SoFTA——如何让人形在餐厅给顾客上一杯啤酒:慢-快双智能体框架,上半身高频执行精细操作,下半身低频稳步行走
SoFTA论文提出慢-快双智能体框架解决人形机器人行走时末端执行器稳定控制难题。该框架将上半身(100Hz)和下半身(50Hz)控制解耦,分别针对精细操作和步态鲁棒性设计独立奖励机制。实验显示该方法能将末端执行器加速度降低50-80%,达到接近人类水平的2m/s²以下,使端水杯等精细任务成为可能。这种差异化控制策略有效解决了行走与操作在时间尺度和控制要求上的根本性矛盾。
前言
姚博士在我司举办的人形二次开发线下营中,讲行走操作时,提到了SoFTA这篇论文
我一细看,SoFTA论文说,尽管仿人机器人在各种炫目的演示中频频亮相——如跳舞、递送包裹、穿越崎岖地形——但在行走过程中实现精细化控制仍是一大挑战
这话说得 可是深得我个人之意啊
总之,行走中干活不容易,尤其是在行走时稳定携带装满液体的末端执行器EE,由于任务特性存在根本性差异,这一问题远未解决:行走需要慢时域的鲁棒控制,而EE的稳定则要求快速且高精度的修正
而让机器人干活,是我司作为具身开发公司的第一目标,无论是坐着干活,还是行走中干活,故对此类问题高度关注
- 为了解决这一问题,来自的研究者提出了SoFTA(Slow-Fast Two-Agent),一种慢-快双智能体框架,将上半身与下半身的控制解耦,分别由不同频率、不同奖励机制的智能体独立控制
- 即SoFTA以上半身100 Hz的频率执行动作,实现高精度的EE控制;下半身以50 Hz的频率执行动作,确保步态的鲁棒性
第一部分 SoFTA:学习温和的人形机器人行走与末端执行器稳定控制
1.1 引言与相关工作
1.1.1 引言
近年来,运动能力[1–11]和操作能力[12–16]的进步推动了人形机器人性能接近人类水平[17]。然而,有一项关键能力仍然研究不足:在行走过程中对末端执行器EE的精细稳定控制。这一能力对于与物体进行安全且精确的物理交互至关重要,例如递送一杯水或录制稳定的视频,但当前的人形机器人在这方面表现不佳
例如,Unitree G1 默认控制器在原地敲击时,其末端执行器的平均加速度约为 5m/s²,超过人类水平的 10 倍,导致过度抖动,使精细任务变得不可行
这一根本性的性能差距源自于末端执行器EE稳定与行走任务在任务特性方面的差异,无论是在任务目标还是动态特性层面
- 在任务目标层面
行走需要具备可通过性,这自然引入了非准静态动态特性
相比之下,EE 稳定则要求底座运动最小,以维持精确性 - 在动态层面
