[论文阅读] 人工智能 + 网络安全(WAF)| 99.63%准确率!基于联邦大模型的Web攻击检测方案,破解数据隐私与训练难题
为解决真实Web应用攻击数据量小、差异性大及攻击载荷多样化导致大模型训练效果差的问题,提出基于联邦大模型的网络攻击检测方法(FL-LLMID)。首先,设计面向大模型微调的联邦学习网络,服务器对客户端本地模型的增量参数进行增量聚合,提升参数聚合效率并避免网络流量数据暴露;其次,构建CodeBERT-LSTM攻击检测模型,通过CodeBERT对应用层数据有效字段向量编码,结合LSTM分类,实现高效We
99.63%准确率!基于联邦大模型的Web攻击检测方案,破解数据隐私与训练难题
论文信息
- 论文原标题:基于联邦大模型的网络攻击检测方法研究
- 主要作者及研究机构:
- 康海燕(1. 北京信息科技大学计算机学院,北京 100192;2. 未来区块链与隐私计算高精尖创新中心,北京 100191)
- 张义钒(同上)
- 王楠敏(同上)
- 收稿日期:2024-12-05
- 网络首发日期:2025-07-09
- 发表期刊:《电子学报》(Acta Electronica Sinica,ISSN 0372-2112,CN 11-2087/TN)
- APA 引文格式:Kang, H. Y., Zhang, Y. F., & Wang, N. M. (2025). Research on network attack detection method based on federated large model. Acta Electronica Sinica. https://doi.org/10.12263/DZXB.20241098
- 网络首发地址:https://link.cnki.net/urlid/11.2087.TN.20250708.1708.088
一段话总结
为解决真实Web应用攻击数据量小、差异性大、攻击载荷多样导致大模型训练效果差,且数据暴露会泄露网站脆弱点的问题,康海燕团队提出基于联邦大模型的网络攻击检测方法(FL-LLMID)。该方法通过“面向大模型微调的联邦学习网络”(增量参数聚合+Paillier同态加密+异步更新)保护数据隐私并提升训练效率,结合“CodeBERT-LSTM攻击检测模型”(解析HTTP数据上下文关联)实现精准检测;实验显示其在应用层攻击检测中准确率达99.63%,F1-score 99.14%,较传统联邦学习增量学习效率提升12个百分点,鲁棒性显著优于全量学习及现有对比方法。
