Meta打开AI元认知,让AI不止会解题,还会总结套路了
大语言模型记性不太好。具体来说,它们在解决需要多个步骤的复杂问题时,经常“顾尾不顾头”。比如它刚辛辛苦苦推导出一个几何级数求和公式解了一道题,下一道题遇到类似的问题,它就把刚才的功夫忘得一干二净,又从头开始重新推导一遍。这个过程不仅浪费了大量的计算资源,还拖慢了响应速度。这就像一个学生,每次考试都现场推导勾股定理,而不是直接记住a²+b²=c²。Meta、Mila-Quebec人工智能研究所、蒙特
大语言模型记性不太好。
具体来说,它们在解决需要多个步骤的复杂问题时,经常“顾尾不顾头”。
比如它刚辛辛苦苦推导出一个几何级数求和公式解了一道题,下一道题遇到类似的问题,它就把刚才的功夫忘得一干二净,又从头开始重新推导一遍。这个过程不仅浪费了大量的计算资源,还拖慢了响应速度。
这就像一个学生,每次考试都现场推导勾股定理,而不是直接记住a²+b²=c²。
Meta、Mila-Quebec人工智能研究所、蒙特利尔大学、普林斯顿大学,他们提出了一套简单的机制,给大模型打开了元认知,让它学会了反思和总结。

简单说,就是让模型在解完一道题后,自己回头看看解题过程,把那些重复出现的、可以泛化的推理步骤给揪出来,然后打包成一个简洁、可重用的‘行为’。
这个‘行为’就像一个武功招式,有个名字,还有一句心法口诀。比如下面这个:
systematic_counting → 通过检查每个数字的贡献而不重叠来系统地计算可能性;这样可以防止遗漏案例和重复计算。
这些‘行为’招式会被收录进一本不断更新的‘行为手册’里。以后再遇到类似的江湖难题,模型就直接翻开手册查阅对应的招式就行。
这套玩法,研究人员称之为‘元认知重用’。
AI如何打造自己的‘武功秘笈’
这本秘笈不是人类高手写的,而是大模型自己琢磨出来的。
整个过程有点像一个三步走的自我修炼:
第一步,找一个策略大师。研究人员请来了DeepSeek-R1-Distill-Llama-70B这个模型担任‘元认知策略师’。它基于Llama-3.3-70B-Instruct架构,是个解数学题和编程题的好手。
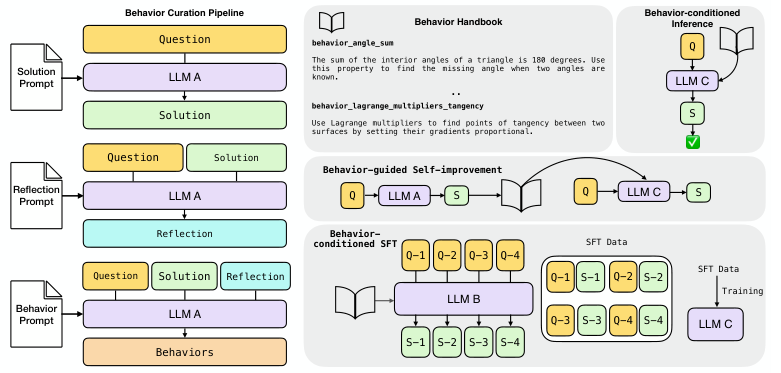
第二步,解题与反思。策略师先老老实实地解决一个给定的问题,写下详细的解题思路和答案。然后,它会像一个严格的老师一样,回头审视自己的解题过程,进行反思:逻辑通不通顺?答案对不对?更重要的是,这里面有没有什么可以提炼出来、以后能用得上的通用技巧?

第三步,提炼与入库。策略师结合原始问题、自己的解题方案和反思,最终提炼出一套‘行为’,也就是(名称,指令)的组合,然后把它们郑重地写进那本不断加厚的‘行为手册’里。
这个过程就像一个武学宗师,打赢了一场架,不仅要复盘胜负手,还要把其中的精妙招式总结成心法,传给后人。
值得一提的是,这种‘行为手册’里装的是程序性的知识,是关于‘如何思考’的方法论。这和市面上主流的检索增强生成(Retrieval-Augmented Generation,RAG)系统有本质区别,RAG主要存储的是陈述性的事实知识,比如‘法国的首都是巴黎’,用来回答事实性问题。而‘行为手册’教的是‘如何找到首都’的通用方法。
‘武功秘笈’的三种实战用法
秘笈写好了,研究人员设计了三种方式,让这本手册在实战中发挥作用。
第一种,行为条件推理(Behavior-Conditioned Inference,BCI)。
这是最直接的用法。来了一个新问题,先别急着动手,去手册里翻一翻,找几条可能用得上的招式。然后把这些招式连同问题一起,作为上下文(context)喂给解题的模型。
这相当于给学生发了一张写着关键公式和提示的‘小抄’。
怎么找相关的招式呢?