下肢行走属于“慢”动态,只能通过相对较大时间尺度上的离散足部接触来控制。地面接触的特性使其更容易受到仿真到现实sim-to-real差距的影响,因此对噪声和扰动的鲁棒性要求更高
而 EE 控制则涉及“快”动态,手臂为全驱动且更易于控制,能够产生连续的力矩,实现快速且精确的修正
为弥合这一差距,来自CMU的研究者提出了SoFTA——一种慢-快双智能体强化学习(RL)框架,该框架将上半身和下半身的动作与价值空间解耦
- 其paper地址为:Hold My Beer: Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control
其对应的作者包括
Yitang Li1, Yuanhang Zhang, Wenli Xiao, Chaoyi Pan,Haoyang Weng1
Guanqi He, Tairan He, Guanya Shi - 其项目地址为:lecar-lab.github.io/SoFTA
其GitHub地址为:github.com/LeCAR-Lab/SoFTA
具体而言,此设计允许不同的执行频率和奖励结构:
- 上半身智能体以高频率动作,实现精确的末端执行器EE控制及补偿行为
- 而下半身智能体则以较低频率优先实现稳健的行走
通过这种解耦,SoFTA促进了稳定的训练与全身协调,从而实现了快速且精确的末端执行器控制,同时保证了稳健的运动能力
如图1所示

他们的系统在末端执行器加速度方面相较于基线方法实现了50–80%的降低
SoFTA能够在多样化运动中将末端执行器加速度控制在2m/s²以下,这一表现更接近于人类水平的稳定性,使得如端咖啡或稳定视频录制等任务成为可能
1.1.2 相关工作
// 待更
1.2 SoFTA:用于学习稳定末端执行器控制和鲁棒行走的算法
1.2.1 问题描述
首先,对于观测与动作,作者的目标是控制一个人形机器人,使其末端执行器稳定在目标位置,同时还能够遵循行走指令
作者将该问题表述为一个目标条件强化学习任务,其中
- 策略
被训练以输出动作
,表示目标关节位置
- 本体感输入
包括
关节位置
关节速度
躯干角速度
投影重力向量
和过去的动作的5 步历史
- 目标状态
包含
目标躯干线速度
目标偏航角速度
期望的基座朝向,
(包括一个二元站立/行走指令和步态频率)
- 以及
编码了末端执行器指令
其中,表示潜在末端执行器的数量,每个末端执行器有一个5 维指令,分别指定其是否被激活用于稳定、本地坐标系下的x 和y 坐标、全局坐标系下的z 坐标,以及跟踪容差σ
其次,对于用于稳定末端执行器控制的奖励设计,作者使用PPO [57] 来最大化累计折扣奖励
定义了若干奖励 以实现稳定的末端执行器控制:
- 惩罚较大的线性/角加速度
