NeurIPS‘25 Spotlight:阿里&西交联手提出FSDrive,VLA+世界模型共筑自动驾驶最强范式
然而,当前的视觉语言模型大多采用为特定场景设计的离散文本“思维链”(Chain-of-Thought, CoT),这种方式本质上是对视觉信息的高度抽象和符号化压缩,可能导致时空关系的模糊和细粒度信息的丢失。大量的实验结果表明,FSDrive在轨迹规划、未来帧生成和场景理解等多个任务上均取得了优异的性能,展现了其在推动自动驾驶技术向更高阶的视觉推理迈进方面的巨大潜力。模型的决策不仅基于当前的视觉输入
导语
视觉语言模型(VLMs)凭借其强大的推理能力,在自动驾驶领域正获得越来越多的关注。 然而,当前的视觉语言模型大多采用为特定场景设计的离散文本“思维链”(Chain-of-Thought, CoT),这种方式本质上是对视觉信息的高度抽象和符号化压缩,可能导致时空关系的模糊和细粒度信息的丢失。 那么,自动驾驶是否更适合通过模拟和想象真实世界来进行建模,而非仅仅依赖符号逻辑?
针对这一问题,本文提出了一种名为“时空思维链”(spatio-temporal CoT)的推理方法,旨在使模型能够进行可视化思考。 该方法首先将VLM作为世界模型,生成统一的图像帧来预测未来的世界状态。 FSDrive通过建立像素级的具身化环境关联来实现对道路场景的理解,而非依赖于人工设计的抽象语言符号,从而推动自动驾驶向视觉推理迈进。
项目链接:https://miv-xjtu.github.io/FSDrive.github.io/
论文链接:https://arxiv.org/abs/2505.17685
代码链接:https://github.com/MIV-XJTU/FSDrive
核心理念:从文本CoT到时空CoT
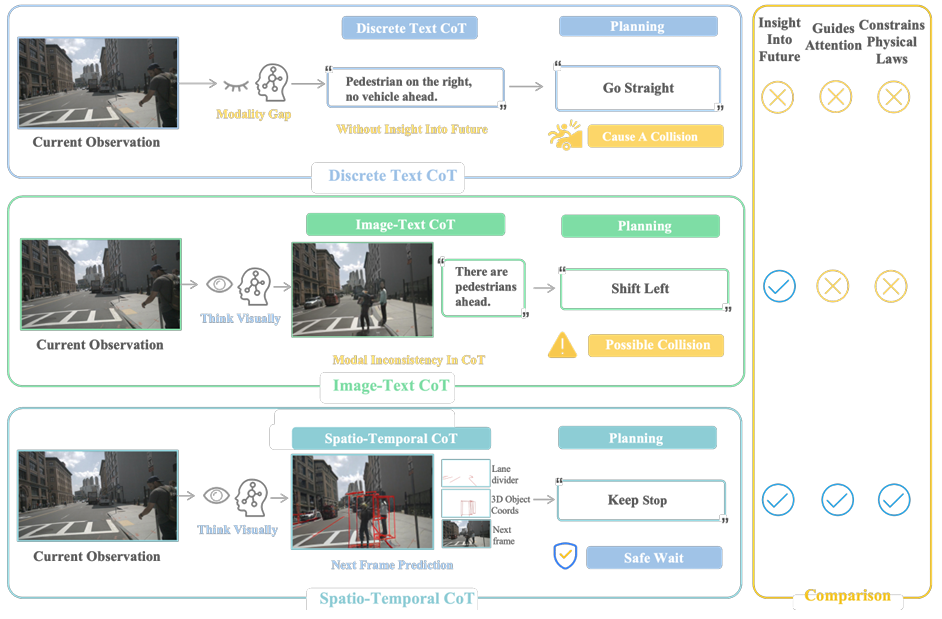
在语言处理领域,“思维链”通过引导模型进行逐步推理,显著提升了模型的推理能力和可解释性。然而,在自动驾驶领域,现有的研究通常将离散的文本CoT作为中间推理步骤,例如使用语言描述当前场景或提供边界框坐标。这种方法存在一些固有的局限性:
- 信息损失:将复杂的视觉信息压缩成抽象的文本符号,不可避免地会丢失大量的细节和空间关系。
- 模态鸿沟:在视觉感知和文本推理之间进行转换,容易产生语义上的偏差和不一致。
- 时空模糊:文本描述难以精确地表达动态场景中复杂的时空演化关系。
