解锁超级生产力:手把手教你构建与GitHub深度集成的自动化工作流,让AI成为你的编程副驾驶
更令人兴奋的是,我们将向你展示如何将这个工作流与强大的GitHub MCP(Multi-Capability Platform)工具无缝集成,从而赋予你的工作流直接与GitHub仓库进行深度交互的能力。我们将深入每一个步骤,从最基础的节点设置,到获取关键的GitHub密钥,再到最终实战演练,让你亲眼见证自动化工作流带来的巨大威力。如果说基础工作流是给了我们一个智能对话的框架,那么集成GitHub_
前言
在当今快节奏的软件开发世界中,效率就是生命线。每一位开发者、项目经理和技术爱好者都在不断寻求能够简化流程、自动化重复性任务并最终解放创造力的工具和方法。想象一下,如果你能用自然语言与你的开发环境对话,让它为你搜索代码库、管理项目任务,甚至直接在你最喜欢的代码托管平台GitHub上执行操作,那将会是怎样一种颠覆性的体验?
这并非遥不可及的科幻场景,而是已经可以实现的强大功能。本文将为你揭开这层神秘的面纱,通过一个名为“蓝耘”的平台(或任何支持此类功能的类似平台),一步步指导你从零开始构建一个基础的自动化工作流。更令人兴奋的是,我们将向你展示如何将这个工作流与强大的GitHub MCP(Multi-Capability Platform)工具无缝集成,从而赋予你的工作流直接与GitHub仓库进行深度交互的能力。
无论你是希望快速检索海量开源项目、自动追踪和创建任务(Issues),还是希望简化代码提交与拉取请求(Pull Request)的流程,本文都将为你提供详尽的、可操作的指南。我们将深入每一个步骤,从最基础的节点设置,到获取关键的GitHub密钥,再到最终实战演练,让你亲眼见证自动化工作流带来的巨大威力。
第一章:奠定基石——从零构建你的第一个自动化工作流
万丈高楼平地起。在我们探索与GitHub集成的强大功能之前,首先需要掌握构建一个基础工作流的核心技能。这个基础工作流是我们后续所有高级操作的载体和起点,它负责接收我们的指令,调用核心处理模块,并最终呈现结果。
第一节:开场白——工作流的起点与引导
在当今快节奏的数字化时代,效率是成功的关键。开发人员、项目经理和技术爱好者们不断寻求更智能、更自动化的方式来管理他们的工作流程。想象一下,如果有一个平台,不仅能够理解你的自然语言指令,还能直接与你的GitHub仓库进行交互,搜索代码、创建Issues、甚至管理拉取请求(Pull Request),那将会是怎样一种颠覆性的体验?今天,我们将深入探讨这样一个强大的工具——蓝耘Agent平台,并详细展示如何将其与GitHub进行无缝集成,从而彻底改变你的开发和项目管理方式。
第一章:初识蓝耘Agent——你的智能工作流引擎
在我们深入了解如何将GitHub集成到工作流之前,我们首先需要熟悉蓝耘Agent这个平台。蓝耘Agent是一个强大的无代码/低代码平台,旨在帮助用户通过可视化的方式构建和自动化各种复杂的工作流。无论你是希望创建一个简单的问答机器人,还是一个能够处理多步骤、多系统交互的复杂应用,蓝耘Agent都能为你提供所需的支持。
第一步,我们需要进入蓝耘Agent的世界。
-
访问注册页面: 点击蓝耘平台即可直接进入注册界面。这个链接包含了推荐码,可以让你更便捷地完成注册。
-
填写注册信息: 在注册页面,你需要输入一些基本信息来创建你的账户。这个过程非常直观,按照页面提示操作即可。
-
登录Agent平台: 注册完成后,你需要跳转到蓝耘Agent的专属登录页面:https://agent.lanyun.net/。在这里,输入你刚刚注册的账号信息,即可成功登录。
成功登录后,你将看到蓝耘Agent的主界面,这里是你构建所有自动化工作流的起点。
