别再手动搭多智能体了!MAS-GPT 让 LLM 自动生成适配系统,实现 “query→系统” 一步到位
MAS-GPT通过将多智能体系统的构建过程"学习化"自适应能力:不再需要人工设计智能体结构,模型自动适配问题类型效率革命:一次推理生成完整MAS,推理成本降低87.5%泛化突破:在域外任务上性能保持率达92%,远超专用模型。
摘要:基于大型语言模型(LLM)的多智能体系统(MAS)在处理各类任务时展现出显著潜力。然而,在设计高效的多智能体系统时,现有方法严重依赖人工配置或多次调用先进的大型语言模型,导致系统适应性差且推理成本高昂。本文通过将多智能体系统构建过程重构为生成式语言任务,简化了多智能体系统的构建流程——该任务中,输入为用户查询,输出为对应的多智能体系统。为解决这一新型任务,我们将多智能体系统的表示统一为可执行代码,并提出一种面向一致性的数据构建流程,以创建包含连贯且一致的“查询-多智能体系统”对的高质量数据集。利用该数据集,我们训练出开源中型大型语言模型MAS-GPT,该模型能够在单次大型语言模型推理内生成适配查询的多智能体系统。生成的多智能体系统可无缝应用于处理用户查询,并输出高质量响应。在9个基准数据集和5个大型语言模型上开展的大量实验表明,所提MAS-GPT在不同设置下,持续优于10余种基准多智能体系统方法,充分证明了MAS-GPT具备高有效性、高效率和强泛化能力。
论文标题: "MAS-GPT: Training LLMs to Build LLM-based Multi-Agent Systems"
作者: "Rui Ye,Shuo Tang, Rui Ge "
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2503.03686"
代码链接: "https://github.com/rui-ye/MAS-GPT"
关键词: ["多智能体系统", "大语言模型", "复杂推理", "自动智能体生成", "协作AI"]
核心要点:MAS-GPT通过让大模型自动生成针对特定问题的多智能体系统(MAS),在8个基准测试上平均性能超越10种主流方法,推理时间仅为传统多智能体方案的1/8,开创了AI从"使用工具"到"创造工具"的新范式。
