。
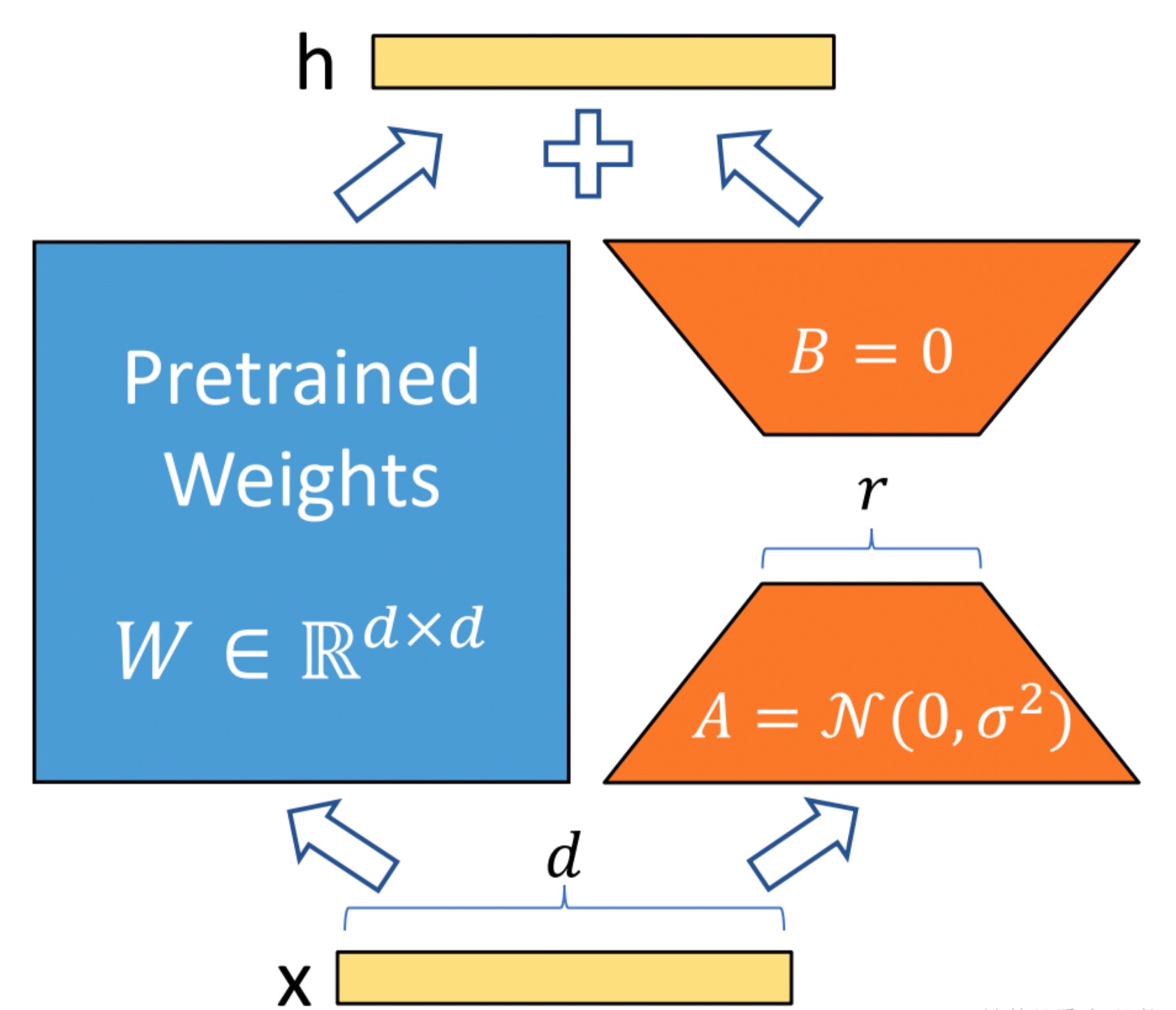
效果:
- 相比于原始的 Adapter 方法“额外”增加网络深度,必然会带来推理过程额外的延迟,该方法可以在推理阶段直接用训练好的 A、B 矩阵参数与原预训练模型的参数相加去替换原有预训练模型的参数,这样的话推理过程就相当于和 Full-finetune 一样,没有额外的计算量,从而不会带来性能的损失。
- 该方法由于实际上相当于是用 LoRA 去模拟 Full-finetune 的过程,几乎不会带来任何训练效果的损失,后续的实验结果也证明了这一点
训练:参考
- 深入浅出 LoRA
- 大模型参数高效微调技术实战(五)-LoRA-六虎
- LoRA还是QLoRA?
