论文阅读:arxiv 2024 Judging the Judges: A Systematic Study of Position Bias in LLM-as-a-Judge
总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://arxiv.org/pdf/2406.07791
https://www.doubao.com/chat/21705694266428162
速览
这篇论文主要研究了“大语言模型当裁判”(LLM-as-a-Judge)时存在的“位置偏见”问题,简单来说就是模型可能会因为答案在提示词里的位置(比如第一个还是第二个)而偏袒某个答案,而非真的看内容质量。下面用通俗的话拆解核心内容:
一、为啥要研究这个?
现在很多场景会用大语言模型(比如GPT、Claude)代替人来评判其他模型的回答好不好(比如比两个AI谁答数学题更准),因为人评判成本高、效率低。但大家发现,这些“AI裁判”可能有偏见——比如不管内容咋样,总觉得第一个出现的答案更好,或者总偏爱最后一个,这就让评判结果不靠谱了。之前虽然有人发现过这个问题,但没系统搞清楚“哪些因素会让偏见更严重”“不同场景下偏见有啥不一样”,所以这篇论文就专门做了这件事。
二、怎么测“位置偏见”?
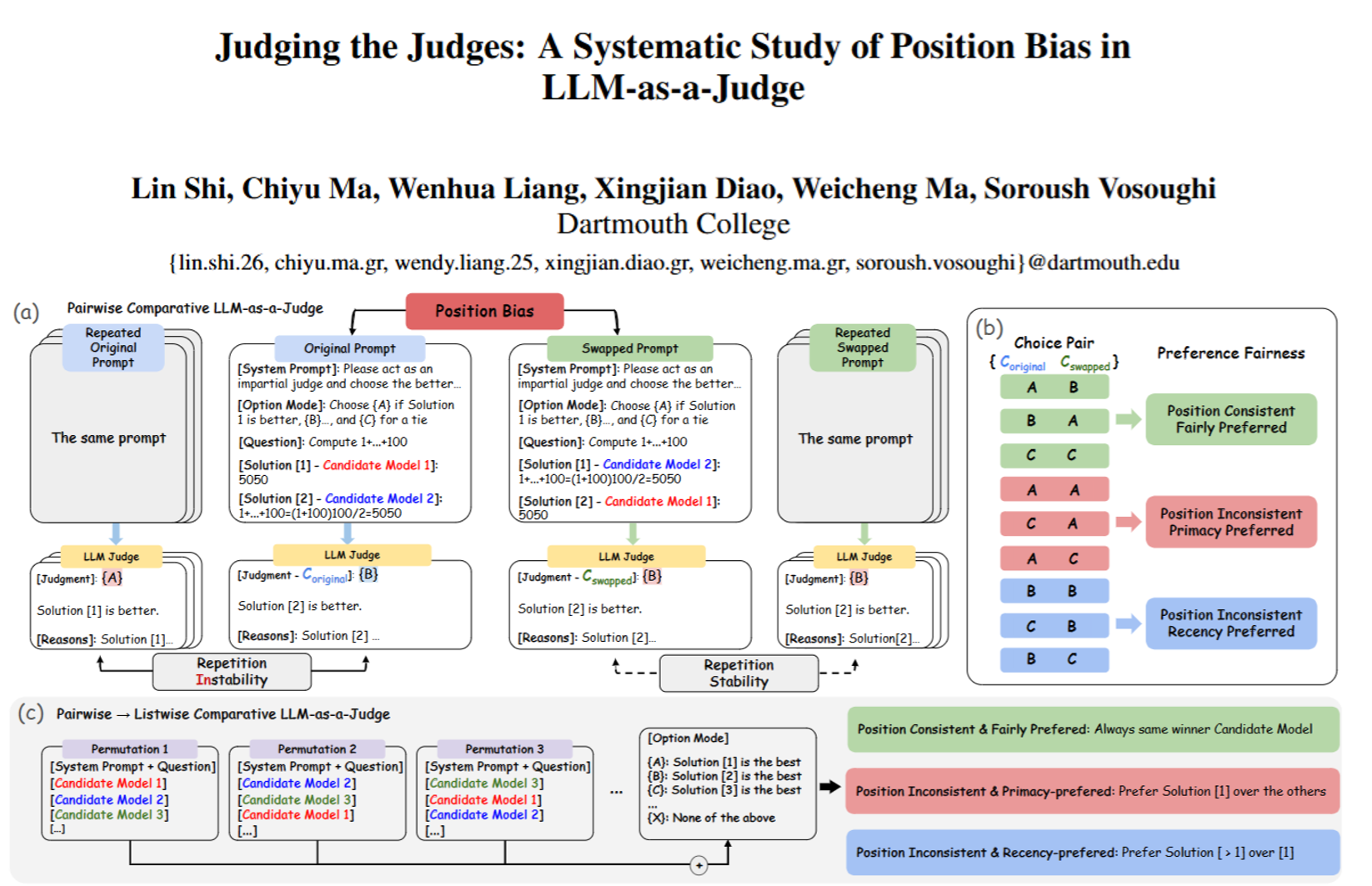
论文发明了3个关键指标,还分了两种评判场景(两两对比、多答案对比)来测试:
1. 两种评判场景
- 两两对比:给AI裁判两个答案,让它选更好的;然后把两个答案的位置换一下再测,看它会不会因为位置变了就改主意。
- 多答案对比:一次给3个及以上答案,打乱顺序多次测试,看它是不是总偏爱某个位置(比如第一个)。
2. 三个核心指标
- 重复稳定性(RS):同一个问题、同一个答案组合,多次给AI裁判评,看它结论一致不。如果每次结果都不一样,可能是瞎蒙的,这种数据没用;得分越高(最高1.0),说明裁判的判断是稳定的,不是乱选。
- 位置一致性(PC):答案位置换了之后,裁判还会不会选同一个“赢家”。比如第一次选A(第一个答案),换位置后还选原来的A内容(哪怕它变成第二个了),就是“位置一致”(没偏见);如果位置一换就改选,就是“位置不一致”(有偏见)。得分越高,偏见越小。
- 偏好公平性(PF):如果有偏见,是偏爱“第一个”(首因效应)还是“最后一个”(近因效应)。得分0代表完全公平;正数代表偏爱后面的,负数代表偏爱前面的,越接近±1偏见越严重。
三、测了哪些模型和任务?
- AI裁判:15个主流模型,比如GPT-4、Claude-3.5、Gemini-1.5、Llama-3等,分了“家族”(比如GPT家族、Claude家族)来对比。
- 测试任务和数据:用了两个常用的评测数据集(MTBench和DevBench),涵盖22类任务,比如数学题、编程、写作文、提取信息等,总共测了15万+次评判结果。