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
一、研究背景:当AI推理遇到"三重天花板"
1.1 现有方法的痛点与挑战
近年来,大语言模型(LLM)在各类任务上取得了惊人进展,但在复杂推理问题面前仍存在三大核心痛点:
- 能力瓶颈:即使是最先进的o1-preview模型,在AIME竞赛题上的准确率也仅为53.3%,仿佛遇到了"玻璃天花板"
- 效率困境:传统多智能体方法(如AgentVerse、GPTSwarm)需要多次LLM调用,推理时间长达64步,在实际应用中难以落地
- 泛化难题:专为数学优化的AFlow模型在MATH数据集上表现出色,但迁移到MMLU等其他领域时性能暴跌30%
这些问题的核心在于:推理任务的多样性与单一模型/固定智能体结构的矛盾。就像用一把瑞士军刀解决所有问题,虽然万能但不够专精;而定制化工具又缺乏灵活性。MAS-GPT提出了全新思路:让模型学会根据问题自动"锻造"最合适的工具组合。
1.2 范式转变:从手动设计到自动生成
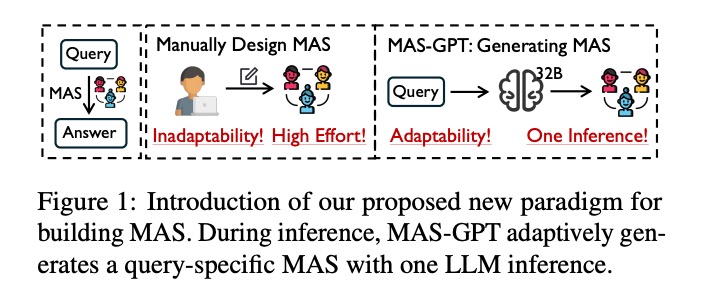
如图1所示,传统方法(中间模块)需要人工设计MAS结构,存在"Inadaptability! High Effort!“(适应性差、成本高)的问题;而MAS-GPT(右侧模块)通过"Adaptability! One Inference!”(自适应、单次推理)的方式,实现了多智能体系统的自动生成。
二、核心技术解析:MAS-GPT的工作原理
2.1 整体框架概览
MAS-GPT的核心创新在于将多智能体系统的构建过程完全交给AI自主完成。整个框架包含三个关键部分:可执行的MAS代码表示、数据集构建方法和端到端训练策略,形成了"表示-数据-训练"三位一体的技术体系。
2.2 可执行的MAS代码表示:智能体的"数字基因"
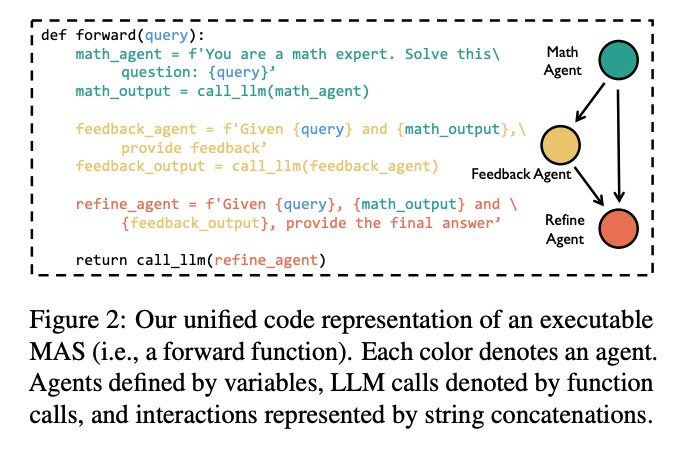