- 鼓励接近零的线性/角加速度
- 惩罚末端执行器坐标系下的重力倾斜
.
表示线加速度
表示角加速度
为指数型奖励缩放因子
表示旋转矩阵,g表示重力向量,
表示投影到xy 平面
最后,对于任务特征
稳定末端执行器控制与鲁棒行走在任务目标和动力学方面本质上是不同的任务
在任务目标层面,末端执行器的控制需要极高的稳定性,因此要求基座尽可能保持静止;而移动则需要适应不同的步态和动量变化。精确的末端执行器控制受益于细致、连续的高分辨率奖励,而移动则更适合长期、注重鲁棒性的奖励
鉴于这些差异,使用单一的评价器来汇总所有奖励信号可能并不是最有效的方法
在动力学层面,运动由离散的地面接触力控制,并由于其较长的时间尺度而表现出“较慢”的动力学特性。相比之下,上半身具有“较快”的动力学反应并且通常通过全驱动机械臂更易于控制,从而能够实现更激进和更快速的控制策略
鉴于更高的控制频率往往会提高系统的灵敏度,并加剧仿真到现实的差距[58–60,19],而较低的频率虽然精度较低,但更易于部署且更具鲁棒性,因此根据实际情况调节控制速率是有利的
1.2.2 SoFTA:慢-快双智能体框架
首先,是慢-快双智能体框架设计。鉴于这些不同的任务特性,作者提出了SoFTA,这是一种双智能体框架,每个智能体以不同的控制频率独立控制机器人自由度的非重叠子集(见图2)
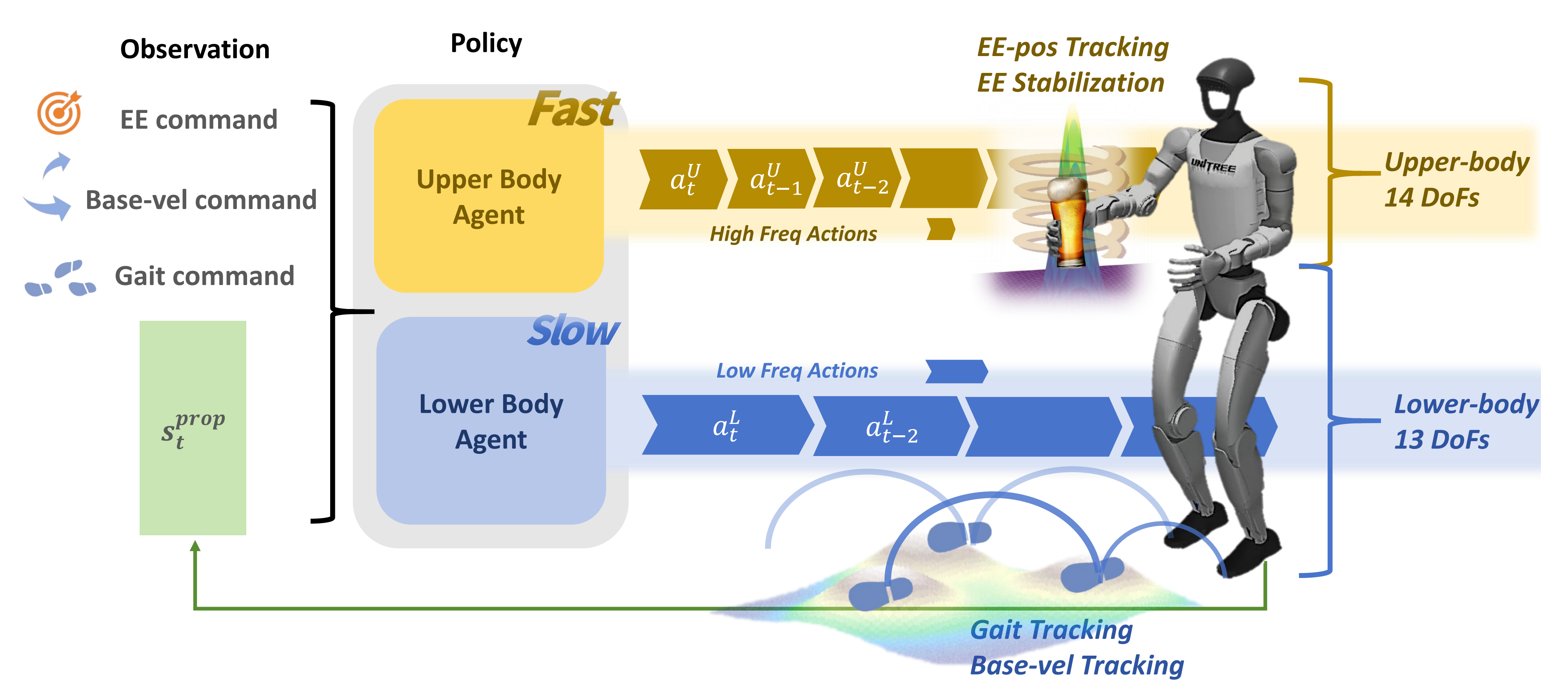
SoFTA中的两个智能体共享全身观测信息,以促进协调行为,同时允许各自专精
- 具体而言,上半身智能体以高频率运行,控制14个手臂关节,从而实现末端执行器的精确和快速调整以保持稳定
- 而下半身智能体以较低的频率运行,管理腿部和腰部,以确保行走和保持平衡的稳定性
这种不对称的控制频率与步态周期较长的特征时间尺度相匹配,同时满足稳定任务所需的快速、精确运动
其次,使用独立奖励组训练SoFTA。由于上半身与下半身任务的控制动态和时间尺度不同,其奖励信号本质上是异质的,这可能导致相互干扰并造成次优学习
- 为改善奖励归因[61–64],作者将整体奖励分解为两个语义对齐的组成部分,分别针对各自的PPO智能体进行定制。此分解为每个智能体提供了更有针对性的反馈,避免了任何智能体的过载,并促进了公平协作
- 且为了进一步鼓励协作行为和持续任务执行,作者在两个奖励流中都包含了终止奖励
尽管两个智能体共享同一观测空间,但它们分别使用独立的actor和critic网络,且参数不共享。更多细节见附录A.1
// 待更

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)