一文彻底讲透:AI大模型应用架构全解析(1)
一文彻底讲透:AI大模型应用架构全解析(1)
引言
大模型应用架构是连接基础模型能力与实际业务场景的关键桥梁,它通过系统化的设计,将大模型的潜力转化为可落地的解决方案。现代大模型应用架构已形成完整的分层体系,从数据接入到应用落地,各层紧密衔接,共同支撑大模型在多行业场景中的规模化应用。这种架构设计不仅提高了系统的可扩展性和稳定性,也增强了模型在不同业务场景中的适应性和价值输出能力。本文将从数据层、预处理层、知识与模型中台层、模型层与训练优化层、应用层及技术支撑层六个维度,全面剖析大模型应用架构的组成与功能。
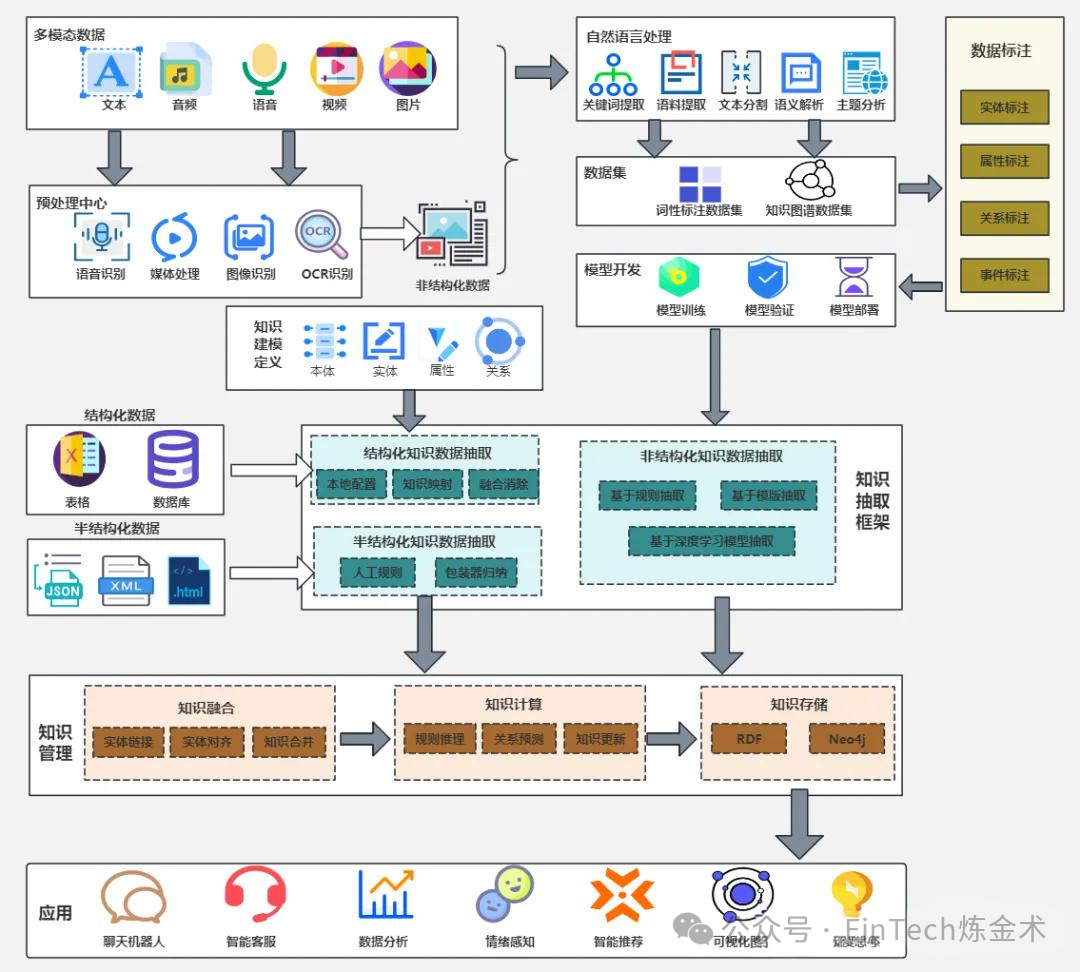
一、数据层与预处理层:多模态数据的标准化处理
数据层与预处理层构成了大模型应用架构的"原料基地",负责原始数据的收集、清洗和转换,为后续模型处理提供高质量输入。
1. 多模态数据接入层
多模态数据接入层是架构的底层入口,负责整合文本、音频、视频、图像等多种数据源。该层通过接入网关与消息总线机制,将数据统一接入平台并标注时间戳与来源标签,为后续处理提供完整上下文 。例如,在客服场景中,该层可能同时处理用户输入的文字咨询、语音留言和上传的图片凭证;在医疗场景中,则需要整合电子病历文本、医学影像和患者语音描述等多模态信息。
2. 预处理与特征提取层
预处理与特征提取层则对原始数据进行标准化、清洗和转换,确保数据质量。该层包含多种技术手段:
- 语音转文本:调用自动语音识别(ASR)服务,将音频转换为可读文本,如客服对话中的语音留言转文字。
- 视频帧分离:关键帧抽取与场景切割,使模型能聚焦画面中最重要的内容,如监控视频中的异常行为识别。
- OCR与图像识别:识别图表、手写体与嵌入式文字,将视觉信息转成结构化文本,如医疗报告中的手写处方提取。
- 分词与句法分析:进行中文分词、词性标注和依存句法分析,以便下游模型更好理解语义。
- 多模态数据对齐:确保不同模态数据(如文本、图像)在语义空间中的一致性,便于模型联合处理。