思维导图
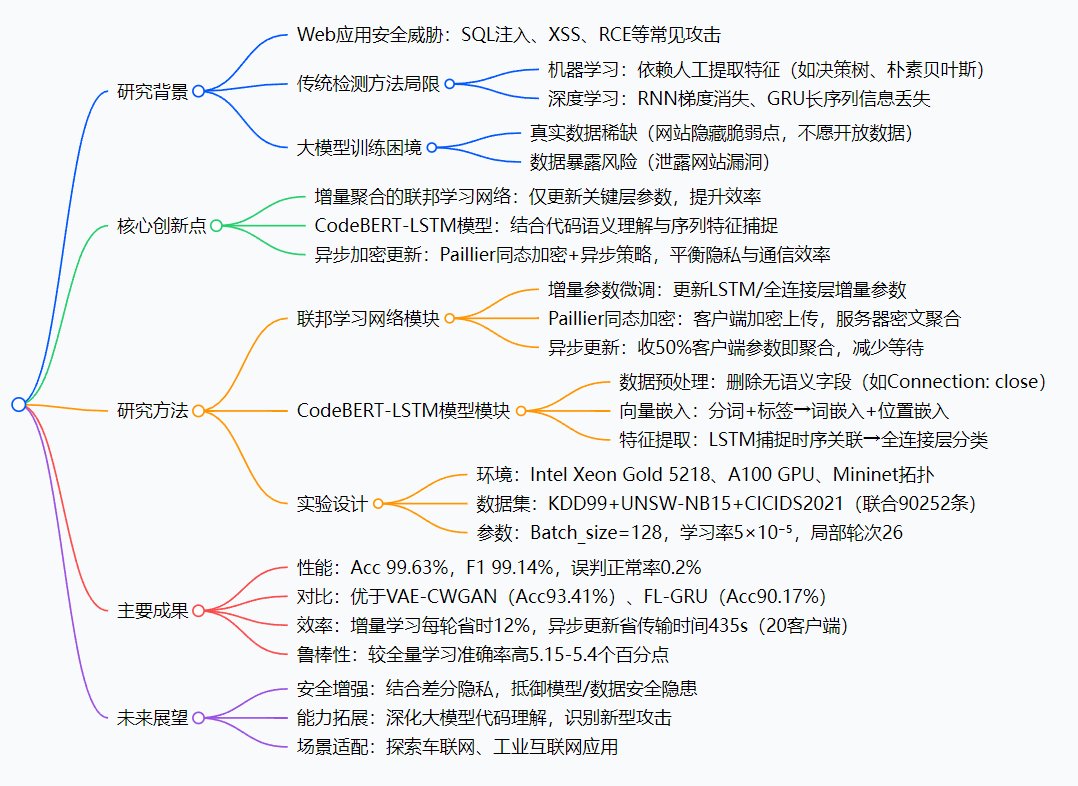
研究背景:Web攻击检测的“两难困境”
如今我们每天刷的网站、用的App,背后都是Web应用在支撑——但这些应用就像“裸露在互联网上的城堡”,随时面临各种“攻城”:比如黑客用SQL注入偷数据库数据、用XSS攻击劫持用户账号、用远程代码执行(RCE)控制服务器……这些攻击不仅会泄露我们的个人信息,还可能让企业蒙受巨大损失。
可过去的“守城方法”总有漏洞:
- 早期靠“人工写规则”(比如识别特定恶意字符串),但黑客很容易改改攻击代码(比如把“eval”嵌套进函数里),规则就失效了——就像小偷换了件衣服,门卫就认不出来了;
- 后来用机器学习(比如决策树、朴素贝叶斯),但得人工挑“攻击特征”,费时又容易漏;
- 再后来用深度学习(比如RNN、GRU),可处理长段请求数据时会“记不住”关键信息(比如长序列里的攻击载荷),还会出现“梯度消失”,就像人记太长的故事,越往后越模糊。
更头疼的是“数据问题”:要训练好的检测模型,得有大量真实攻击数据——但网站管理员谁敢把真实数据公开?万一泄露了网站的漏洞(比如某个页面有代码执行漏洞),等于给黑客“递刀子”。这就陷入了“两难”:没有真实数据,模型训不好;公开数据,又怕引火烧身。
举个具体例子:有个HTTP请求里藏了“eval(next(apache_request_headers()))”,传统方法会把“eval”当普通字符串,根本查不出这是在执行恶意命令;大模型虽然能看懂这种“代码套路”,但没足够真实数据训练,也只能“巧妇难为无米之炊”。这就是FL-LLMID要解决的核心问题。
创新点:FL-LLMID的“三大杀手锏”
这篇论文的厉害之处,在于用三个“创新设计”破解了上述困境,每个设计都精准命中痛点:
1. 增量参数微调:不搬“整座山”,只带“关键石头”
传统联邦学习要把模型所有参数传到服务器,就像每次搬家都要搬整座山,又慢又费资源。FL-LLMID只更新模型的“关键部分”——LSTM层和全连接层的增量参数(比如模型学到的新攻击特征对应的参数变化),其他参数不动。这样一来,客户端上传的数据量大大减少,训练效率直接提升,就像搬家只带重要行李,省时又省力。
2. CodeBERT-LSTM:让模型“读懂”攻击代码的“语义”