为了更好地理解蓝耘Agent的工作方式,我们将从构建一个最基础的工作流开始。这个工作流将接收用户的输入,通过大语言模型进行处理,然后输出结果。
-
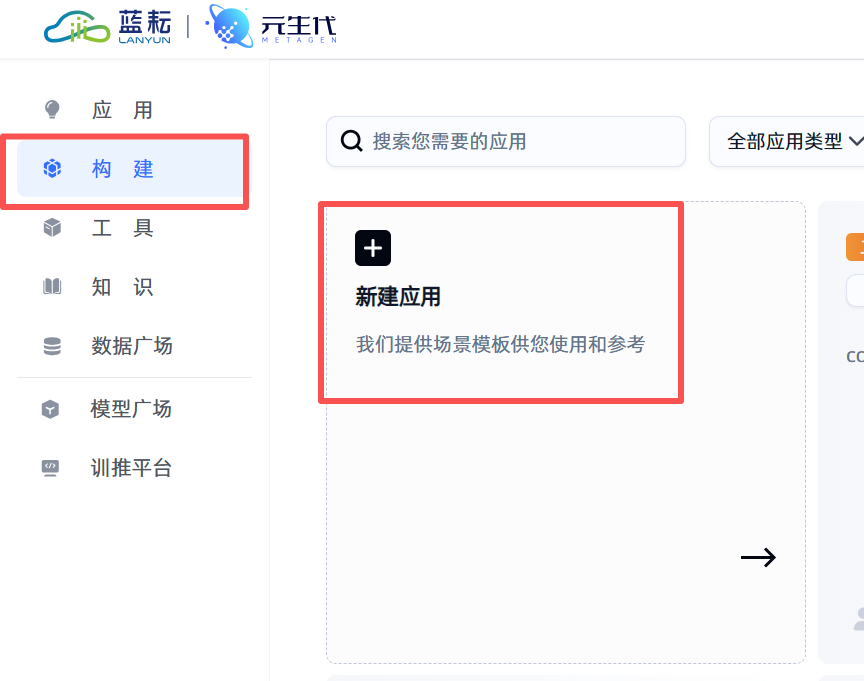
新建应用: 在主界面,找到并点击“构建”按钮,然后选择“新建应用”。
-
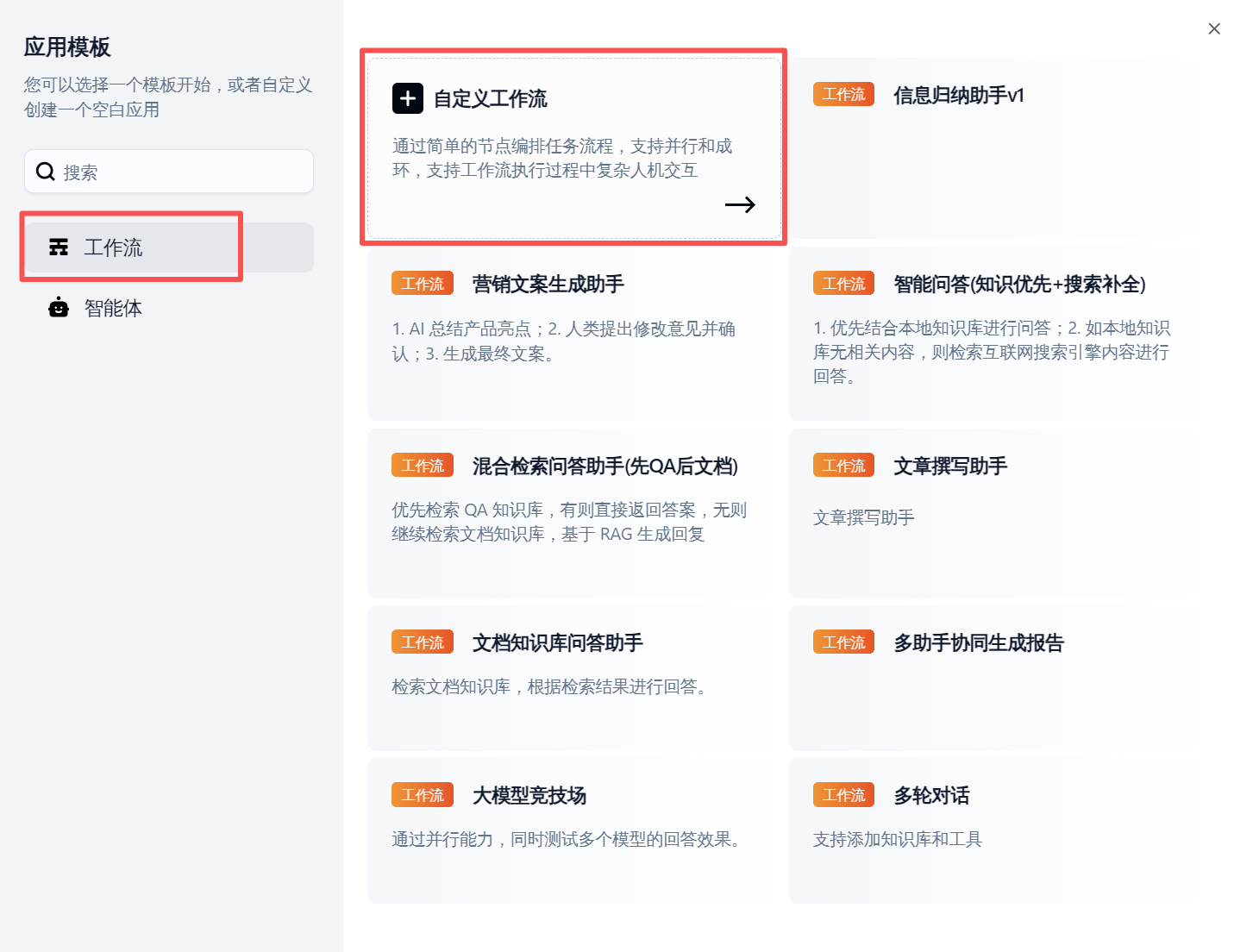
选择自定义工作流: 在弹出的选项中,我们选择“自定义工作流”,这将给予我们最大的灵活性来设计自己的流程。
-
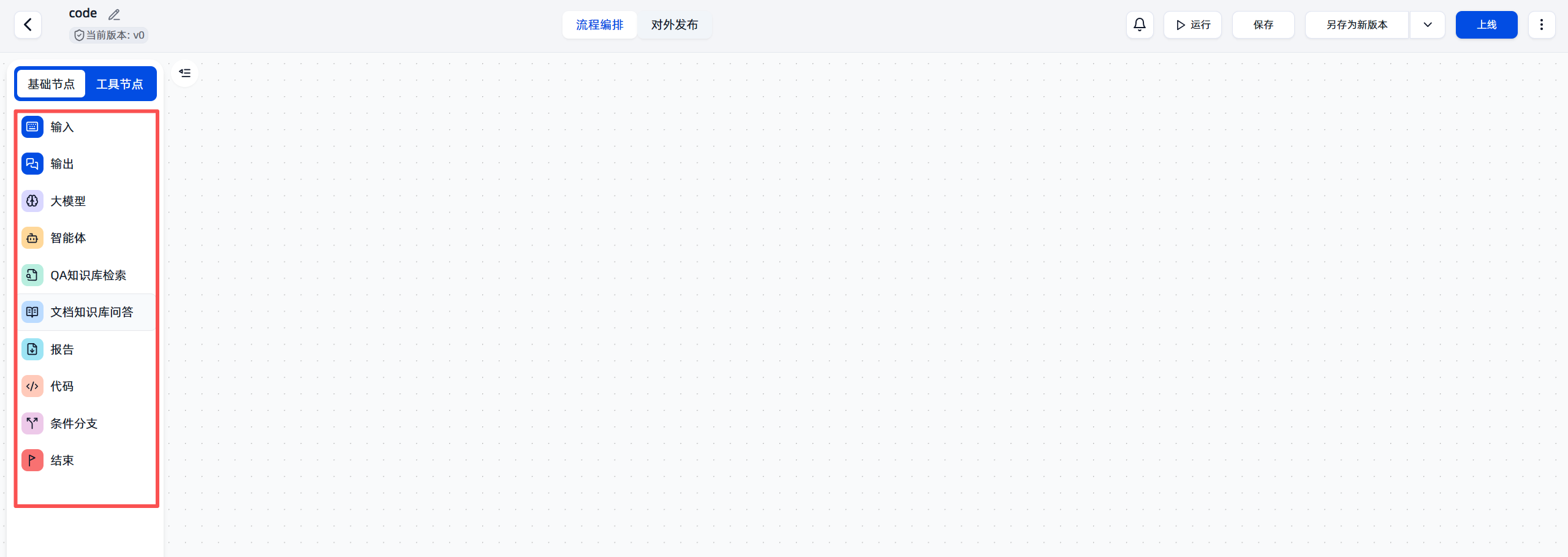
熟悉工作流画布: 进入工作流编辑界面后,你会看到一个清晰的布局。
-
左侧是工具栏: 这里包含了各种可用的节点,如输入、输出、大模型、代码执行等。
-
中间是画布: 这是你拖拽和连接节点,设计工作流的地方。
-
右上角是控制区: 在这里你可以进行运行测试、保存、设置版本以及最终上线你的应用。
-
操作步骤:
- 找到开始节点:在你的工作流构建界面中,通常会有一个默认的“开始”节点。
- 设置开场白:点击并编辑这个节点,你会看到一个用于输入文本的区域。在这里,我们可以设置一段友好的引导语。例如:“您好!我是您的智能工作流助手。您可以向我提问任何问题,或者让我帮您执行特定的GitHub操作。请直接输入您的需求。”
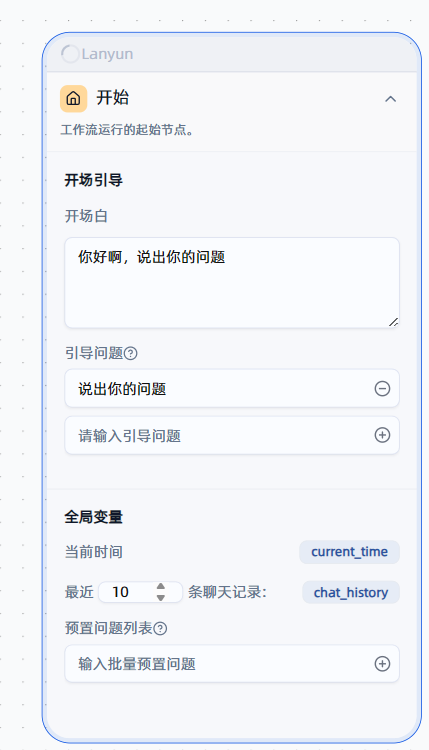
这个简单的设置至关重要。它为用户提供了明确的交互起点,避免了用户面对一个空白的输入框时不知所措的尴尬。一个好的开场白,是构建用户友好型工作流的第一步。
第二节:接收指令——配置输入节点
有了开场白,下一步就是让工作流能够接收并理解我们的指令。这就需要“输入节点”的帮助。输入节点是一个专门用来捕捉用户输入信息的组件,无论是我们通过键盘输入的文字,还是我们上传的文件,都会被这个节点捕获并存储起来,以供后续流程使用。
操作步骤:
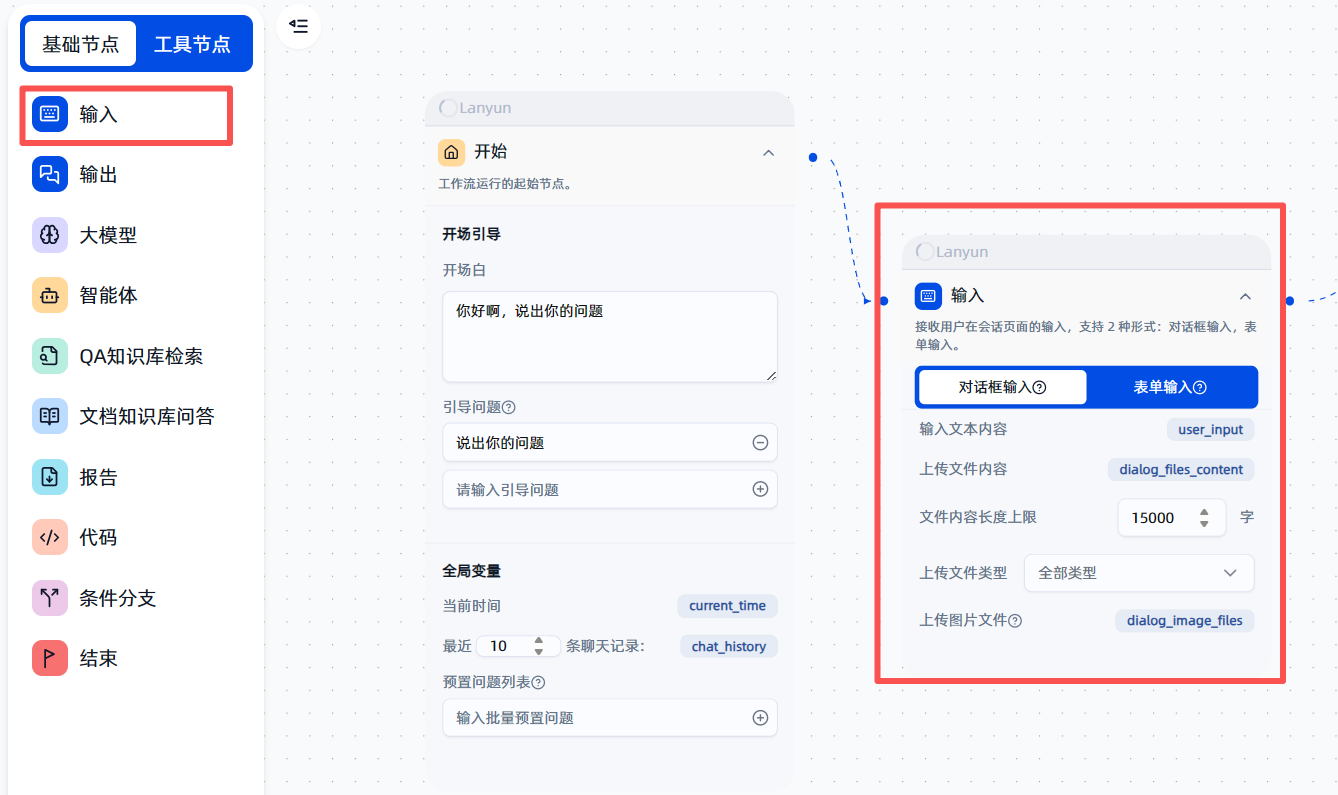
- 添加输入节点:在“开始”节点的后面,点击右上角的加号(“+”)按钮,从节点列表中选择并添加一个“输入”节点。
- 理解变量存储:这个节点会自动完成大部分工作。你需要了解的是,它如何存储我们输入的信息。根据文档,平台会将不同的输入类型保存在特定的变量中:
- 自然语言文本:保存在
user_input变量中。这是我们最常使用的,比如当我们输入“帮我搜索一下PyTorch”时,这句话就会被存入user_input。 - 上传的文件内容:保存在
dialog_files_content变量中。 - 上传的图片文件:保存在
dialog_image_files变量中。
- 自然语言文本:保存在
理解这些变量的名称至关重要,因为在后续的步骤中,我们需要通过调用这些变量,来让其他节点(比如大模型节点)知道我们到底输入了什么。这就像给信息贴上了一个标签,方便后续的查找和使用。
第三节:注入灵魂——集成大语言模型
现在,工作流已经能够接收我们的指令了,但它还不知道如何“思考”和“回应”。要让工作流变得智能,我们就需要为其注入一个强大的“大脑”——大语言模型(LLM)节点。这个节点的核心作用是处理和理解我们输入的自然语言,并根据指令生成相应的回答或执行相应的分析。
操作步骤:
- 添加大模型节点:在“输入”节点之后,继续点击加号,添加一个“大模型”节点。
- 配置系统提示词 (System Prompt):这是最关键的一步。系统提示词是给大模型的“指令说明书”,它告诉模型应该扮演什么样的角色,以及如何处理我们输入的信息。在这里,我们需要将之前输入节点保存的变量引入进来。
- 点击系统提示词输入框右上角的
{x}按钮,这会弹出一个变量列表。 - 从列表中选择