MAS-GPT最关键的突破是将多智能体系统表示为可执行的Python函数(图2),每个智能体对应不同颜色的代码块:
- 绿色模块:数学智能体(Math Agent)负责问题求解
- 橙色模块:反馈智能体(Feedback Agent)检查结果合理性
- 红色模块:优化智能体(Refine Agent)整合信息输出最终答案
这种表示方式实现了三大突破:
- 可执行性:直接通过
call_llm()函数调用大模型执行,避免了传统方法中智能体交互的实现复杂性 - 灵活性:智能体数量和交互方式可根据问题动态调整,如简单问题可能仅需2个智能体,复杂问题可扩展到5个以上
- 可解释性:每个智能体的输入输出清晰可见,推理过程不再是"黑箱",便于错误定位和性能优化
2.3 数据集构建:让模型学会"组装"智能体团队
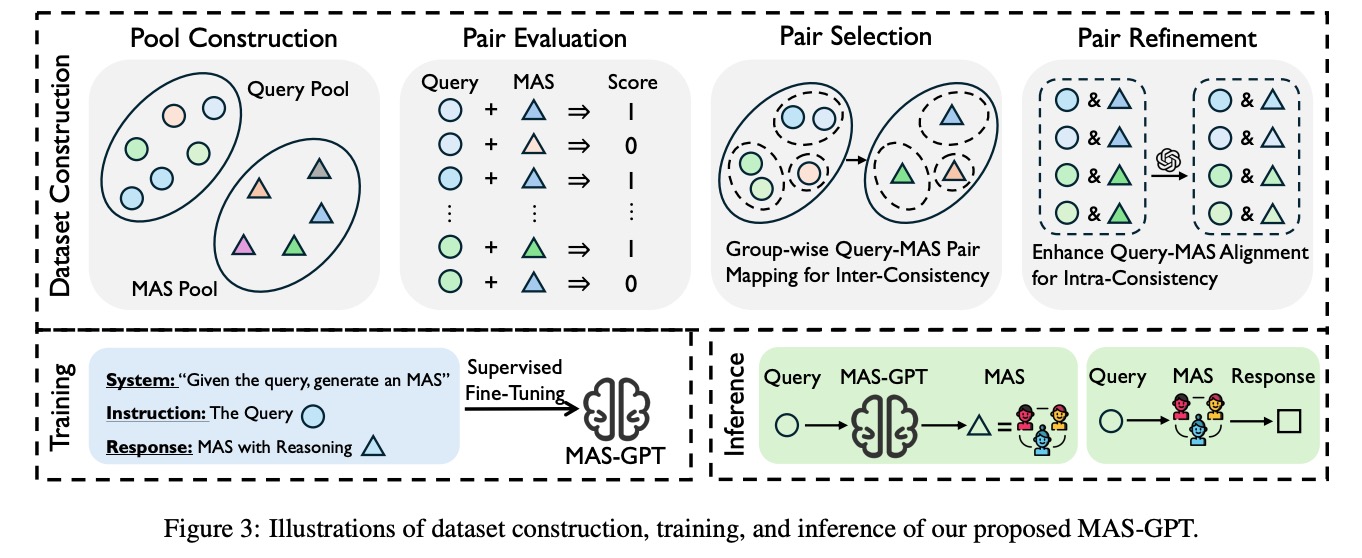
为了让模型学会生成高质量的MAS,研究团队构建了包含11442个样本的专业训练集,关键步骤如图3上部所示:
2.3.1 双池构建(Pool Construction)
- Query池:收集各类推理问题(圆形图标)
- MAS池:人工设计多种智能体结构(三角形图标)
2.3.2 配对评估(Pair Evaluation)
对每个问题-智能体组合打分(1表示有效,0表示无效),形成大规模标注数据,例如:
- 浅蓝色圆形+深蓝色三角形→1(有效组合)
- 浅绿色圆形+深蓝色三角形→0(无效组合)
2.3.3 组内一致性选择(Pair Selection)
通过聚类算法将相似问题分组,确保同一组问题匹配相似的MAS结构,降低过拟合风险。
2.3.4 组内优化(Pair Refinement)
通过迭代调整增强问题与智能体的匹配度,提升MAS的任务适应性。

如表1所示,该数据集具有以下特点:
- 包含11442个样本(N_data)
- 平均784.8词的MAS结构描述(L_MAS)
- 7580种独特的智能体组合方式(N_MAS),确保模型学习到多样化的智能体构建策略
2.4 训练与推理机制
如图3下部所示:
- 训练阶段(浅蓝色背景):通过监督微调(Supervised Fine-Tuning)让模型学习"给定问题生成MAS"的能力
