强化学习基础入门(PPO, GRPO)
近端策略优化(PPO)是OpenAI于2017年提出的强化学习算法,以实现简单、样本效率高、训练稳定著称。PPO通过限制新策略与旧策略的差异,解决策略梯度算法中步长难以选择的问题。其核心创新是裁剪目标函数,利用概率比和优势函数,确保策略更新幅度在可控范围内。PPO训练过程分为采样和优化两阶段,结合价值网络和熵奖励机制,实现稳定高效的策略优化。这一方法有效避免了策略崩溃,成为强化学习领域最受欢迎的算
PPO
近端策略优化(Proximal Policy Optimization, PPO)。
PPO由OpenAI在2017年提出,它迅速成为强化学习领域最受欢迎、最常用的算法之一,因其在实现简单、样本效率高、训练稳定等方面的优异平衡而著称。
1. PPO 的核心思想
在介绍PPO之前,首先要理解它要解决的核心问题:策略梯度算法中步长(Learning Rate)难以选择的问题。
- 步长太小:收敛速度极慢,需要大量样本和环境交互,训练成本高。
- 步长太大:策略更新容易失控,一次糟糕的更新可能会严重降低策略性能(即策略崩溃,Policy Collapse),且由于数据是由当前策略收集的,策略变差后后续采集的数据质量也会下降,导致训练难以恢复,越练越差。
PPO的目标很明确:在每一步更新时,试图找到一个性能更好的新策略,同时确保新策略不会偏离旧策略太远,从而保证更新的稳定性。
2. 数学原理
PPO的数学基础主要建立在策略梯度(Policy Gradient) 和重要性采样(Importance Sampling) 之上。
2.1 策略目标函数
策略梯度算法的目标是最大化一个目标函数 J ( θ ) J(\theta) J(θ),即期望累积奖励。
传统的策略梯度(如REINFORCE算法)的梯度计算公式为:
∇ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) ⋅ G t ] \nabla J(\theta) = \mathbb{E}_{\tau \sim \pi_{\theta}} \left[ \sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t | s_t) \cdot G_t \right] ∇J(θ)=Eτ∼πθ[t=0∑T∇θlogπθ(at∣st)⋅Gt]
其中 G t G_t Gt 是时间步 t t t 之后的累积回报。
2.2 重要性采样(Importance Sampling)
重要性采样是一种用一个已知的、容易采样的分布( q ( x ) q(x) q(x))去估计另一个分布( p ( x ) p(x) p(x))的期望值的方法。
E x ∼ p [ f ( x ) ] = E x ∼ q [ p ( x ) q ( x ) f ( x ) ] \mathbb{E}_{x \sim p}[f(x)] = \mathbb{E}_{x \sim q} \left[ \frac{p(x)}{q(x)} f(x) \right] Ex∼p[f(x)]=Ex∼q[q(x)p(x)f(x)]
在PPO中:
- p ( x ) p(x) p(x) 是旧策略(Old Policy) π θ o l d \pi_{\theta_{old}} πθold,我们用这个策略与环境交互收集了大量数据。
- q ( x ) q(x) q(x) 是新策略(New Policy) π θ \pi_{\theta} πθ,我们希望通过这些数据来更新它。
- f ( x ) f(x) f(x) 可以理解为优势(Advantage) A t A_t At,衡量在状态 s t s_t st 下采取动作 a t a_t at 比平均情况好多少。
因此,新策略的目标函数可以用旧策略收集的数据来构建:
J θ o l d ( θ ) = E ( s t , a t ) ∼ π θ o l d [ π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) ⋅ A θ o l d ( s t , a t ) ] J^{\theta_{old}}(\theta) = \mathbb{E}_{(s_t, a_t) \sim \pi_{\theta_{old}}} \left[ \frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{old}}(a_t | s_t)} \cdot A^{\theta_{old}}(s_t, a_t) \right] Jθold(θ)=E(st,at)∼πθold[πθold(at∣st)πθ(at∣st)⋅Aθold(st,at)]
其中 π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) \frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{old}}(a_t | s_t)} πθold(at∣st)πθ(at∣st) 就是重要性权重(Importance Weight)。
我们希望最大化这个目标函数,但直接最大化它会导致新策略相对旧策略变化过大,因为重要性权重可能会变得非常大(尤其是当新策略更倾向于某个动作而旧策略很少选择它时)。
2.3 核心创新:Clipped Surrogate Objective
PPO的核心贡献是提出了一个裁剪(Clipping) 的替代目标函数,来强制约束新策略和旧策略的差异。
我们定义概率比(Probability Ratio):
r t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) r_t(\theta) = \frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{old}}(a_t | s_t)} rt(θ)=πθold(at∣st)πθ(at∣st)
那么原始的目标就变成了 J = E [ r t ( θ ) ⋅ A t ] J = \mathbb{E} [ r_t(\theta) \cdot A_t ] J=E[rt(θ)⋅At]。
如果优势 A t A_t At 是正的(这是一个好动作),我们鼓励这个动作,增加 π θ ( a t ∣ s t ) \pi_\theta(a_t | s_t) πθ(at∣st),从而使 r t r_t rt 变大。
如果优势 A t A_t At 是负的(这是一个坏动作),我们抑制这个动作,减少 π θ ( a t ∣ s t ) \pi_\theta(a_t | s_t) πθ(at∣st),从而使 r t r_t rt 变小。
但如果不加约束, r t r_t rt 可能会变得无限大或无限小。PPO通过裁剪来限制 r t r_t rt 的变化范围。其裁剪后的目标函数为:
J C L I P ( θ ) = E [ min ( r t ( θ ) A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) ] J^{CLIP}(\theta) = \mathbb{E} \left[ \min( r_t(\theta) A_t, \operatorname{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) A_t ) \right] JCLIP(θ)=E[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
其中:
- ϵ \epsilon ϵ 是一个超参数(如0.2),定义了裁剪的范围,即新策略与旧策略的最大差异幅度。
- clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) \operatorname{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) clip(rt(θ),1−ϵ,1+ϵ) 函数将 r t r_t rt 限制在 [ 1 − ϵ , 1 + ϵ ] [1-\epsilon, 1+\epsilon] [1−ϵ,1+ϵ] 之间。
这个 min 操作的设计非常巧妙,它起到了悲观估计(Pessimistic Estimate) 的作用:
-
当优势 A t > 0 A_t > 0 At>0(好动作)时:
- 目标函数的第一项是 r t A t r_t A_t rtAt。
- 第二项是 clip ( r t , 1 − ϵ , 1 + ϵ ) A t \operatorname{clip}(r_t, 1-\epsilon, 1+\epsilon) A_t clip(rt,1−ϵ,1+ϵ)At,它不会让 r t r_t rt 超过 1 + ϵ 1+\epsilon 1+ϵ。
min操作会取两者中较小的那个。这意味着即使这个动作非常好,我们更新策略时对其的鼓励也是有限度的(最多使概率变为原来的 1 + ϵ 1+\epsilon 1+ϵ 倍),防止它“暴增”。
-
当优势 A t < 0 A_t < 0 At<0(坏动作)时:
- 第一项 r t A t r_t A_t rtAt 是负数(因为 A t < 0 A_t<0 At<0)。
- 第二项 clip ( r t , 1 − ϵ , 1 + ϵ ) A t \operatorname{clip}(r_t, 1-\epsilon, 1+\epsilon) A_t clip(rt,1−ϵ,1+ϵ)At 也是负数,但它不会让 r t r_t rt 低于 1 − ϵ 1-\epsilon 1−ϵ。
min操作会取两者中较小的那个(即负得更多的那个)。这意味着我们对坏动作的惩罚也是有限度的(最多使概率变为原来的 1 − ϵ 1-\epsilon 1−ϵ 倍),防止它“暴减”。
通过这个裁剪机制,PPO有效地避免了策略的剧烈变化,保证了训练的稳定性。
3. 训练过程
PPO的训练过程是一个循环迭代的过程,通常包含采样(Sampling) 和优化(Optimization) 两个阶段。
-
初始化:
- 随机初始化策略网络(Actor) π θ \pi_\theta πθ 和价值网络(Critic) V ϕ V_\phi Vϕ。
- 初始化旧策略 π θ o l d \pi_{\theta_{old}} πθold(通常就是当前策略的参数副本)。
-
循环迭代(for each iteration):
a. 采样阶段(并行):
- 使用当前的旧策略 π θ o l d \pi_{\theta_{old}} πθold 与环境的多个副本(并行)进行交互,收集大量轨迹(Trajectories)数据 { ( s t , a t , r t , s t + 1 ) } \{ (s_t, a_t, r_t, s_{t+1}) \} {(st,at,rt,st+1)}。
- 对于每个时间步,计算其优势(Advantage)估计值 A t ^ \hat{A_t} At^ 和回报(Return) R t ^ \hat{R_t} Rt^。
- 回报 R t ^ \hat{R_t} Rt^:通常使用折扣累积回报, R t ^ = ∑ k = 0 ∞ γ k r t + k \hat{R_t} = \sum_{k=0}^{\infty} \gamma^k r_{t+k} Rt^=∑k=0∞γkrt+k。
- 优势 A t ^ \hat{A_t} At^:衡量动作的好坏。常用GAE(Generalized Advantage Estimation) 方法进行估计,它平衡了偏差和方差,效果很好。公式涉及价值函数 V ( s ) V(s) V(s) 和时序差分误差(TD-error), A t ^ = δ t + ( γ λ ) δ t + 1 + ( γ λ ) 2 δ t + 2 + . . . \hat{A_t} = \delta_t + (\gamma\lambda)\delta_{t+1} + (\gamma\lambda)^2\delta_{t+2} + ... At^=δt+(γλ)δt+1+(γλ)2δt+2+...,其中 δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st)。
- 将收集到的数据(状态、动作、奖励、优势、回报)存入一个经验回放缓冲区(Buffer)。注意:这个阶段的数据是用旧的、固定的策略 π θ o l d \pi_{\theta_{old}} πθold 收集的。