user_input变量。这样,系统提示词就会动态地包含我们每次输入的具体问题。例如,你可以这样设置提示词:“你是一个专业的程序员助手,请根据用户输入的问题{{user_input}}提供详细和准确的解答。”
- 点击系统提示词输入框右上角的
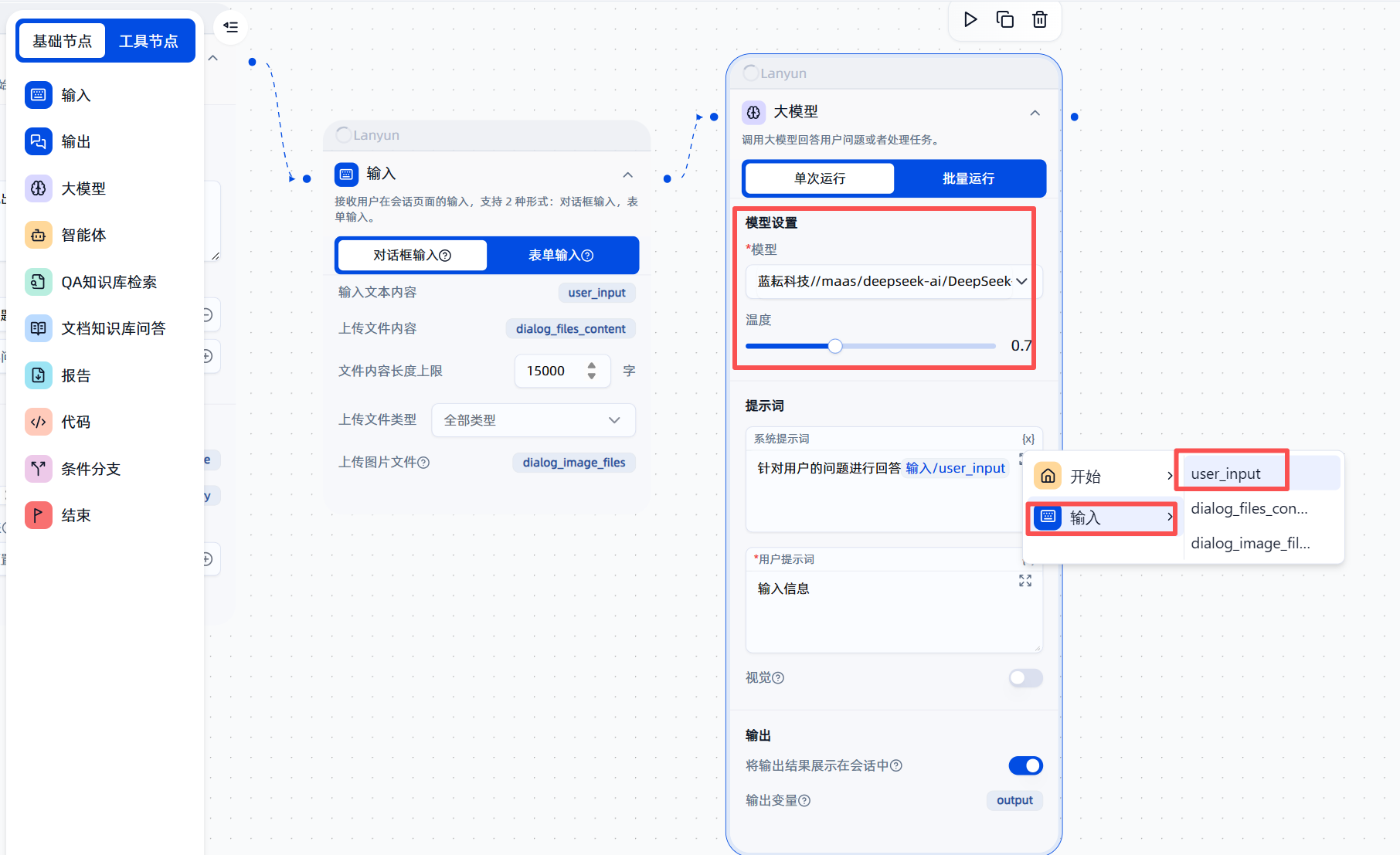
- 选择模型类型:平台通常会提供多种不同能力和特性的模型供你选择。对于大多数通用任务,使用默认的模型通常就足够了。当然,你也可以根据自己的具体需求(例如,需要更强的代码生成能力或更快的响应速度)来自定义选择更适合的模型。
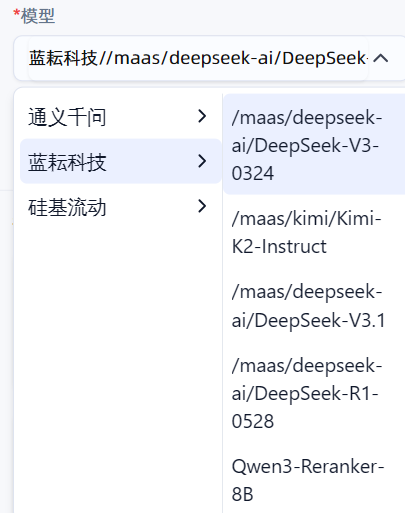
通过这一步,我们的工作流就拥有了理解和生成人类语言的能力,它不再是一个简单的信息传递管道,而是一个具备了初步智能的交互系统。
第四节:完美收官——设置结束节点
经过大模型的处理,我们已经得到了想要的答案。最后一步,就是将这个答案清晰地呈现给我们。这就是“结束节点”的任务。它负责收集上一个节点(大模型节点)的输出,并将其作为整个工作流的最终结果进行打印和展示。
操作步骤:
- 添加结束节点:在大模型节点之后,添加一个“结束”节点。
- 自动连接:通常情况下,这个节点会自动连接到大模型节点的输出,无需过多配置。它的核心功能就是将处理结果进行输出。
至此,一个完整的基础工作流就已经搭建完成了。它的结构清晰,逻辑简单:
开始 -> 输入 -> 大模型处理 -> 结束
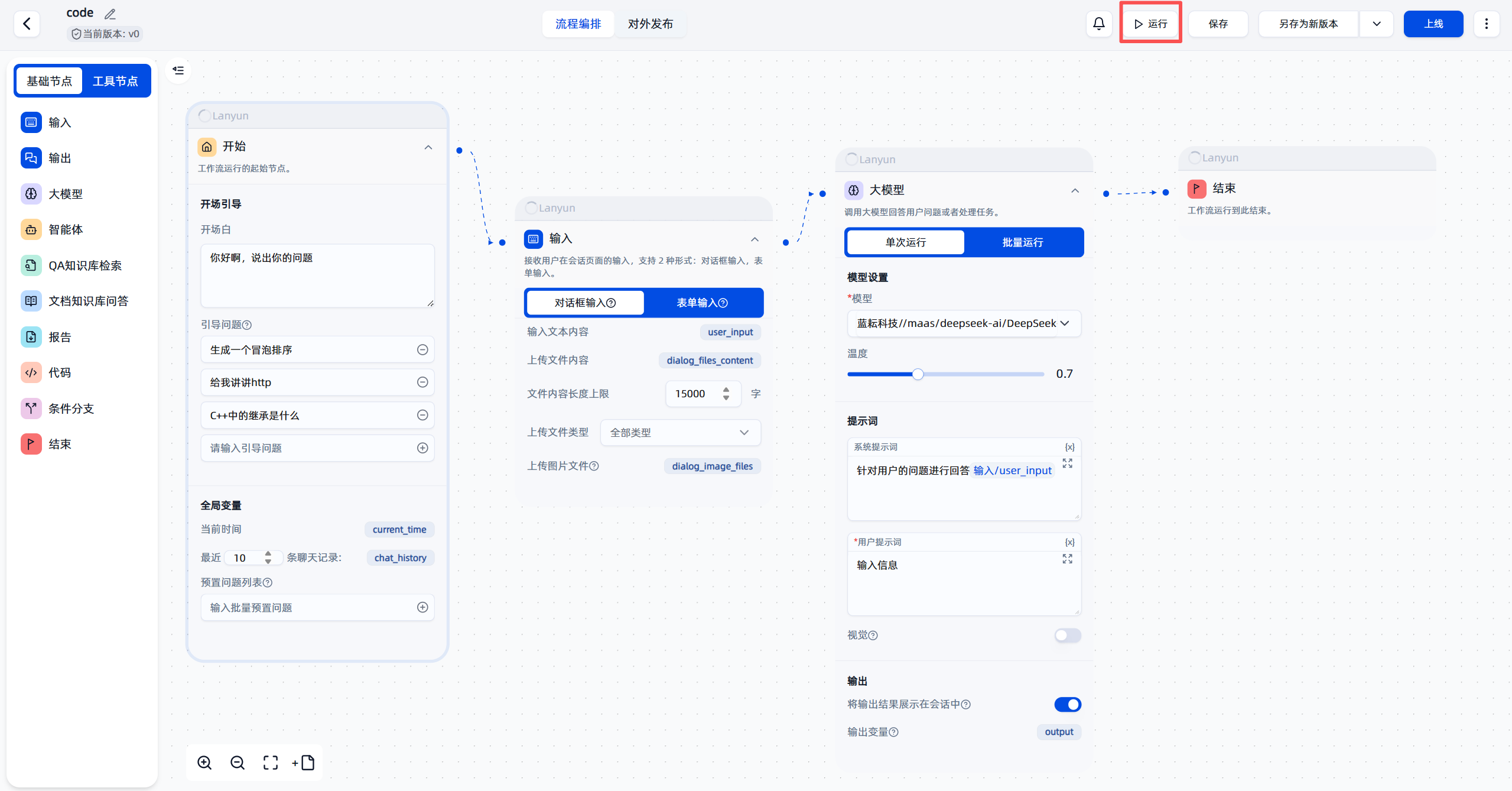
第五节:首次运行与效果展示
理论必须与实践相结合。现在,让我们来运行这个刚刚创建的工作流,看看它的实际效果。
操作步骤:
- 点击运行:在工作流界面的右上角,找到并点击“运行”按钮。
- 输入问题:工作流启动后,会首先显示我们在“开始节点”设置的开场白。接着,在输入框中输入一个问题,例如:“什么是人工智能?”
- 查看结果:点击发送后,工作流会依次执行输入、大模型处理和结束节点。很快,你就会在界面上看到大模型生成的关于人工智能的详细解答。
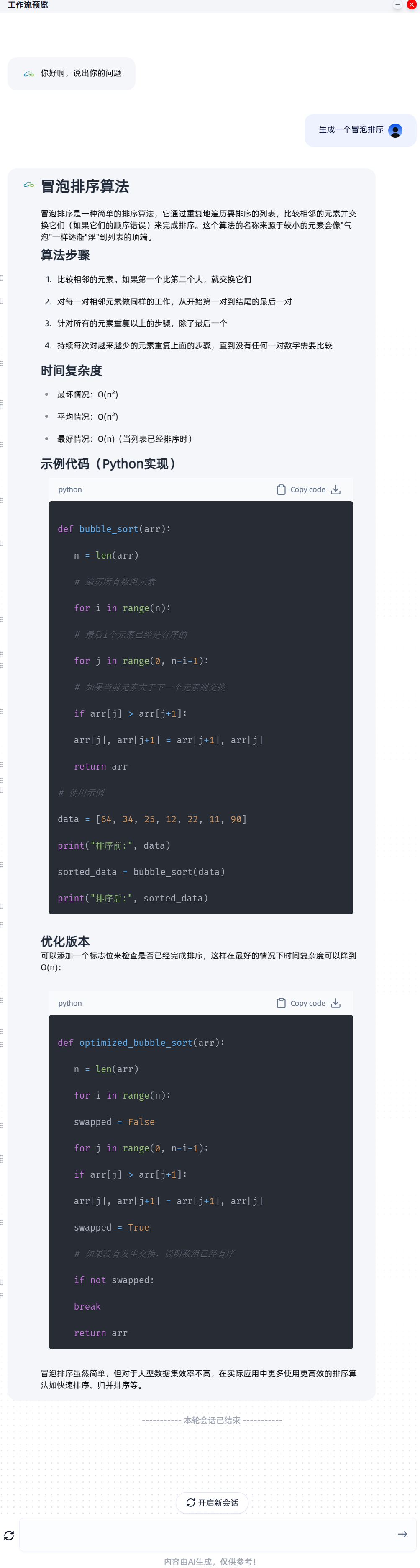
这个基础工作流虽然简单,但它验证了整个流程的可行性,并为我们接下来集成更复杂的工具(如GitHub_mcp)打下了坚实的基础。你可以把它看作是一个骨架,我们将在下一章中为这个骨架赋予更强壮的肌肉和更丰富的功能。
第二章:超级赋能——在工作流中集成GitHub_mcp
如果说基础工作流是给了我们一个智能对话的框架,那么集成GitHub_mcp工具,就相当于为这个框架插上了翅膀,让它能够飞出本地的对话框,直接在广阔的GitHub世界中翱翔和作业。本章将详细介绍如何完成这一关键的集成步骤。
第一节:获取通行证——生成你的GitHub个人访问令牌
要让我们的工作流代表我们去操作GitHub,首先需要向GitHub证明“我们是我们自己”。这就需要一个特殊的“通行证”——个人访问令牌(Personal Access Token, PAT)。这个令牌本质上是一串加密的字符串,它被用作API请求的身份验证,赋予了我们的工作流与我们本人账户相同的权限。
获取这个令牌的过程需要非常仔细,因为权限的设置直接关系到我们工作流的能力上限以及账户的安全性。
操作步骤:
- 访问GitHub设置:登录你的GitHub账户,点击右上角的个人头像,在下拉菜单中选择 Settings(设置)。
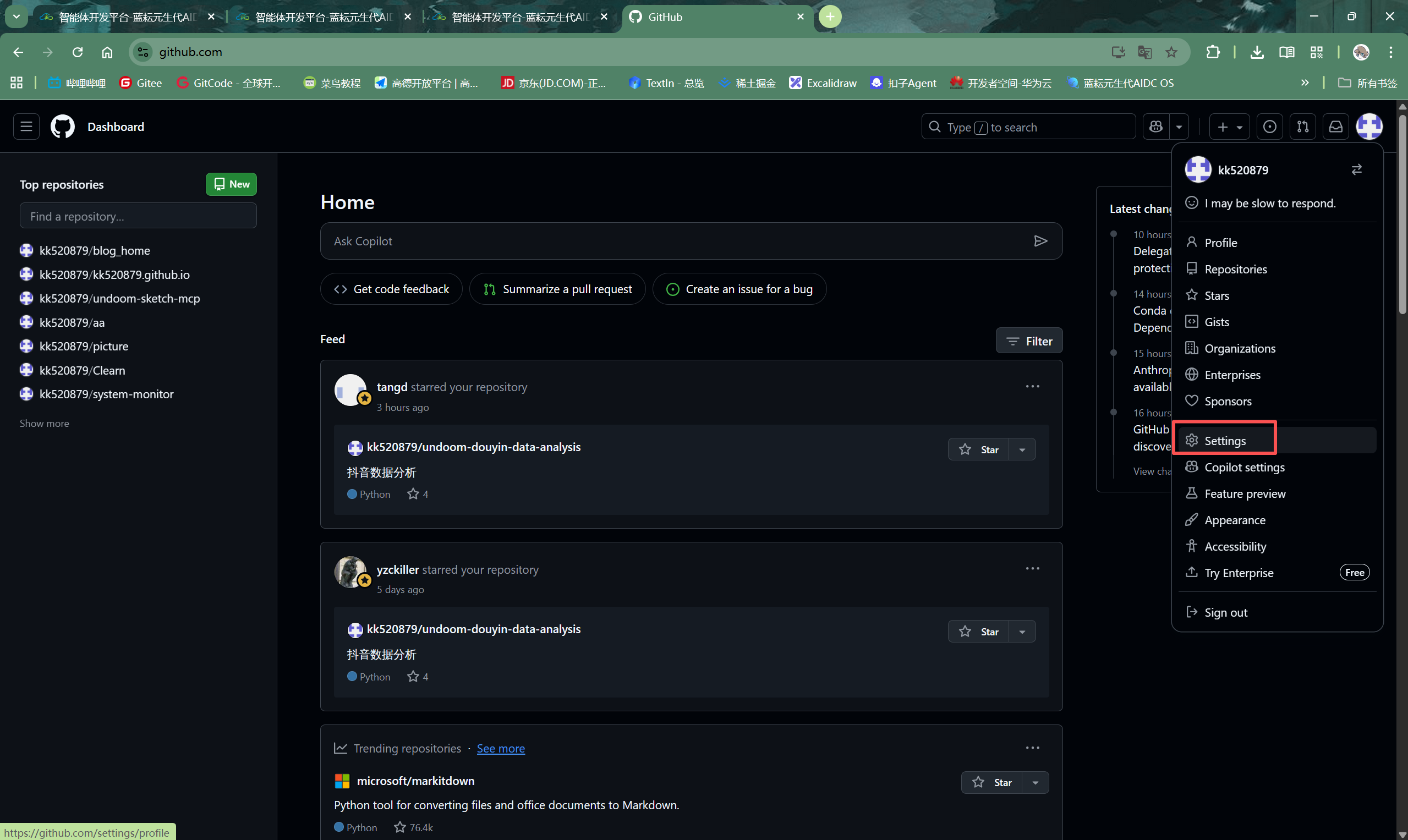
- 进入开发者设置:在左侧导航栏中,滚动到底部,找到并点击 Developer settings(开发者设置)。
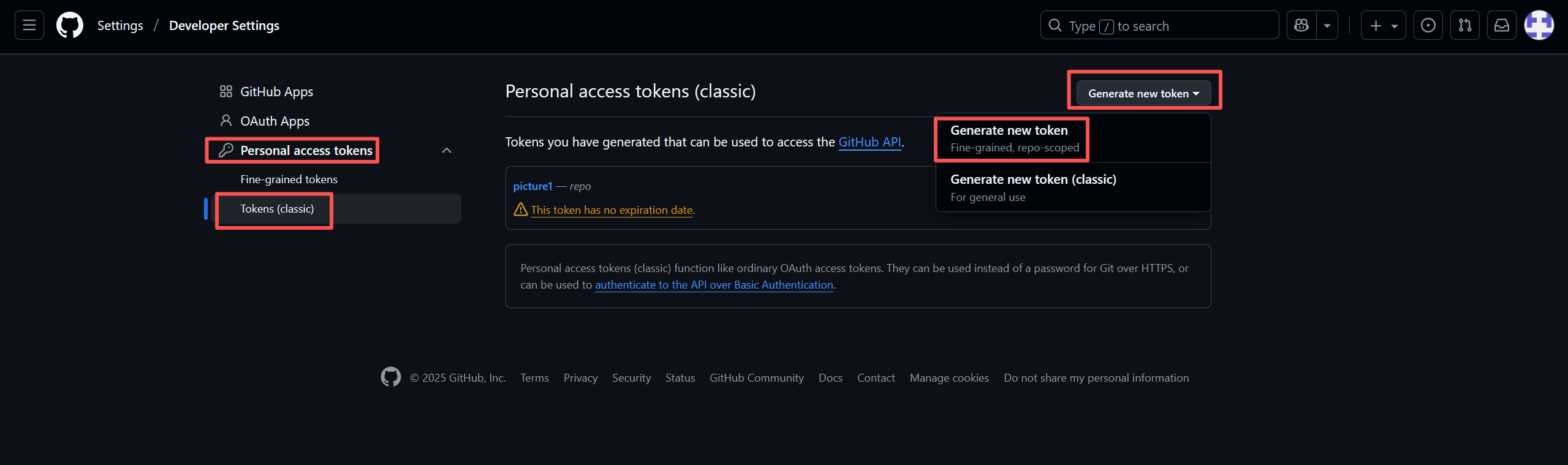