过去的模型看攻击数据,就像看“乱码”——只认字符,不认含义;FL-LLMID让模型学会“读代码”:
- 先用CodeBERT(专门理解代码的大模型)把HTTP请求里的有效字段(比如URI、参数值)转换成“语义向量”,比如把“system(‘cat /flag’)”识别成“执行系统命令的恶意代码”;
- 再用LSTM(擅长记长序列的模型)捕捉这些向量的上下文关联,比如发现“apache_request_headers()”获取的请求头,会传给“eval”执行——就像人读句子时,能理清“谁做了什么、和谁有关”,再也不会把嵌套的恶意代码当正常字符串。
3. 异步加密更新:既“锁好数据”,又“不堵车”
要保护数据隐私,又怕传输时“堵车”?FL-LLMID用了两个办法:
- Paillier同态加密:客户端把增量参数加密后再上传,服务器不用解密就能直接聚合——就像把数据装在带锁的箱子里,服务器能把多个箱子的东西“合并”,但打不开箱子,绝对不会泄露数据;
- 异步更新:不用等所有客户端都上传参数,服务器收到50%客户端的参数就开始聚合,聚合完立刻下发新模型——就像快递不用等所有包裹到齐再派送,大大减少等待时间,20个客户端场景下,比同步更新少花435秒传输时间,网络也不容易拥堵。
研究方法与实验:把“创新”落地成“可验证的效果”
光有想法不够,还得用实验证明管用。FL-LLMID的研究方法分“模型设计”和“实验验证”两步,每一步都很扎实:
第一步:搭建FL-LLMID的“两大模块”
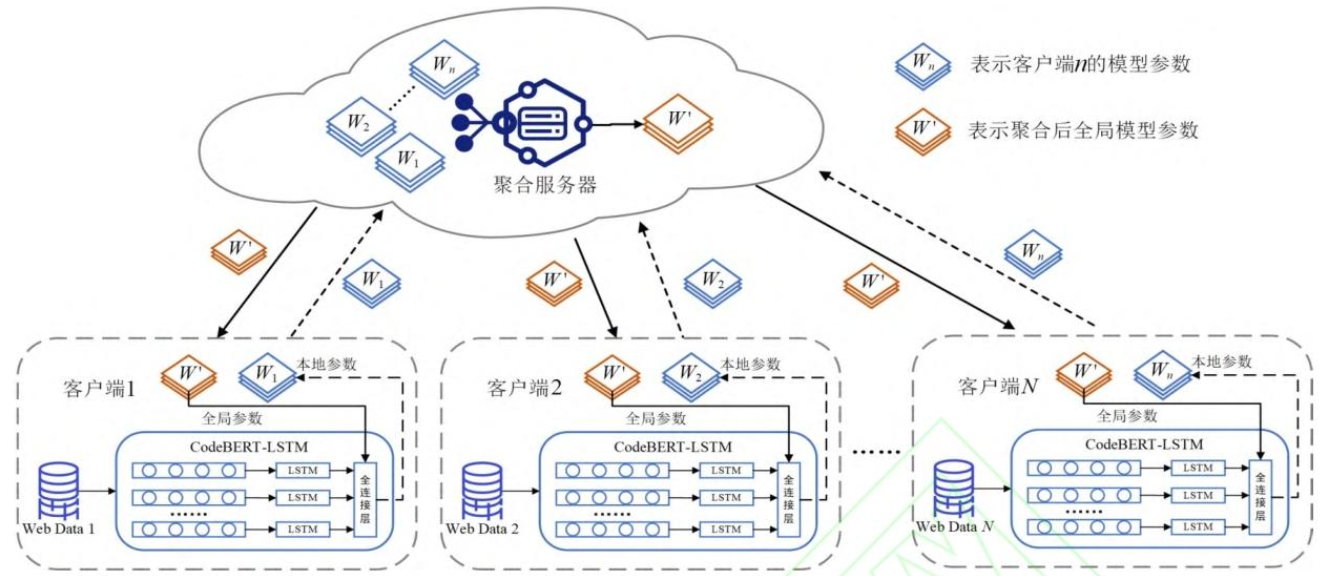
模块1:面向大模型微调的联邦学习网络
- 客户端训练:每个客户端(比如不同网站)下载全局模型,用自己的本地数据(HTTP请求数据)训练,只更新LSTM层和全连接层的增量参数;
- 加密上传:客户端用Paillier加密增量参数,传给服务器;
- 服务器聚合:服务器对密文参数做“增量聚合”(按公式计算权重,合并成新的全局参数);
- 迭代优化:服务器把新的全局参数下发给客户端,客户端用新参数继续训练——循环直到模型稳定。
模块2:CodeBERT-LSTM攻击检测模型
- 数据预处理:用WireShark解析HTTP数据包,删掉“Connection: close”这类无关字段,只留URI、参数等关键信息;
- 向量嵌入:把预处理后的文本分词,加“
