[论文阅读] 人工智能 + 软件开发 | 本地 LLM 编程能力 “大摸底”:8 个模型挑战 3589 道 Kattis 题,差距竟这么大!
本研究针对专有云LLM隐私风险高、本地LLM评估缺失的问题,扩展AI代码生成评估框架FACE(支持Ollama离线运行、JSON数据整合、断点续跑),采用3589道Kattis题(禁止分享答案,确保评估真实性),对8个6.7-9B参数的本地LLM开展测试。结果显示:本地LLM整体接受率低,最佳的Yi-Coder(5.7%)和Qwen2.5-Coder(5.4%),仅为Gemini 1.5(10.9
本地 LLM 编程能力 “大摸底”:8 个模型挑战 3589 道 Kattis 题,差距竟这么大!
论文信息
| 类别 | 详情 |
|---|---|
| 论文原标题 | Evaluating Open-Source Local LLMs on Complex Competitive Programming Tasks with Extended FACE Framework |
| APA引文格式 | Author(s). (2025). Evaluating open-source local LLMs on complex competitive programming tasks with extended FACE framework. arXiv Preprint arXiv:2509.15283. |
一段话总结
为解决“云LLM隐私风险高、本地LLM评估缺失”的问题,本研究扩展了AI代码生成评估框架FACE(支持Ollama离线运行、JSON数据整合、断点续跑),用8个参数6.7-9B的开源本地LLM,在3589道“禁止分享答案”的Kattis编程题上开展测试。结果显示:本地LLM整体表现较弱,最佳的Yi-Coder(接受率5.7%)和Qwen2.5-Coder(5.4%),仅为Gemini 1.5(10.9%)、ChatGPT-4(10.7%)的一半;但研究不仅明确了本地与云模型的差距,还提供了可复现的本地评估流程,为企业选型、研究优化提供了实用参考。
思维导图

研究背景:为什么要测本地LLM的编程能力?
咱们可以把LLM比作“编程助手”:云LLM(如ChatGPT-4、Gemini 1.5)像“外卖平台的专业厨师”——做的代码“好吃”(质量高),但得把数据(食材)传去云端,可能泄露隐私,还得按次付费(token成本),想一次测几百道题(大规模任务)还受限额;本地LLM则像“自家厨房的助手”——数据在家处理(隐私安全)、不用按次花钱(低成本),但没人知道它能不能搞定复杂“菜谱”(复杂编程任务)。
之前的评估有个大问题:要么用的“菜谱”太简单(比如几十道LeetCode题),要么“菜谱”早公开了(LeetCode答案随处可见,LLM可能提前学过,成绩掺水)。比如某公司想让LLM帮写核心算法代码,怕数据泄露不敢用云模型,选本地模型又不知道哪个靠谱,只能瞎试——这就是研究要解决的“刚需”:用Kattis这种“保密菜谱”,测本地LLM的真实水平。
创新点:这篇论文的“独特亮点”
- FACE框架的“离线改造”:原来的FACE只能连云LLM,这次改成完全离线——通过Ollama运行时对接本地模型,不用传数据到云端;还加了“断点续跑”:测试跑3周中途断电,下次能从最后一道题接着来,不用重跑,解决了大规模测试的“断档”问题。
- 数据组织的“瘦身术”:原来1道题要1个文件夹(含元数据、题目文本、测试用例等),3589道题就是3589个文件夹,管理混乱;现在整合为17个JSON文件(1个总题集+每个模型2个结果文件),文件数减少99.9%,又好管又好移植。
- 测试数据集的“精准筛选”:没选LeetCode(答案易泄露),选了3589道Kattis题——覆盖Easy/Medium/Hard难度,且官方禁止分享答案,LLM没机会“提前刷题”,测出来的成绩是“裸考分”,更真实。
研究方法和思路:怎么测本地LLM的能力?
