[ESWA 2025]Self-perceptive feature fusion network with multi-channel graph convolution for brain dis
计算机-人工智能-多模板相似约束fMRI精神疾病二分类

论文网址:https://www.sciencedirect.com/science/article/pii/S0957417425016057
论文代码:https://github.com/XL-Jiang/MCGC-SPFFN
目录
2.3.1. Traditional Methods for Brain Disorder Diagnosis
2.3.2. GCN-Based Methods for Brain Disorder Diagnosis
2.4.1. Multi-Graph Mutual Construction Module
2.4.2. Self-Perceptive Feature Fusion Module
2.5.1. Materials and Preprocessing
2.5.2. Experimental Setup and Evaluation
2.5.5. Visualization of Learning Features
2.6.1. Computational Complexity
2.6.2. Influence of Network Architecture
2.6.3. Influence of Hyperparameter
2.6.4. Effectiveness of the accuracy-weighted voting strategy
2.6.5. Influence of Different Similarity Metrics in AELN
2.6.6. Discriminative Brain Region Detection
2.6.7. Limitations and Future Work
1. 心得
(1)和2024TMI的MGCA-RAFFNet有点一眼太像了,导航在这:[IEEE TMI 2024]A Multi-Graph Cross-Attention-Based Region-Aware Feature Fusion Network Using Multi-T-CSDN博客
(2)这文章表述好奇怪啊感觉数学怪有问题的他有问题还是我有问题啊。不是我怎么看了很多了还是觉得是作者的问题,吃蘑菇吃出幻觉了吗?
(3)看完还将就吧,实验还是到位的
2. 论文逐段精读
2.1. Abstract
①fMRI用于精神疾病诊断的限制:脑模板或模态单一
2.2. Introduction
①额,没什么好记录的
2.3. Related work
2.3.1. Traditional Methods for Brain Disorder Diagnosis
①将特征选择与分类器的训练分开,如果特征提取不好可能导致下游误差显著
2.3.2. GCN-Based Methods for Brain Disorder Diagnosis
①作者说虽然现在有很多基于图结构的,但都是单一模态,而他们提出了多模板
2.4. Methodology
①整体框架图:
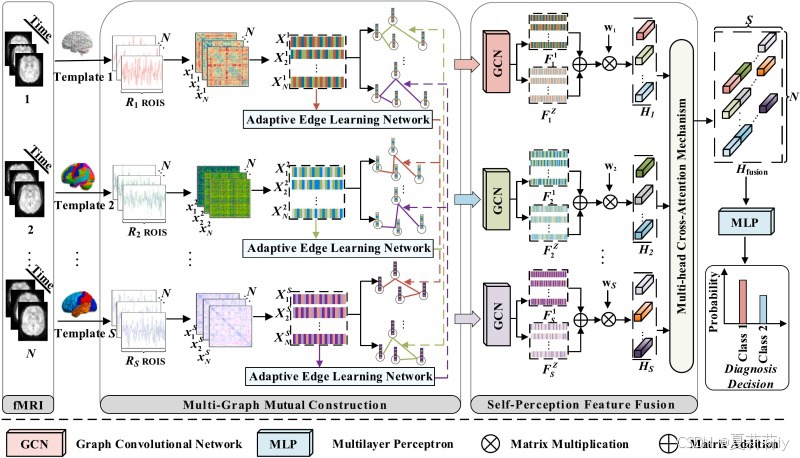
2.4.1. Multi-Graph Mutual Construction Module
①功能连接矩阵:
其中是脑模板数量,
是脑区个数(啊???那
是什么?
不是脑区个数吗。但其实从主图来看N=S诶...而且都是矩阵了为什么是小写的...
...)
