Datawhale 算法笔记 AI硬件与机器人大模型 (二)
从一张普通的二维图片算出图像里各个物体的相对远近关系。难点在于二维图片是对三维的投影,很多深度信息丢失了。因为最后一层包含了最终决策的最丰富、最高级的语义信息。浅层卷积提取的是边缘、颜色、纹理等局部低级特征。深层卷积将低级特征组合成了高级概念,比如眼睛,车轮等,能反应模型基于哪些部件进行的决策。
主题:
- 视觉感知与手眼协调(见一)
- 计算机视觉在机器人中应用(见一)
- 手眼标定算法实现(见一)
- 深度估计与3D重建
具身智能场景的计算机视觉
教程第一节在讲SAM,以下将通过QA的形式做笔记
SAM是什么,与传统的分割模型有何不同?
SAM是一个通用的可提示的分割模型,传统的分割模型是能针对专门的类别分割的很好,比如车子猫,但是面对其它物体可能就分不清楚。而SAM可以根据物体在哪的少量提示进行分割,提示可以是点,框。

SAM的组成?

图像编码器:用vit,提取特征,得到包含空间和语义信息的特征(embeddings)
提示编码器 (Prompt Encoder): 把用户提示的点和框转换成特征嵌入
掩码解码器:使用图像特征和提示特征进行分割,可毫秒级输出
单目深度估计
什么是单目深度估计?难点是什么?
从一张普通的二维图片算出图像里各个物体的相对远近关系。难点在于二维图片是对三维的投影,很多深度信息丢失了。
AI 是如何从一张 2D 照片中计算深度的?它利用了哪些视觉线索?
其实一张图片也得不到绝对的深度信息,比如物体距离相机的距离。只能看相对大小。
因为模型不知道一个物体的“小而近” 还是“大而远的”。比如一张玩具房子和一个真实大房子在视觉上是完全一样的。如果想知道绝对深度,需要额外的尺度信息,或者要靠立体相机,雷达等。
可利用的线索是:
相对大小:同类问题,越小离的越远
遮挡:A挡住了B,那么A比B更靠近相机
纹理:远处的(如砖墙)的表面纹理会更密,相比于近处
