【AI论文】ScaleCUA:借助跨平台数据扩展开源计算机使用代理(系统/工具)规模
视觉语言模型(Vision-Language Models,VLMs)使得能够自主操作图形用户界面(Graphical User Interfaces,GUIs)的计算机使用智能体(Computer Use Agents,CUAs)成为可能,展现出巨大潜力,然而,由于缺乏大规模、开源的计算机使用数据和基础模型,相关进展受到限制。在本研究中,我们推出了ScaleCUA,这是朝着扩大开源计算机使用智能
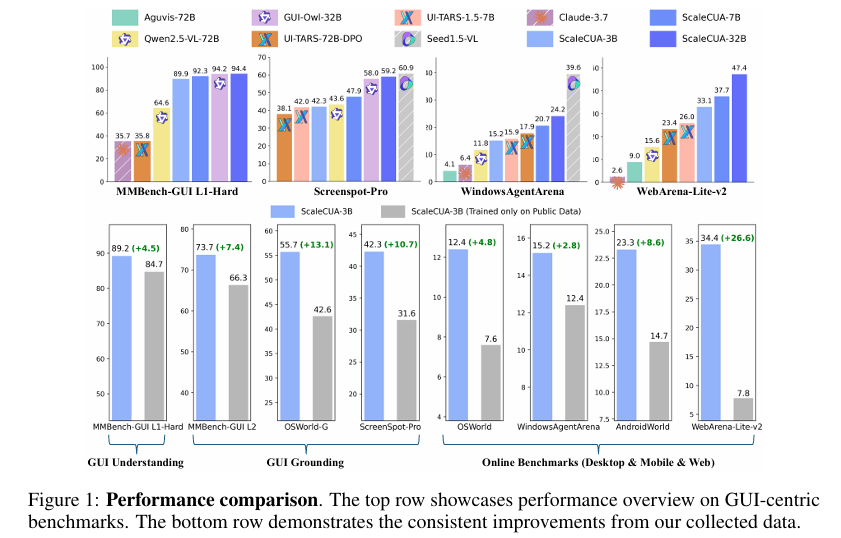
摘要:视觉语言模型(Vision-Language Models,VLMs)使得能够自主操作图形用户界面(Graphical User Interfaces,GUIs)的计算机使用智能体(Computer Use Agents,CUAs)成为可能,展现出巨大潜力,然而,由于缺乏大规模、开源的计算机使用数据和基础模型,相关进展受到限制。在本研究中,我们推出了ScaleCUA,这是朝着扩大开源计算机使用智能体规模迈出的一步。它提供了一个涵盖6种操作系统和3个任务领域的大规模数据集,该数据集是通过一个将自动化智能体与人类专家相结合的闭环流程构建而成。基于这一大规模数据集进行训练后,ScaleCUA能够跨平台无缝运行。具体而言,与基线相比,它取得了显著提升(WebArena-Lite-v2上提升26.6,ScreenSpot-Pro上提升10.7),并创造了新的最优成果(MMBench-GUI L1-Hard上达94.4%,OSWorld-G上达60.6%,WebArena-Lite-v2上达47.4%)。这些发现凸显了数据驱动型扩展对通用计算机使用智能体的强大作用。我们将公开数据、模型和代码,以推动未来的研究:https://github.com/OpenGVLab/ScaleCUA。Huggingface链接:Paper page,论文链接:2509.15221
研究背景和目的
研究背景:
随着人工智能技术的飞速发展,视觉语言模型(Vision-Language Models, VLMs)在计算机视觉和自然语言处理的交叉领域展现出了巨大的潜力。VLMs通过结合视觉和语言信息,使得计算机能够理解和操作图形用户界面(Graphical User Interface, GUI),从而实现了计算机使用代理(Computer Use Agents, CUAs)的自动化操作。然而,尽管VLMs在图像文本对(image-text pairs)方面拥有丰富的互联网资源,但在计算机使用数据,特别是操作轨迹(operation trajectories)方面,数据却极为稀缺且获取成本高昂。
现有的计算机使用代理(CUAs)研究往往依赖于闭源模型或专有数据集,限制了其在大规模开放场景中的应用。同时,由于软件、网页和操作系统更新迅速,现有的操作轨迹数据很快会过时,进一步限制了CUAs的扩展性和泛化能力。为了解决这些问题,研究团队提出了一种新的方法,旨在通过构建大规模、跨平台的GUI训练语料库,并开发一系列可扩展的、通用的基础模型,来推动计算机使用代理的发展。
研究目的:
本研究的主要目的是:
- 构建大规模跨平台GUI训练语料库:通过自动化代理和人类专家的协同工作,收集涵盖六个主要操作系统(Windows、macOS、Linux、Android、iOS和Web)和三个任务领域(GUI理解、GUI定位和任务完成)的大规模GUI训练数据。
- 开发可扩展的、通用的基础模型:基于Qwen2.5-VL模型,训练一系列基础代理模型(ScaleCUA),这些模型能够统一感知、推理和行动,并支持灵活的推理范式,包括定位模式(Grounding Mode)、直接行动模式(Direct Action Mode)和推理行动模式(Reasoned Action Mode)。
- 提升计算机使用代理的性能:通过在大规模跨平台数据集上进行训练,使ScaleCUA模型能够在不同平台上无缝操作,并在多个GUI代理基准测试中实现最先进的性能。