对于像MATH数据集这种题目本身就分好类的,比如‘代数’、‘几何’,那就简单了,直接从对应类别的行为里找就行。研究人员从MATH训练集中随机抽取了1000个问题,生成了一本包含七个章节(主题)的行为手册,共计785条行为。

对于没有分类的数据集,比如美国数学邀请赛(American Invitational Mathematics Examination,AIME)的题目,就得上点技术手段了。研究人员使用BGE-M3模型将问题和手册里所有行为都转换成向量,然后用FAISS(一个用于密集向量相似性搜索和聚类的库)这个工具,快速找到和问题向量最接近的前40条行为。这种基于嵌入的检索方式扩展性很强,理论上可以维护一个跨领域的超大行为库,并且能以很低的延迟检索。
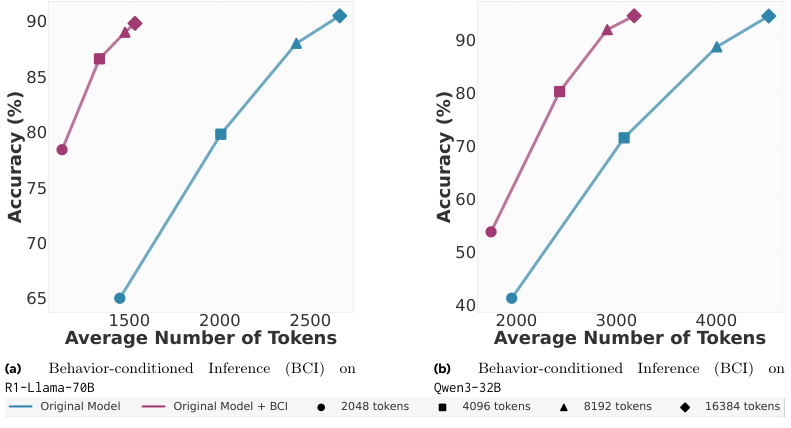
实验结果显示,有了‘小抄’的模型,在MATH和AIME数据集上,用更少的输出令牌就达到了与原始模型相当甚至更高的准确率。省钱又增效。

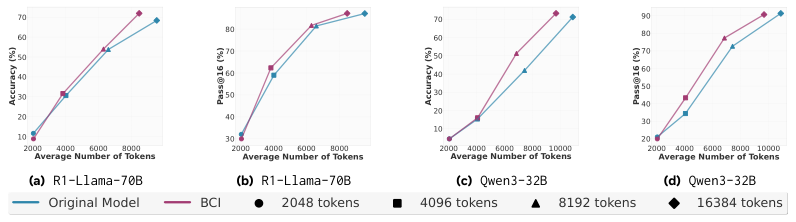
第二种,行为引导的自我改进。
这个玩法是让模型自己教自己。模型(比如R1-Llama-70B)既是出题的元认知策略师,又是答题的学生。
它先用较少的计算资源(2048令牌预算)解一道题,得到一个初步的答案。然后,它从这个初步的解题过程中提炼出‘行为’,再把这些新鲜出炉的行为作为提示,回头用更多的计算资源(2048到16384令牌)重新解这道题。
相当于一个学生做完草稿后,自己总结了一下方法论,然后用这个方法论去完善草稿,写出更漂亮的最终答案。
研究人员设计了一个‘批判和修订’的基线方法做对比,也就是让模型直接回头看自己的草稿,然后进行修改。
结果显示,行为引导的自我改进方法,在准确率上几乎全面优于简单的‘批判和修订’。而且随着给的计算资源增多,性能提升也更稳定。这说明,提炼‘行为’这个步骤,确实能帮助模型更有效地进行自我提升。
第三种,行为条件监督微调(Behavior-Conditioned Supervised Fine-Tuning,BC-SFT)。
前面两种方法,每次解题都得带着那本厚厚的‘行为手册’,不仅麻烦,还增加了输入令牌的成本。有没有办法把这些武功招式直接内化成模型的本能呢?
