基于chainlit聊天会话的后续实现
在上一次我们实现了简单的连接大模型使用聊天会话功能,在这一次的实现当中,我们将实现文档上传,历史会话实现,以及简单登录,其中文档上传,我们将支持pdf文件,带文字的图片文件,同时我们可能还会实现知识库的创建,其中可以包括我们自己预先设定的知识库或者是大模型的知识库的一个知识库问答功能。
一、项目简介
在上一次我们实现了简单的连接大模型使用聊天会话功能,在这一次的实现当中,我们将实现文档上传,历史会话实现,以及简单登录,其中文档上传,我们将支持pdf文件,带文字的图片文件,同时我们可能还会实现知识库的创建,其中可以包括我们自己预先设定的知识库或者是大模型的知识库的一个知识库问答功能。
二、项目展示
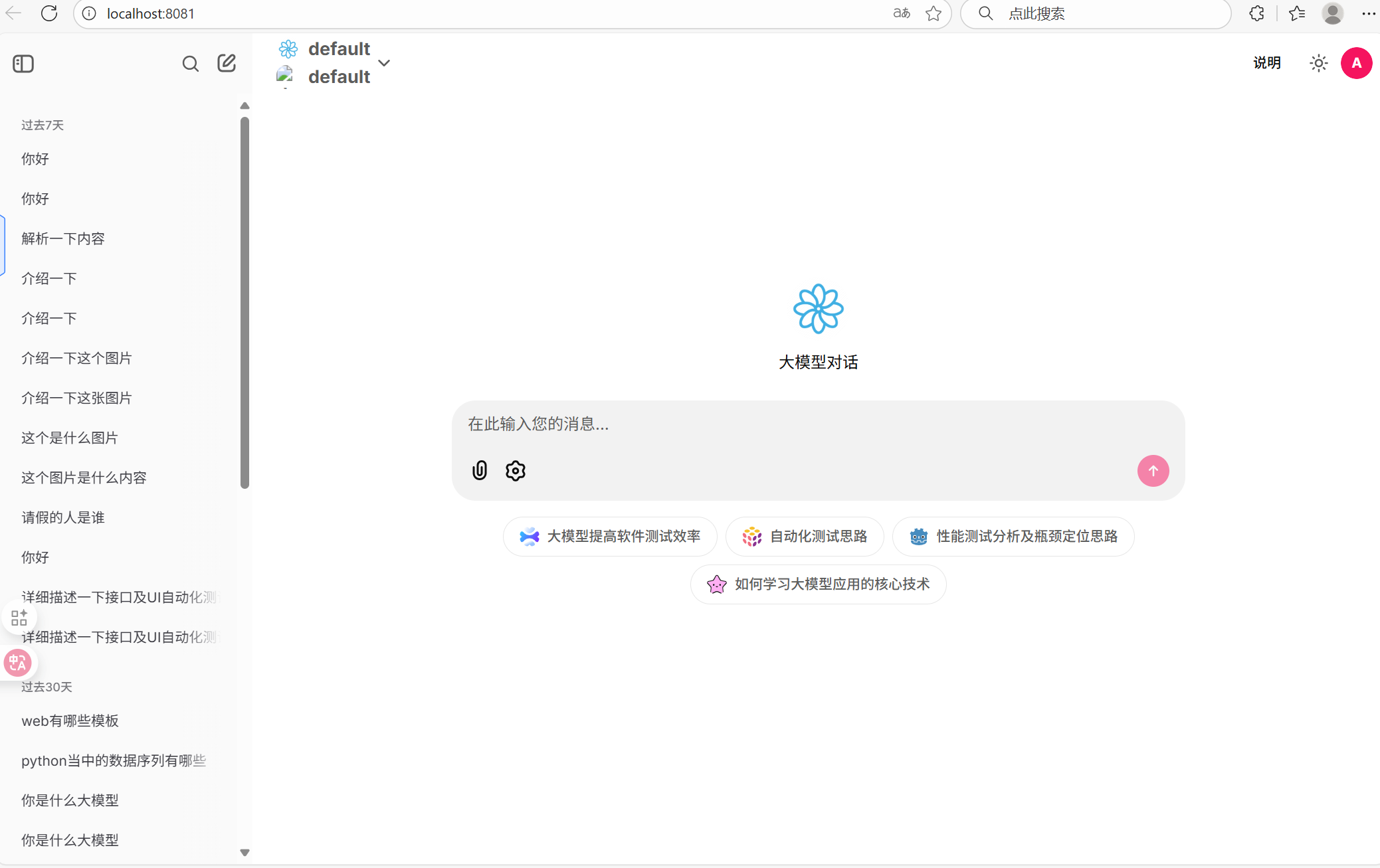
三、项目实现
在项目实现之前我们需要提前做好项目准备,其中第一个就是我们在与大模型聊天的同时会产生很多的聊天记录,这些聊天记录需要用到数据库存储,用户的登录也需要存储,所以我们需要首先提前准备好数据库。我们需要用到postgresql去存储用户与大模型的聊天记录,使用Minio去存储我们上传的文件,使用向量数据库去存储我们的知识库。在我们开始这个项目钱我们首先需要做到这些准备。
3.1用户登录权限的实现
要想实现历史会话,我们首先应该实现用户认证,这是chinlit官方文档当中提到的,使用chainlit实现最重要的就是要参考官方文档的内容,这是在开发过程当中十分重要的!我们可以在官方文档当中看到这段内容。
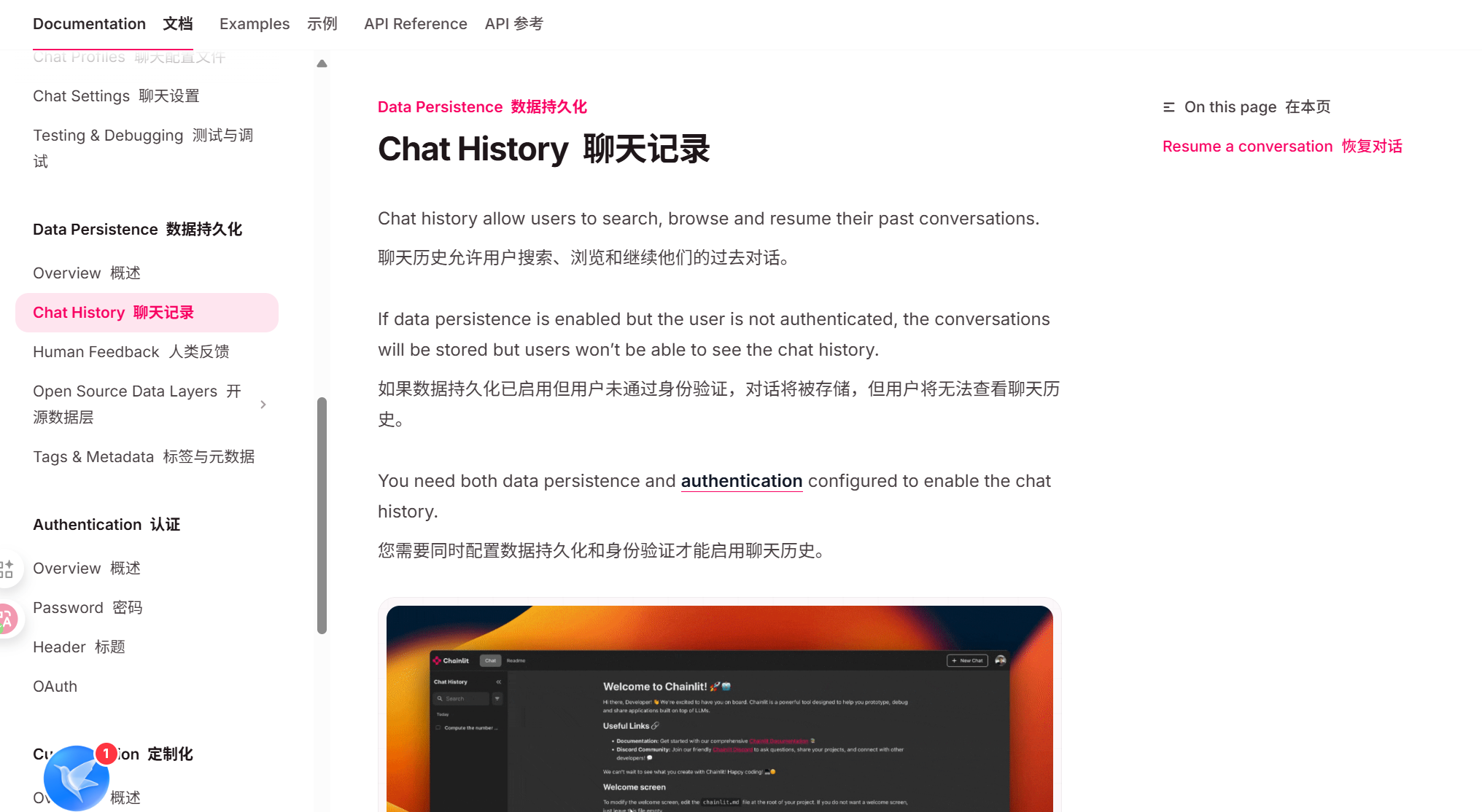

他的示例文档当中存在着这样子的一段代码:
from typing import Optional
import chainlit as cl
@cl.password_auth_callback
def auth_callback(username: str, password: str):
# Fetch the user matching username from your database
# and compare the hashed password with the value stored in the database
if (username, password) == ("admin", "admin"):
return cl.User(