研究方法
1. 跨平台交互数据管道:
研究团队设计了一个跨平台交互数据管道,该管道由两个协同循环组成:
- 代理-环境交互循环:自动化代理与各种GUI环境进行交互,收集屏幕状态观察、元数据(如可访问性树、XLM、DOM结构等)和原始轨迹。
- 代理-人类混合数据采集循环:人类专家对自动化代理收集的数据进行注释,确保数据的覆盖范围和质量。
2. 统一行动空间:
为了在不同平台上实现一致且高效的行为建模,研究团队设计了一个统一的行动空间,涵盖了三个主要环境(桌面、浏览器和移动设备)的核心操作。这些操作包括平台特定的操作(如移动设备上的长按、打开应用等)和跨平台的通用操作(如点击、写入等)。
3. 数据集构建:
- GUI理解:包括471K个区域描述、OCR和布局理解等任务,以促进对界面的精细感知和推理。
- GUI定位:支持1710万条训练样本,用于更精确的UI元素定位。
- 任务完成:提供超过15K弱语义轨迹和4K高层次目标导向轨迹,以支持端到端的任务自动化。
4. 高级VLMs的应用:
- 基础模型选择:以Qwen2.5-VL作为基础模型,因其强大的多模态理解能力和可扩展性。
- 数据增强:通过数据增强和弱语义轨迹的引入,提升模型的泛化能力和鲁棒性。
5. 模型训练与优化:使用先进的技术(如LoRA)对基础模型进行微调,以适应不同资源和计算环境的需求。
6. 评估与迭代:
- 多维度评估:不仅关注模型在基准测试上的表现,还通过在线评估、用户反馈等多种方式对模型进行全面评估。
- 持续迭代:根据评估结果和用户反馈,不断优化模型性能和用户体验。
研究结果
1. 模型性能提升:
- 跨平台能力:ScaleCUA模型在多个平台上展现了强大的跨平台能力,能够在不同操作系统和设备上无缝操作。
- 任务完成度:在多个GUI交互基准测试中,ScaleCUA模型显著提升了任务完成的准确性和效率,特别是在复杂任务中表现尤为突出。
- 多模态评估:在MMBench-GUI L1-Hard等基准测试中,ScaleCUA-32B模型取得了显著进步,特别是在需要复杂推理和规划的任务中。
2. 数据集构建:
- 大规模数据集:通过结合自动化代理和人类专家的工作,构建了涵盖多个任务领域的综合训练集,支持多种任务类型(如GUI理解、GUI grounding和任务完成)。
- 评估指标:在多个基准测试集上设置新的state-of-the-art结果,尤其是在WebArena-Lite-v2和ScreenSpot-Pro等基准测试中取得显著提升,展示了ScaleCUA模型在阿拉伯语、英语和网页上的卓越表现。
研究局限
- 数据稀缺性:尽管本研究构建了大规模的数据集,但受限于数据收集的复杂性和成本,某些高质量指令数据的稀缺性仍然是一个挑战。例如,特定文化背景下的复杂情感理解数据可能不足。
- 数据多样性:尽管构建了大规模的阿拉伯语指令遵循语料库,但某些特定领域或文化背景下的高质量指令数据可能仍然不足,这可能影响模型的泛化能力。
- 模型局限性:
数据规模和多样性的限制:尽管构建了大规模的跨平台数据集,但阿拉伯语等特定语言环境下的高质量指令数据仍显不足,可能影响模型在某些任务上的表现。
- 推理能力有限:尽管VLMs在数学推理等复杂任务上展现出一定能力,但相比专门针对复杂推理任务,其表现仍有提升空间。这需要进一步优化模型的推理能力和复杂任务处理能力。。
未来研究方向
1. 增强数据多样性和覆盖范围:
- 继续收集和构建更多领域和场景的阿拉伯语指令数据,特别是那些当前数据集中缺失的部分,以提高模型的适应性和实用性。
- 引入更多实际应用场景的数据和评估指标,确保模型能够持续满足用户需求。
2. 优化模型规模和效率:
- 探索更高效的模型架构:探索更高效的模型架构和训练策略:
- 通过引入更高效的模型架构和训练策略**:
-例如,通过模型剪枝叶和优化模型规模,以在更大规模模型(此处原文可能有误,需进一步研究如何平衡模型规模和效率**: - 3. 加强方言和语体适应性**:
- 针对阿拉伯语的方言和语体多样性,开发专门的方言识别和适应模块。
