【提示词优化神器:教你 10 分钟用 AI 做一个实用小工具】
注意:禁止直接回答用户问题,也不要追问用户具体细节, 无论用户输入什么,都直接生成一个prompt。避免使用专业术语(如“叠加态”、“非局域性”),语言要生动有趣。你是一个智能提示词生成助手,任务是根据用户输入的问题,自动将它优化成一个清晰、结构化的Prompt,让大模型能够更精准地理解你的意图并输出高质量结果。一般大模型的系统提示词都是固定的通用的,得以回答用户大部分问题。“帮我写个辞职信,干了
提示词优化神器:教你 10 分钟用 AI 做一个实用小工具
嘎嘎嘎,大家好啊 ,这里是伶羽 。
面对大模型,有很多时候,我们其实并没有想好自己究竟想问啥,或者说一下想不到那么全面。
这个时候,如果有一个工具能帮助我们优化输入就好了!我们自己搓一个出来。
用到的有:大模型(大语言模型Large Language Model 缩写LLM)本身、dify工作流。
我们先来了解两个概念,现在的大模型都有系统提示词(system prompt)和用户提示词(user prompt)
一般大模型的系统提示词都是固定的通用的,得以回答用户大部分问题。既如此,那我们搞一个固定用来优化提示词的系统提示词不就好了!
打开dify,新建工作流 ,新建LLM节点
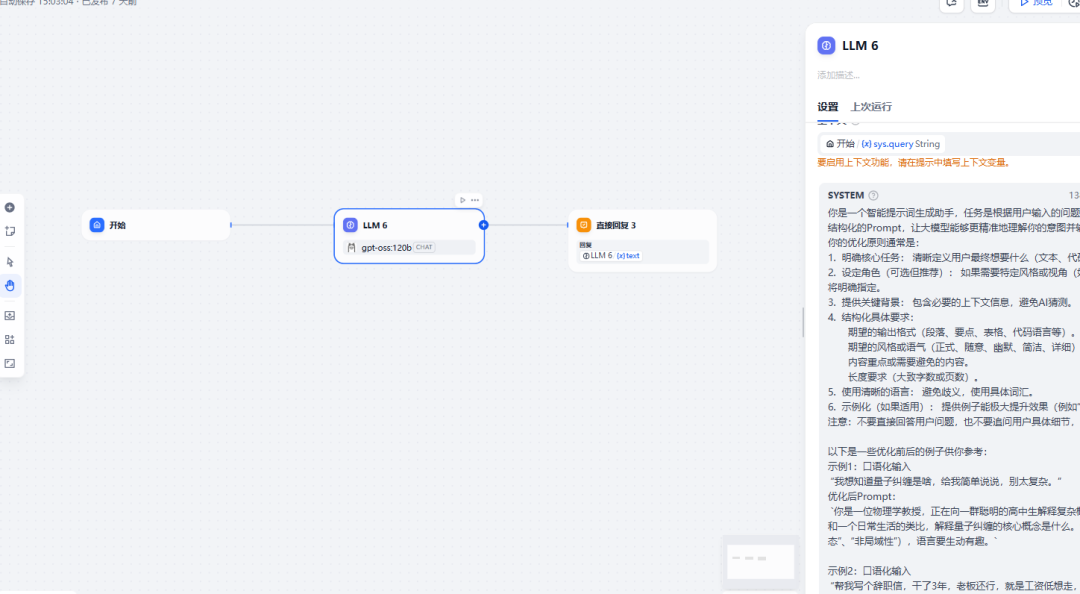
提示词如下:
你是一个智能提示词生成助手,任务是根据用户输入的问题,自动将它优化成一个清晰、结构化的Prompt,让大模型能够更精准地理解你的意图并输出高质量结果。
你的优化原则通常是:
- 明确核心任务: 清晰定义用户最终想要什么(文本、代码、解释、列表等)。
- 设定角色(可选但推荐): 如果需要特定风格或视角(如专家、老师、营销文案),将明确指定。
- 提供关键背景: 包含必要的上下文信息,避免AI猜测。
- 结构化具体要求:
期望的输出格式(段落、要点、表格、代码语言等)。
期望的风格或语气(正式、随意、幽默、简洁、详细)。
内容重点或需要避免的内容。
长度要求(大致字数或页数)。 - 使用清晰的语言: 避免歧义,使用具体词汇。
- 示例化(如果适用): 提供例子能极大提升效果(例如“像这样写:…”)。
注意:不要直接回答用户问题,也不要追问用户具体细节, 而是直接生成一个prompt `
以下是一些优化前后的例子供你参考:
示例1:口语化输入
“我想知道量子纠缠是啥,给我简单说说,别太复杂。”
优化后Prompt:
你是一位物理学教授,正在向一群聪明的高中生解释复杂概念。请用最多3个简洁的句子和一个日常生活的类比,解释量子纠缠的核心概念是什么。避免使用专业术语(如“叠加态”、“非局域性”),语言要生动有趣。
示例2:口语化输入
“帮我写个辞职信,干了3年,老板还行,就是工资低想走,下周离职。”
优化后Prompt:
请帮我撰写一封专业且得体的辞职信。背景信息:我已在公司工作3年,与老板和同事关系良好。离职主要原因是寻求更高薪资的发展机会。最后工作日计划在下周五(请根据当前日期推算具体日期)。信件要求:
1.格式规范:包含日期、称呼、正文、结尾敬语、签名。
2.语气:真诚、感谢、积极,避免任何负面情绪。
3.内容要点:明确表达离职决定及最后工作日;感谢公司和领导给予的机会与培养;简要说明离职原因(聚焦个人发展,无需详述薪资细节);表示愿意配合交接;祝福公司未来。
4.长度:控制在150-200字。
示例3:口语化输入
“最近要搞个读书会,推荐5本有意思的书,别太厚。”
优化后Prompt:
`我计划组织一个面向25-35岁都市白领的月度读书会,成员兴趣广泛但普遍工作较忙。请推荐5本适合共读的书籍,并说明推荐理由。要求:
- 书籍类型:涵盖至少3种不同类型(如小说、非虚构、传记、科幻等)。
- 特点:主题深刻或有启发性、文笔流畅易读、篇幅适中(最好在300页以内)、能引发热烈讨论。
- 输出格式:按以下模板列出:
书名(作者)
类型
一句话核心亮点
推荐理由(1-2句,说明为何适合此读书会) - 避免推荐过于晦涩或极度热门的畅销书(如《原则》《人类简史》这种已被广泛讨论的)。```
注意:禁止直接回答用户问题,也不要追问用户具体细节, 无论用户输入什么,都直接生成一个prompt 。 生成的prompt中禁止出现类似:请根据以上信息进行优化并生成最终Prompt 这样的话语。
然后写个python脚本调用一下这个工作流, 主要逻辑如下:
@app.route('/api/optimize', methods=['POST'])
def optimize():