- 选择个人访问令牌:在开发者设置页面,依次选择 Personal access tokens -> Tokens (classic)。然后点击 Generate new token 按钮,并选择 Generate new token (fine-grained)。
- 重点说明:这里强烈建议选择 Fine-grained tokens。与传统的Classic tokens相比,Fine-grained tokens提供了更精细的权限控制。你可以精确地指定这个令牌能够访问哪些仓库,以及在这些仓库上拥有哪些具体权限(比如只读、读写、仅创建Issue等)。这种最小权限原则是保障账户安全的重要实践。
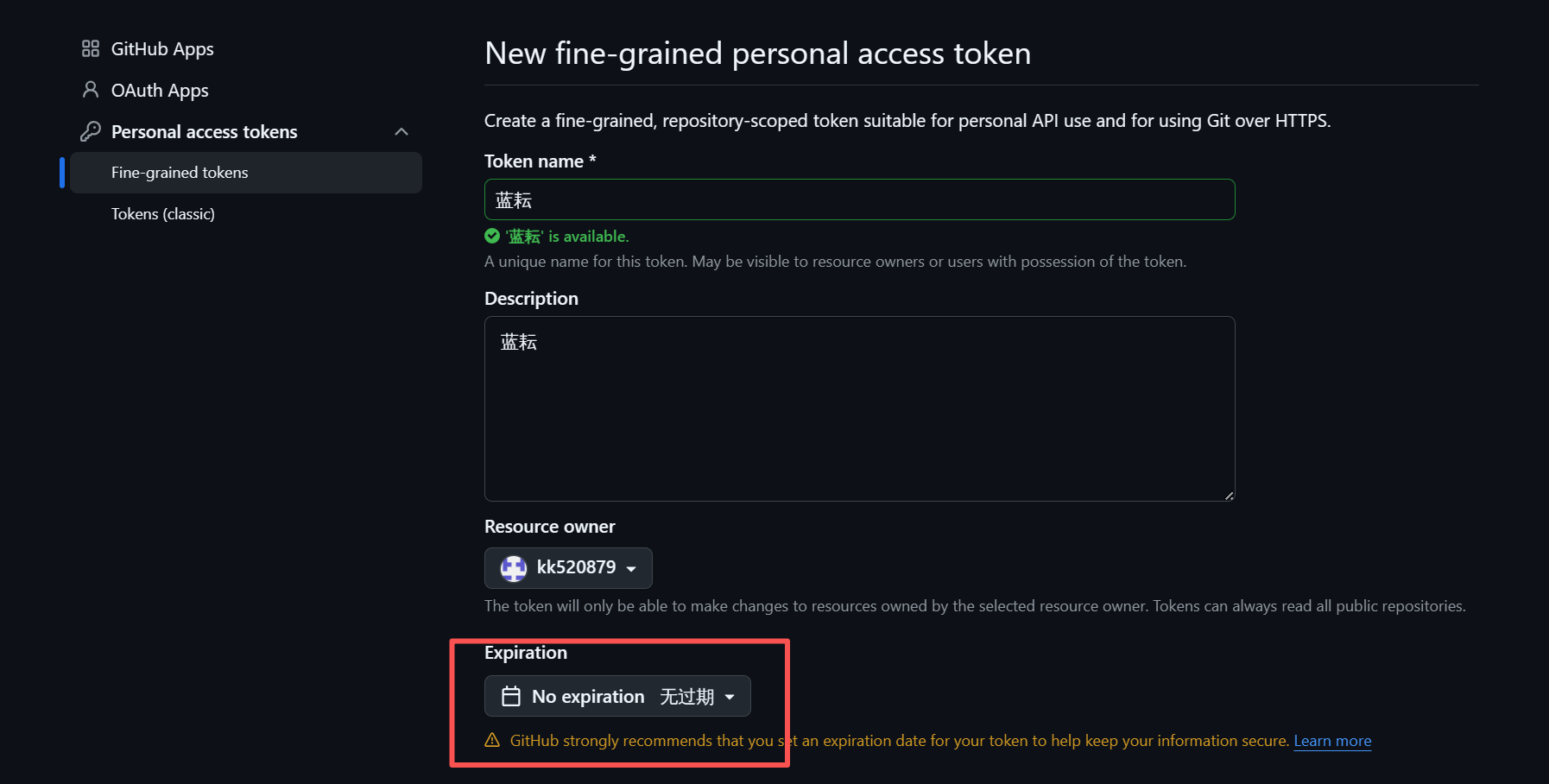
- 配置令牌属性:
- Token name:给你的令牌起一个有意义的名字,比如 “Workflow_Agent_Token”,方便日后管理。
- Expiration:为了方便长期使用和测试,文档中建议选择 No expiration(无过期)。但在生产环境中,出于安全考虑,建议设置一个合理的过期时间(如30天或90天),并定期轮换。
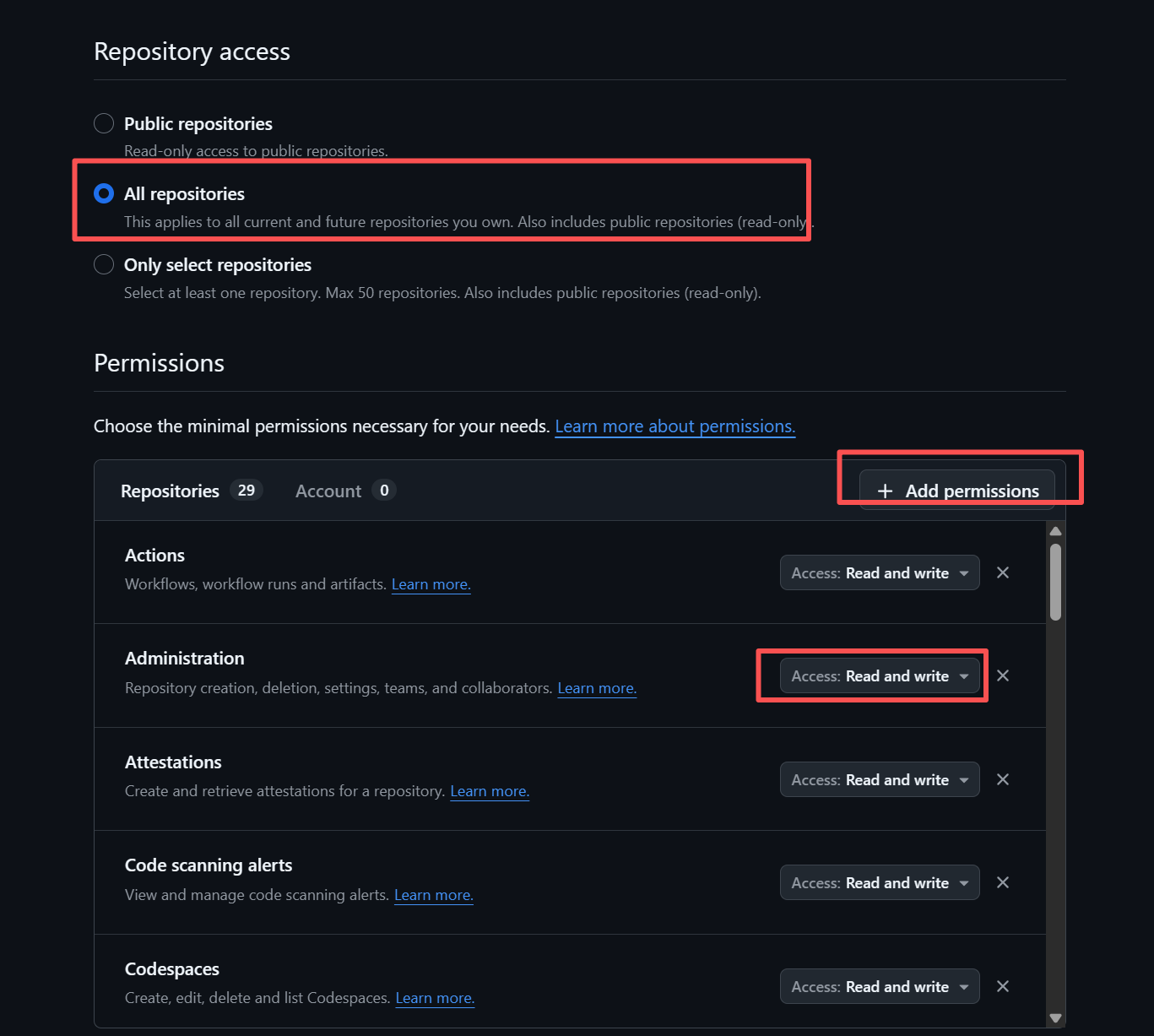
- 授予权限 (Permissions):这是整个过程中最核心、最需要谨慎操作的一步。
- Repository access:选择 All repositories(所有仓库)可以让你在所有仓库中使用这个令牌。如果你只想让工作流操作特定的项目,请选择 Only select repositories 并勾选相应的仓库。
- Permissions:向下滚动,你会看到一个长长的权限列表。文档中为了最大化演示功能,建议将所有权限都打开,并将每个权限的操作级别设置为 Read and write。这包括了对仓库内容、Issues、Pull Requests、Actions等所有方面的完全控制权。
- 安全警告:在实际应用中,请务必遵循最小权限原则。如果你的工作流只需要创建Issue,那就只授予
Issues (Read and write)权限,不要授予代码写入等不必要的权限。授予全部读写权限意味着任何获得此令牌的应用或个人都将拥有对你所有仓库的完全控制权,这存在巨大的安全风险。
- 安全警告:在实际应用中,请务必遵循最小权限原则。如果你的工作流只需要创建Issue,那就只授予
- 生成并保存令牌:配置完所有权限后,滚动到页面底部,点击 Generate token 按钮。
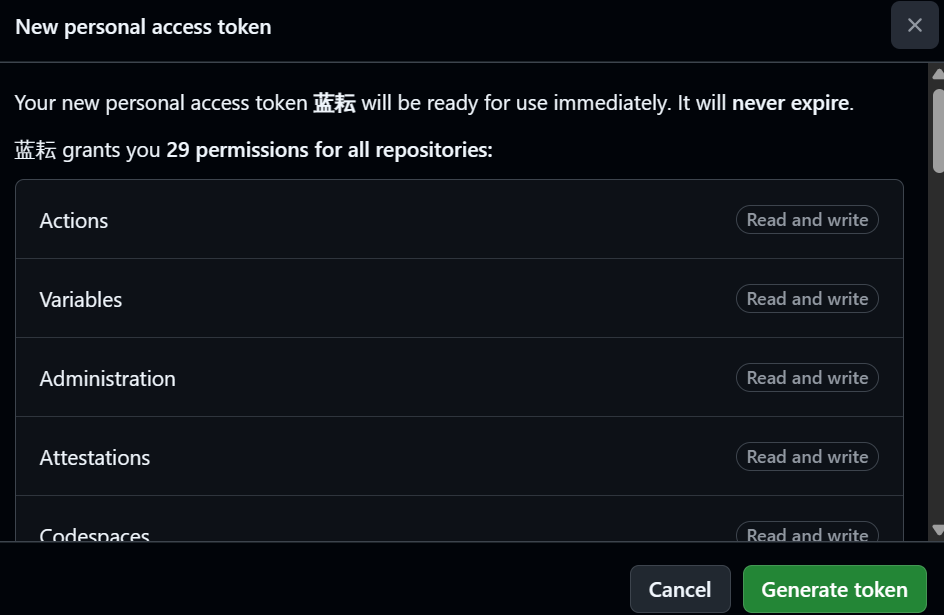
- 立即复制并妥善保管:令牌生成后,会且仅会显示一次。你必须立即点击复制按钮,并将其保存在一个安全的地方(比如密码管理器中)。一旦你离开或刷新这个页面,你将永远无法再次看到这个完整的令牌。
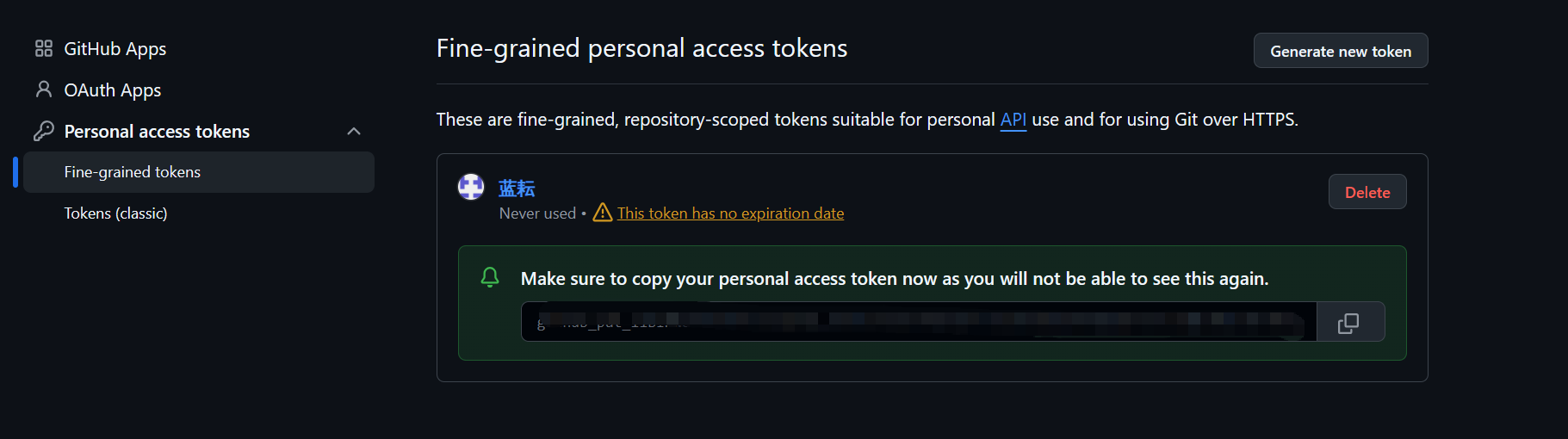
现在,你已经拥有了连接工作流与GitHub世界的“黄金钥匙”。请务必像保管你最重要的密码一样保管它。
第二节:节点连接——在工作流中配置智能体
获取了令牌之后,我们就要回到工作流的构建界面,将这把“钥匙”交给一个能够使用它的角色——“智能体(Agent)”节点。智能体节点是一种特殊的高级节点,它可以被赋予使用各种外部工具的能力。
操作步骤:
- 添加智能体节点:打开我们之前创建的基础工作流。与之前添加大模型节点不同,这次我们要在输入节点后添加一个“智能体”节点。你可以选择替换掉之前的大模型节点,或者将其置于大模型节点之前,让智能体先根据工具执行结果,再由大模型进行总结。一个更常见的做法是直接用智能体节点替代简单的大模型节点,因为它内部本身就集成了大模型来进行决策。