identifier="admin", metadata={"role": "admin", "provider": "credentials"}
)
else:
return None现在我们只需要将这一段代码复制到app.py文件当中即可实现用户登录的权限,以便于我们后续开启chainlit的聊天会话功能。
3.2历史会话功能的实现
在实现历史会话功能之前,我们首先需要对数据库进行连接,我们需要提前将数据库部署在docker当中,然后确保在docker当中启动好这些数据库以后再开始,这个是我们需要配置的内容,具体如何配置我也将会再后续的博客当中给出。
再上一篇我们讲过了RAG的基本原理,我们都需要知道的是,要想大模型对一些比较复杂的文件实现理解,并且提高大模型输出的准确性和效率的话,我们需要对这些文档进行加载,分割,然后嵌入,而这个嵌入的过程就是使用本地部署好的大模型对得到的向量数据进行嵌入向量数据库,所以我们首先要部署好本地嵌入模型,而我们如何去部署本地嵌入模型,这个其实很简单,我们只需要用到llama_index当中嵌入模型进行部署即可。和我们前面进行部署模型是一致的,使用也只需要settings然后点即可,十分的方便,下面就是本地嵌入模型的部署代码,我们首先需要创建一个
embeddings.py的文件,然后下面是对他的使用:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
def embed_model_local_bge_small(**kwargs):
embed_model=HuggingFaceEmbedding(
model_name="BAAI/bge-small-zh-v1.5",
cache_folder=r"../embed_cache",
**kwargs
)
return embed_model
通过上面那一段代码我们就实现好了对嵌入模型的部署。
在完善了些许RAG的流程以后我们需要直接开始连接postgresql数据库,现在我们需要在postgresql当中创建表,以下是创建表个数据库的源码:
CREATE TABLE users (
"id" UUID PRIMARY KEY,
"identifier" TEXT NOT NULL UNIQUE,
"metadata" JSONB NOT NULL,
"createdAt" TEXT
);
CREATE TABLE IF NOT EXISTS threads (