线性透视: 平行的线条在远处会汇聚到一点
光影和阴影:物体和影子可以反映物体的形状和相对位置
有哪些可以做深度估计的模型?
Dense Prediction Transformer(DPT)
核心架构: 它是一种采用编码器-解码器架构的深度学习模型。
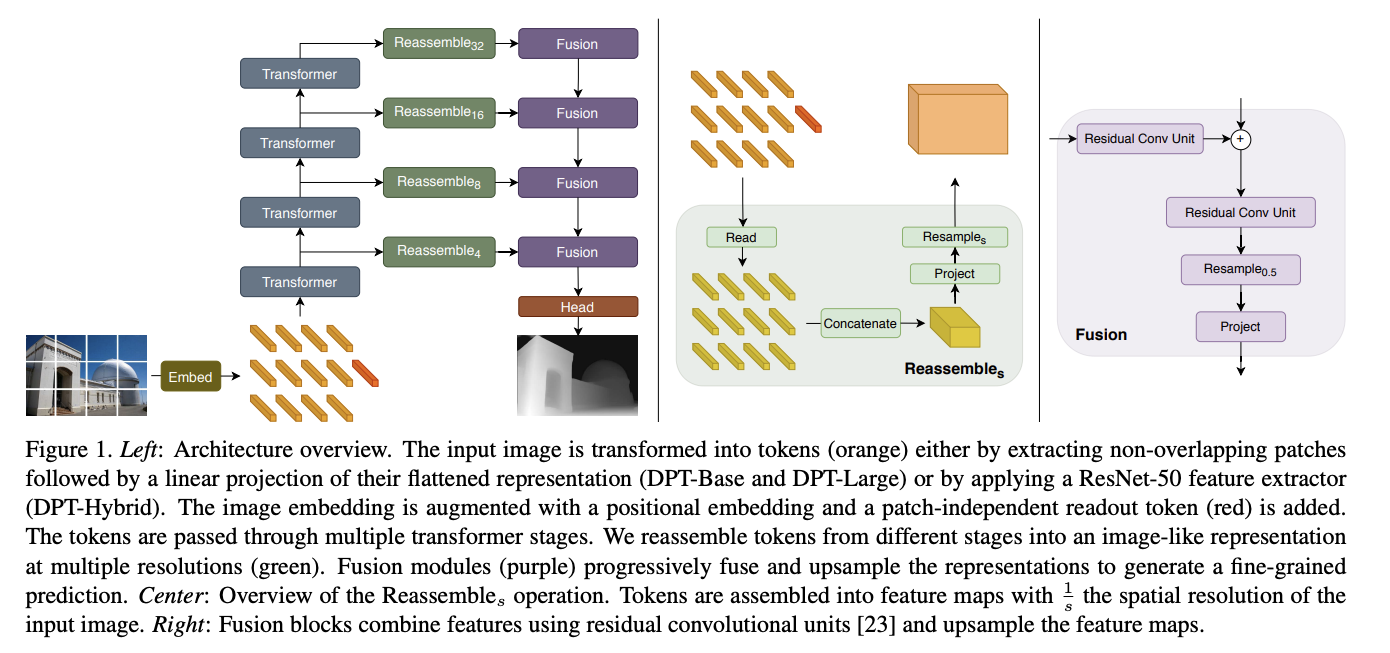
独特优势: 它的编码器采用了 ViT。相比于传统的卷积网络,ViT 更擅长捕捉图像中的全局依赖关系(例如整个场景的透视结构),能对远处的物体做出更准确的深度判断,在深度估计任务上表现非常出色。
随后使用MHSA处理经过Vit 编码器的token,然后送入卷积解码器。使用多尺度的特征进行密集预测。
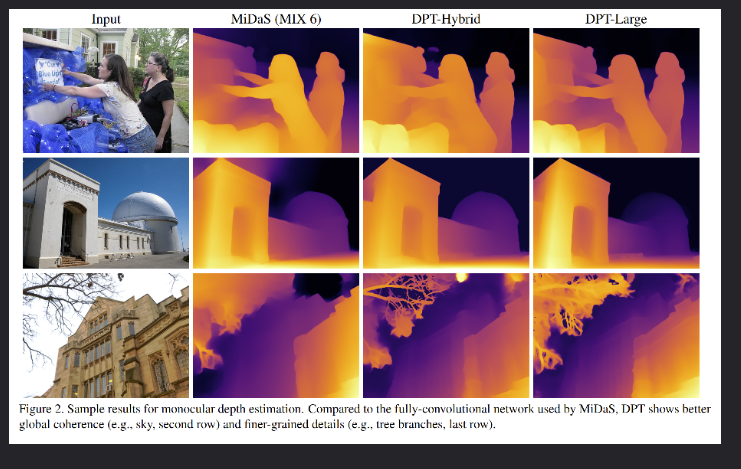
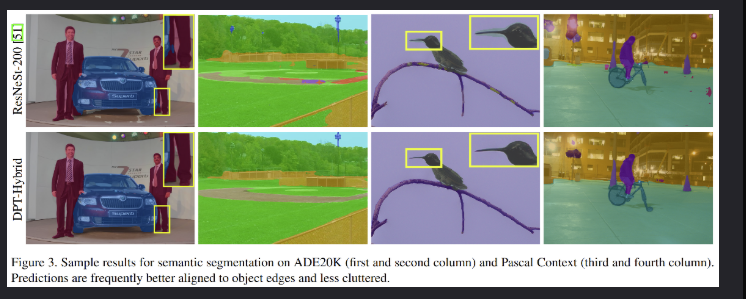
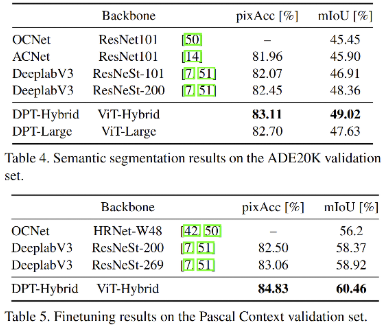
在深度估计和分割任务上都取得了当时的sota
注意力热图
注意力热图和YOLO输出画出的“热力图”的区别是什么?
yolo的热力图是回答模型在哪里找到了什么,显示模型判断物体存在的位置和给出的置信度分数。是检测结果的可视化。
注意力热图(类激活图,Grad-CAM)回答的是模型为什么认为这里是某个物体,显示了为了做一个特定的分类决策,比如从图像中分割出猫猫(对图片像素进行判断,哪些像素对这个决策贡献最大)
Grad-CAM是如何“计算”出模型的“注意力焦点”的?
梯度。Grad-CAM 中使用的梯度,不是我们在模型训练过程中用来更新网络权重的那个梯度。
在Grad-CAM中,模型是已经训练好且冻结的,不会去更新它的权重。计算的是最终某个类别(比如“猫”)的预测分数,相对于中间层特征图(Feature Map)中每一个像素的梯度。这个梯度含义是“这张特征图上的这个像素,对于最终‘这是一只猫’这个决策的贡献有多大?”
