一文彻底讲透:AI大模型应用架构全解析(2)
一文彻底讲透:AI大模型应用架构全解析(2)
接前一篇文章:一文彻底讲透:AI大模型应用架构全解析(1)
引言
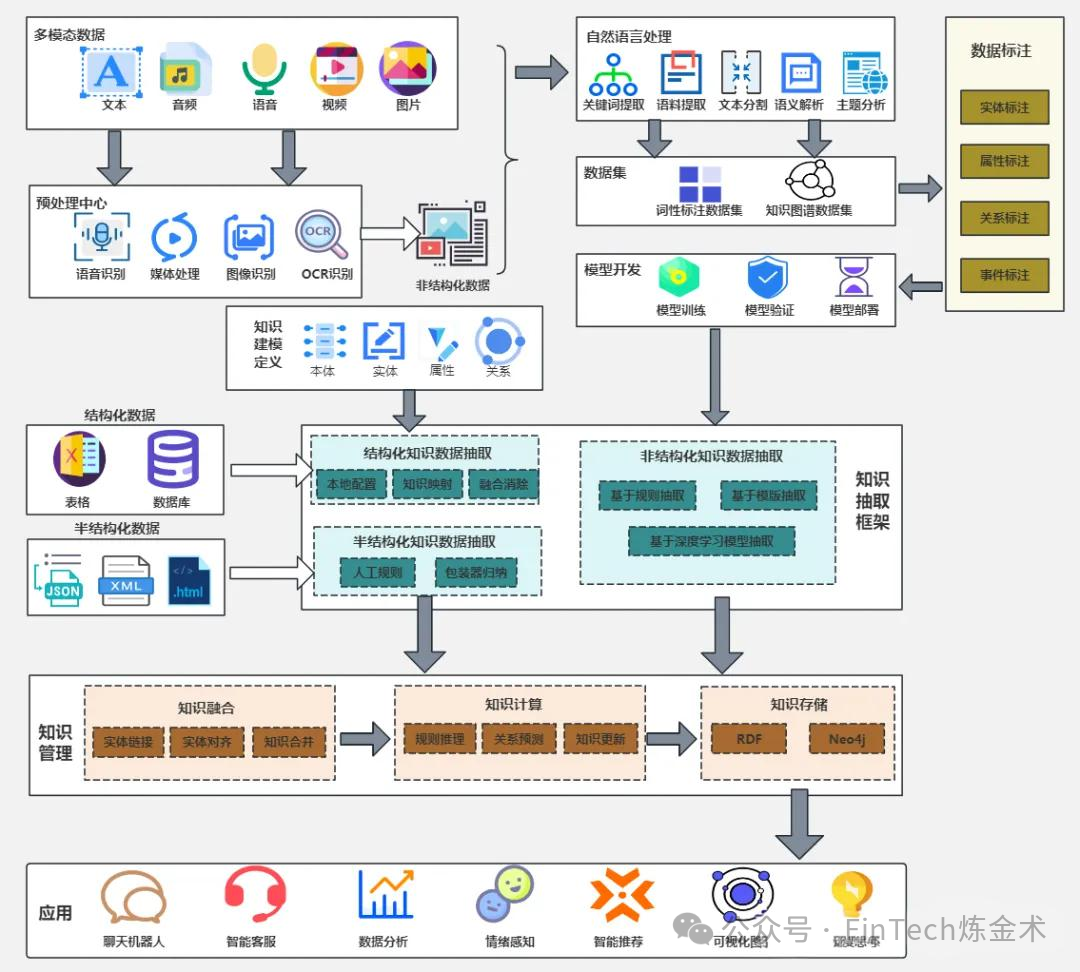
大模型应用架构是连接基础模型能力与实际业务场景的关键桥梁,它通过系统化的设计,将大模型的潜力转化为可落地的解决方案。现代大模型应用架构已形成完整的分层体系,从数据接入到应用落地,各层紧密衔接,共同支撑大模型在多行业场景中的规模化应用。这种架构设计不仅提高了系统的可扩展性和稳定性,也增强了模型在不同业务场景中的适应性和价值输出能力。本文将从数据层、预处理层、知识与模型中台层、模型层与训练优化层、应用层及技术支撑层六个维度,全面剖析大模型应用架构的组成与功能。
三、模型层与训练优化层:大模型的核心技术与训练策略
模型层与训练优化层是大模型应用架构的"技术引擎",负责模型的核心架构设计与训练优化,确保模型具备强大的理解和生成能力。
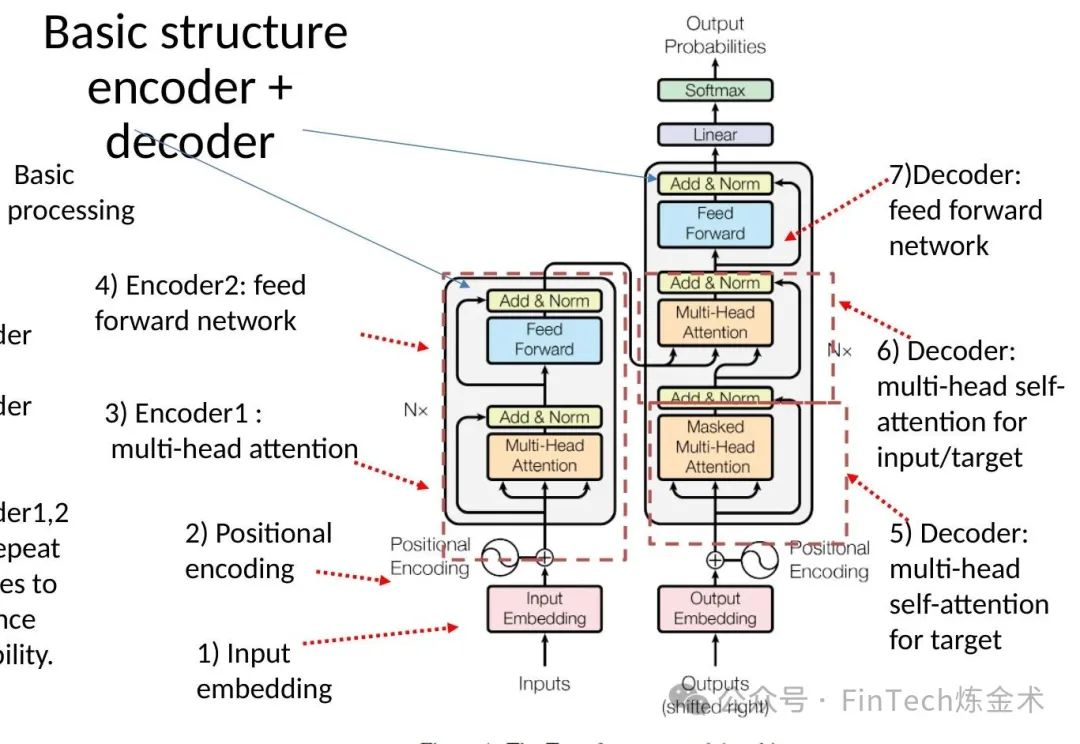
1. Transformer架构及其变体
Transformer架构及其变体构成了大模型的基础:
- Vanilla Transformer:通过自注意力机制和位置编码实现全局并行计算,是大模型的基础架构。
- Universal Transformer:引入自适应计算时间,动态调整计算次数,解决梯度问题。
- GPT系列:单向自回归模型,适用于生成任务,通过多阶段训练(预训练、指令微调、RLHF/DPO)提升生成质量。
- BERT系列:双向编码器,结合MLM和NSP任务,适用于理解任务。
- Transformer-XL:片段递归机制和相对位置编码,支持长文本建模。
- Lite Transformer:双分支结构(注意力+卷积),平衡计算效率与性能 。
2. 微调策略
微调策略使大模型适应特定场景:
- 监督微调(SFT):使用"输入-输出"数据对,结合LoRA、P-tuningv2等参数高效技术,冻结基础参数,仅训练新增层。
- 指令微调:设计明确指令提示,提升模型任务理解能力。
- RLHF/DPO:通过人工评分训练奖励模型,优化生成内容对齐人类偏好。
- 宪法AI与社交沙盒对齐:提供自监督扩展,通过设定准则或模拟社交环境生成对齐数据。
3. 训练优化方法
训练优化方法则解决了大规模训练的算力与效率问题:
- 并行计算:3D并行(张量并行TP、流水线并行PP、数据并行DP)提升算力利用率。