"id" UUID PRIMARY KEY,
"createdAt" TEXT,
"name" TEXT,
"userId" UUID,
"userIdentifier" TEXT,
"tags" TEXT[],
"metadata" JSONB,
FOREIGN KEY ("userId") REFERENCES users("id") ON DELETE CASCADE
);
CREATE TABLE IF NOT EXISTS steps (
"id" UUID PRIMARY KEY,
"name" TEXT NOT NULL,
"type" TEXT NOT NULL,
"threadId" UUID NOT NULL,
"parentId" UUID,
"disableFeedback" BOOLEAN NOT NULL DEFAULT true,
"streaming" BOOLEAN NOT NULL,
"waitForAnswer" BOOLEAN,
"isError" BOOLEAN,
"metadata" JSONB,
"tags" TEXT[],
"input" TEXT,
"output" TEXT,
"createdAt" TEXT,
"start" TEXT,
"end" TEXT,
"generation" JSONB,
"showInput" TEXT,
"language" TEXT,
"indent" INT
);
CREATE TABLE IF NOT EXISTS elements (
"id" UUID PRIMARY KEY,
"threadId" UUID,
"type" TEXT,
"url" TEXT,
"chainlitKey" TEXT,
"name" TEXT NOT NULL,
"display" TEXT,
"objectKey" TEXT,
"size" TEXT,
"page" INT,
"language" TEXT,
"forId" UUID,
"mime" TEXT
);
CREATE TABLE IF NOT EXISTS feedbacks (
"id" UUID PRIMARY KEY,
"forId" UUID NOT NULL,
"threadId" UUID NOT NULL,
"value" INT NOT NULL,
"comment" TEXT