有,就是监督微调。
这个过程需要三个角色:元认知策略师(还是R1-Llama-70B)、教师(也是R1-Llama-70B)和学生(比如Qwen或Llama系列的一些小模型)。
首先,策略师和教师合作,用BCI的方法生成一大批高质量的、带有行为指导的解题范例。这批范例构成了一个特殊的训练数据集DBC。
然后,让学生模型在这个数据集上进行微调训练。
关键点在于,训练的时候,学生模型看到的是问题和教师给出的‘行为条件响应’,但并不直接看到行为本身。训练完成后,在测试时,也只给学生模型问题,不给任何行为提示。
这么做的目的,是希望学生模型能通过学习这些优秀的解题范例,把其中蕴含的推理‘行为’融入到自己的参数里,变成一种直觉。
这就好比一个武学奇才,不需要看武功秘笈,只通过观摩顶尖高手的过招,就领悟了其中的精髓,并化为己用。
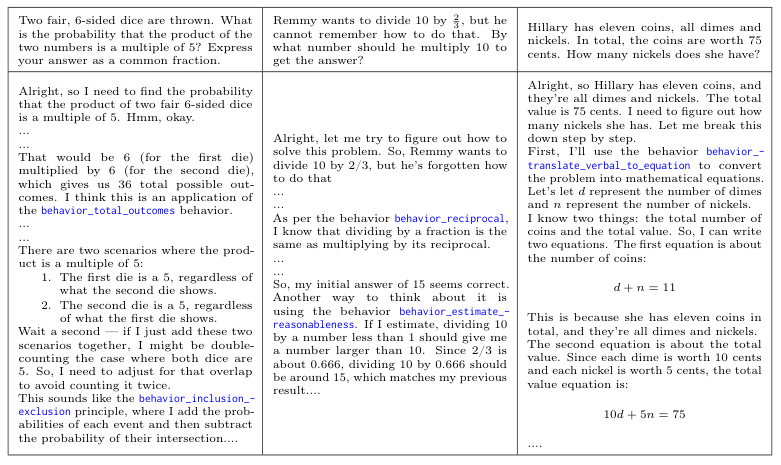
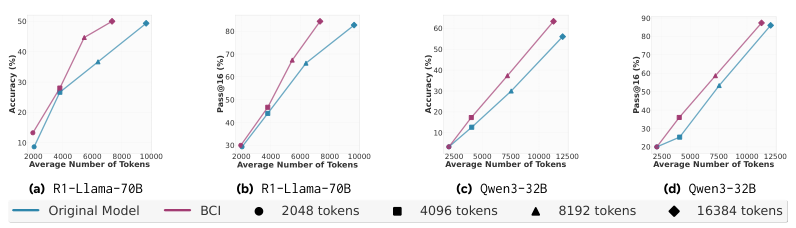
实验结果令人振奋。经过BC-SFT训练的学生模型,不仅在解题时令牌效率更高,而且在几乎所有计算预算下,准确率都超过了两个基线(原始模型和在普通解题数据上微调的模型)。
更厉害的是,BC-SFT能有效地把一些本身不擅长推理的模型(比如Qwen2.5-14B-Base)调教成推理高手。这表明,BC-SFT不仅仅是教模型如何说得更简洁,而是真正向模型的参数里注入了有用的推理能力。
研究人员检查了训练数据的答案正确率,发现带有行为指导的范例(44.4%)和普通范例(42.7%)的正确率差距微乎其微。这说明,下游性能的巨大差异,源于解题过程的质量,而不是答案本身。
局限与未来
这项工作为大模型推理效率低下这个老大难问题,提供了一个优雅的解决方案。通过元认知重用,模型进化到可以回忆和运用已有的方法论。
这个框架是通用的,不局限于数学,未来可以在编程、科学推理、甚至开放式对话等领域大放异彩。
当然,目前的实现还有一些局限。
比如,行为的检索是在解题开始前一次性完成的,不够灵活。理想情况下,模型应该能在推理过程中,根据需要动态地、即时地去手册里查找行为,就像人思考时随时查资料一样。
另外,这项研究目前只是一个概念验证。未来能否扩展到构建一个跨越多个领域的庞大行为库,并在大规模微调中应用,还有待观察。
看来,不仅会解决问题,还知道‘如何’解决问题的AI就要来了。
参考资料:
https://arxiv.org/abs/2509.13237
END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)