b. 优化阶段(多次 epochs):
- 从缓冲区中随机抽取小批量(Minibatch) 数据。
- 更新价值网络(Critic):
- 目标:让价值网络 V ϕ ( s ) V_\phi(s) Vϕ(s) 的预测更准确。
- 损失函数通常采用均方误差(MSE): L V F ( ϕ ) = 1 2 ( V ϕ ( s t ) − R t ^ ) 2 L^{VF}(\phi) = \frac{1}{2} (V_\phi(s_t) - \hat{R_t})^2 LVF(ϕ)=21(Vϕ(st)−Rt^)2。即让价值网络的预测值 V ϕ ( s t ) V_\phi(s_t) Vϕ(st) 尽可能接近实际计算出的回报 R t ^ \hat{R_t} Rt^。
- 更新策略网络(Actor):
- 目标:最大化 PPO 的裁剪目标函数 J C L I P ( θ ) J^{CLIP}(\theta) JCLIP(θ)。
- 损失函数是负的目标函数(因为优化器通常最小化损失): L P G ( θ ) = − J C L I P ( θ ) L^{PG}(\theta) = - J^{CLIP}(\theta) LPG(θ)=−JCLIP(θ)。
- 通常还会在总损失函数中加入一个熵奖励(Entropy Bonus)项 S S S:
- 目的是鼓励探索,防止策略过早地收敛到一个局部最优解。熵值高代表策略更随机,探索性更强。
- 因此,总的损失函数通常是三项的加权和:
L T O T A L ( θ , ϕ ) = L P G ( θ ) + c 1 L V F ( ϕ ) − c 2 S [ π θ ] ( s t ) L^{TOTAL}(\theta, \phi) = L^{PG}(\theta) + c_1 L^{VF}(\phi) - c_2 S[\pi_\theta](s_t) LTOTAL(θ,ϕ)=LPG(θ)+c1LVF(ϕ)−c2S[πθ](st)
其中 c 1 c_1 c1 和 c 2 c_2 c2 是超参数。 - 用随机梯度下降(如Adam)对上述总损失进行多次(例如3-4次)优化更新(epochs)。关键点:我们用同一批旧策略收集的数据,进行多次更新,这大大提高了样本效率。
c. 更新旧策略:
- 一轮优化完成后,将旧策略的参数 θ o l d \theta_{old} θold 更新为当前策略的参数 θ \theta θ: θ o l d ← θ \theta_{old} \leftarrow \theta θold←θ。
- 清空缓冲区,回到步骤a,用更新后的新策略去与环境交互收集新的数据。
总结与优势
| 特性 | 描述 |
|---|---|
| 核心思想 | 在策略更新时,限制新策略与旧策略的差异,避免破坏性的巨大更新。 |
| 关键机制 | 裁剪(Clipping) 的重要性权重,悲观地限制策略更新的幅度。 |
| 训练方式 | 交替进行:1) 用旧策略采样;2) 用采样的数据对新策略进行多次小批量更新。 |
| 主要优势 | 1. 稳定:Clipping机制有效防止策略崩溃。 2. 样本效率高:一批数据可用来更新多次。 3. 易于实现:相比TRPO等算法,无需计算复杂的二阶导数,实现简单。 4. 通用性强:在多种任务(从离散到连续控制)上表现良好。 |
PPO通过其精巧的裁剪设计,成功地解决了策略梯度算法中的核心稳定性问题,使其成为实践中强化学习项目的首选算法之一。
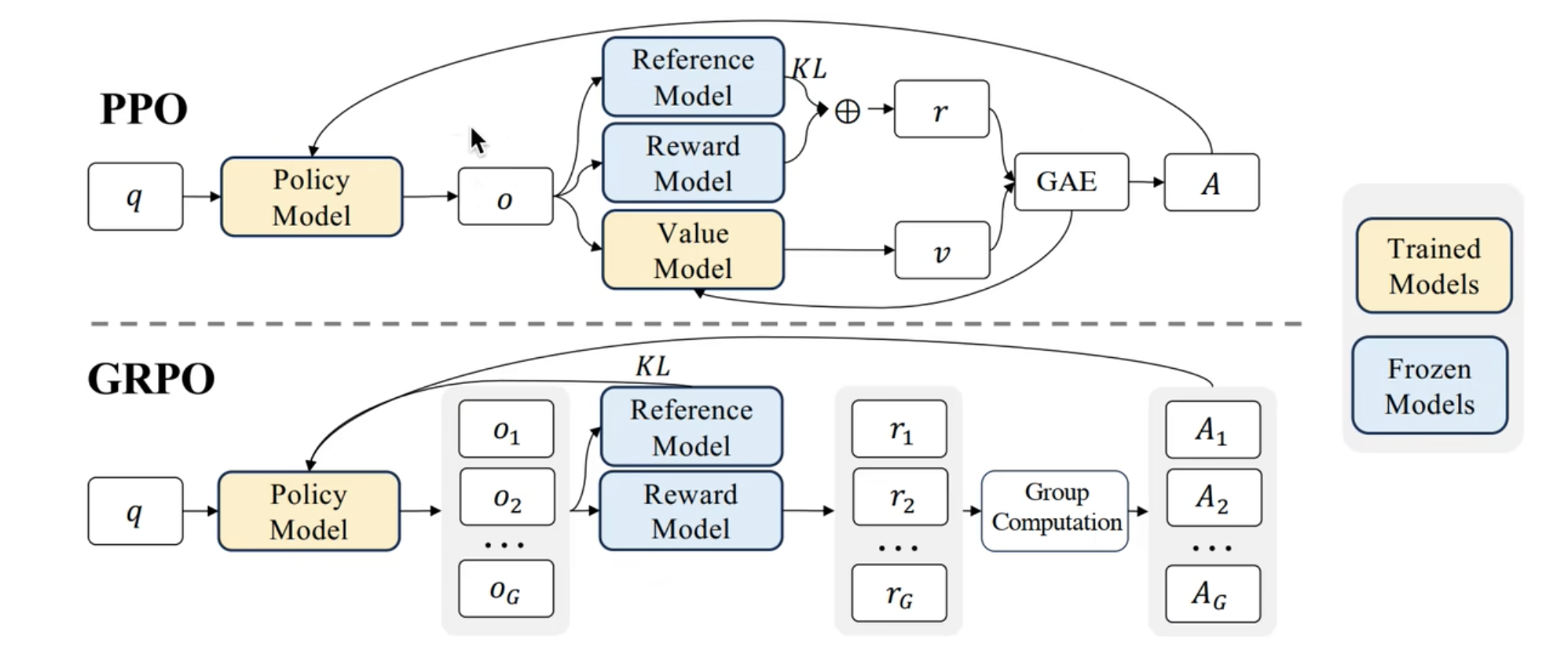
GRPO(组相对策略优化)是一种专为大语言模型(LLM)微调设计的强化学习算法。它通过简化传统PPO算法的复杂架构,在保持强大性能的同时,显著提升了训练效率。下面这张图可以帮你直观地理解它的核心工作流程。
GRPO
GRPO的数学原理:用“组内比较”替代“价值判断”
GRPO的核心创新在于,它摒弃了PPO中需要额外训练一个“价值函数”(Critic Model)来评判好坏的环节。取而代之的,是一种更为巧妙的组内相对比较方法。
-
目标函数与优势估计
GRPO的最终目标函数如下:
L G R P O = E [ − min ( π θ ( a ∣ s ) π θ o l d ( a ∣ s ) A G R P O , clip ( π θ ( a ∣ s ) π θ o l d ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A G R P O ) + β D K L ( π θ ∣ ∣ π r e f ) ] L^{GRPO} = \mathbb{E} \left[ -\min\left( \frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)} A^{GRPO}, \text{clip}\left(\frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)}, 1-\epsilon, 1+\epsilon\right) A^{GRPO} \right) + \beta D_{KL}(\pi_\theta || \pi_{ref}) \right] LGRPO=E[−min(πθold(a∣s)πθ(a∣s)AGRPO,clip(πθold(a∣s)πθ(a∣s),1−ϵ,1+ϵ)AGRPO)+βDKL(πθ∣∣πref)]这个公式包含两个关键部分:
- 裁剪的替代目标(Clip Term):这部分与PPO相同,通过限制新旧策略的概率比( π θ ( a ∣ s ) π θ o l d ( a ∣ s ) \frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)} πθold(a∣s)πθ(a∣s)),防止单次更新步子迈得太大,保证训练稳定。
- KL惩罚项(KL Penalty):这是一个重要的设计差异。PPO通常将KL散度作为惩罚项加入奖励(reward)中,而GRPO则将其直接作为损失函数的一个正则项(即公式中的 β D K L ( π θ ∣ ∣ π r e f ) \beta D_{KL}(\pi_\theta || \pi_{ref}) βDKL(πθ∣∣πref))。这样做的好处是简化了奖励函数,并使KL散度的值为非负,更利于稳定训练。
-
组相对优势(Group Relative Advantage)
GRPO最核心的概念是 A G R P O A^{GRPO} AGRPO,也就是优势。它的计算方式体现了“组内比较”的思想:- 对于同一个输入提示(prompt),让当前的策略模型生成一组(Group)输出(例如,生成4个不同的回答)。
- 使用奖励模型(Reward Model)或基于规则的奖励函数,为这组输出中的每一个计算一个奖励分数 r r r。
- 将这组奖励分数的平均值作为基线(baseline)。
- 每个输出的优势就是其自身奖励与这个组基线的差值: A i = r i − baseline A_i = r_i - \text{baseline} Ai=ri−baseline。
这个过程如上图所示。这意味着,模型不再需要学习一个绝对意义上的“价值函数”,而是通过同一批次同伴的表现来相对地判断自己当前输出的好坏。这大大降低了算法的复杂度和对计算资源的需求。
GRPO的训练过程
GRPO的成功往往依赖于一个精心设计的多阶段训练流程,以DeepSeek R1的训练为例,通常包含以下阶段:
- 阶段一:监督微调:使用高质量的“思维链”数据对预训练好的基础模型进行微调。这个阶段的目标是让模型学会如何一步步地推理,并生成逻辑连贯的文本,为后续的强化学习打下坚实基础。
- 阶段二:推理导向的强化学习:在此阶段引入GRPO。奖励函数通常侧重于准确性和格式,例如,数学答案的正确性、代码的可执行性,以及是否将推理过程包裹在特定的XML标签内以保证输出结构化。
- 阶段三:拒绝采样与监督微调:让第二阶段训练好的模型大量生成样本,然后根据奖励分数筛选出高质量的样本,构成一个新的数据集。再用这个数据集对模型进行一轮监督微调,从而将强化学习中学到的“知识”巩固下来,并扩展模型的能力范围。
- 阶段四:实用性导向的强化学习:最后,再次应用GRPO,但此时的奖励函数会更侧重于输出的实用性、安全性和无害性,使模型最终成为一个均衡、可靠的人工智能助手。
核心创新与后续发展