②然后作者说功能连接矩阵维度太高了要执行递归特征消除(recursive feature elimination,RFE)算法。会得到,说这个是从被试
的第
个模板中得到的,
是降维后的特征维度。(诶?????这这字母怎么这样写啊什么意思啊为什么两个
那
又是什么)
③作者想建立人与人的亲和力评分矩阵,如果年龄差小于两岁,或者性别相同,则亲和力分数增加一分。意思这里的
是被试个数?。然后还要用高斯核函数计算不同被试同模板
下特征的关系
。最后将这两个矩阵相乘得到邻接关系(是什么乘法?逐元素稍微能接受但矩阵乘法就很苛刻了吧)。然后只保留阈值大于
的。
②AELN模块构造:
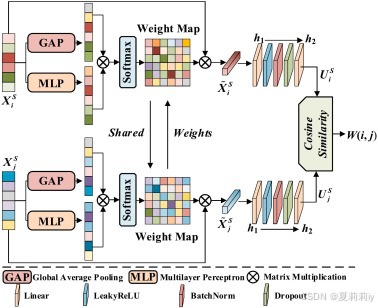
公式是:
我靠作者说是边的特征??How??怎么逐步趋于魔幻了。这个
和之前的
是一个东西吗为什么一个加粗一个不加粗:
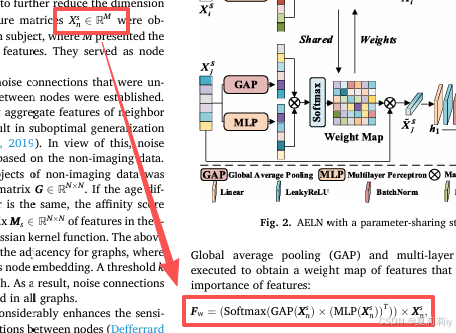
这个X就是不一样吧???![]()
![]() ???难道一个是节点特征一个是边特征吗然后计算AELN输出的不同人?还是脑区的相似度:
???难道一个是节点特征一个是边特征吗然后计算AELN输出的不同人?还是脑区的相似度:
2.4.2. Self-Perceptive Feature Fusion Module
①堆叠的GCN:
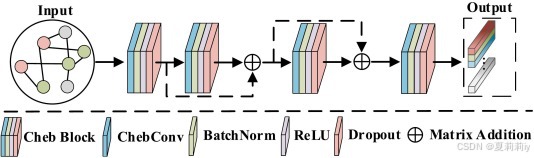
②残差GCN的公式:
其中是图卷积
③作者把每个输出都加起来:
我不知道哪来的个输出,
④作者提出的多头交叉注意力:
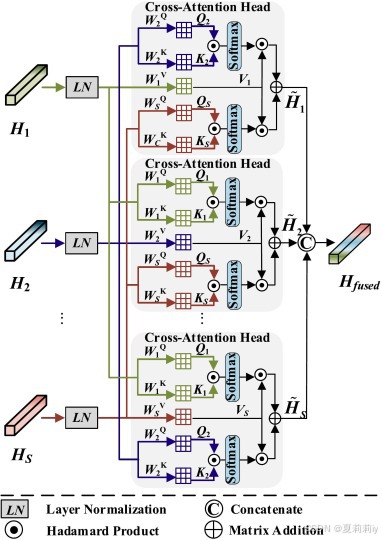
头的个数就是模板的个数。多了之后怪浪费计算量的,不是吗?公式懒得写了和所有的多头交叉都一样。注意力完所有的全加在一起然后进MLP芬贝克u
2.4.3. Objective function
①作者想用Hilbert-Schmidt 独立性标准 (HSIC)捕获同通道(所以这个通道是模板吗?)下不同特征
和
的差异:
其中又是特征维度了?
,
是
的内积。基于此的损失:
作者希望每个特征更彼此独立,即HSIC值越小
②不同模板间特征的相似性损失(怎么感觉这个怪怪的):
其中是协方差矩阵
③总损失:
2.5. Experiments
2.5.1. Materials and Preprocessing
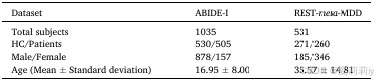
①数据集统计信息:
2.5.2. Experimental Setup and Evaluation
①交叉验证:十倍
②RFE特征维度:1500
③图阈值:
④AELN,,
的丢弃率:1500、128和0.3
⑤每个GCN由4个隐藏层和24个单元组成,丢弃率设置为0.4。
⑥超参数λ和μ设置为5×10−5和 1 × 10−3
⑦优化器:Adam,学习率为0.001,权重衰减设置为0.0005
⑧轮数:150
2.5.3. Comparative Methods
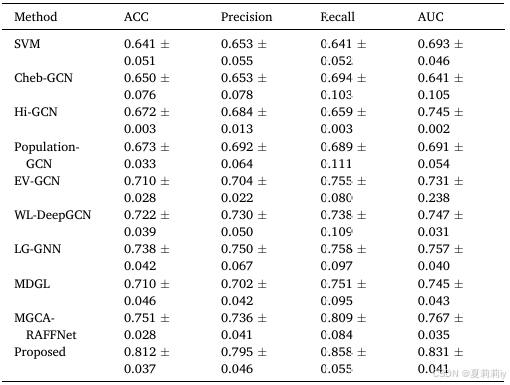
①ABIDE数据集上的比较:
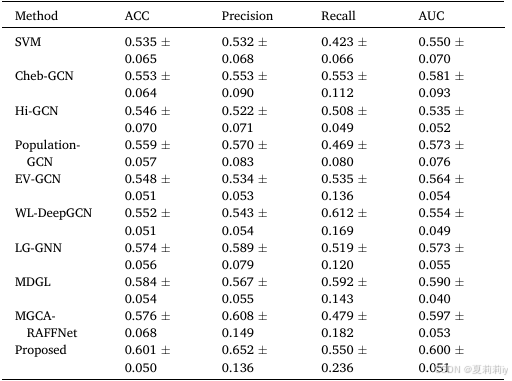
②Rest-meta-MDD数据集的表现:
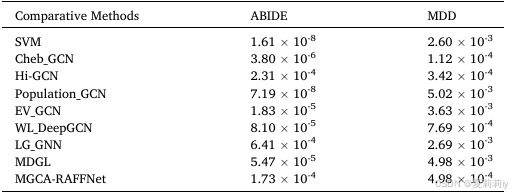
③方法间t检验:
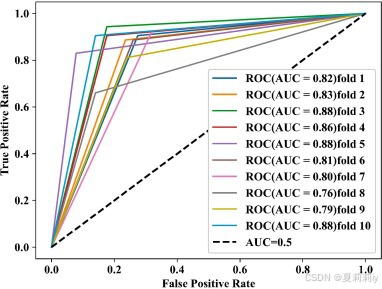
④ROC曲线:
2.5.4. Ablation Study
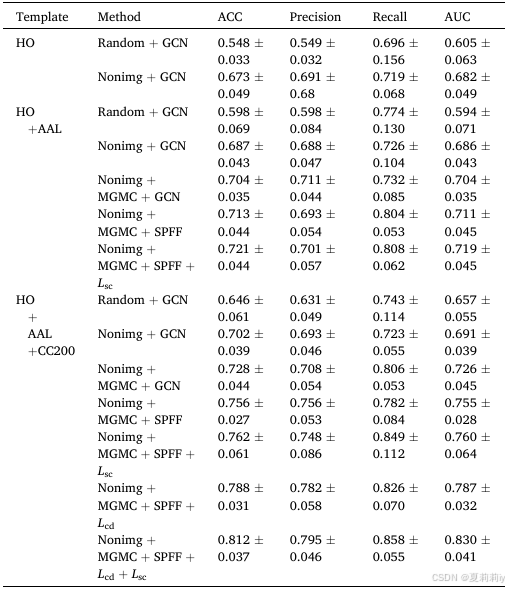
①ABIDE数据集上不同脑图谱的消融实验:
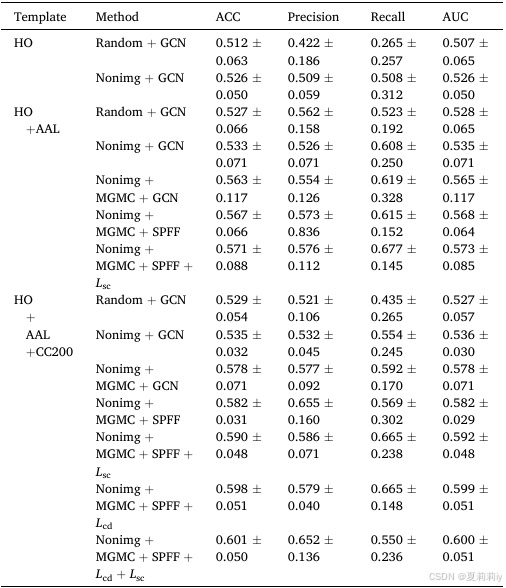
②Rest-meta-MDD数据集上不同脑图谱的消融实验:
③ABIDE数据集中两个损失随着Epoch增加的贡献率:
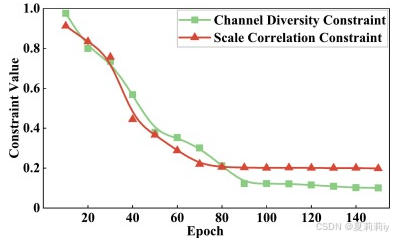
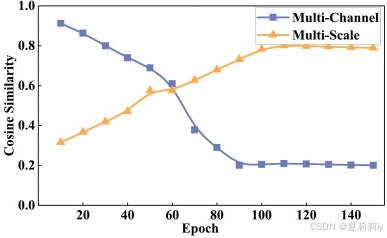