);在创建好数据库和表以后我们开始使用chinlit连接数据库,连接数据库也很简单,我们需要在app.py文件当中使用以下这段代码以及chainlit特有的连接方式连接即可。
cl_data._data_layer = PostgreSQLDataLayer(
conninfo=os.environ["PG_CONNECTION_STRING"], # 使用PostgreSQL数据层
storage_provider=storage_client # 使用之前创建的存储客户端
)在写完这段代码以后我们就成功连接好数据库了。
现在我们直接启动app.py应该就可以看到历史记录已经出现了。
3.3上传文件的实现
上传文件比较重要的是我们应该如何去实现文件的识别,这里我给出了几种方案,最简单的肯定就是借助由相关能力的大模型进行调用然后去实现,第二种是使用别人的开源大模型进行本地部署实现(ocr),这里我们知识当作的demo的形式去实现,所以我们展示使用有相关能力的大模型去实现,这里我们还是去使用kimi,kimi提供了相关文件识别的APIkey我们直接调用即可十分的方便,这里我们直接去到kimi的官网。
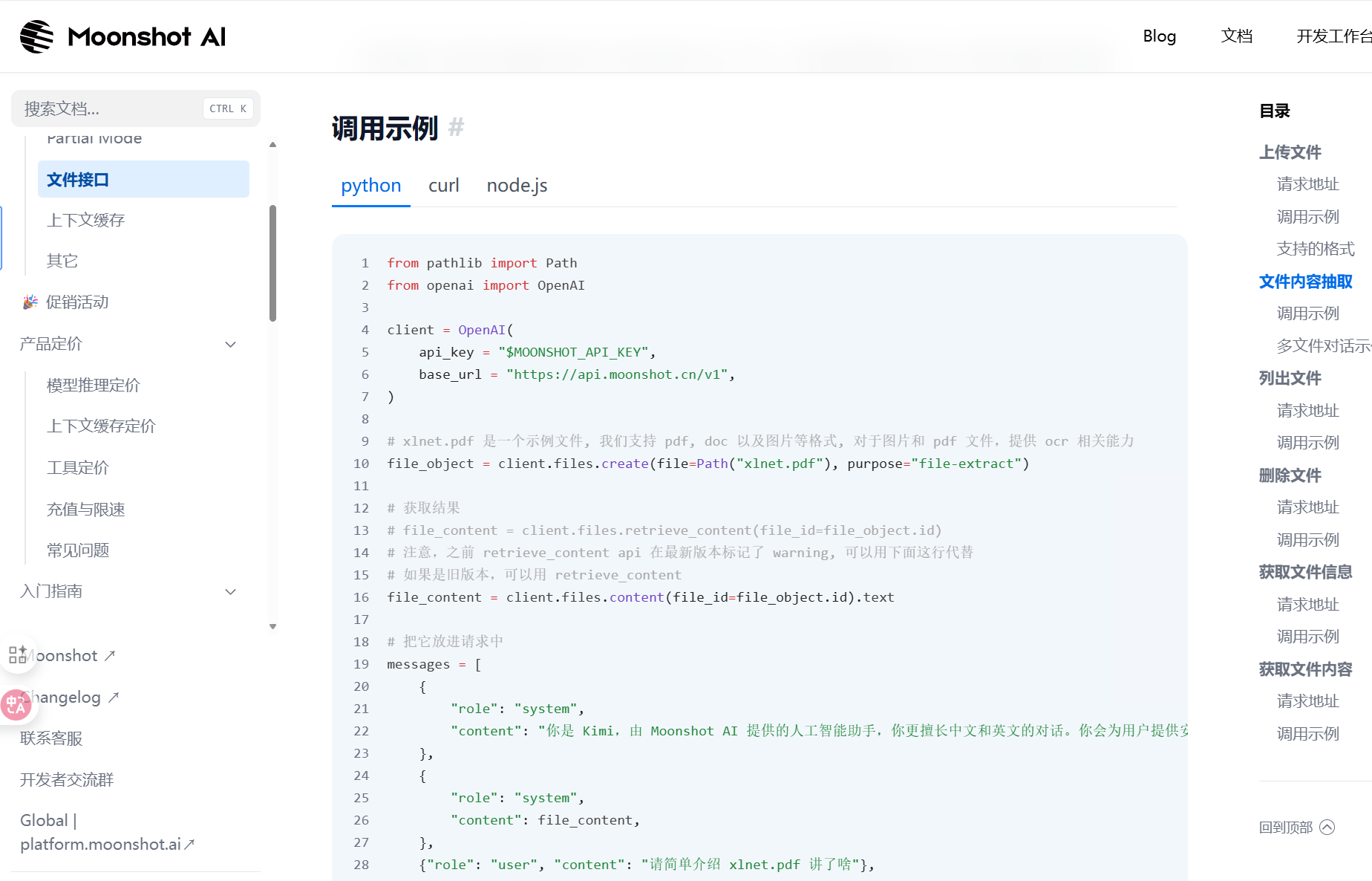
官方给出的代码如上,我们只需要复制粘贴即可,kimi的api我们前面已经实现成功,现在我直接给出api.py文件的源代码,大家有兴趣的可以自行理解。
# 导入chainlit库,用于构建和部署AI驱动的聊天应用
import os
import asyncio
from typing import List
import chainlit as cl
from chainlit.element import ElementBased
from dotenv import load_dotenv
# 导入基础设置类和简单的目录读取器
from llama_index.core import Settings, SimpleDirectoryReader
from llama_index.core.chat_engine import SimpleChatEngine
# 导入聊天模式类型
from llama_index.core.chat_engine.types import ChatMode
# 从embeddings模块中导入嵌入模型
from embeddings import embed_model_local_bge_small
