初学AI超级智能体SpringAI + RAG + MCP(第一天)
本文介绍了初学AI智能体时使用SpringAI框架实现检索增强生成(RAG)的入门方法。主要内容包括:1) RAG工作流程(文档收集、向量转换、检索增强);2) 使用Markdown格式加载文档资源;3) 通过SimpleVectorStore进行向量存储;4) 利用QuestionAnswerAdvisor实现检索增强问答。文章详细展示了Java代码实现过程,包括文档加载、向量转换和问答增强等关
·
初学AI超级智能体SpringAI + RAG + MCP(第一天)
入门AI智能体小白:零基础入门智能体知识框架
RAG(检索增强生成)
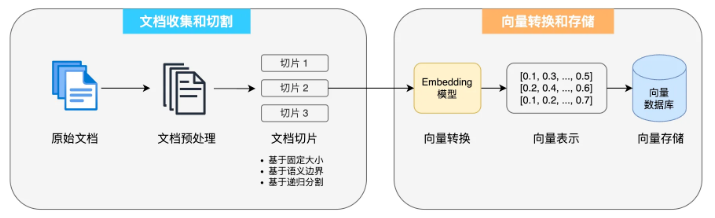
RAG工作流程
- 文档的收集和切割划分;
- 向量存储与转换(利用Embedding模型)
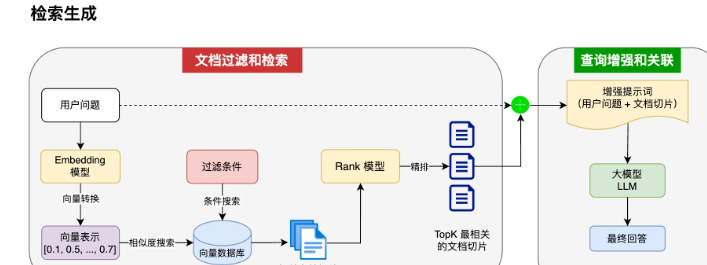
- 文档过滤与检索
- 文档增强与关联
MarkDown 结构化文档格式 加载文档
- Spring 参考官方文档:英文版;
- Spring Alibaba 参考官方文档:中文版;
- 利用MarkDown结构化文档格式进行相关文档创建并收集;
@Component
@Slf4j
class RagDocumentLoader {
private final ResourcePatternResolver resourcePatternResolver;
RagDocumentLoader(ResourcePatternResolver resourcePatternResolver) {
this.resourcePatternResolver = resourcePatternResolver;
}
public List<Document> loadMarkdowns() {
List<Document> allDocuments = new ArrayList<>();
try {
Resource[] resources = resourcePatternResolver.getResources("classpath:document/*.md");
for (Resource resource : resources) {
String fileName = resource.getFilename();
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", fileName)
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
allDocuments.addAll(reader.get());
}
} catch (IOException e) {
log.error("Markdown 文档加载失败", e);
}
return allDocuments;
}
}
- 利用 ResourcePatternResolver 多文档读取的优势 进行从资源路径下获取多个文件资源;
Resource[] resources = resourcePatternResolver.getResources("classpath:document/*.md");
- 利用 AdditionMetadata 可自定义Document文档数据
String fileName = resource.getFilename();
.withAdditionalMetadata("filename", fileName)
SimpleVectorStore 简单向量转换存储
- 首先自动注入 自定义的文档加载对象
@Resource
private RagDocumentLoader ragDocumentLoader;
- 自定义构造VectorStore返回类型的对象进行向量转换存储
@Configuration
public class RagVectorStoreConfig {
@Resource
private RagDocumentLoader ragDocumentLoader;
@Bean
VectorStore RagVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel)
.build();
// 加载文档
List<Document> documents = ragDocumentLoader.loadMarkdowns();
simpleVectorStore.add(documents);
return simpleVectorStore;
}
}
- 引入Spring Ai的Embedding模型包
检索增强
Spring AI 通过Advisor 特性提供了开箱即用的RAG功能。主要是QuestionAnswerAdvisor问答拦截器和RetrievalAugmentationAdvisor 检索增强拦截器 ,前者更简单易用、后者更灵活强大
- 使用QuestionAnswerAdvisor问答拦截器,新增和RAG知识库进行对话,采用MessageChatMemoryAdvisor对话记忆方法进行实现
下期预告:我们将推出支持 “多轮对话记忆功能” 的新版本
public MessageChat(ChatModel dashscopeChatModel) {
ChatMemory chatMemory = new InMemoryChatMemory();
chatClient = ChatClient.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory)
)
.build();
}
}
-
会话调用过程:加载文档信息–>通过VectorAdvisor进行向量转换存储–>利用QuestionAnswerAdvisor进行检索增强 这些文档被切块、通过嵌入模型(Embedding Model)转换为高维向量。检索时,用户的查询也会被转换成向量,并通过相似度计算(如余弦相似度)快速找到最相关的文档块
-
最后通过相关链式调用处理方法,进行将最佳匹配用户所问的答案组合好的增强提示发送给配置好的大语言模型,进行处理输出
@Resource
private VectorStore RagVectorStore;
public String doChatWithRag(String message, String chatId) {
ChatResponse chatResponse = chatClient
.prompt()
.user(message)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))
// 开启日志,便于观察效果
.advisors(new MyLoggerAdvisor())
// 应用知识库问答
.advisors(new QuestionAnswerAdvisor(RagVectorStore))
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
log.info("content: {}", content);
return content;
}
RAG(检索增强生成)— 项目总结
实现基于 RAG 问答知识步骤如下
1.通过构建 文档 资源配置类(RagDocumentLoader) 获取相关 MarkDown文档内容
2.利用 SimpleVectorStore 进行对 文档内容进行 向量转换存储
3.通过 QuestionAnswerAdvisor 对相关内容进行检索增强

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)