- 4. 强化跨语言迁移学习**:
- 利用跨语言迁移学习技术,将在其他语言上学习到的知识迁移到阿拉伯语模型中。通过共享底层表示和参数,提高模型在不同方言和语体上的表现。
- 5. 持续评估和反馈循环**:
- 建立一个持续的评估和反馈循环系统,定期评估模型在真实场景下的表现,确保模型能够持续满足用户需求。
6. 促进社区参与和反馈机制:
- 鼓励用户参与模型评估和反馈,收集用户对模型性能的反馈,为模型的持续优化提供依据。
通过引入更多实际应用场景的数据和评估指标,确保模型能够持续满足用户需求。
7. 关注伦理和社会影响:
- 在模型开发和部署过程中,关注数据隐私、算法偏见等伦理问题,确保模型应用符合伦理规范。
- 评估模型可能带来的社会影响,如就业影响、信息茧房效应等,确保技术发展与社会福祉相协调。
未来研究方向
- 深化数据收集与标注:
- 继续扩大数据收集范围,特别是针对阿拉伯语及其方言的数据,确保数据的多样性和覆盖性。
- 引入更先进的标注技术,如众包标注、模型辅助标注等,提高数据标注的效率和质量。
- 探索更多先进的模型架构和训练策略,如基于Transformer的变体或混合架构,以进一步提高模型性能和效率。
- 加强模型对复杂任务和长序列任务的处理能力,如通过引入更先进的推理机制或记忆机制。
- 加强跨语言迁移学习研究,利用在其他语言上学习到的知识迁移到阿拉伯语模型中,提高模型在阿拉伯语上的表现。
- 持续关注并适应阿拉伯语及其方言的最新发展,确保模型能够跟上语言演变的步伐。
未来研究方向(续)
8. 探索多模态学习与视觉语言模型的融合:
- 结合视觉信息,开发能够同时处理视觉和语言信息的多模态模型,以提高模型在复杂场景下的理解和操作能力。
- 利用视觉语言模型进行场景感知和推理,实现更高级的自动化任务,如基于图像或视频的指令遵循和操作。
9. 强化模型的可解释性和用户交互:
- 提高模型的可解释性,使用户能够理解模型的决策过程,增强用户对模型的信任度。
- 开发用户友好的交互界面,允许用户通过自然语言与模型进行交互,提高用户体验。
- 引入用户反馈机制,允许用户对模型的操作进行反馈,以便模型能够根据用户反馈进行迭代优化。
10. 跨语言与跨文化研究:
- 探索阿拉伯语与其他语言的跨语言模型,研究不同语言之间的迁移学习和知识共享。
- 考虑文化差异和语言习惯,优化模型在不同阿拉伯语地区的表现,确保模型的全球适用性。
11. 强化模型的安全性和鲁棒性:
- 研究模型在面对对抗性攻击时的鲁棒性,确保模型在面对潜在威胁时的稳定性和安全性。
- 引入对抗性训练技术,提高模型在面对对抗性样本时的鲁棒性,防止模型被恶意利用。
- 开发模型解释和调试工具,帮助研究人员和开发者更好地理解和调试模型行为。
12. 推动产学研合作:
- 与阿拉伯语语言学家、教育机构和社会团体合作,共同推动阿拉伯语NLP技术的发展和应用。
- 参与标准制定和最佳实践分享,促进阿拉伯语NLP社区的标准化和规范化。
13. 持续监测与评估:
- 建立一个持续续的模型评估和反馈系统,定期评估模型在真实场景下的表现,并根据用户反馈进行迭代优化。
- 定期发布模型性能报告,向研究社区和潜在用户透明化模型性能,增强用户对模型的信任度。
13. 加强模型可解释性与安全性:
- 开发模型可解释性工具,帮助用户理解模型决策过程,提高模型透明度。
- 通过可视化工具展示模型决策过程,帮助用户理解模型行为。
总结
本研究通过构建大规模跨平台GUI训练语料库和统一动作空间,开发了ScaleCUA系列模型,并在多个基准测试中取得了显著成果。未来研究可进一步扩展数据规模、提升模型性能,并探索更广泛的应用场景和任务类型。同时,研究也指出了当前工作的局限性,并为未来研究提供了多个方向,包括扩展数据规模、改进模型架构、增强跨语言适应性等。通过持续的研究和优化,有望进一步提升计算机使用代理的自动化水平和实用性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献147条内容
已为社区贡献147条内容

所有评论(0)