# 导入deepseek_llm,这可能是一个自定义的语言模型接口
from llms import deepseek_llm, moonshot_llm
from rag_pro4.rag.base_rag import RAG
# 加载环境变量文件,以便在应用程序中使用这些变量
load_dotenv()
from rag_pro4.persistent.minio_storage_client import MinioStorageClient
from rag_pro4.persistent.postgresql_data_layer import PostgreSQLDataLayer
# 实现聊天数据与文件持久化
import chainlit.data as cl_data
# 创建一个Minio存储客户端实例,用于与Minio服务器进行通信
storage_client = MinioStorageClient()
# 初始化数据层实例,使用从环境变量中获取的连接字符串和之前创建的存储客户端
# 这里使用的是PostgreSQL数据层,它不仅负责数据的存储和检索,还通过存储客户端与Minio服务器交互,处理对象存储需求
cl_data._data_layer = PostgreSQLDataLayer(
conninfo=os.environ["PG_CONNECTION_STRING"], # 使用PostgreSQL数据层
storage_provider=storage_client # 使用之前创建的存储客户端
)
# 设置嵌入模型为本地的bge_small模型
Settings.embed_model = embed_model_local_bge_small()
# 设置语言模型为DeepSeek提供的模型
Settings.llm = deepseek_llm()
@cl.on_chat_start
async def start():
# 基于大模型直接创建聊天引擎
chat_engine = SimpleChatEngine.from_defaults()
# 在用户会话中设置聊天引擎,以便后续使用
cl.user_session.set("chat_engine", chat_engine)
# 发送欢迎消息给用户
await cl.Message(
author="Assistant", content="你好!我是 AI 助手。有什么可以帮助你的吗?"