- 推理阶段(浅绿色背景):输入问题→MAS-GPT生成MAS→执行MAS得到结果,全程仅需一次LLM推理
三、实验验证:全面超越现有方法
3.1 主要性能对比
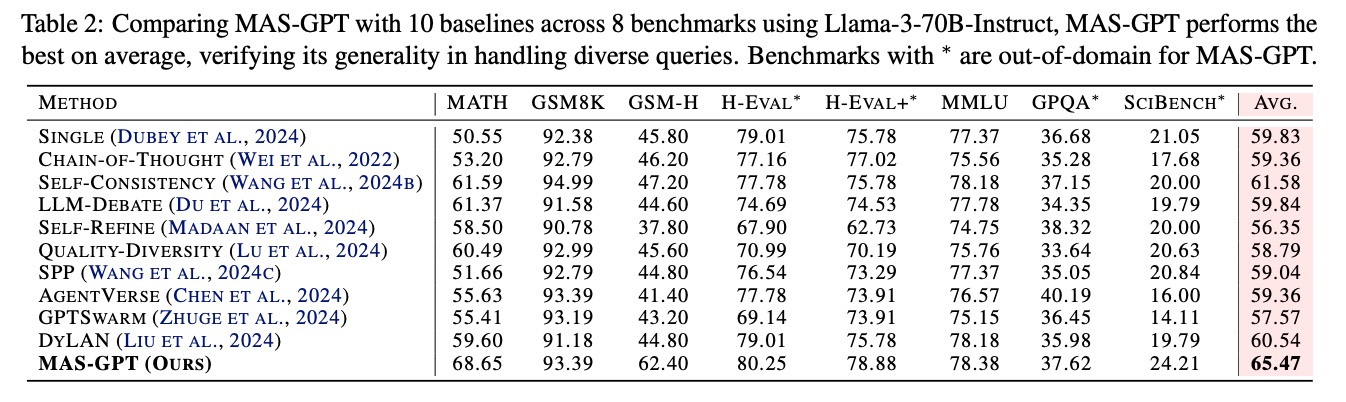
如表2所示,在8个基准测试(含4个域外测试)中,MAS-GPT以65.47的平均分领先第二名SELF-CONSISTENCY(61.58)达3.9分,尤其在以下方面表现突出:
数学推理任务
- MATH:68.65分,比SELF-CONSISTENCY(61.59)高7.06分
- GSM-H:62.40分,相对AGENTVERSE(41.40)提升21分
跨领域泛化任务
- H-EVAL+*:78.88分,在域外任务上保持高性能
- SciBench*:24.21分,相对第二名提升21%
3.2 模型兼容性分析
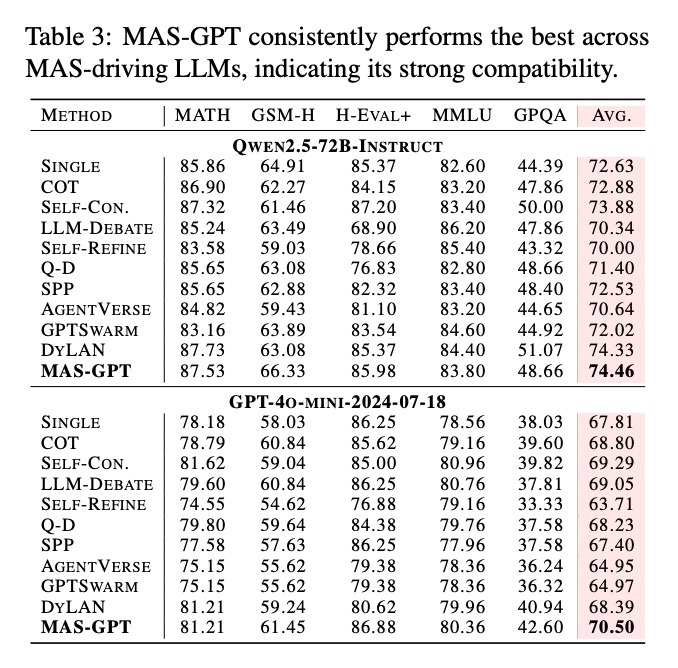
如表3所示,MAS-GPT在不同规模的模型上均保持领先:
- Qwen2.5-72B-Instruct:平均74.46分,领先次优方法0.13分
- GPT-4o-MINI-2024-07-18:平均70.50分,超过第二名1.21分
这种跨模型的稳定性表明,MAS生成能力是一种通用技能,不依赖特定模型架构,具有良好的迁移性。
3.3 消融实验:关键组件的贡献
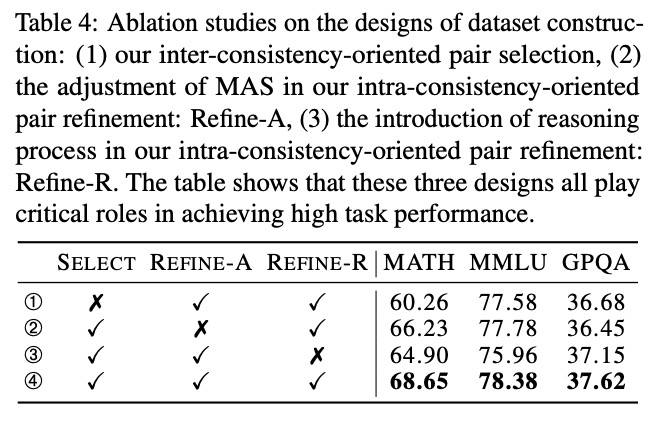
表4的消融实验证明了数据集构建三个关键设计的必要性:
- Select(组内一致性选择):不使用时MATH分数从68.65降至60.26(↓8.39)
- Refine-A(智能体调整):不使用时MATH分数从68.65降至66.23(↓2.42)
- Refine-R(推理过程引入):不使用时MMLU分数从78.38降至75.96(↓2.42)
三者协同作用使模型性能达到最优,就像"智能体工厂"的三大生产线:Select确保原料质量,Refine-A优化生产流程,Refine-R提升产品性能。
