Hadoop完全分布式集群环境的搭建
本次实验基于三节点(主节点elaine,从节点hadoop01/02)搭建Hadoop 3.3.0完全分布式集群。实验步骤包括:1)克隆主机并修改主机名;2)安装net-tools获取IP;3)配置网络映射;4)设置SSH免密登录;5)配置Hadoop核心文件(hadoop-env.sh、core-site.xml等),设置HDFS/YARN参数;6)修改workers文件指定节点。通过分步配置实
·
前言:
- 本次实验开始前应做好主节点Hadoop安装,详情移步
系统配置:
- 本次实验elaine为主节点,hadoop01和hadoop02为从节点,hadoop版本为3.3.0,jdk版本为1.8,操作系统类型:Linux,操作系统发行版:CentOS7(64位)
内容原理
- Hadoop完全分布式配置在3台计算机节点的情况下,对Hadoop的分布式存储和计算进行模拟安装和配置。通过在计算机主节点上解压Hadoop安装压缩后,然后进行Hadoop相关文件配置,再分发给另外2台从节点,完成Hadoop集群搭建,并实现对数据存储和计算的测试支持。
实验过程与分析
- 1、克隆两个主机,并修改主机名为(hadoop01和hadoop02)
su - (切换超级用户)


vi /etc/hostname(编辑主机名文件)


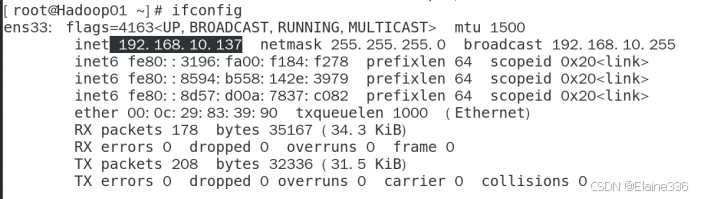
- 2、切换root用户,安装net-tools软件包,并查询各个主机的IP地址,以下命令在各个主机均执行
su -
yum install -y net-tools
ifconfig


- 3、进行linux网络配置
vi /etc/hosts(编辑主机名IP文件,映射到 IP 地址)
- 将以下内容分别追加复制在三个主机的etc/hosts文件
- [IP地址+主机名]

- 4、在所有主机进行SSH登录设置
ssh -keygen -t rsa(生成RSA类型的密钥对)
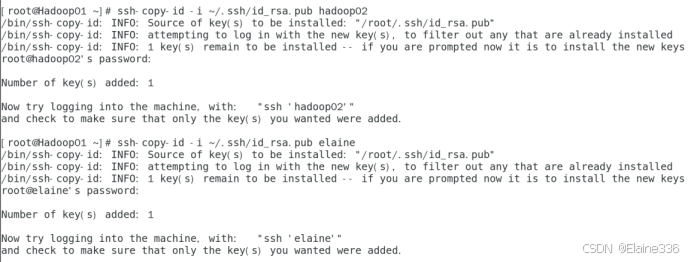
ssh -copy-id -i ~/.ssh/id_rsa.pub elaine(公钥复制到目标主机)
ssh -copy-id -i ~/.ssh/id_rsa.pub hadoop01
ssh -copy-id -i ~/.ssh/id_rsa.pub hadoop02
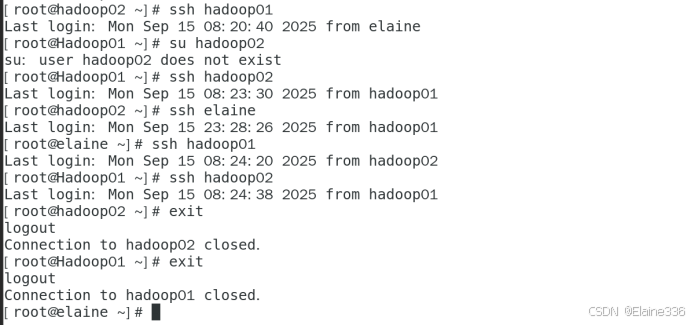
- 5、在所有主机之间随意登录测试,遇到无法登录重复步骤4
- 6、设置Hadoop配置文件
readlink -f $(which java)(寻找java安装路径)
cd $HADOOP_HOME/etc/hadoop(进入配置目录)
vi hadoop-env.sh(修改配置文件)

vi core-site.xml(修改配置文件)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://elaine:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/elaine/hadoop/tmp</value>
</property>
</configuration>