- 添加工具:进入智能体节点的设置界面,你会看到一个“添加工具”的选项。
- 搜索并选择GitHub工具:在工具市场或工具列表中,搜索关键词 “github”。
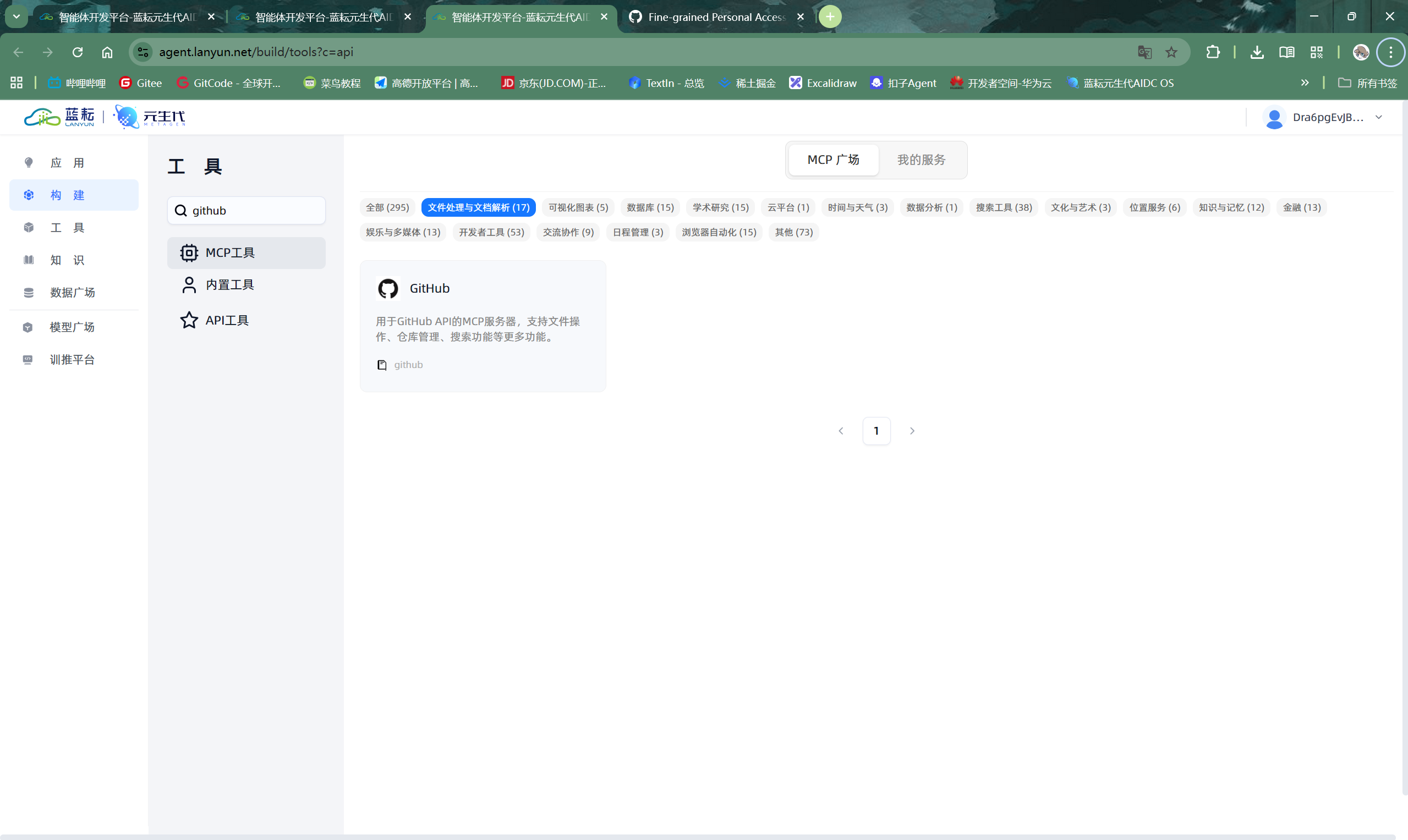
- 输入密钥并连接:选择
GitHub_MCP工具后,系统会要求你提供凭证。这时,将你刚刚在GitHub生成并保存的个人访问令牌(PAT)粘贴到指定的输入框中,然后点击“链接”或“保存”。
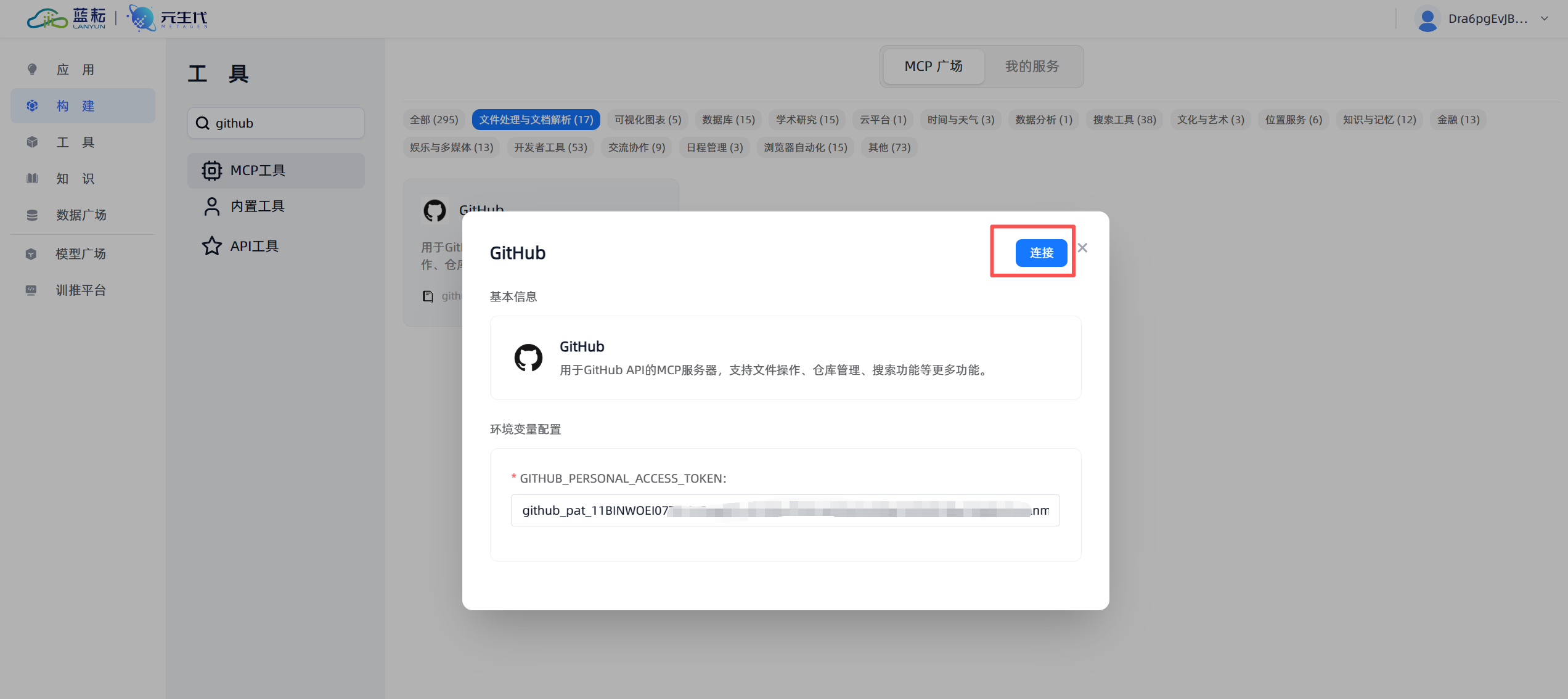
- 验证连接成功:如果你的令牌是有效的,系统会显示一个连接成功的提示。这意味着你的工作流平台现在已经获得了通过API与GitHub进行通信的授权。

- 在智能体中正式启用工具:回到智能体节点的设置界面,再次点击“添加工具”,在“MCP工具”分类下,你现在应该能看到已经成功链接的
GitHub_MCP工具。点击它,然后点击“添加”按钮,将其正式加入到该智能体的可用工具箱中。
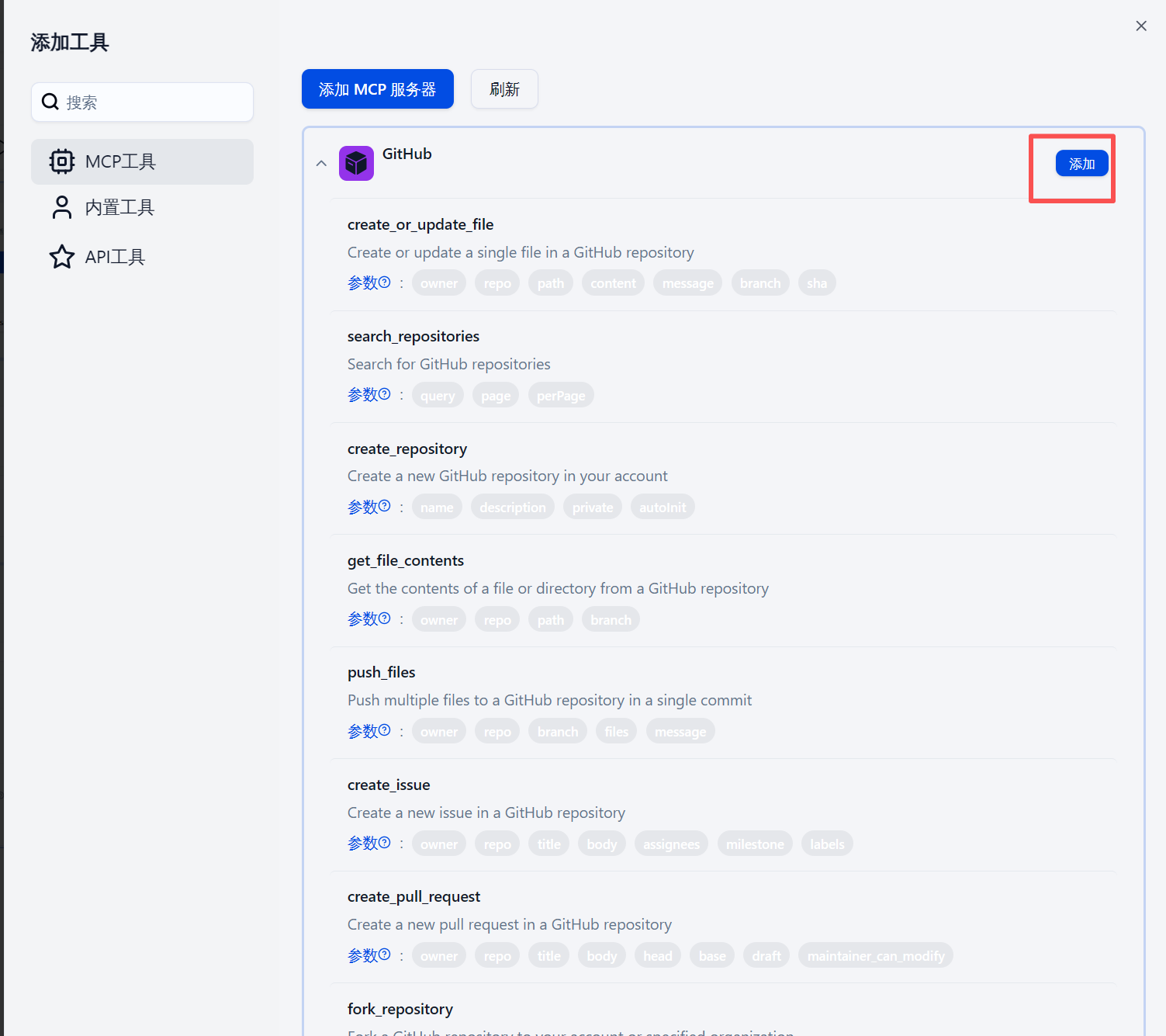
完成这一步后,你的智能体节点就已经被成功赋能了。它不再只是一个空谈者,而是变成了一个能够调用一系列强大GitHub API的实干家。
第三节:能力清单——深入了解GitHub_mcp的强大功能
在开始实战之前,让我们花点时间来检阅一下 GitHub_mcp 这个“工具箱”里到底都有些什么宝贝。了解每个工具的功能、描述和所需参数,对于我们后续如何用自然语言精确地向智能体下达指令至关重要。
以下是 GitHub_mcp 工具集中包含的核心功能,我们对其进行了更详细的解读:
| 功能 (Function) | 描述 (Description) | 核心参数解读 | 应用场景举例 |
|---|---|---|---|
| create_or_update_file | 在指定仓库中创建新文件或更新已有文件。 | owner (仓库所有者), repo (仓库名), path (文件路径), content (文件内容) |
自动生成文档、更新配置文件、提交代码片段。 |
| search_repositories | 根据关键词在整个GitHub上搜索仓库。 | query (搜索关键词) |
“帮我找找关于 ‘data visualization’ 的热门Python项目。” |
| create_repository | 在你的账户下创建一个全新的GitHub仓库。 | name (仓库名称), description (描述), private (是否私有) |
“帮我创建一个名为 my-new-project 的私有仓库。” |
| get_file_contents | 获取仓库中某个文件或目录的具体内容。 | owner, repo, path |
“读取一下 pytorch/pytorch 仓库根目录下的 README.md 文件内容。” |
| push_files | 一次性将多个文件作为一个提交推送到仓库。 | owner, repo, branch, files (文件列表), message (提交信息) |
批量上传项目初始化文件、一次性提交多个模块的修改。 |
| create_issue | 在指定的仓库中创建一个新的Issue。 | owner, repo, title (标题), body (内容) |
“在 kk520879/undoom 仓库创建一个Bug报告,标题是‘登录模块失效’。” |
| create_pull_request | 创建一个新的拉取请求 (PR)。 | owner, repo, title, head (源分支), base (目标分支) |