- 核心优势:GRPO最大的优势在于计算效率。它移除了与策略模型同等规模的价值模型,显著降低了内存消耗,使得大规模语言模型的强化学习训练变得更加可行。
- 面临的挑战与改进:GRPO的主要挑战在于训练稳定性。由于依赖组内采样,当批次较小或数据多样性不足时,优势估计的方差可能较大,导致训练崩溃。为此,研究者们提出了多种改进算法,例如:
- DAPO:通过解耦裁剪范围的上下限等方式,缓解极端奖励导致的梯度问题。
- GMPO:将优化目标从算术平均改为对异常值不敏感的几何平均,从而提升训练稳定性。
希望这份详细的介绍能帮助你全面理解GRPO算法。如果你对其中某个具体的细节(比如KL散度不同的估计方法)特别感兴趣,我们可以继续深入探讨。
好的,我们来详细对比一下PPO和GRPO的损失函数设计和奖励机制,这是理解两者差异的核心。
PPO VS GRPO
PPO 的损失函数组成
PPO的总损失函数通常包含三个主要部分,形成一个权衡:
总损失 = 策略损失 + 价值函数损失 + 熵奖励
用数学公式表示为:
L t o t a l P P O = L C L I P + c 1 L V F − c 2 L E n t r o p y L^{PPO}_{total} = L^{CLIP} + c_1 L^{VF} - c_2 L^{Entropy} LtotalPPO=LCLIP+c1LVF−c2LEntropy
1. 策略损失 (Policy Loss) - L C L I P L^{CLIP} LCLIP
这是PPO的核心创新,确保策略更新稳定:
L C L I P ( θ ) = E t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min\left( r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_t \right) \right] LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
- r t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)} rt(θ)=πθold(at∣st)πθ(at∣st): 重要性权重,衡量新旧策略的差异
- A ^ t \hat{A}_t A^t: 优势函数估计,衡量动作的相对好坏
- ϵ \epsilon ϵ: 裁剪参数(通常为0.1-0.3),限制更新幅度
2. 价值函数损失 (Value Function Loss) - L V F L^{VF} LVF
训练critic网络来准确估计状态价值:
L V F ( ϕ ) = 1 2 ( V ϕ ( s t ) − R ^ t ) 2 L^{VF}(\phi) = \frac{1}{2} (V_\phi(s_t) - \hat{R}_t)^2 LVF(ϕ)=21(Vϕ(st)−R^t)2
- V ϕ ( s t ) V_\phi(s_t) Vϕ(st): 价值网络的预测值
- R ^ t \hat{R}_t R^t: 实际的经验回报(折扣累积奖励)
3. 熵奖励 (Entropy Bonus) - L E n t r o p y L^{Entropy} LEntropy
鼓励探索,防止策略过早收敛:
L E n t r o p y = E t [ S ( π θ ( ⋅ ∣ s t ) ) ] L^{Entropy} = \mathbb{E}_t [S(\pi_\theta(\cdot|s_t))] LEntropy=Et[S(πθ(⋅∣st))]
其中 S S S 是策略分布的熵。
PPO 的奖励设计
在PPO中,奖励通常直接来自环境:
- 环境奖励: 游戏得分、任务完成度等
- 优势估计: 使用GAE(Generalized Advantage Estimation)计算:
A ^ t G A E = ∑ l = 0 ∞ ( γ λ ) l δ t + l \hat{A}_t^{GAE} = \sum_{l=0}^{\infty} (\gamma\lambda)^l \delta_{t+l} A^tGAE=l=0∑∞(γλ)lδt+l