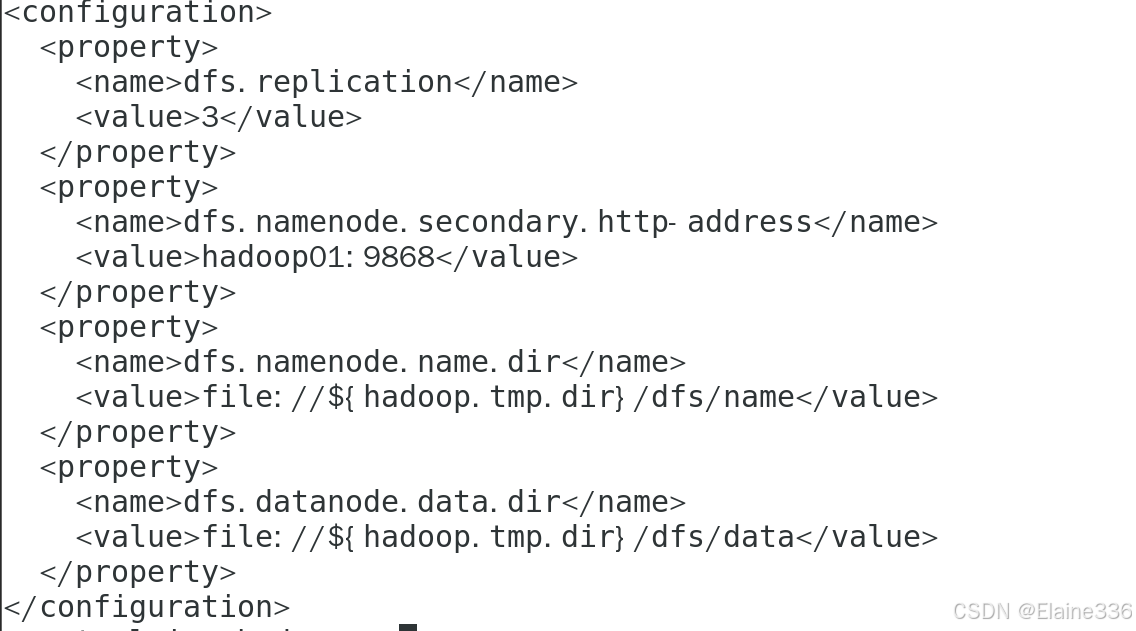
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop01:9868</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
</configuration>
vi mapred-site.xml
<configuration>
<!-- 指定MapReduce运行时框架,这里指定在Yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/home/elaine/hadoop-3.3.0/share/hadoop/mapreduce/*:/home/elaine/hadoop-3.3.0/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>

vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>elaine</value> <!-- 根据实际情况修改 -->
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/home/elaine/hadoop-3.3.0/etc/hadoop:/home/elaine/hadoop-3.3.0/share/hadoop/common/*:/home/elaine/hadoop-3.3.0/share/hadoop/common/lib/*:/home/elaine/hadoop-3.3.0/share/hadoop/hdfs/*:/home/elaine/hadoop-3.3.0/share/hadoop/hdfs/lib/*:/home/elaine/hadoop-3.3.0/share/hadoop/yarn/*:/home/elaine/hadoop-3.3.0/share/hadoop/yarn/lib/*</value>
</property>
</configuration>

- 7、修改work文件(文件用于列出所有作为NodeManager运行的主机名,是YARN集群正常工作的关键配置)
cd /home/elaine/hadoop-3.3.0/etc/hadoop
vi workers

- 8、将Hadoop配置分发到所有节点
- 分发环境变量配置:
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop01:/etc/profile
分发Hadoop配置文件:
scp -r /home/elaine/hadoop-3.3.0/etc/hadoop/*hadoop@hadoop02:/home/elaine/hadoop-3.3.0/etc/hadoop/
scp -r /home/elaine/hadoop-3.3.0/etc/hadoop/*hadoop@hadoop01:/home/elaine/hadoop-3.3.0/etc/hadoop/
- 在每个节点上使环境变量生效:
source /etc/profile
- 9、格式化HDFS
hdfs namenode -format
- 10、启动Hadoop集群:
stop-all.sh - 11、在每个节点进行jps验证,确保服务正常启动
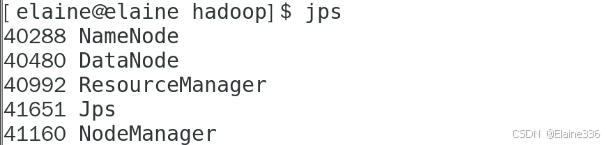