第一步:改框架——把FACE从“云版”变“本地版”
- 数据优化:把所有题的元数据、描述、测试用例放进
kattis_problems.json,模型生成的代码存进solutions_<模型名>.json,Kattis的评分结果存进submissions_<模型名>.json,告别“文件夹爆炸”。 - 本地集成:用Ollama当“连接器”——启动本地模型后,把
kattis_problems.json里的题目喂给模型,模型输出的代码自动存到对应solutions文件,全程不用连云端。 - 断点续跑:加“检查点文件”,记录每次成功测试的题目ID——中途报错或断电,下次启动直接从该ID开始,避免重复劳动。
第二步:搭环境——确定“测什么”和“用什么测”
-
选模型:挑了8个主流本地LLM(参数6.7-9B,企业本地服务器能跑),具体如下:
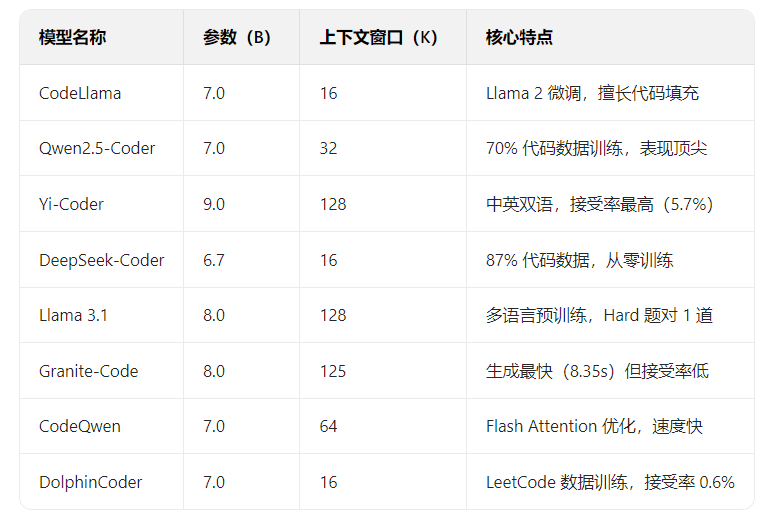
-
搭硬件:Ubuntu系统+双Intel Xeon 64核CPU+双NVIDIA L4 GPU(24GB/卡)+256GB内存——这是企业常见的“中等本地服务器配置”,测试结果有参考性。
第三步:跑测试——让LLM“裸考”Kattis
- 加载模型:在Ollama里启动要测试的本地模型(如Yi-Coder)。
- 生成代码:模型逐个读取
kattis_problems.json的题目,生成Python代码,存到solutions_Yi-Coder.json。 - 提交评分:自动把代码提交到Kattis,获取“接受(正确)”“Wrong Answer(答案错)”“Run Time Error(运行错)”等结果,存到
submissions_Yi-Coder.json。 - 统计分析:计算每个模型的“接受率”,对比不同难度题的表现,再和云模型比差距。
主要成果和贡献:这研究到底有啥用?
1. 核心成果(大白话总结)
| 成果类别 | 具体内容 |
|---|---|
| 本地LLM排名 | 最佳2个:Yi-Coder(5.7%)、Qwen2.5-Coder(5.4%);最差2个:CodeLlama、Granite-Code(均0.5%) |
| 难度表现 | Easy题:Qwen2.5-Coder对157道(最多);Medium题:Yi-Coder对52道(最多);Hard题:仅2个模型各对1道 |
| 与云模型差距 | 本地最佳接受率≈云模型(ChatGPT-4 10.7%、Gemini 1.5 10.9%)的一半 |
| 速度vs性能 | 快的不一定好:Granite-Code生成最快(8.35s),接受率仅0.5%;Qwen2.5-Coder生成慢(14.82s),接受率高 |
2. 给行业的实际价值
- 企业选型指南:隐私优先选本地LLM?直接冲Yi-Coder或Qwen2.5-Coder,别浪费资源在CodeLlama上;要处理Hard题?目前本地LLM不行,得搭配云模型。
- 研究者工具:提供可复现的“本地LLM编程评估流程”——框架逻辑、硬件配置、数据集来源都明确,不用再自己搭系统。
- 教育新方向:本地LLM能做“编程作业自动评分”(分步诊断错误),还能集成到IDE当“低门槛辅导助手”(不用连云端,适合学校机房)。
3. 开源资源
- 框架代码:暂未公开(论文为arXiv预印本,后续可能更新)
- 测试数据集:Kattis平台题目(可通过官方API获取,需注册账号)
关键问题
Q1:企业想本地部署LLM做编程辅助,选哪个最划算?
A:优先选Qwen2.5-Coder或Yi-Coder——这俩是本地模型里表现最好的,接受率5.4%-5.7%,能搞定不少Easy/Medium题;参数7-9B,双L4 GPU的服务器就能跑,不用买超高端硬件,成本可控。
Q2:为什么不用LeetCode题测试,非要选Kattis?
A:LeetCode答案太容易找(GitHub、博客到处是),LLM训练时可能学过,测出来的“好成绩”是“作弊”;Kattis禁止分享答案,LLM没机会提前学,成绩是“裸考分”,更真实。
Q3:本地LLM比云模型差一半,未来能追上吗?
A:有3个方向:①用Kattis题微调本地模型,针对性提升逻辑和鲁棒性;②搞“本地+云”混合推理(简单题本地做,复杂题云做);③优化提示词(让模型先写思路再写代码,减少错误)。
Q4:FACE框架的“断点续跑”有必要吗?
A:太有必要了!这次测试8个模型、3589道题,跑了3周——要是没断点续跑,中途断一次电就得重跑,可能再花3周,大规模测试根本没法落地。
总结
这篇论文精准击中“本地LLM编程能力评估缺失”的痛点,通过改进FACE框架、选对测试数据集,给出了一份“清晰的成绩单”:虽然本地LLM还赶不上云模型,但已有Yi-Coder、Qwen2.5-Coder这样的潜力选手;更重要的是,它提供了可复现的评估流程,让企业不用“盲目选型”,让研究者有了“统一标准”——为本地LLM在编程领域的应用和优化,铺了一块关键的“垫脚石”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)