解锁AI巨型模型训练:DeepSpeed ZeRO Offload 全面指南
摘要:DeepSpeed的ZeROOffload技术通过将模型参数和优化器状态从GPU卸载到CPU/NVMe存储,使单张32GBGPU也能训练13亿参数模型。该技术基于ZeRO三阶段优化:1)仅卸载优化器状态;2)增加梯度卸载;3)完整分片参数和状态。相比传统方法,ZeROOffload可降低10倍GPU内存需求,支持在单机上训练原本需要多GPU集群的模型。配置简单,通过JSON文件即可启用,兼容
在AI时代,大型语言模型(LLM)如GPT系列的参数量动辄数百亿,甚至上万亿,训练它们需要海量的计算资源。但如果你只有有限的GPU,怎么办?DeepSpeed的ZeRO Offload技术就是你的救星!这项创新功能能将模型参数和优化器状态“卸载”到CPU或更远的存储上,让单张GPU也能驾驭原本遥不可及的巨型模型。
想象一下:在单张32GB GPU上训练一个13亿参数的模型,而无需昂贵的多GPU集群。这不是科幻,而是DeepSpeed ZeRO Offload的真实能力。本文将深入剖析这项技术,从背景、工作原理到配置实战,帮助你快速上手。无论你是AI研究员、开发者还是爱好者,这篇指南都能让你在资源有限的环境中高效训练模型。让我们开始吧!
1、什么是DeepSpeed ZeRO Offload?
DeepSpeed是由微软开发的开源深度学习优化库,专注于大规模模型训练。ZeRO(Zero Redundancy Optimizer,零冗余优化器)是其核心技术,通过参数分片(sharding)减少内存冗余,让多GPU协作时每个设备只持有部分模型状态,从而节省宝贵的GPU内存。
ZeRO Offload则是ZeRO的扩展版,它将模型的部分组件(如参数、梯度和优化器状态)从GPU“卸载”(offload)到CPU内存,甚至NVMe存储上。这特别适合GPU内存瓶颈严重的场景,能让单GPU或少量GPU训练10倍于原生PyTorch的模型规模。DeepSpeed团队在2020年推出ZeRO-Offload,旨在“民主化”亿级参数模型训练,让更多人能参与AI创新。
为什么需要它? 传统训练中,GPU内存往往是瓶颈——参数、梯度、激活值和优化器状态(如Adam的动量和方差)会迅速耗尽空间。ZeRO Offload利用CPU的更大内存(可达TB级)和计算能力,缓解这一问题。例如,在单V100 GPU + 1.5TB CPU内存上,你能轻松训练40亿参数模型。

2、ZeRO Offload的工作原理
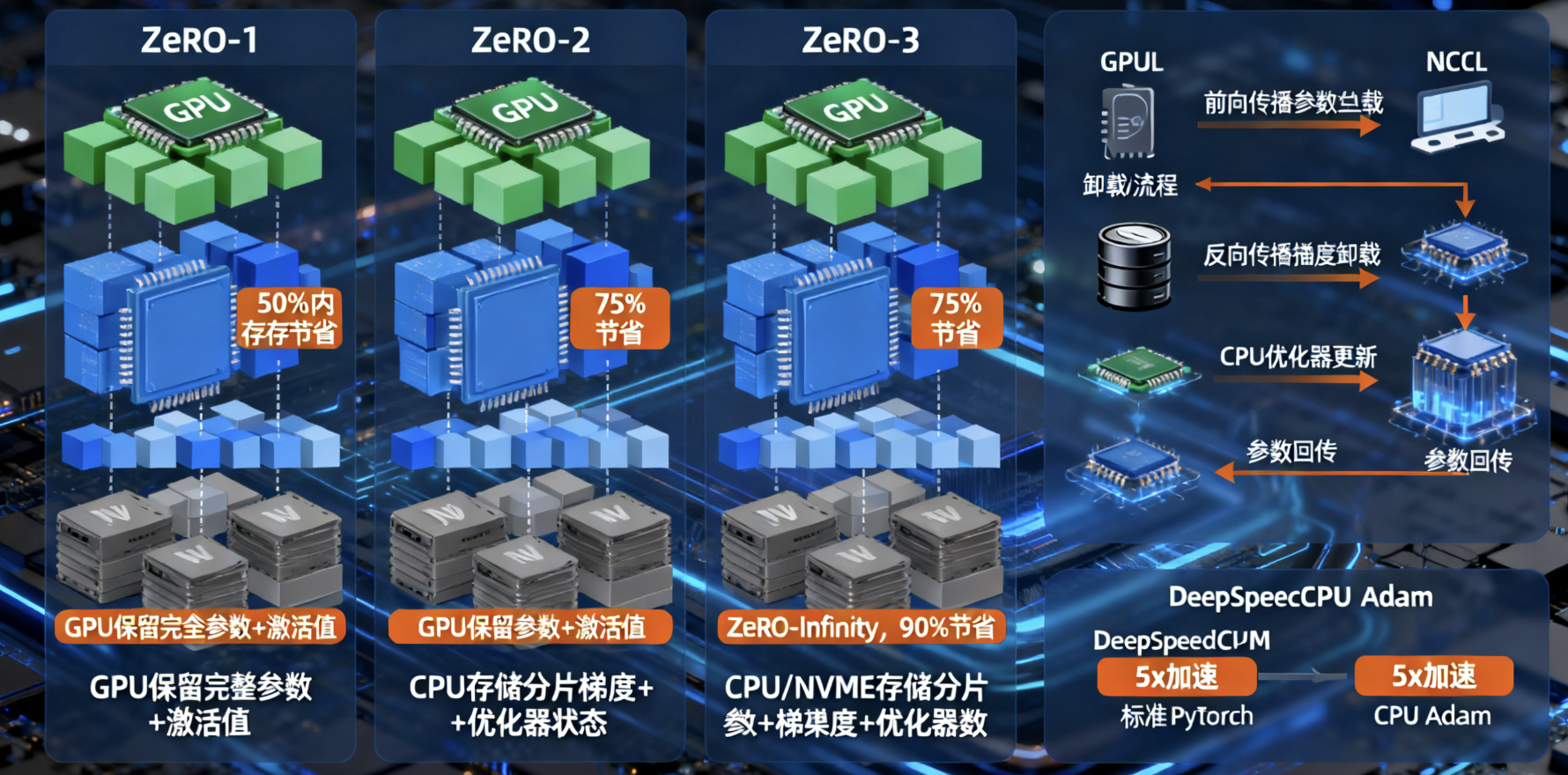
ZeRO Offload基于ZeRO的三个阶段逐步卸载,越来越彻底:
- ZeRO-1:分片优化器状态,并卸载到CPU。模型参数仍留在GPU,只优化器部分(如Adam的momentum和variance)移到CPU计算。这能节省约50%的GPU内存。
- ZeRO-2:在ZeRO-1基础上,分片梯度,并可选卸载到CPU。优化器计算也可移到CPU执行,进一步释放GPU空间。
- ZeRO-3:最强大,分片模型参数、梯度和优化器状态,支持卸载到CPU或NVMe(称为ZeRO-Infinity)。训练过程中,GPU只在需要时从CPU动态拉取参数,计算后推送更新回CPU。
卸载流程详解:
- 前向/反向传播:GPU执行核心计算,但参数可从CPU加载。DeepSpeed使用高效通信(如NCCL)最小化GPU-CPU数据传输延迟。
- 优化器步骤:使用DeepSpeedCPUAdam等优化器,将计算移到CPU,比标准PyTorch CPU Adam快5倍。