”(开头)和“”(结尾)标签,用CodeBERT转成语义向量,再加上位置嵌入(标记每个向量的顺序); - 分类检测:LSTM提取向量的时序关联特征,全连接层结合Softmax函数,把数据分成8类(正常数据+SQL注入、XSS等7种攻击)。
第二步:用实验验证“效果到底有多好”
实验环境:模拟真实网络
- 硬件:64核Intel Xeon Gold CPU、40GB显存A100 GPU(保证大模型训练速度);
- 软件:用Mininet搭3个客户端+1个服务器的网络拓扑(模拟多个网站协同训练),用PyCharm写代码;
- 数据集:用KDD99、UNSW-NB15、CICIDS2017三个公开数据集,按2:3:5比例混合成90252条数据,涵盖8类Web攻击(如表1);
- 训练参数:每次训练128条数据(Batch_size=128),学习率5×10⁻⁵,客户端本地训练26轮,全局训练5轮。
表1:实验数据集类别及数目
| 数据类别 | 数据数目 |
|---|---|
| XSS(跨站脚本)攻击 | 6446 |
| RCE(远程命令执行)攻击 | 6093 |
| SQL注入攻击 | 7269 |
| 目录遍历攻击 | 5734 |
| XXE(外部实体注入)攻击 | 8645 |
| SSRF(跨站请求伪造)攻击 | 7870 |
| 文件上传攻击 | 3070 |
| 正常数据 | 45125 |
实验类型:从“性能”到“鲁棒性”全验证
- 性能实验:模型训练26轮后,准确率从73.3%涨到99.63%,F1-score达99.14%,Loss值稳定(不再大幅波动)——说明模型不仅准,还很稳定;
- 对比实验:和VAE-CWGAN、FL-GRU等5种现有方法比,FL-LLMID的准确率(99.63%)远超其他方法(最高93.41%)——证明它比前辈们更厉害;
- 鲁棒性实验:换Maple-ID、HIKARI-2021等新数据集,FL-LLMID准确率仍保持在97.9%以上,而全量学习波动很大——说明它在不同场景下都好用;
- 效率实验:增量学习每轮训练时间比全量学习少12%(350-370秒 vs 400-420秒),异步更新比同步更新省435秒传输时间——证明它又快又省资源;
- 消融实验:把CodeBERT换成Code Llama、LSTM换成BiGRU,准确率都下降(最低95.36%)——证明CodeBERT+LSTM的组合是最优的。
主要成果与贡献:给Web安全领域带来了什么?