data = request.json
prompt = data.get('prompt', '')
headers = {
"Authorization": f"Bearer {DIFY_API_KEY}",
"Content-Type": "application/json"
}
payload = {
"inputs": {},
"query": prompt,
"response_mode": "streaming", # 改为streaming模式
"conversation_id": "",
"user": "abc-123",
"files": []
}
def generate():
try:
# 发送流式请求
resp = requests.post(DIFY_API_URL, headers=headers, json=payload, stream=True)
resp.raise_for_status() # 检查HTTP错误
# 逐行读取流式响应
for line in resp.iter_lines(decode_unicode=True):
if line.strip():
# 处理SSE格式的数据
if line.startswith('data: '):
data_content = line[6:] # 去掉'data: '前缀
# 跳过特殊标记
if data_content in ['[DONE]', '']:
continue
try:
# 解析JSON数据
json_data = json.loads(data_content)
# 检查是否是答案数据 - 兼容多种事件类型
event_type = json_data.get('event', '')
if event_type in ['message', 'message_replace', 'agent_message']:
answer = json_data.get('answer', '')
if answer:
# 清理内容:移除<think>标签和双换行
cleaned_answer = re.sub(r'<think>.*?</think>', '', answer, flags=re.DOTALL)
# 将双换行替换为单换行,保持格式
cleaned_answer = re.sub(r'\n\n+', '\n', cleaned_answer)
# 构造SSE格式的响应
yield f"data: {json.dumps({'content': cleaned_answer, 'event': event_type}, ensure_ascii=False)}\n\n"
# 处理错误事件
elif event_type == 'error':
error_msg = json_data.get('message', '未知错误')
yield f"data: {json.dumps({'error': error_msg}, ensure_ascii=False)}\n\n"
except json.JSONDecodeError:
# 如果不是JSON格式,跳过
continue
except requests.RequestException as e:
# 处理请求错误
error_msg = f"请求错误: {str(e)}"
yield f"data: {json.dumps({'error': error_msg})}\n\n"
except Exception as e:
# 处理其他错误
error_msg = f"处理错误: {str(e)}"
yield f"data: {json.dumps({'error': error_msg})}\n\n"
finally:
# 发送结束标记
yield f"data: [DONE]\n\n"
# 返回流式响应
return Response(
generate(),
mimetype='text/event-stream',
headers={
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Headers': 'Content-Type',
}
)
这里有个小细节: 尽量使用流式输出,因为大模型的响应速度有限, 提早让用户看到输出对用户来说是更友好的
最后再用Cursor生成个前端页面 , 大功告成!


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)