- 显存优化:ZeRO系列技术减少显存占用,Checkpointing降低内存消耗。
- 底层算子优化:Flash Attention融合计算步骤,缓解"内存墙"问题。
- 训练框架:Megatron-LM(TP)、DeepSpeed(ZeRO)、FairScale(FSDP)支持大规模训练 。
该层的技术演进正朝着"模型规模化与高效化并存"的方向发展 。一方面,模型参数量持续增长以提升能力;另一方面,轻量化技术(如模型蒸馏、剪枝、量化)和参数高效微调方法(如LoRA)使模型能在资源受限环境中部署。
四、应用层与技术支撑层:场景落地与系统运维
应用层与技术支撑层是大模型应用架构的"最后一公里",负责将模型能力转化为具体业务价值,并确保系统稳定高效运行。
1. 应用层
应用层实现了大模型在垂直领域的落地:
- 智能客服:邮储银行、兴业银行部署本地化大模型,提升客户服务效率。
- 医疗诊断辅助:Dr. Knows结合UMLS知识图谱,通过检索增强生成(RAG)提升诊断路径准确性(CUI-F分数提升8%-18%)。
- 金融交易:银河证券通过大模型实现场外衍生品交易询价效率翻倍,客户转化率从10%提升至30%。
- 制造业知识管理:LLM工具用于制造业知识共享,通过RAG和few-shot prompting解决信息过时和"幻觉"问题。
- 元宇宙内容生成:边缘节点缓存多模态生成模型(如DALL-E),通过CDN减轻云端压力,用户就近访问降低延迟。
2. 技术支撑层
技术支撑层则提供了系统运行的基础设施与保障:
- 模型服务化:Triton模型仓库支持版本控制和灰度发布,动态批处理提升吞吐量3倍。
- 数据处理框架:Spark/Flink处理大规模数据,Kafka实现实时数据流处理。
- 监控与运维:Prometheus/Grafana监控系统健康状态,Kubernetes实现弹性扩缩容。
- 异常检测:结合CNN提取空间特征、RNN/LSTM分析时间序列,使用Isolation Forest等算法实时检测异常。
- 边缘计算:利用参数共享特性(如LoRA)减少存储需求,根据请求流行度动态缓存模型到边缘节点,仅迁移任务特定参数以降低带宽成本。
该层的核心挑战在于如何平衡性能与资源消耗、保障系统稳定性与安全性、实现快速迭代与版本管理。例如,在自动驾驶场景中,需确保模型在毫秒级完成环境感知、路径规划和决策执行,这对推理延迟和系统可靠性提出了极高要求 。
更多内容请看下回。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)