阿里云携手 海信聚好看 构建开源云原生大数据平台最佳实践
海信聚好看基于阿里云EMR全栈开源大数据技术体系——包括 EMR on ECS、Serverless Spark 、Serverless StarRocks等核心产品,并引入开放标准的数据湖格式 Apache Paimon,实现了多个技术变革。
一、海信聚好看简介
聚好看科技股份有限公司是海信集团旗下互联网科技公司,提供互联网电视云服务及Al场景功能和AloT智慧生活解决方案,以AI赋能海信旗下多品牌多品类智能终端,持续推动技术革新与落地转化,为超1.2亿全球家庭用户提供智能化体验。
经过多年的系统化建设与技术沉淀,聚好看已构建起一套以离线大数据集群为核心、覆盖全业务场景的现代化大数据平台。该平台全面支撑数据运营、用户画像、搜索推荐等关键业务,累计数据规模突破 X PB,日均新增数据量超百TB,是驱动业务增长的核心引擎。
二、聚好看开源大数据升级项目概览
随着智能电视行业向精细化运营与个性化服务加速演进,叠加“AI + Data”深度融合的技术趋势,海信聚好看持续推进数智化转型。在内容智能推荐、用户行为洞察等核心场景中,业务对数据的时效性、准确性与服务敏捷性提出了更加苛刻的要求:
-
数据分析需求从“查询半天前的离线报表”升级为“即时洞察5分钟前的用户行为趋势”;
-
用户画像更新从“T+1静态标签”转向“近实时动态偏好感知”;
-
运营决策周期从“天级响应”压缩至“分钟级闭环”。
在此背景下,传统以批处理为中心的大数据架构面临严峻挑战:数据链路长、计算资源耦合、扩展成本高、入湖延迟大等问题日益凸显,难以支撑业务对“实时化、智能化、弹性化”的综合诉求。
为应对这一变革,聚好看启动大数据平台架构升级工程,致力于构建面向未来的下一代数据基础设施。通过与阿里云深度合作,基于其全栈开源大数据技术体系——包括 EMR on ECS、Serverless Spark 、Serverless StarRocks等核心产品,并引入开放标准的数据湖格式 Apache Paimon,双方共同实现了多个技术变革:
1、实时数据湖建设
2、存算分离架构升级
3、Serverless算力模式
4、持续性能优化
三、实时数据湖架构助力聚好看数据新鲜度全面提升
📌 问题:传统架构难以满足实时化运营需求
随着电视OTT行业进入存量竞争时代,聚好看持续推进精细化、智能化运营,亟需通过数字化手段实时感知用户行为变化,实现精准推荐与动态营销。然而,现有大数据平台基于经典的 Lambda 架构构建,ETL 链路以批处理为主,数据更新时效普遍为小时级,严重制约了业务敏捷性与用户体验提升。
✅ 解决方案:构建基于 Apache Paimon 的流批一体实时数据湖
为突破数据时效瓶颈,聚好看携手阿里云,引入 Apache Paimon 作为统一数据湖存储格式,并结合 Serverless Spark 构建新一代湖仓一体、流批融合的实时数据架构。Paimon 创新性地融合 LSM(Log-Structured Merge)树架构与实时数据湖设计,原生支持流式写入与增量读取,实现了真正的“批可流化、流可统管”。