“从我的 feature-branch 分支向 main 分支创建一个PR。” |
| fork_repository | 将一个公共仓库“Fork”到你自己的账户下。 | owner, repo |
“帮我Fork一下 tensorflow/tensorflow 这个仓库。” |
| create_branch | 在仓库中基于现有分支创建一个新分支。 | owner, repo, branch (新分支名), from_branch (源分支名) |
“在 my-project 仓库,基于 main 分支创建一个名为 dev 的新分支。” |
| list_commits | 列出某个分支上的提交历史记录。 | owner, repo, sha (分支名) |
“显示 expressjs/express 仓库 master 分支最近的5次提交。” |
| list_issues | 根据条件筛选并列出仓库中的Issues。 | owner, repo, state (‘open’, ‘closed’, ‘all’) |
“列出 microsoft/vscode 仓库里所有打开的、带有 ‘bug’ 标签的Issue。” |
| update_issue | 更新一个已经存在的Issue的状态、标题、内容等。 | owner, repo, issue_number, state (‘closed’) |
“关闭 my-repo 仓库里的第42号Issue。” |
| add_issue_comment | 向一个指定的Issue添加一条评论。 | owner, repo, issue_number, body (评论内容) |
“在 my-repo 的第42号Issue下评论:‘这个问题我已经修复了’。” |
| search_code | 在代码库中进行关键词搜索。 | q (包含仓库和代码关键词的查询) |
“在 lodash/lodash 仓库里搜索 debounce 函数的实现。” |
| search_issues | 在GitHub范围内根据关键词搜索Issues和PR。 | q (查询关键词) |
“搜索所有关于 ‘React 19 hooks’ 的Issue。” |
| search_users | 根据用户名或邮箱在GitHub上搜索用户。 | q (用户名) |
“搜索一下用户 ‘linus torvalds’。” |
| … | … | … | … |
(注:表格中仅列举了部分常用功能,完整列表请参考文档。)
通过理解这份能力清单,我们就能明白,我们的智能体现已具备了从代码操作、项目管理到社区互动的全方位GitHub能力。
最终,配置完成的智能体节点,将成为我们工作流中功能最强大的核心枢erva。
现在,我们已经完成了所有的准备工作。工作流的骨架已经搭建,强大的GitHub工具也已装配到位。在下一章,我们将进入激动人心的实战环节,亲身体验这个超级工作流在真实场景中的应用效果。
第三章:实战演练——释放自动化工作流的真正威力
理论的价值在于指导实践。现在,我们已经构建并配置好了一个与GitHub深度集成的自动化工作流,是时候让它在真实的场景中大显身手了。本章将通过一系列具体的、由易到难的任务,来展示这个工作流的强大能力和便捷性。
第一节:信息检索——你的专属GitHub搜索引擎
对于开发者来说,GitHub不仅是代码托管平台,更是一个巨大的知识库和灵感来源。每天,我们都可能需要上去搜索优秀的开源项目、学习他人的代码实现。传统的方式是打开浏览器,输入网址,再在搜索框中键入关键词。现在,我们可以将这个过程简化为一步。
任务一:搜索关于 ‘PyTorch’ 的仓库
目标:我们希望工作流能像GitHub的搜索功能一样,帮我们找到与深度学习框架 “PyTorch” 相关的仓库,并返回第一页的结果,最好能直接给出链接。