该层的核心挑战在于如何处理数据噪声、实现格式统一、保障实时性及满足隐私保护要求 。例如,在金融场景中,需确保客户数据在预处理阶段完成脱敏;在医疗场景中,需处理医学影像与文本描述的时空对齐问题。
二、知识与模型中台层:能力聚合与复用
知识与模型中台层是大模型应用架构的"能力中枢",负责将大模型与行业知识、业务规则相结合,提升模型在特定场景中的专业性和可靠性。
1. 知识管理子系统
知识管理子系统构建了领域知识的结构化存储与检索能力:
- 本体定义:预先规划"实体-属性-关系"体系,形成领域本体 ,如医疗领域的疾病-症状-治疗方案知识图谱。
- 知识库存储:采用图数据库(如Neo4j)与RDF三元组库并行存储,兼顾灵活推理与标准化语义。
- 检索服务:结合向量化查询与精确匹配,既能模糊搜索,又能精准定位实体关系。
- 知识更新机制:通过持续学习框架,动态更新知识库内容,解决信息过时问题。
2. 模型管理子系统
模型管理子系统则实现了模型的版本控制与优化:
- 模型注册与版本控制:记录模型训练参数、性能指标及应用场景,支持版本回滚与对比分析。
- 模型性能评估:建立多维度评估体系,包括推理速度、准确率、资源消耗等指标。
- 模型适配与优化:针对不同场景需求,对模型进行轻量化、量化或参数高效调整 。
3. 流程引擎
流程引擎负责管理多模型协作与任务执行:
- 工作流管理:定义模型调用顺序、参数传递规则及异常处理策略。
- 任务协调:优化资源分配,确保任务间的依赖关系得到满足。
- 流程监控:实时跟踪流程执行状态,提供可视化监控与告警。
4. 安全与合规机制
安全与合规机制保障了系统的可靠性与合规性:
- 数据安全:访问控制、数据加密、权限管理等技术确保数据操作安全。
- 隐私保护:数据脱敏、匿名化、差分隐私等技术保护用户隐私。
- 内容安全:通过内容过滤、价值观对齐等技术确保模型输出符合伦理与法规要求。
该层的核心价值在于实现知识与模型的复用,避免重复开发。例如,某银行在构建智能客服系统时,可复用已有的金融知识图谱和风控模型,大幅降低开发成本。
更多内容请看下回。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)