FL-LLMID不是“纸上谈兵”,而是给Web攻击检测领域带来了三个实实在在的价值:
1. 解决了“数据隐私与训练效果”的矛盾
过去要么“牺牲隐私换数据”(公开数据训模型),要么“保护隐私丢效果”(用少量数据训模型);FL-LLMID用联邦学习+同态加密,让多个网站“数据不出本地,却能一起训模型”——既不用暴露漏洞,又能拿到足够真实的数据,模型准确率还能到99.63%。
2. 提升了攻击检测的“精准度”和“效率”
- 精准度:能识别嵌套、变形的攻击代码(比如把“eval”藏在函数里),误判正常数据的概率只有0.2%——相当于1万个攻击里只漏判2个;
- 效率:增量参数微调+异步更新,让训练和传输都更快——20个客户端场景下,传输时间少435秒,每轮训练少花12%时间,适合大规模部署。
3. 为后续研究提供了“新范式”
FL-LLMID把“联邦学习”和“代码理解大模型”结合起来,给其他研究者提供了新思路——比如未来可以用这个思路做工业互联网、车联网的攻击检测,不用再局限于传统方法。
表2:FL-LLMID与现有方法的性能对比
| 方法模型 | 准确率(Acc/%) | 召回率(Rec/%) | 精确率(Prec/%) | F1-score |
|---|---|---|---|---|
| VAE-CWGAN | 93.41 | 92.16 | 92.36 | 93.83 |
| FL-GRU | 90.17 | 90.29 | 89.03 | 90.76 |
| 组内聚合&联邦学习 | 83.05 | 82.93 | 81.32 | 83.18 |
| MHFL-ID | 83.61 | 82.95 | 82.74 | 80.77 |
| Fed-GA-CNN-IDS | 93.20 | 91.05 | 89.82 | 92.18 |
| FL-LLMID(本文) | 99.63 | 99.98 | 97.84 | 99.14 |
关键问题:一文看懂FL-LLMID的核心
Q1:FL-LLMID怎么做到“数据不出本地,还能一起训模型”?
A:靠“联邦学习+同态加密”的组合:每个客户端用自己的本地数据训模型,只把“增量参数”(模型学到的新特征)用Paillier加密后传给服务器;服务器不用解密,直接对密文参数做聚合,生成新的全局参数再下发——整个过程中,原始数据(比如网站的HTTP请求)始终在客户端本地,不会泄露,却能实现“多方协同训练”。
Q2:为什么CodeBERT-LSTM能识别“变形的攻击代码”?
A:因为它能“读懂代码语义”,而不是只认字符:比如“eval(next(apache_request_headers()))”,传统方法只看到“eval”这个字符串,CodeBERT却能识别出“这是在调用函数获取请求头,再传给eval执行恶意命令”;LSTM还能捕捉上下文关联,比如发现“apache_request_headers()”和“eval”的依赖关系——就算黑客改了参数名、嵌套了函数,模型也能认出这是攻击。
Q3:FL-LLMID的“增量学习”比全量学习好在哪里?
A:全量学习每次要更新模型所有参数,就像每次复习都要重看整本书,又慢又费资源;增量学习只更新LSTM层和全连接层的“增量参数”,就像复习只看新增的笔记,效率更高——实验显示,增量学习每轮训练时间比全量学习少12%,还能保持更高的准确率(99.63% vs 99.58%)。
Q4:FL-LLMID在实际场景中好部署吗?
A:好部署!它的实验环境用的是常规硬件(Intel CPU、NVIDIA GPU),软件也是开源工具(Mininet、PyCharm);异步更新策略还能适应不同数量的客户端(10-20个都好用),网络拥塞少——不管是中小网站还是大型企业,都能搭起这个系统。
Q5:未来FL-LLMID还能怎么优化?
A:论文提到了三个方向:一是结合“差分隐私”技术,进一步抵御模型投毒、数据污染等攻击;二是深化大模型的代码理解能力,让它能识别更多新型攻击(比如现在还没出现的攻击手法);三是把它用到车联网、工业互联网等场景,适配这些领域的特殊网络环境。
总结
康海燕团队的《基于联邦大模型的网络攻击检测方法研究》,精准命中了Web攻击检测的“数据隐私”和“训练效果”两难困境。通过设计“增量聚合的联邦学习网络”和“CodeBERT-LSTM检测模型”,FL-LLMID既实现了“数据不出本地的协同训练”,又让模型能“读懂攻击代码语义”,最终在实验中取得99.63%的准确率、99.14%的F1-score,且效率和鲁棒性远超传统方法。
这篇研究不仅为Web安全领域提供了一种“高效、精准、隐私保护”的攻击检测新方案,还为“联邦学习+大模型”在安全领域的应用提供了可参考的范式——未来有望在车联网、工业互联网等更多场景落地,让互联网更安全。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)