④通道和尺度特征的余弦相似度:
2.5.5. Visualization of Learning Features
①t-SNE可视化不同模板下分布:
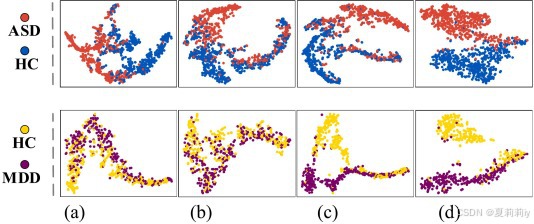
Nonimg + GCN:(a) HO;(b) HO + AAL;(c) HO + AAL + CC200。MCGC-SPFFN:(d) HO + AAL + CC200
2.6. Discussion
2.6.1. Computational Complexity
①运行时间:

2.6.2. Influence of Network Architecture
①网络维度和层数实验:
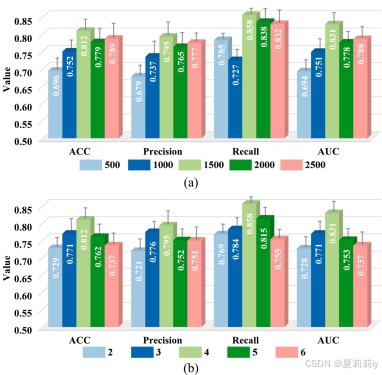
2.6.3. Influence of Hyperparameter
①损失超参数实验:
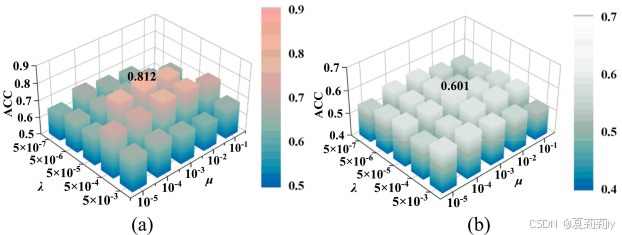
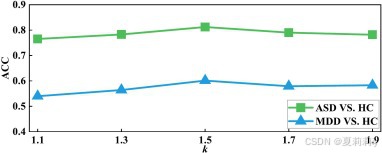
②阈值的影响:
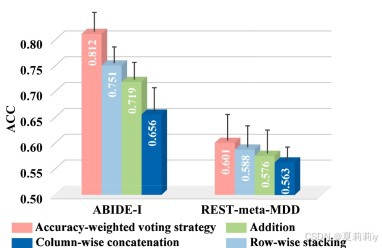
2.6.4. Effectiveness of the accuracy-weighted voting strategy
①融合特征比较:
2.6.5. Influence of Different Similarity Metrics in AELN
①相似度比较:

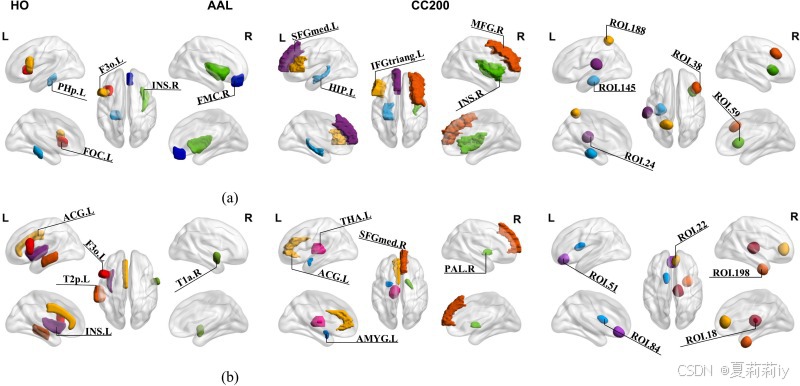
2.6.6. Discriminative Brain Region Detection
①前五个辨别性脑区:
2.6.7. Limitations and Future Work
①消除多站点数据异质性,考虑数据里动态特征,使用纵向数据集
2.7. Conclusion
~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)