在落地实践中,利用 Paimon与开源 Spark、StarRocks 大数据生态技术栈开放融合的优势,借助Serverless Spark先进技术栈,通过Spark Streaming 技术,快速实现了实时数据入湖的链路,用 Paimon 格式重构了ODS层存储机制,实现了亿级设备数据分钟级入湖,实时可查可用,极大提升了数据新鲜度。通过Serverles StarRocks可以实时对Paimon数据进行极速分析和查询。
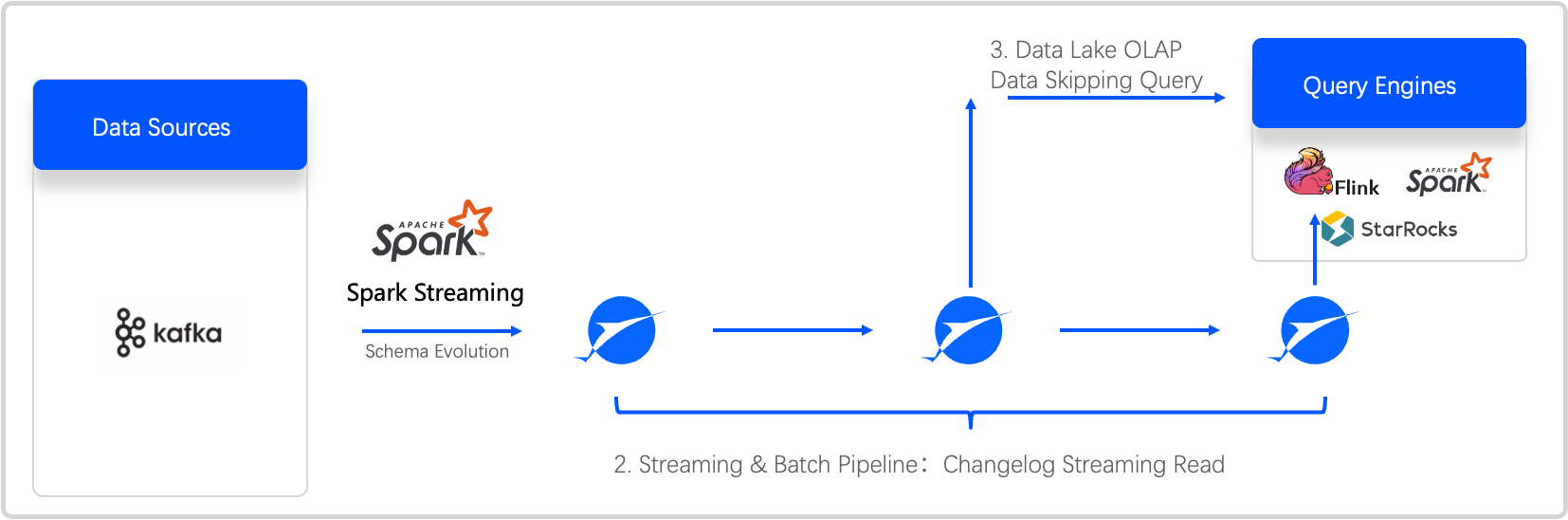
💡 价值:数据新鲜度跃升,驱动智能运营升级
-
通过该架构升级,聚好看实现了从“离线主导”向“近实时驱动”的根本转变:
-
数据入湖时效从小时级缩短至5分钟内,数据新鲜度提升超10倍;
-
支持亿级规模数据下的高吞吐写入与低延迟查询,在保障稳定性的同时显著降低运维复杂度;
四、存算分离架构破解资源耦合瓶颈,提升平台弹性与稳定性
📌 问题:存算一体架构制约资源效率与系统扩展性
随着聚好看数据规模持续增长(累计超 X PB),原有大数据平台采用传统存算一体架构,计算与存储深度绑定于 HDFS 集群。该模式存在显著瓶颈:
-
资源扩展不灵活:扩容需同时增加存储与计算资源,导致资源错配与浪费;
-
NameNode 压力过大:元数据规模急剧增长,导致 HDFS NameNode 负载过高,出现响应延迟甚至单点故障风险;
-
多引擎协同困难:Flink、Spark、StarRocks 等异构计算引擎难以高效共享同一份数据,存在数据冗余复制与一致性挑战。
这些问题严重限制了平台的弹性能力与运维效率,难以支撑实时化、多场景并发的数智化运营需求。
✅ 解决方案:构建基于 OSS 的云原生存算分离架构
为突破资源耦合困局,聚好看全面升级底层架构,采用 存算分离(Compute-Storage Separation) 设计范式,将数据存储与计算资源彻底解耦。核心举措包括:
-
将全部核心数据统一迁移至高可靠、无限扩展的阿里云对象存储 OSS,作为统一的数据湖底座;
-
基于EMR on ECS、EMR Serverless Spark、EMR Serverless StarRocks 构建弹性计算集群,通过云内高速网络连接 OSS 存储层;
-
借助 OSS-HDFS 的 HDFS 兼容特性,实现现有 HDFS 应用无缝迁移,同时享受对象存储的弹性与成本优势;
-
针对实时数仓场景,选择 StarRocks 存算分离架构,将计算和存储进行解耦。在这种模式中,数据持久化存储转移到了成本更优化且可靠性更高的远程对象存储(例如OSS)或HDFS上。计算节点(CN)所在的本地磁盘主要用作缓存,以加速对高频访问数据的查询。

存算分离模式下,可以动态地添加或移除计算节点,实现秒级别的扩缩容,有效降低了数据存储与资源扩展的成本,并促进资源隔离及计算资源的弹性伸缩。
💡 价值:资源利用率提升,系统更稳定、更开放
存算分离架构落地后,带来显著技术与业务收益:
-
实现“一份数据、多种计算”:OSS 统一存储支持 Spark 批处理、Flink 实时计算、StarRocks OLAP 查询等多引擎并发访问,避免数据冗余,提升数据一致性与使用效率。
-
资源弹性显著增强:计算资源可根据负载动态扩缩容(如Serverless Spark),高峰时段自动扩容千核算力,低峰期自动释放,整体算力弹性供给能力提升数倍。