- 如何从头开始编写LoRA代码,这有一份教程
- LoRA及其变体概述:LoRA, DoRA, AdaLoRA, Delta-LoRA
- 在进行 LoRA 微调时,首先需要确定 LoRA 微调参数,其中一个重要参数即是 target_modules(要替换为 LoRA 的模块称号列表或模块称号的正则表达式,针对不同类型的模型,模块称号不一样)。
- 在 PEFT 中支持的模型默许的模块名如下所示:
TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPING = {
"t5": ["q", "v"],
"mt5": ["q", "v"],
"bart": ["q_proj", "v_proj"],
"gpt2": ["c_attn"],
"bloom": ["query_key_value"],
"blip-2": ["q", "v", "q_proj", "v_proj"],
"opt": ["q_proj", "v_proj"],
"gptj": ["q_proj", "v_proj"],
"gpt_neox": ["query_key_value"],
"gpt_neo": ["q_proj", "v_proj"],
"bert": ["query", "value"],
"roberta": ["query", "value"],
"xlm-roberta": ["query", "value"],
"electra": ["query", "value"],
"deberta-v2": ["query_proj", "value_proj"],
"deberta": ["in_proj"],
"layoutlm": ["query", "value"],
"llama": ["q_proj", "v_proj"],
"chatglm": ["query_key_value"],
"gpt_bigcode": ["c_attn"],
"mpt": ["Wqkv"],
}- target_modules一般是一个模块称号列表,每一个字符串是需要进行LoRA的层名称,例如:
target_modules = ["q_proj","v_proj"]