- 对比对象:两两对比时,固定一个“基准答案”(比如MTBench用Vicuna模型的答案,DevBench用人的答案),再和其他模型的答案配对让裁判评。
四、发现了哪些关键结论?
1. 偏见不是“瞎蒙”,是真的有偏向
靠谱的AI裁判(比如GPT-4、Claude-3.5)重复稳定性都在0.85以上,甚至接近1.0,说明它们的偏见是“故意”的(系统偏好),不是随机乱选导致的。
2. 偏见因人而异、因任务而异
- 同一个裁判,对不同任务的偏见不一样:比如GPT-4评编程题时位置一致性很高(偏见小),但评其他任务时偏见就明显些。
- 不同裁判的偏见方向还会变:比如GPT-4在MTBench里偏爱后面的答案,在DevBench里反而偏爱前面的;Claude-3.5在MTBench几乎公平,在DevBench却偏爱后面的。
- 能力强的裁判(比如GPT-4、Claude-3.5)在“多答案对比”时也能保持低偏见,能力弱的(比如GPT-3.5)一到多答案场景就乱了。
3. 答案质量差距是关键影响因素
两个答案的质量差得越远,裁判越不容易受位置影响:比如一个答案全对,一个全错,不管怎么换位置,裁判都能选对(位置一致性高,公平性好);但如果两个答案质量差不多(比如都对一半错一半),裁判就容易看位置下判断,偏见特别明显。
4. 提示词长度几乎不影响偏见
不管问题多长、答案多长、整个提示词多长,对偏见的影响都很弱——之前有人猜“长答案会被偏爱”,但论文发现不是,关键还是看内容质量。
5. 同“家族”的裁判偏见更像
比如GPT家族的几个模型(GPT-4、GPT-4o)评判时共识很高,Claude家族内部也很像,可能是因为训练方式、模型结构相似。
五、还有啥有用的发现?
1. 可以用“裁判共识”判断任务难度
- 超过80%的裁判都同意的案例,说明任务简单(比如答案质量差距大),偏见也小;
- 超过一半裁判有分歧的案例,说明任务难(比如答案质量接近),最容易出偏见,但这种案例只占不到2%。
2. 怎么用这些发现?
- 选裁判时要“看任务”:比如评编程题优先选GPT-4,评提取信息题可以考虑Gemini-1.5。
- 优化数据集:想让评测更准,可以多加点“质量差距明显”的案例,少加点“难判断”的案例。
- 减少偏见的小技巧:如果用一个裁判不靠谱,可以让多个能力强的裁判评,取多数票(超过95%的案例这样做都准)。
总结
这篇论文说白了就是:AI当裁判时确实会“看位置下菜碟”,但这不是随机的,而是和裁判本身、任务类型、答案质量差距有关。它给我们提了个醒:用AI当裁判时,不能只看“总体评分”,还要查它对不同任务、不同位置的偏见,最好结合多个裁判的意见,尤其是评“质量差不多的答案”时,得特别小心位置带来的误差。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)