-
显著降低 NameNode 压力,元数据操作时延降低50%,系统稳定性大幅提升;
五、Serverless 模式突破算力瓶颈,实现弹性敏捷的数据处理
📌 问题:传统架构难以应对算力潮汐与资源刚性约束
随着聚好看数据作业规模持续增长,大数据集群长期处于高负载运行状态。原有基于存算一体的离线架构 在算力供给方面暴露出多重瓶颈:
-
资源扩容僵化:计算与存储必须同步扩展,导致高峰期资源不足、低谷期大量闲置,资源利用率低下;
-
“潮汐效应”显著:实时化需求催生每日多个数据处理高峰(如早间报表、晚间用户行为汇总),算力争抢严重,任务排队频发;
-
人为调度受限:受制于 IDC 物理资源上限(最大仅支持 3000 vCore),高峰期无法满足并发需求,不得不推迟非关键任务窗口,导致部分业务指标延迟产出,影响运营决策时效。
-
传统模式已无法支撑“按需响应、准时交付”的现代数据服务要求。
✅ 解决方案:引入 Serverless 弹性算力,构建智能调度新范式
为打破算力桎梏,聚好看全面拥抱云原生理念,采用 Serverless 模式重构计算层,实现面向业务负载的动态资源供给。核心举措包括:
-
引入 Serverless Spark 和 Serverless StarRocks 服务,基于 OSS 统一存储层实现计算与存储彻底解耦,支持计算资源秒级弹性伸缩;
-
利用阿里云海量资源池与容器化调度能力,实现 最小粒度 1 核 的精细化资源计量,按实际使用量计费,彻底告别资源预占;
-
基于Serverless Spark提供的友好的用户交互和全面的开源生态,可以提交管理Streaming/SQL/PySpark等多类作业,基于SQL Editor和Notebook进行交互式的任务开发,基于Kyuubi等兼容聚好看历史的工作流管理方式;
-
高峰期算力爆发能力大幅提升,1 分钟内即可弹出数千核 vCore 资源,满足瞬时高并发处理需求。该模式实现了从“资源驱动调度”向“业务需求驱动执行”的根本转变。
 Serverless Spark 天级资源弹性
Serverless Spark 天级资源弹性
💡 价值:算力无限延展,数据时效全面提速
Serverless 架构的落地,为聚好看带来了前所未有的算力灵活性与效率提升:
-
算力瓶颈被彻底打破:不再受限于物理服务器数量,高峰期可调用云端近乎无限的计算能力,任务排队现象基本消除;
-
作业调度更加智能高效:调度策略从“看资源排期”转变为“按业务 SLA 排程”,关键任务可优先保障资源,确保核心指标准时产出;
-
资源成本显著优化:按实际使用量付费,避免空闲资源浪费,整体 TCO 下降超 30%;
-
Serverless Spark支持HMS元数据,全面兼容Kyuubi等开源任务管理框架等,大幅降低上云的迁移成本;
-
通过 Serverless 化升级,聚好看不仅解决了长期困扰的算力瓶颈,更建立起一套敏捷、弹性、低成本的现代化数据处理体系,为实时化、智能化运营提供了强有力的底层支撑。
六、全链路引擎优化加速聚好看数据处理效率
📌 问题:传统架构下性能调优空间有限,瓶颈突出