为了克服这些挑战,FSDrive提出了一种全新的“时空思维链”方法。其核心思想是让模型直接在视觉层面进行思考和推理,模拟人类驾驶员在脑海中构建未来场景的认知过程。
具体来说,FSDrive中的VLM扮演了世界模型的角色,通过生成统一的图像帧来预测未来的世界状态。这些生成的图像帧包含了丰富的时空信息:
- 空间关系:通过在预测的图像中绘制未来车道分隔线和3D检测框,来表征未来世界的空间结构。这些视觉线索能够引导模型关注可行驶区域和关键物体,并施加物理上的合理性约束。
- 时间关系:通过生成一系列连续的未来帧,来表征场景的动态演化过程。
这种可视化的思维链作为中间推理步骤,使得VLM能够充当逆动力学模型,根据当前的观测和对未来的预测来进行精准的轨迹规划。
FSDrive的技术实现
为了实现上述构想,FSDrive提出了一套完整的技术方案,包括统一的预训练范式和渐进式的生成策略。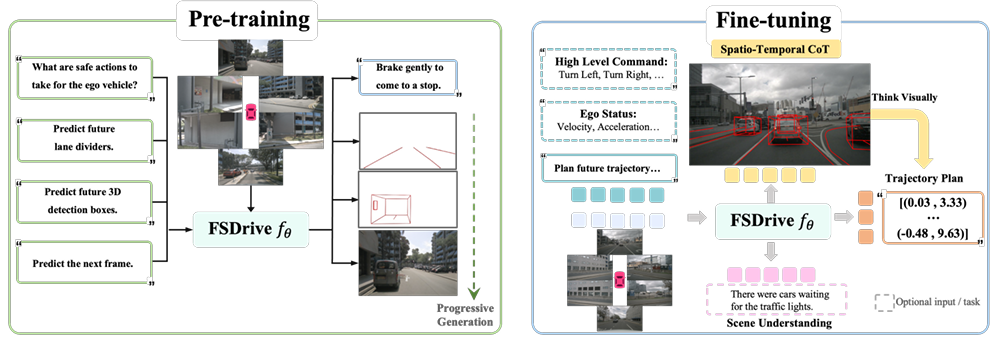
统一视觉生成与理解的预训练
为了赋予VLM生成图像的能力,同时保留其强大的语义理解能力,FSDrive设计了一种统一的预训练范式:
- 视觉理解:沿用视觉问答(VQA)任务,让模型理解当前驾驶场景的语义信息。
- 视觉生成:通过自回归的方式,让模型预测未来的视觉帧。值得一提的是,该方法仅需极少量数据,便能有效激活现有MLLM的视觉生成潜力。
渐进式图像生成
直接生成完整且符合物理规律的未来场景是一项极具挑战性的任务。为此,FSDrive提出了一种由易到难的渐进式生成策略:
- 生成物理约束:首先,利用VLM的世界知识推理出未来场景中的车道线和3D检测框,这些元素构成了场景的骨架,并施加了静态和动态的物理约束。
- 补充细节信息:在物理约束的指导下,生成完整的未来图像帧,补充丰富的细节信息。
通过这种渐进式的方法,模型能够生成更加真实、准确的未来预测,为其后续的规划决策提供可靠的依据。
FSDrive的贡献与意义
FSDrive的提出,为自动驾驶领域带来了诸多贡献:
- 创新的时空思维链:首次提出将思维链从文本域扩展到时空域,使模型能够进行可视化思考,增强了轨迹规划能力。
- 统一的预训练范式:将视觉生成与理解任务相结合,有效激活了VLM的图像生成能力。
- 渐进式生成策略:通过由易到难的生成方式,提高了未来场景预测的准确性和物理真实性。
- 端到端的视觉推理:构建了从视觉输入到轨迹输出的端到端视觉推理流程,消除了跨模态转换带来的语义鸿沟。