# q_proj,k_proj,v_proj,o_proj,down_proj,gate_proj,up_proj,参考:
## 1)https://blog.csdn.net/BIT_666/article/details/132161203
## 2)https://zhuanlan.zhihu.com/p/636784644
# 补充说明
#Transformer的权重矩阵包含Attention模块里用于核算query, key, value的Wq,Wk,Wv以及多头attention的Wo和MLP层的权重矩阵,LoRA只应用于Attention模块中的4种权重矩阵,并且经过融化实验发现一起调整Wq和Wv会发生最佳成果,因而,默许的模块名基本都为Wq和Wv权重矩阵。
在创建 LoRA 模型时,会获取该参数,然后在原模型中找到对应的层,该操作主要通过使用 re 对层名进行正则匹配实现:
# 找到模型的各个组件中,名字里带"q_proj","v_proj"的
target_module_found = re.fullmatch(self.peft_config.target_modules, key)
# 这里的 key,是模型的组件名AdaLoRA Tuning
提出时间:2023.03.18
现存在问题:预训练语言模型中的不同权重参数对下游任务的贡献是不同的。因此需要更加智能地分配参数预算,以便在微调过程中更加高效地更新那些对模型性能贡献较大的参数。
微调范式:通过奇异值分解将权重矩阵分解为增量矩阵,并根据新的重要性度量动态地调整每个增量矩阵中奇异值的大小。这样可以使得在微调过程中只更新那些对模型性能贡献较大或必要的参数,从而提高了模型性能和参数效率。
效果:参数量明显减少,效果和全参数微调差不多
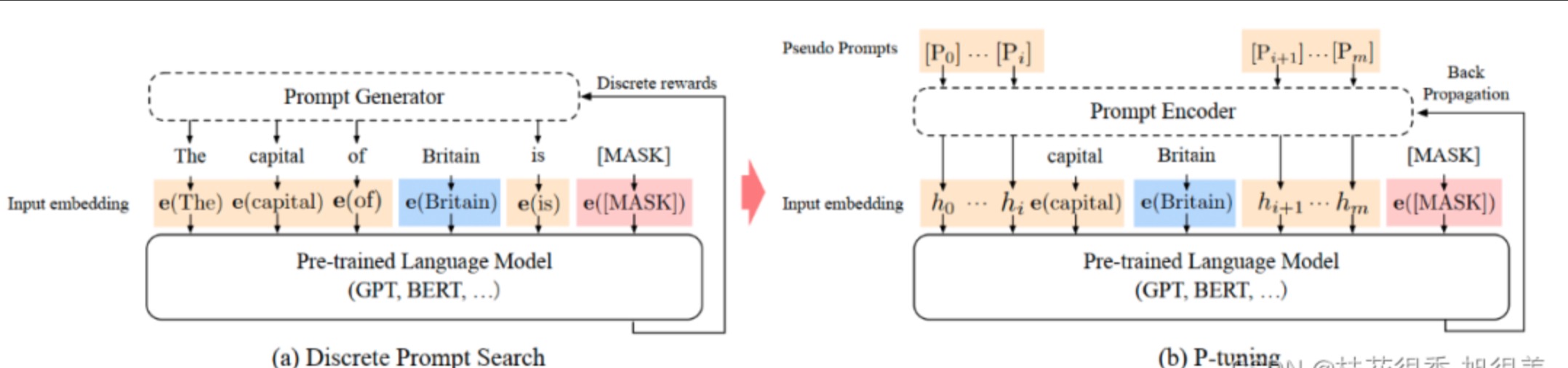
P-Tuning
提出时间:2021.11.02
微调范式:p-tuning依然是固定LLM参数,利用多层感知机和LSTM对prompt进行编码,编码之后与其他向量进行拼接之后正常输入LLM。注意,训练之后只保留prompt编码之后的向量即可,无需保留编码器。
效果:
- GPT在P-tuning的加持下可达到甚至超过BERT在NLU领域的性能
P-Tuning v2
提出时间:2022.03.20
微调范式:p-tuning的问题是在小参数量模型上表现差,于是有了V2版本。相比 Prompt Tuning 和 P-tuning 的方法,P-tuning v2 方法在多层加入Prompts tokens 作为输入,带来两个方面的好处:
- 带来更多可学习的参数(从 P-tuning 和 Prompt Tuning 的 0.1% 增加到0.1%-3%),同时也足够 parameter-efficient。