数据作业性能优化是大数据团队的核心职责。然而,在传统 Hadoop/Spark 架构下,优化手段长期依赖资源配置、SQL 改写、分区调整等表层方式,面临多重瓶颈:
-
执行引擎性能封顶:开源 Spark 的解释执行模式存在大量运行时开销,复杂查询性能难以提升;
-
Shuffle 效率低下:MapReduce 式 Shuffle 依赖本地磁盘 I/O,易引发网络拥塞、磁盘压力和任务失败,尤其在大规模并发场景下稳定性差;
-
小文件问题严重:高频批处理和流式写入产生海量小文件,导致元数据膨胀、NameNode 压力剧增、读取效率下降,显著拖累整体查询性能。
✅ 解决方案:三位一体性能优化体系构建
为实现性能优化,聚好看基于阿里云 EMR Serverless Spark,构建了覆盖查询优化层、查询执行层、数据存储层的全栈性能优化体系:
-
内置Fusion Engine (Spark Native Engine):
相对开源版本性能提升5倍,显著加速大数据计算任务。通过向量化引擎和批量数据处理技术优化计算效率,同时减少内存占用,大幅提升整体性能。
-
内置企业级Celeborn(Remote Shuffle Service):
支持PB级Shuffle数据处理,大幅提高大Shuffle任务的稳定性和性能。计算节点无需配置大规格云盘,充分利用Spark的动态资源伸缩能力,降低存储成本,计算资源总成本最高下降30%。
-
自动化小文件合并机制
基于 Apache Paimon 的 LSM Compaction 机制,在写入过程中自动合并小文件;合并后自动更新元数据,确保下游无缝感知。
💡 价值:作业效率全面提升,平台进入高效稳定新阶段
通过上述关键技术落地,聚好看实现了数据作业性能的全方位提升:
-
通过应用全面的优化策略,聚好看核心业务指标产出时效性大幅提升:从原来的上午9点30分之前,提拉到了7点30分之前,提升了业务运营的时效。
-
查询性能显著增强:Serverless Spark在Fusion向量化引擎之外,还拓展了很多生产场景下得以应用的查询优化规则,提供了预读等IO优化,在聚好看实践中对比同等数据规模同样资源配置下可以带来30%的性能提升表现,部分任务有数倍的处理效率提升。
-
存储效率优化:小文件数量减少超 90%,NameNode 压力降低 65%,Spark 任务启动速度提升 2 倍;
-
零改造优化:向量化引擎 与 Celeborn 均为透明集成,业务无感升级,迁移成本极低;
七、总结
此次技术变革项目不仅是技术层面的迭代,更是一次面向未来的能力重塑。它标志着聚好看大数据平台正式迈入“一份数据、实时可见、多种计算、弹性高效”的新阶段,为用户画像实时更新、内容智能推荐等核心业务提供了强大支撑,也为后续 AI 大模型训练、终端智能体构建、跨场景智慧联动奠定了坚实的数据基础。
未来,阿里云将继续深化与聚好看的技术协同,助力聚好看探索湖仓一体、智能运维、数据安全治理等前沿方向,持续打造高可用、自进化、智能化的数据引擎,助力海信全场景智慧生态加速落地。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 5
5 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)