大量的实验结果表明,FSDrive在轨迹规划、未来帧生成和场景理解等多个任务上均取得了优异的性能,展现了其在推动自动驾驶技术向更高阶的视觉推理迈进方面的巨大潜力。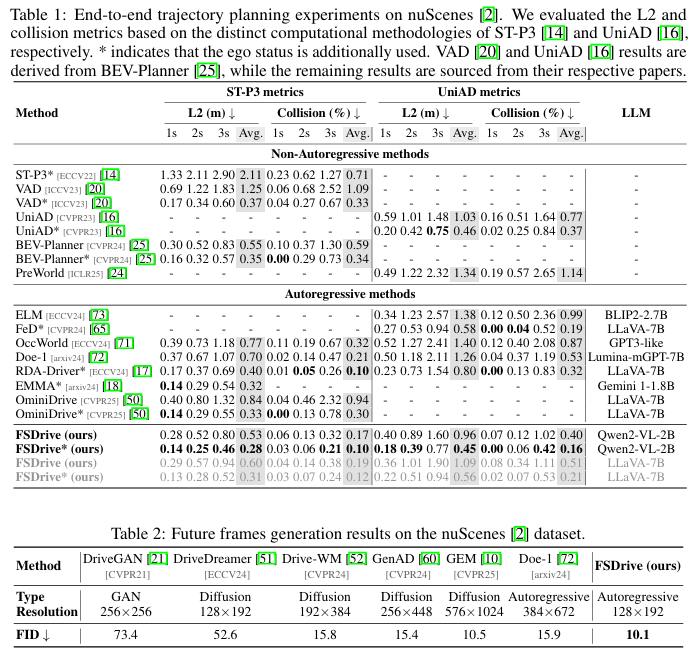
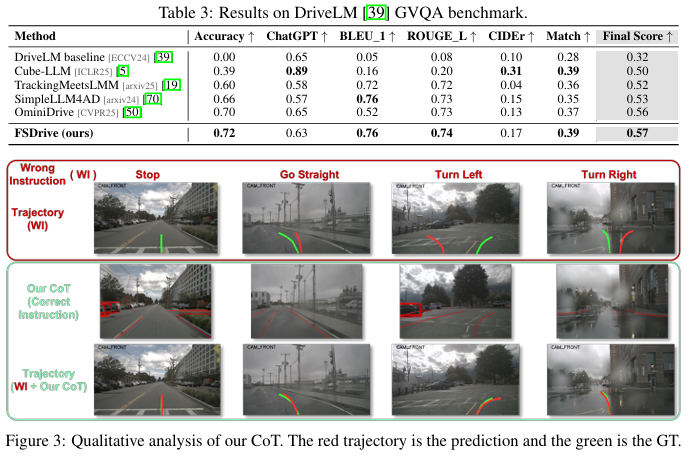
公式解析
1. 端到端轨迹规划:
Wt=M(It,opt(Tcom,Tego))W_t = M(I_t, opt(T_{com}, T_{ego}))Wt=M(It,opt(Tcom,Tego))
该公式描述了端到端自动驾驶模型的基本工作原理。其中,ItI_tIt 代表在时间步 ttt 输入的环视图像,opt(Tcom,Tego)opt(T_{com}, T_{ego})opt(Tcom,Tego) 代表可选的导航指令和自车状态(如速度、加速度),MMM 代表自动驾驶模型,其输出 WtW_tWt 为预测的未来轨迹。
2. 统一视觉生成与理解:
L=−∑i=1h⋅wlogPθ(qi∣q<i)L = -\sum_{i=1}^{h \cdot w} \log P_\theta(q_i | q_{<i})L=−∑i=1h⋅wlogPθ(qi∣q<i)
这是用于训练自回归模型的通用语言建模目标函数。qiq_iqi 代表图像经过VQ-VAE编码后的离散视觉token,θ\thetaθ 是模型的参数。模型的目标是最大化每个token出现的概率,从而学习生成连贯的图像。
3. 时空思维链下的轨迹规划:
P(Wt∣It,QCoT,opt(Tcom,Tego))=∏i=1nPθ(wi∣w<i,It,QCoT,opt(Tcom,Tego))P(W_t | I_t, Q_{CoT}, opt(T_{com}, T_{ego})) = \prod_{i=1}^{n} P_\theta(w_i | w_{<i}, I_t, Q_{CoT}, opt(T_{com}, T_{ego}))P(Wt∣It,QCoT,opt(Tcom,Tego))=∏i=1nPθ(wi∣w<i,It,QCoT,opt(Tcom,Tego))
此公式清晰地展示了FSDrive如何利用时空思维链进行轨迹规划。模型的决策不仅基于当前的视觉输入ItI_tIt和可选指令,还依赖于生成的时空思维链QCoTQ_{CoT}QCoT。这使得模型的规划更具前瞻性和鲁棒性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)