- 加入到更深层结构中的 Prompt 能给模型预测带来更直接的影响。
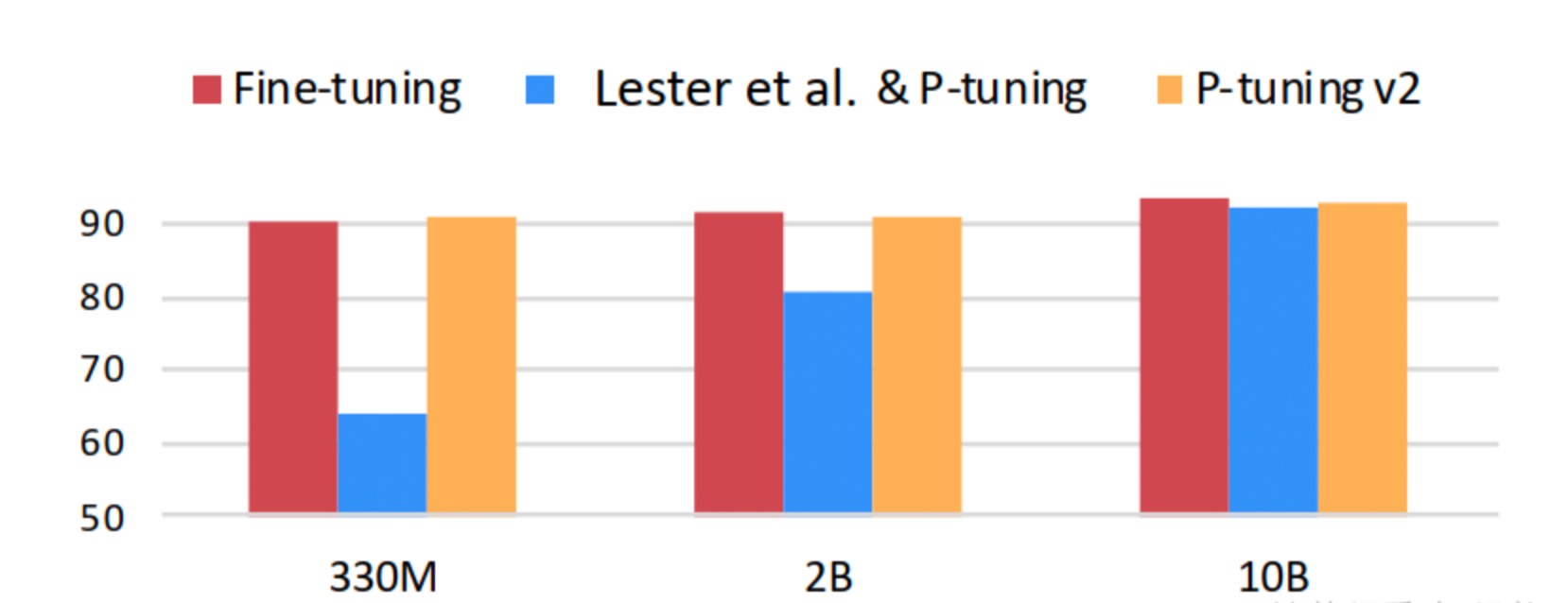
效果:
- 在小模型下取得与Full-finetuning相近的结果,并远远优于P-Tuning。
- 不同任务下的 P-Tuning v2 效果都很好,而 P-Tuning 和 Prompt Learning 效果不好;同时,采用多任务学习的方式能在多数任务上取得最好的结果。
- Verbalizer with LM head v.s. [CLS] label with linear head,两种方式没有太明显的区别
- Prompt depth,在加入相同层数的 Prompts 前提下,往更深层网络加效果大部分优于往更浅层网络。
结尾
亲爱的读者朋友:感谢您在繁忙中驻足阅读本期内容!您的到来是对我们最大的支持❤️
正如古语所言:"当局者迷,旁观者清"。您独到的见解与客观评价,恰似一盏明灯💡,能帮助我们照亮内容盲区,让未来的创作更加贴近您的需求。
若此文给您带来启发或收获,不妨通过以下方式为彼此搭建一座桥梁: ✨ 点击右上角【点赞】图标,让好内容被更多人看见 ✨ 滑动屏幕【收藏】本篇,便于随时查阅回味 ✨ 在评论区留下您的真知灼见,让我们共同碰撞思维的火花
我始终秉持匠心精神,以键盘为犁铧深耕知识沃土💻,用每一次敲击传递专业价值,不断优化内容呈现形式,力求为您打造沉浸式的阅读盛宴📚。
有任何疑问或建议?评论区就是我们的连心桥!您的每一条留言我都将认真研读,并在24小时内回复解答📝。
愿我们携手同行,在知识的雨林中茁壮成长🌳,共享思想绽放的甘甜果实。下期相遇时,期待看到您智慧的评论与闪亮的点赞身影✨!
万分感谢🙏🙏您的点赞👍👍、收藏⭐🌟、评论💬🗯️、关注❤️💚~
自我介绍:一线互联网大厂资深算法研发(工作6年+),4年以上招聘面试官经验(一二面面试官,面试候选人400+),深谙岗位专业知识、技能雷达图,已累计辅导15+求职者顺利入职大中型互联网公司。熟练掌握大模型、NLP、搜索、推荐、数据挖掘算法和优化,提供面试辅导、专业知识入门到进阶辅导等定制化需求等服务,助力您顺利完成学习和求职之旅(有需要者可私信联系)
友友们,自己的知乎账号为“快乐星球”,定期更新技术文章,敬请关注!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)