).send()
@cl.on_message
async def main(message: cl.Message):
# 初始化文件列表,用于存储用户上传的文件路径
files = []
# 遍历用户上传的元素,筛选出文件和图片类型的元素
for element in message.elements:
# 检查元素是否为文件或图片类型,如果是,则将其路径添加到文件列表中
if isinstance(element, cl.File) or isinstance(element, cl.Image):
files.append(element.path)
# 如果有文件被上传,则进一步处理这些文件
if len(files) > 0:
# 使用SimpleDirectoryReader读取文件内容并加载数据
data = SimpleDirectoryReader(input_files=files).load_data()
# 创建或更新本地索引,以支持后续的查询和检索操作
# index = await RAG.create_index_local(data)
# 创建远程索引
index = await RAG.create_index_remote(data)
# 将索引转换为聊天引擎,以便在聊天模式下使用
chat_engine = index.as_chat_engine(chat_mode=ChatMode.CONTEXT)
# 在用户会话中设置聊天引擎,以便在后续的交互中使用
cl.user_session.set("chat_engine", chat_engine)
# 从用户会话中获取chat_engine
chat_engine = cl.user_session.get("chat_engine")
# 创建一个空的助理消息
msg = cl.Message(content="", author="Assistant")
# 使用chat_engine生成回复(带重试,处理429限流)
max_retries = 5
backoff_seconds = 1.0
last_error: Exception | None = None
for attempt in range(max_retries):
try:
res = await cl.make_async(chat_engine.stream_chat)(message.content)
for token in res.response_gen:
await msg.stream_token(token)
await msg.send()
last_error = None
break
except Exception as e:
err_text = str(e)
# 简单匹配429/限流错误,指数退避
if "429" in err_text or "rate_limit" in err_text or "RateLimit" in err_text:
await asyncio.sleep(backoff_seconds)
backoff_seconds *= 2
last_error = e
continue
else:
last_error = e
break
if last_error:
# 回退为非流式错误输出,避免静默失败
await msg.update(content=f"发生错误:{last_error}")
# 登录认证
@cl.password_auth_callback
def auth_callback(username: str, password: str):
"""
密码认证回调函数,用于验证用户凭据并返回用户对象
参数:
username (str): 用户名
password (str): 密码
返回:
cl.User: 认证成功时返回用户对象,包含用户标识和元数据
None: 认证失败时返回None
"""
# 验证用户名和密码是否匹配预设的管理员凭据
if (username, password) == ("admin", "admin123"):
return cl.User(
identifier="admin", # 用户标识
metadata={
"role": "admin", # 用户角色
"provider": "credentials" # 认证提供者,默认为密码
} # 用户元数据
)
else:
return None
# 查看PDF文件
async def view_pdf(elements: List[ElementBased]):
"""
查看PDF文件
此函数接收一个元素列表,从中筛选出名称以.pdf结尾的元素,
并创建Pdf对象用于显示。它将这些PDF文件以消息的形式发送出来,
并在消息内容中包含PDF文件的名称。
参数:
- elements: List[ElementBased] -- 一个包含各种元素的列表,其中可能包括PDF文件
返回:
此函数没有返回值,但会发送包含PDF文件和它们名称的消息
"""
# 初始化两个空列表,分别用于存储Pdf对象和PDF文件名
files = []
contents = []
# 遍历元素列表,寻找名称以.pdf结尾的元素
for element in elements:
if element.name.endswith(".pdf"):
# 为每个找到的PDF文件创建Pdf对象,并添加到files列表中
pdf = cl.Pdf(name=element.name, display="side", path=element.path)
files.append(pdf)
# 将PDF文件名添加到contents列表中
contents.append(element.name)
# 如果没有找到任何PDF文件,则不执行任何操作直接返回
if len(files) == 0:
return
# 构造消息内容,包含所有PDF文件名,并将消息和PDF文件作为元素发送
await cl.Message(content=f"查看PDF文件:" + ",".join(contents), elements=files).send()
至此我们上传文件的功能也已经实现成功,还可以实现文件理解,大模型可以对文件的内容进行问答。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)