其中 δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st)
GRPO 的损失函数组成
GRPO的损失函数更加简洁,主要包含两个部分:
总损失 = 策略损失 + KL散度惩罚
用数学公式表示为:
L t o t a l G R P O = L p o l i c y G R P O + β D K L ( π θ ∣ ∣ π r e f ) L^{GRPO}_{total} = L^{GRPO}_{policy} + \beta D_{KL}(\pi_\theta || \pi_{ref}) LtotalGRPO=LpolicyGRPO+βDKL(πθ∣∣πref)
1. 策略损失 (Policy Loss) - L p o l i c y G R P O L^{GRPO}_{policy} LpolicyGRPO
基于PPO的裁剪机制,但优势估计方式不同:
L p o l i c y G R P O = E [ − min ( π θ ( a ∣ s ) π θ o l d ( a ∣ s ) A G R P O , clip ( π θ ( a ∣ s ) π θ o l d ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A G R P O ) ] L^{GRPO}_{policy} = \mathbb{E} \left[ -\min\left( \frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)} A^{GRPO}, \text{clip}\left(\frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)}, 1-\epsilon, 1+\epsilon\right) A^{GRPO} \right) \right] LpolicyGRPO=E[−min(πθold(a∣s)πθ(a∣s)AGRPO,clip(πθold(a∣s)πθ(a∣s),1−ϵ,1+ϵ)AGRPO)]
2. KL散度惩罚 (KL Penalty) - β D K L \beta D_{KL} βDKL
这是GRPO与PPO的关键区别之一:
- 直接作为损失项,而不是融入奖励
- 参考策略 π r e f \pi_{ref} πref 通常是SFT后的模型
- 系数 β \beta β 控制与原始策略的偏离程度
GRPO 的奖励设计
GRPO的奖励机制完全不同于PPO:
1. 奖励模型 (Reward Model)
- 学习到的奖励函数: 通常基于人类偏好数据训练
- 规则基础奖励: 针对特定任务设计的启发式奖励
2. 组相对优势 (Group Relative Advantage)
这是GRPO最核心的创新:
A i G R P O = r i − baseline A^{GRPO}_i = r_i - \text{baseline} AiGRPO=ri−baseline
其中 baseline = 1 G ∑ j = 1 G r j \text{baseline} = \frac{1}{G} \sum_{j=1}^G r_j baseline=G1∑j=1Grj
对于同一提示生成G个响应:
- 计算每个响应的奖励 r i r_i ri
- 组平均奖励作为基线(baseline)
- 相对优势 = 个体奖励 - 组平均奖励
📊 对比总结
| 方面 | PPO | GRPO |
|---|---|---|
| 损失函数组成 | 策略损失 + 价值损失 + 熵奖励 | 策略损失 + KL惩罚 |
| 价值函数 | 需要训练Critic网络 | 不需要Critic网络 |
| 优势估计 | 基于时间差分的GAE | 基于组内相对比较 |
| KL散度处理 | 通常融入奖励函数 | 直接作为损失项 |
| 奖励来源 | 环境反馈 | 奖励模型或规则奖励 |
| 计算复杂度 | 较高(需要训练Critic) | 较低(去掉了Critic) |
| 稳定性 | 相对稳定 | 对组大小和采样敏感 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)