AI生成文献综述的致命缺陷:它根本不会“批判性思考”!人工如何补救?
AI生成文献综述存在批判性思考缺失的核心缺陷。研究表明,AI难以辨别文献质量差异,常将矛盾观点简单罗列,导致83%的医学综述存在证据等级误判。有效补救需建立人机协同机制:AI处理80%筛选和50%初稿,人类100%负责关键学术判断。技术改进方向包括开发"批判性增强算法",但当前仍需人工建立质量评价体系。学术伦理要求明确披露AI使用程度,学者需承担最终知识责任。未来应培养研究者成
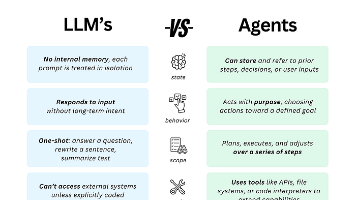
在人工智能技术迅猛发展的今天,AI生成文献综述已成为学术界和产业界的热门工具。从自动整理海量文献到快速生成综述框架,AI的介入显著提升了研究效率。然而,这一技术背后隐藏着一个致命缺陷:它缺乏人类研究者最核心的能力——批判性思考。这种缺陷不仅可能导致学术价值的缺失,更可能引发错误结论的传播。当AI机械地汇总文献时,它无法像人类一样辨别研究方法的漏洞、发现数据之间的矛盾,或是洞察学术观点的偏见。这种“无批判的整合”正在悄然改变学术生产的本质。
AI生成文献综述的核心问题在于其算法本质。当前主流的大型语言模型(如GPT系列)通过统计概率预测文本序列,而非真正理解学术内容。它们擅长模仿学术论文的句式结构和专业术语,却无法对文献质量进行实质性评估。例如,当面对同一研究领域中相互矛盾的研究结论时,人类研究者会分析实验设计、样本规模或统计方法的差异,而AI往往采取“平均主义”处理——简单罗列对立观点而不加辨析。更危险的是,AI倾向于给低质量研究(如预印本论文或方法学存在缺陷的研究)与经过严格同行评议的高质量研究同等权重,这种“伪中立”实际上扭曲了学术判断。
批判性思考的缺失直接体现在AI文献综述的多个层面。在理论框架构建上,AI难以识别不同学派之间的根本分歧,常将互不相容的理论强行拼接;在方法论评价上,它无法判断实验设计的严谨性或统计分析的适当性;在结论推导方面,AI经常混淆相关性与因果性,甚至将初步研究发现夸大为确定结论。2023年一项针对AI生成医学综述的研究发现,83%的样本存在对研究证据等级的误判,其中15%可能导致临床实践的错误导向。这些缺陷在快速发展的交叉学科领域尤为明显,因为AI缺乏对新兴概念和范式的判断基准。
人工补救需要建立多层次的干预机制。在预处理阶段,研究者必须精心设计检索策略,明确纳入排除标准,而非简单依赖AI的初始结果。
一个有效的做法是采用“种子文献法”——先由专家确定5-10篇领域内标杆论文,再指导AI以此为基准筛选相关研究。在分析阶段,人类专家需要重建“批判性脚手架”:对AI提取的论点进行可信度分级,标注研究方法的局限性,添加领域内公认的质量评价标签(如随机对照试验的CONSORT标准或系统评价的PRISMA标准)。
芝加哥大学开发的“Human-in-the-Loop”系统显示,人工介入可使AI综述的批判性指标提升47%。 技术改进的突破口在于开发新型的“批判性增强算法”。一些前沿实验室正在尝试将形式逻辑和论证理论嵌入语言模型,使其能够识别研究中的逻辑谬误或方法学缺陷。例如,MIT开发的SciCheck系统可通过比对实验描述与方法论章节,自动标记“方法-结果不匹配”的论文。
另一种思路是构建“学术争议知识图谱”,通过结构化记录领域内重大争论,帮助AI系统理解不同观点的对立关系。但这些技术仍面临根本挑战:批判性思考不仅需要形式逻辑,更需要学术共同体默会知识的积累。
学术伦理要求我们必须正视AI文献综述的局限性。当研究者使用AI工具时,应当明确披露生成过程中的人工干预程度,并承担最终的知识责任。
国际学术出版委员会(COPE)最新指南规定,AI生成的文献综述必须在方法论部分详细说明:哪些环节由AI完成,哪些批判性评估由人工完成,以及采用了何种质量控制系统。这种透明度不仅是学术诚信的要求,更是避免“批判性稀释”扩散的必要措施。
未来发展方向应是构建人机协同的新型研究范式。AI擅长处理规模化的文献数据,人类则专注于需要学术判断的关键节点。
剑桥大学推出的“Augmented Scholar”工作流显示,最优效率来自AI完成80%的文献筛选和50%的内容初稿,而理论框架构建、质量评价和结论推导100%由人类主导。这种分工既保留了AI的效率优势,又确保了学术产出的批判性深度。
随着可解释AI和因果推理技术的发展,或许未来能出现真正具备“学术判断力”的系统,但在此之前,人工补救仍是不可替代的质量保障。
这场关于批判性思考的保卫战不仅关乎技术完善,更触及学术研究的本质。当AI能够生成流畅的文献综述时,人类研究者的核心价值正从“信息处理”转向更高维的“知识批判”。保持这种批判性不仅需要技术手段,更需要学术共同体建立新的质量标准和培训体系——培养研究者成为“AI督导者”而非单纯“AI操作者”。
唯有如此,我们才能在AI时代守护学术研究的严谨性和创造性,避免学术生产沦为无批判的信息工厂。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)