操作步骤:
- 设置提示词 (Prompt):在运行工作流时,向它输入清晰、直接的指令。同时,我们可以在智能体节点的系统提示词中预设一些期望,比如“你是一个GitHub专家,请使用工具来回答用户的问题”。
- 用户输入:
请帮我搜索一下 GitHub 上关于 ‘PyTorch’ 的仓库,并返回第一页的结果。
- 用户输入:
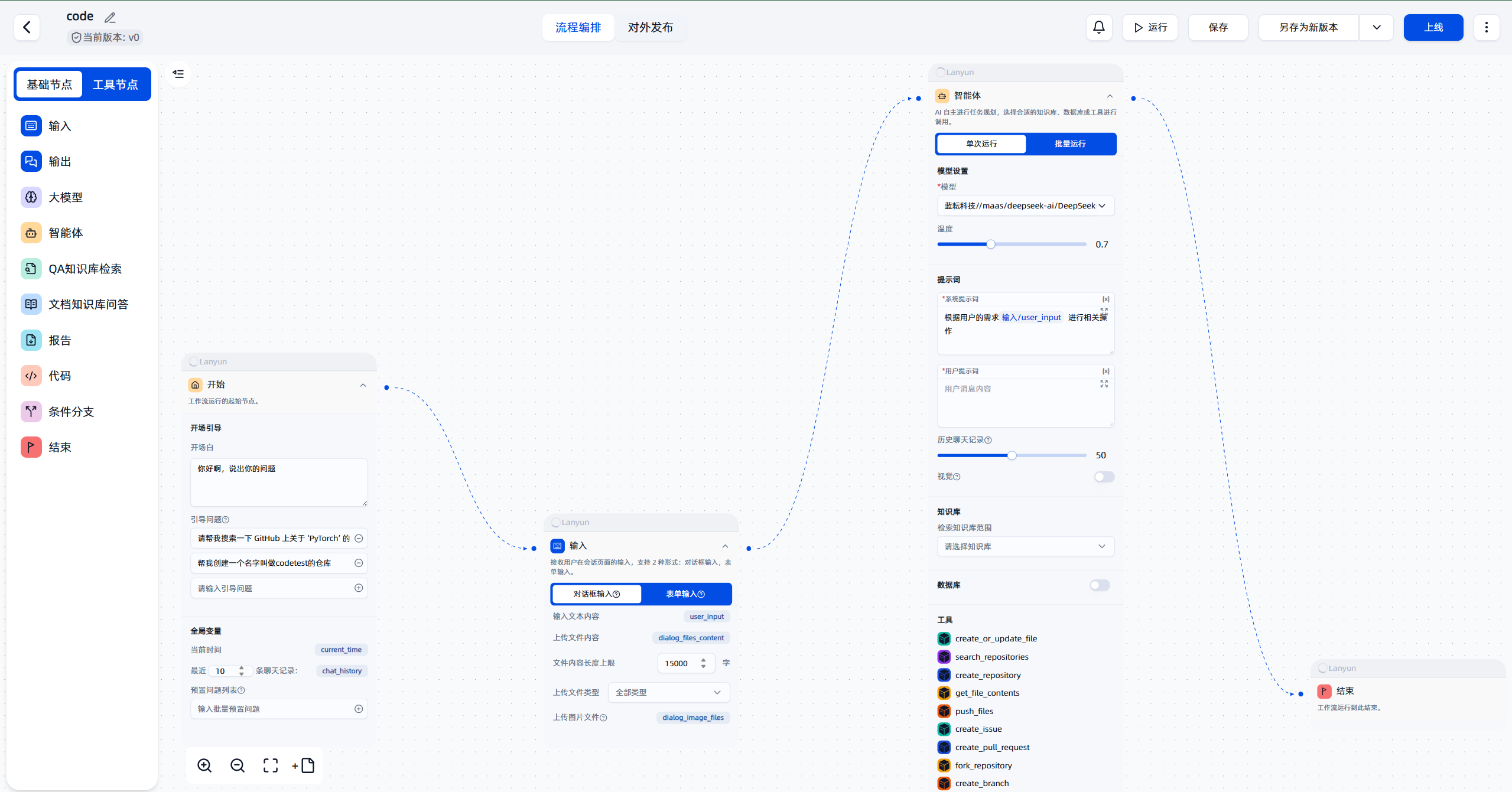
执行过程揭秘:
当智能体接收到这个指令后,它内部的大模型会进行“思考”:
- 意图识别:模型首先识别出用户的核心意图是“搜索GitHub仓库”。
- 工具选择:接着,它会浏览自己拥有的工具列表(即我们配置的GitHub_mcp),发现
search_repositories这个功能完美匹配当前任务。 - 参数提取:模型从用户的输入中提取出
search_repositories功能所需要的参数。很明显,query参数就是 “PyTorch”。对于page和perPage这样的可选参数,如果用户没有指定,它可能会使用默认值(例如,page=1)。 - 工具调用:智能体随后执行
github_mcp.search_repositories(query='PyTorch', page=1)。 - 结果格式化:API调用会返回一串结构化的数据(通常是JSON格式),包含了仓库的名称、所有者、描述、URL等信息。智能体的大模型会将这些原始数据进行整理和美化,以一种更易读的格式呈现给用户。
结果展示:
工作流的输出结果非常直观,它会列出一系列与 “PyTorch” 相关的仓库,每个仓库都包含关键信息,并且附带了可以直接点击跳转的链接。
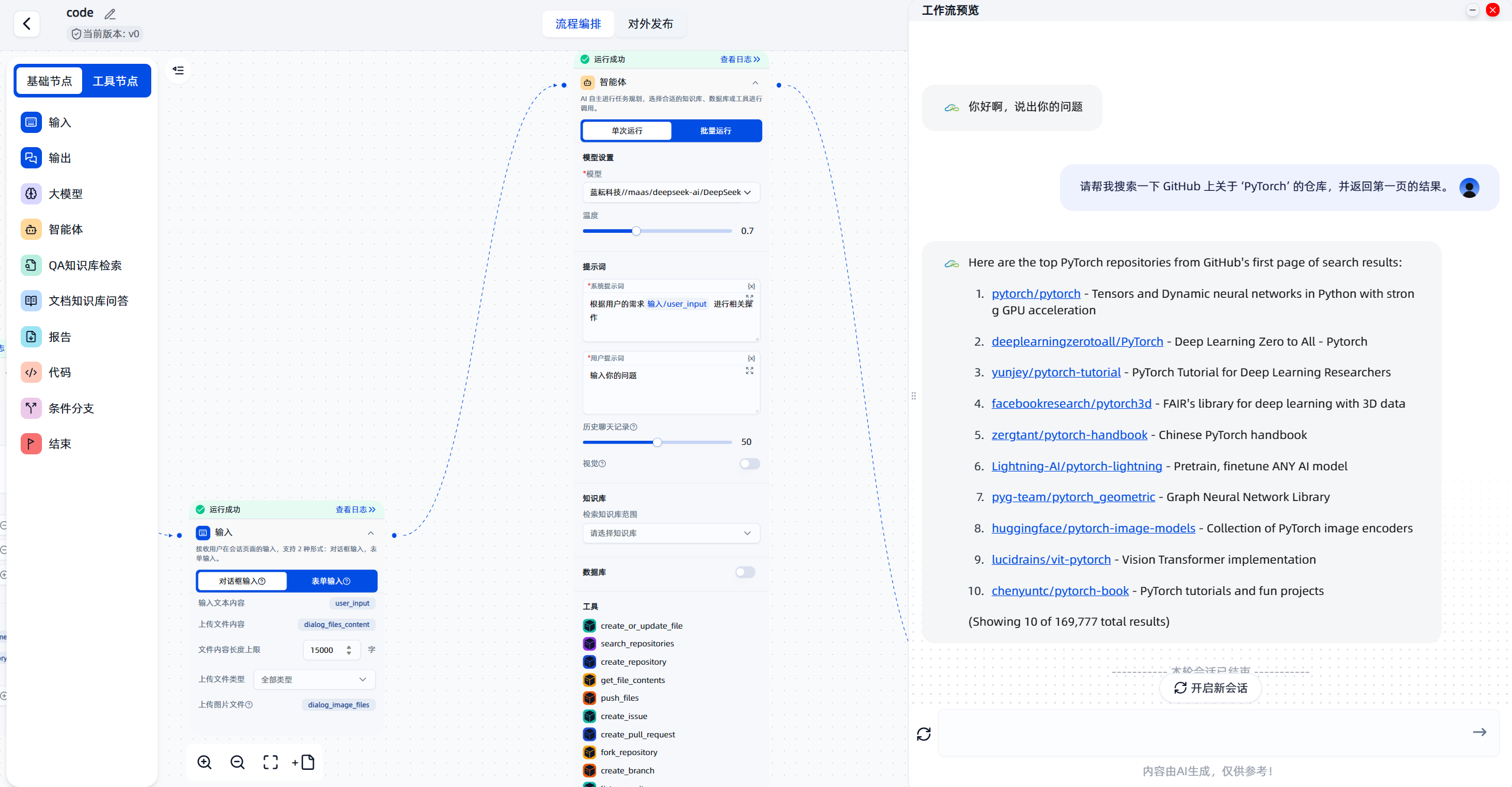
效果验证:
为了验证其准确性,我们可以手动打开GitHub网站,进行相同的搜索。你会发现,工作流返回的结果与GitHub官方搜索结果的第一页是完全一致的。
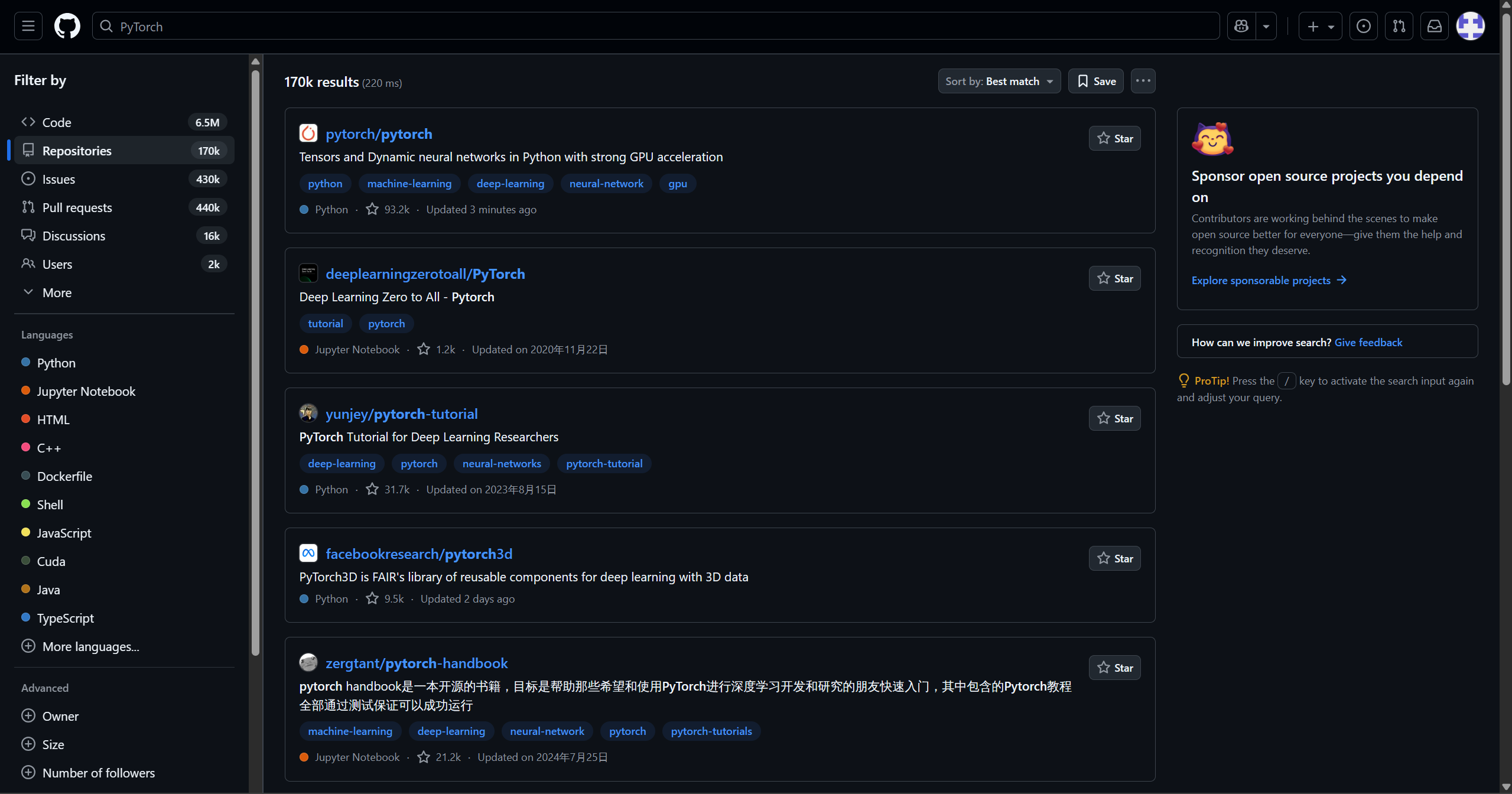
这个看似简单的任务,完美展示了工作流的价值:它将一个多步骤的网页操作,简化成了一次自然语言对话,极大地提升了信息获取的效率。
第二节:趋势追踪——动态获取GitHub热门项目
紧跟技术趋势是每个开发者的必修课。GitHub Trending页面是发现当下最火、最受关注项目的重要渠道。我们能否让工作流每天自动为我们播报这些热门项目呢?答案是肯定的。
任务二:获取今日的GitHub热门项目
目标:让工作流返回当天GitHub上的热门项目列表,要求包含详细的英文说明,并附上快速跳转链接。
操作步骤:
- 用户输入:
帮我获取今日的GitHub热门项目,需要有详细的英文说明,并附带一个快速跳转链接。
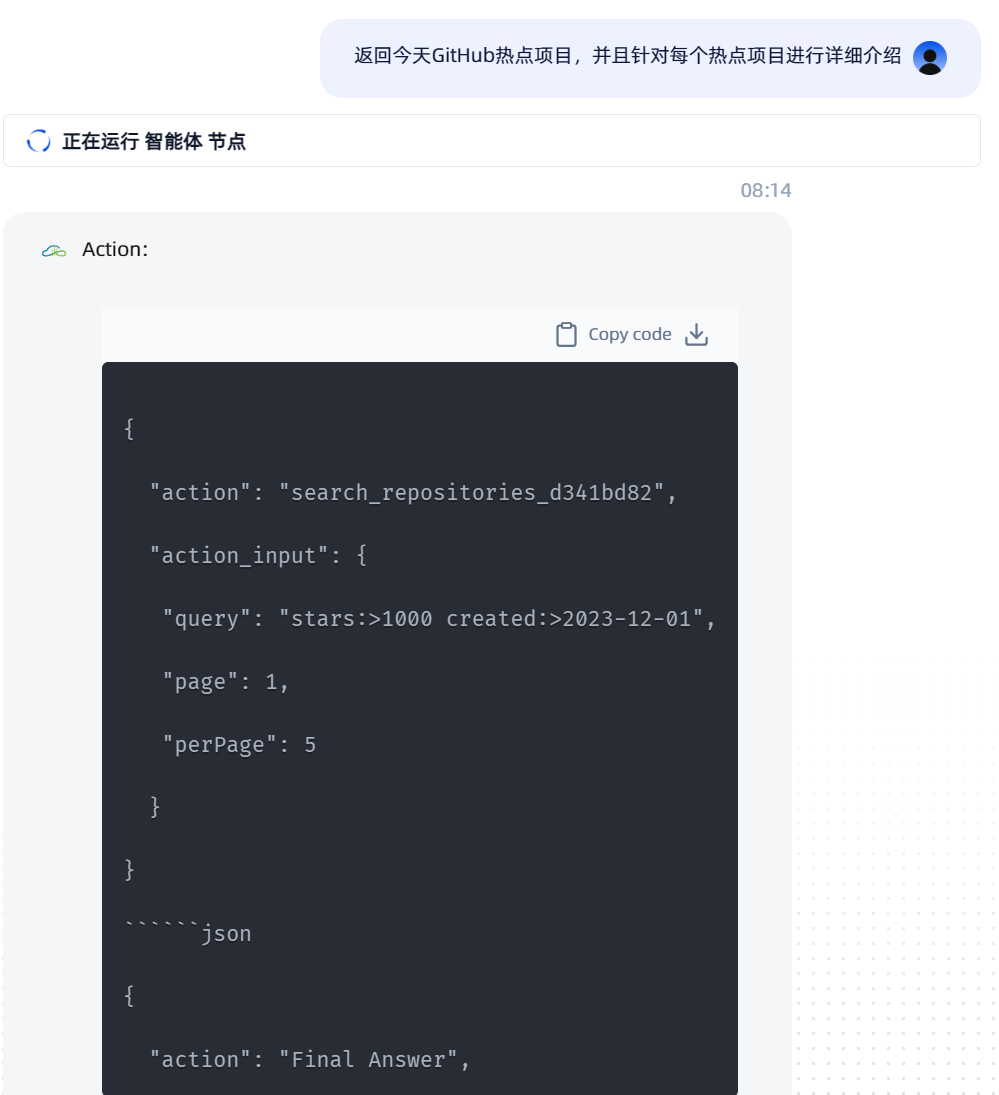
执行过程揭秘:
这个任务比上一个稍微复杂一些。GitHub_mcp 工具列表中可能没有一个直接名为 get_trending_repositories 的功能。这时,智能体的大模型会展现出更强的推理能力:
- 意图理解:“热门项目”通常与“星星数(stars)”的增长趋势有关。
- 策略规划:模型可能会制定一个策略:使用
search_repositories功能,但构造一个特殊的查询。GitHub的搜索支持多种限定符,比如stars:>N,或者按照updated日期排序。一个聪明的模型可能会构造一个类似q='stars:>100 created:>{today-1day}' sort='stars' order='desc'这样的高级查询,来模拟“今日热门”的效果。 - 工具执行与结果呈现:执行搜索后,同样将返回的结果进行美化,提取英文描述和URL,然后呈现出来。