具体计算过程
-
输入与前向传播: 将一张含有猫的图片输入模型,模型进行一次完整的前向传播。在网络的末端,模型会输出一个分数向量,比如
[0.01 (狗), 0.98 (猫), 0.01 (鸟)]。选择想解释的那个类别,即“猫”,并记下它在Softmax层之前的原始分数(logit),称之为 Sc(c代表猫这个类别)。 -
选择目标层: 选择一个卷积层进行分析,通常是最后一个卷积层,因为它包含了最高级的语义信息。假设这个卷积层输出了N个特征图,我们把其中第k个特征图记为 Ak。
-
计算“归因梯度”: 现在到了最关键的一步。进行一次特殊的反向传播。我们计算目标分数 Sc 相对于特征图 Ak 中每一个像素 (i,j) 的梯度。
这个梯度的数学表达是:∂Sc/∂Ak ij
-
这个梯度的直观含义:“如果我们稍微增加第k个特征图在(i, j)位置的像素值,那么模型最终预测为‘猫’的分数 Sc 会增加多少?”如果这个梯度值很大且为正,说明 Ak 在 (i,j) 位置的激活值对“这是一只猫”的判断起到了强烈的积极作用。如果梯度值为负,说明这个激活值反而抑制了“猫”这个判断。如果梯度值为0,说明这个激活值对判断“猫”没什么影响。
-
Grad-CAM 接下来对每个特征图 Ak 上的所有梯度值求一个全局平均,得到一个单一的权重 αk。这个 αk 代表了整个第k个特征图对于“猫”这个决策的总体重要性。
-
最后用这些重要性权重 αk 去加权求和所有的特征图 Ak,就得到了最终的注意力热图。
为什么Grad-CAM通常选择最后一个卷积层来生成热图?
因为最后一层包含了最终决策的最丰富、最高级的语义信息。
浅层卷积提取的是边缘、颜色、纹理等局部低级特征。
深层卷积将低级特征组合成了高级概念,比如眼睛,车轮等,能反应模型基于哪些部件进行的决策。
YOLO系列分析
YOLO v1到v10的演进,最主要的几个发展阶段是什么?
-
奠基与成熟(v1-v3):从0到1,开创了单阶段检测的范式,并逐步引入Anchor Box、多尺度预测等关键技术,使之成为一个经典、可靠的模型。
-
集大成与工程化(v4-v5):v4像一个“学术集大成者”,整合了当时所有有效的技术。v5则开启了“工程化”时代,凭借其易用性、灵活性和出色的部署支持,成为应用最广泛的版本。
-
架构革新(v6-v8):开始探索无锚框(Anchor-Free)设计,简化了训练流程,并最终由v8统一了检测、分割、姿态估计等多个任务,成为新的行业基准。
-
追求极致性能与端到端(v9-v10):v9从信息论角度优化网络结构,解决信息瓶颈问题。v10则实现了革命性的突破,通过去除NMS,打造了真正的端到端实时检测模型,将延迟降到了新的水平。
YOLOv10的核心创新是什么?
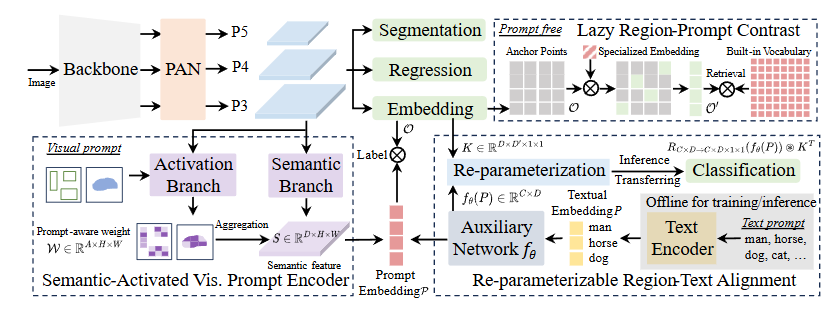
YOLOv10的核心目标是在保持高精度的同时,实现极致的端到端实时性能。为了达到这个目标,它解决的最大痛点是消除了对NMS(非极大值抑制)这个后处理步骤的依赖。
NMS主要有两个痛点:
-
增加计算开销:NMS本身是一个独立的算法,需要在模型推理结束后额外运行,这会增加整个检测流程的延迟。
-
破坏端到端特性:因为它是一个独立的后处理模块,导致整个检测流程不是一个从输入到输出一步到位的“端到端”系统。这使得模型的部署、优化和训练变得更加复杂。
YOLOv10通过在训练阶段模型筛选出最佳检测框,从而在推理时无需NMS。其“一致性双重分配”策略运作如下(有点像DETR的匈牙利匹配算法):
-
双重分配:在训练时,模型内部有两个并行的“分支”来处理同一个物体。
-
一对一匹配分支:这个分支被严格要求,对于一个真实物体,只能生成一个最精准的预测框。它的目标是追求最高的检测精度。
-
一对多匹配分支:这个分支像传统的YOLO一样,会生成多个预测框。它的目标是提供更丰富的监督信号,帮助模型训练。
-
-
一致性监督:模型被额外训练,以确保“一对一”分支产出的那个最佳预测框,必须和“一对多”分支里得分最高的那个预测框保持一致。
通过这种“惩罚和奖励同时进行”式的训练,模型自己就学会了从众多可能的预测框中选出那个唯一的,所以在推理时只会输出那个高质量的框,就不再需要NMS来做“海选”了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)