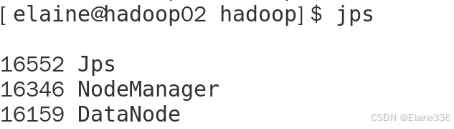
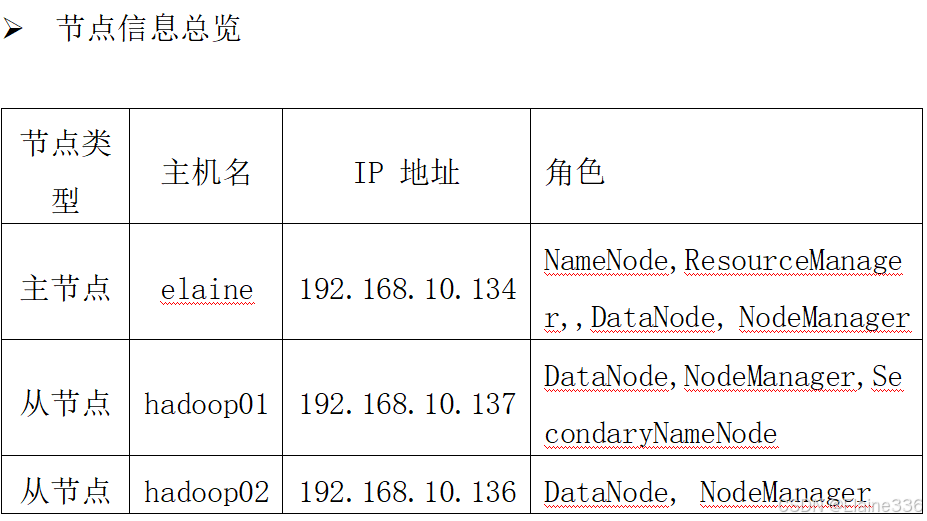
- 12、Hadoop集群测试
- 访问主节点IP:8088/9870(默认是没有数据文件)
- 进入资源管理器Web UI端口
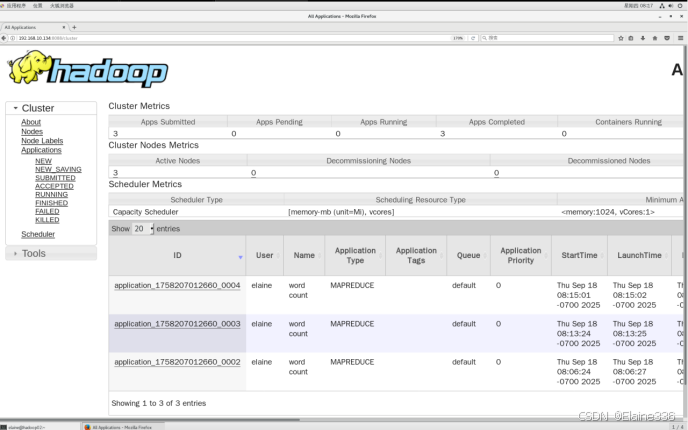
- Hadoop HDFS的NameNode Web UI端口
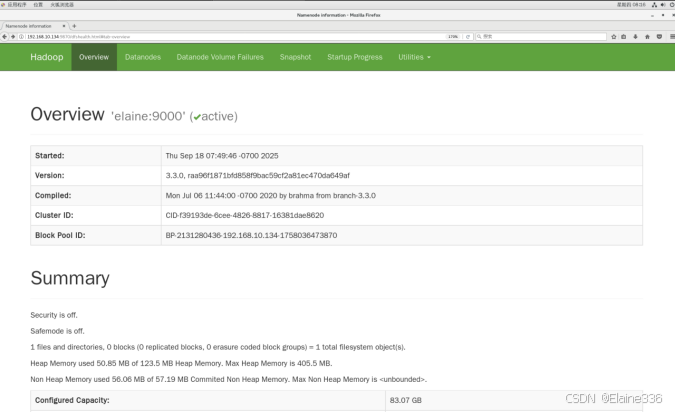
- 13、单词统计
- 创建一个本地测试文件
echo"HelloWorld,thisisatestfileforHadoopMapReduce." >/tmp/test.txt echo "Hadoop is a distributed computing framework." >> /tmp/test.txt
echo "MapReduce is a programming model for processing large data sets." >> /tmp/test.txt
- 将文件上传到HDFS
hdfs dfs -put /tmp/test.txt /input/
- 验证文件已成功上传:
hdfs dfs -ls /input
hdfs dfs -cat /input/test.txt
- 运行MapReduce作业
hadoopjar/home/elaine/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output
- 查看UI界面,Yarn集群UI界面出现程序运行成功的信息HDFS集群UI界面出现了结果文件,可进行结果查看。(9870端口)