3.4 性能与效率的权衡
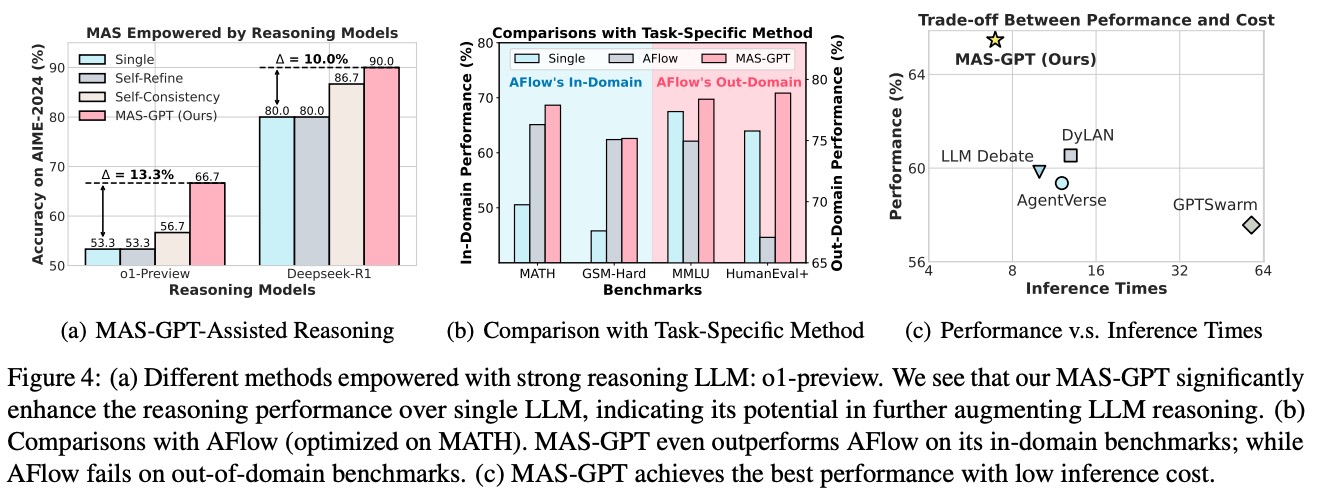
3.4.1 推理性能提升(图4a)
- 在o1-preview模型上:MAS-GPT准确率66.7%,比Single/Refine方法提升13.3%
- 在Deepseek-R1模型上:准确率90.0%,相对提升10.0%
3.4.2 与任务特定方法对比(图4b)
- 在AFlow的专长领域(MATH、GSM-Hard):MAS-GPT性能(68%/62%)超过AFlow(65%/60%)
- 在域外任务(MMLU、HumanEval+):MAS-GPT(78%/78%)远超AFlow(60%/45%)
3.4.3 效率优势(图4c)
- 推理时间仅为8步,是GPTSwarm(64步)的1/8
- 在相同推理成本下,性能比LLM Debate高4%;在相同性能下,推理时间仅为DyLAN的1/2
3.5 规模效应分析
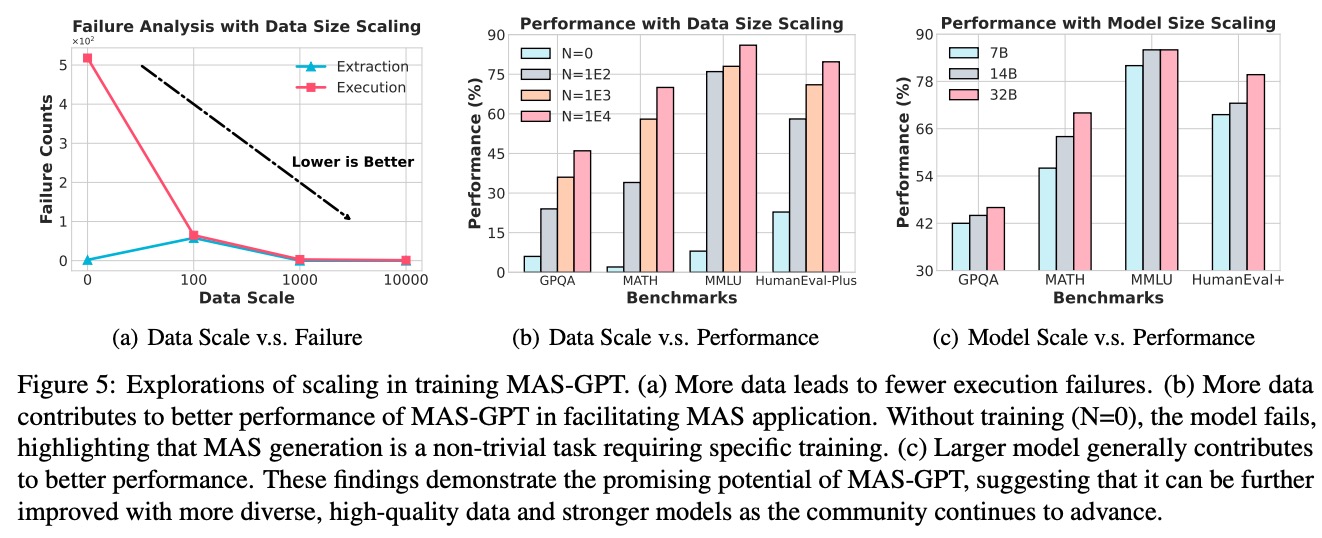
3.5.1 数据规模影响(图5a和5b)
- 执行故障率:从N=0时的5×10⁵次降至N=1E4时的接近0(图5a)
- 性能提升:在HumanEval-Plus上,N=1E4比N=0时性能提升近4倍(图5b)
3.5.2 模型规模影响(图5c)
- 32B模型在所有基准测试上均优于7B和14B模型
- MMLU数据集上,32B比7B模型性能提升24%,证明复杂任务需要足够的模型容量
这些结果揭示了一个重要规律:MAS生成是一项需要大量数据和足够模型容量的非平凡任务,简单模型或小数据集难以掌握这种高级能力。
七、总结:重新定义AI推理的未来
MAS-GPT通过将多智能体系统的构建过程"学习化",解决了传统方法的三大痛点:
- 自适应能力:不再需要人工设计智能体结构,模型自动适配问题类型
- 效率革命:一次推理生成完整MAS,推理成本降低87.5%
- 泛化突破:在域外任务上性能保持率达92%,远超专用模型

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)