结果展示:
工作流的输出会是一个清晰的列表,每个项目都像一个摘要卡片,让你能迅速了解其核心价值,并决定是否要点击链接深入探索。

通过这个任务,我们看到了智能体不仅仅是简单的API执行者,它还能在一定程度上理解抽象概念(如“热门”),并将其转化为具体可执行的工具调用策略。
第三节:项目管理——直接在工作流中提交Issue
这可能是最能体现工作流与GitHub深度集成价值的功能之一。在开发过程中,发现Bug或有新想法时,我们需要去对应的仓库创建一个Issue。这个过程虽然不复杂,但却会打断我们当前的工作流。现在,我们可以直接在对话中完成这一切。
任务三:为指定仓库提交一个具体的Issue
背景:假设我是项目 undoom-douyin-data-analysis 的使用者,我发现了一个问题:内置浏览器在某些情况下需要用户手动登录,影响了体验。我希望提交一个Issue来反馈这个问题,并建议改进方案。
目标:通过工作流,向 https://github.com/kk520879/undoom-douyin-data-analysis 这个仓库提交一个Issue。
操作步骤:
- 用户输入:我们需要提供所有必要的信息:仓库地址、Issue的内容和标题。我们可以将这些信息整合在一个指令中。
请针对我的undoom-douyin-data-analysis Public仓库提交一个issues 内容是:目前可能会出现内置浏览器打开需要进行登录操作或者是弹窗,需要进行一个持久化的操作甚至是增加一个内置tool进行用户登录操作- 为了让Issue更规范,我们可以补充一个标题:
标题是:【功能建议】优化内置浏览器登录体验,增加持久化登录
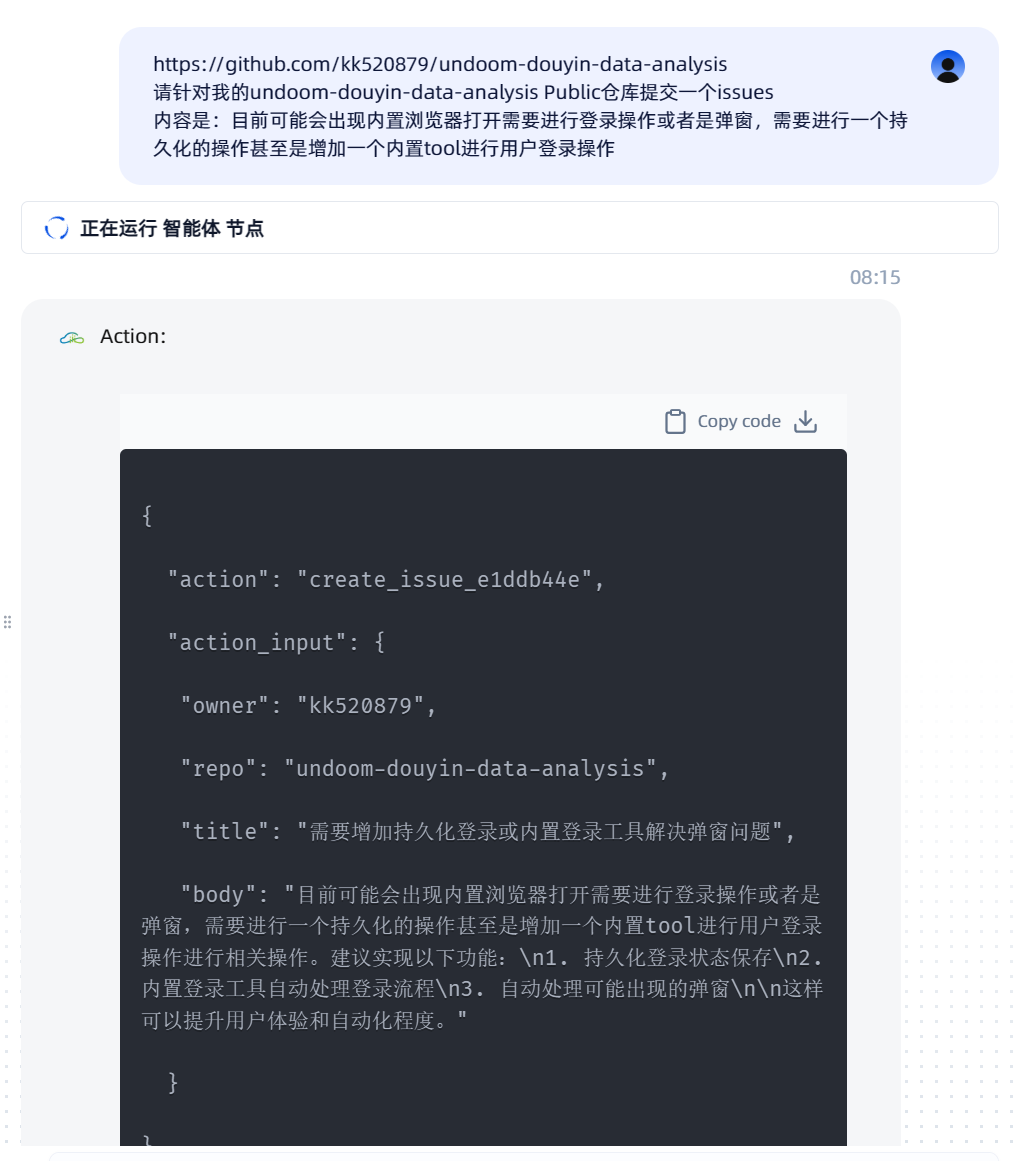
执行过程揭秘:
- 意图识别:核心意图是“提交Issue”。
- 工具选择:智能体立即锁定
create_issue功能。 - 参数提取:
repo:从仓库名undoom-douyin-data-analysis中提取出undoom-douyin-data-analysis。owner:从GitHub用户名kk520879中提取。title:从用户输入的“标题是:…”中提取。body:提取用户描述的问题和建议内容。
- 智能优化(亮点):在文档的截图中,我们发现了一个非常有趣的现象。工作流在执行创建Issue之前,可能会调用其内置的大模型能力,对用户输入的
body内容进行优化和润色。它可能会将口语化的描述变得更书面化、结构化,使其看起来更专业,甚至补充一些上下文。这是单纯的API调用无法做到的,体现了AI的增值作用。 - 工具调用:执行
github_mcp.create_issue(owner='kk520879', repo='undoom-douyin-data-analysis', title='...', body='...')。
结果展示与验证:
工作流会返回一个确认信息,通常会包含新创建Issue的编号和链接。

我们可以点击这个链接,或者直接访问GitHub上的该仓库。在 “Issues” 标签页下,我们会赫然发现一个新的Issue已经被成功创建。点开查看,其标题和内容都与我们的要求一致,甚至可能经过了AI的优化,语言表达更加清晰、专业。
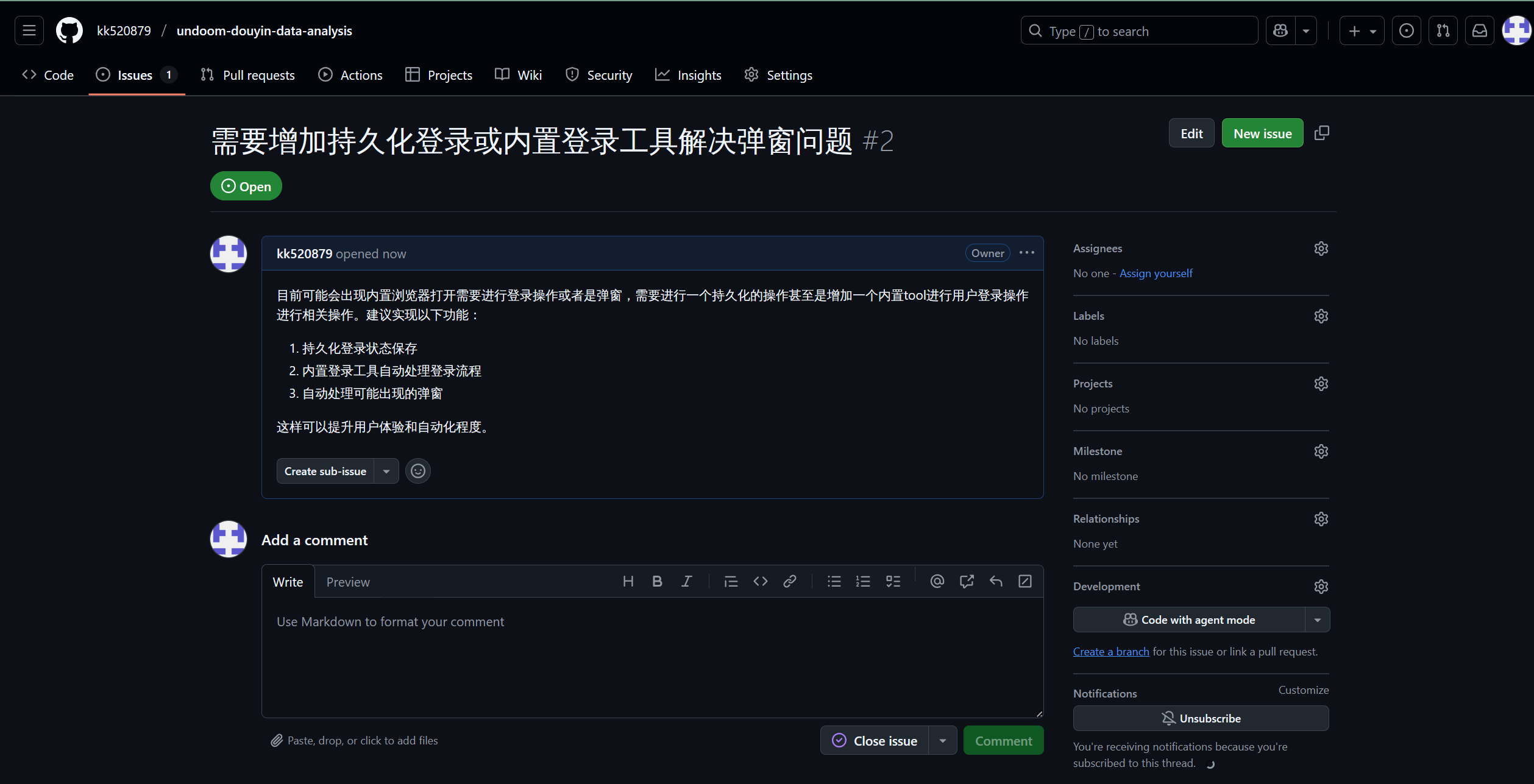
这个实战案例的意义是巨大的。它意味着,从发现问题、构思描述到最终创建任务记录,整个项目管理的闭环都可以在一个统一的对话界面中完成,无需切换应用,无需中断心流。这对于提升开发者的专注度和工作效率有着不可估量的价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)