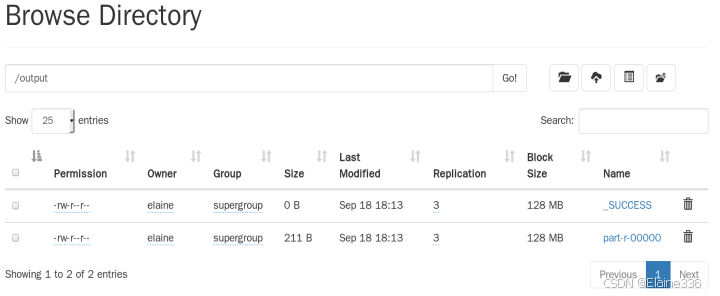
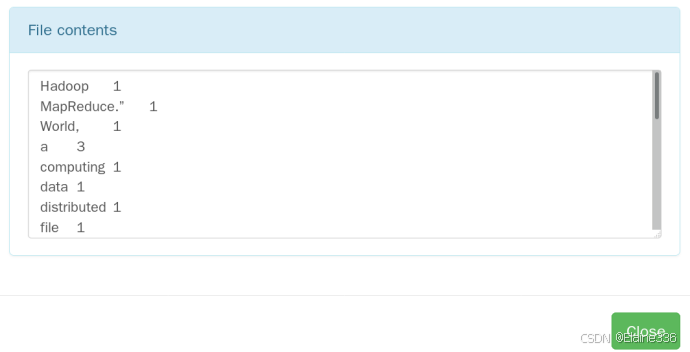
- 在命令行中查看
hdfs dfs -cat /output/part-r-00000
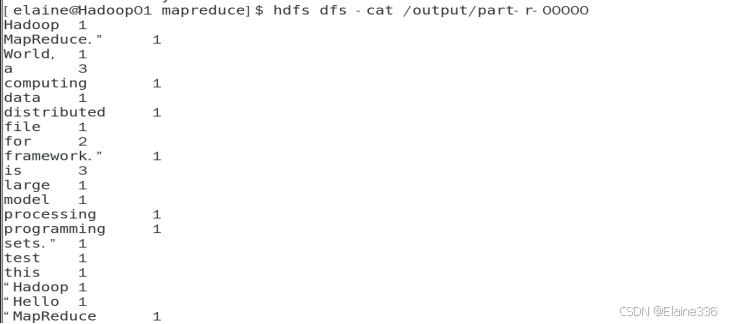
问题及解决方式
1.在单词统计时MapReduce作业失败了,错误信息显示“找不到或无法加载主类 rg.apache.hadoop.mapreduce.v2.app.MRAppMaster”
原因分析:
MRAppMaster是YARN中管理MapReduce作业生命周期的核心组件,当相关JAR包加载失败时通常由以下原因导致:
- 类路径配置问题:YARN运行时环境缺少必要的Hadoop依赖JAR包
解决方案:
- 在yarn-site.xml配置文件中通过yarn.application.classpath属性明确指定完整类路径
- 确保配置包含所有必需的JAR包
最终yarn-site.xml配置示例如下:
2.Linux 系统具备严格的权限管理机制,每个用户的 SSH 密钥和配置都是独立存储的。当普通用户完成节点间的免密登录设置后,若切换为超级用户身份,原有 SSH 登录将失效。因此,节点间的免密登录仅适用于普通用户之间。如需实现超级用户间的免密登录,必须单独进行相应配置。这一特性要求在分发密钥时需要格外注意权限问题。
3.在不同主机上进行配置时可能遇到不同问题,初次遇到故障时可借助大模型辅助排查,并通过持续对话保持上下文连贯性,从而获得更优解决方案

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)