- 内存管理:动态分区和重用内存,避免I/O瓶颈。ZeRO-Infinity甚至能利用NVMe存储,进一步扩展规模。
相比ZeRO++(另一个优化变体,聚焦通信效率),ZeRO Offload更注重内存节省,尤其适合单机多卡或云环境。
3、ZeRO Offload的优势与实际益处
为什么ZeRO Offload这么受欢迎?来看看它的核心优势:
- 内存效率爆表:显著降低GPU内存占用,支持更大模型或批次大小。单GPU可训13B参数模型,比原生方法大10倍。
- 成本大幅降低:无需数百张GPU集群,适合预算有限的开发者。在云平台上,这意味着更低的账单。
- 性能优化:GPU专注高吞吐计算,CPU处理优化器步骤。结合混合专家模型(MoE),可扩展到万亿参数。
- 灵活性强:支持长序列训练(如Transformer模型),兼容NVIDIA/AMD GPU。实测在A100上,训练速度仅略微牺牲,但内存收益巨大。
- 实际影响:在Hugging Face生态中,ZeRO Offload常用于PEFT(参数高效微调),让社区用户轻松微调大模型。
总之,它让AI训练更“民主化”,从学术到工业,都能受益。
4、如何配置和使用ZeRO Offload?
配置简单,主要通过JSON文件或命令行。以下是实战指南:
4.1、基本JSON配置示例
使用DeepSpeed的zero_optimization字段启用Offload:
{
"zero_optimization": {
"offload_optimizer": {
"device": "cpu", // 或 "nvme" for ZeRO-Infinity
"pin_memory": true // 加速数据传输
},
"offload_param": {
"device": "cpu"
},
"cpu_offload": true // 启用开关(旧版)
},
"zero_optimization_stage": 2 // 选择阶段:1/2/3
}- offload_optimizer:卸载优化器到CPU。
- offload_param:卸载参数到CPU。
- 对于ZeRO-1,参考专用配置。
4.2、命令行启用
在训练脚本中添加参数:
deepspeed --cpu_offload your_script.py --model_size large4.3、代码集成示例(PyTorch + Hugging Face)
import deepspeed
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("gpt2-large")
ds_config = "ds_config.json" # 你的JSON文件
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
config=ds_config
)
# 开始训练...结合Hugging Face Trainer:
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args, # 包含 --deepspeed ds_config.json
)
trainer.train()从简单模型测试开始,逐步增大规模。
5、潜在挑战与注意事项
ZeRO Offload并非完美,以下是关键点:
- 性能权衡:CPU计算慢于GPU,可能导致训练速度下降5-20%。使用梯度检查点(gradient checkpointing)可缓解。
- 硬件要求:需要充足CPU内存和带宽。兼容PyTorch 1.8+,NVIDIA GPU最佳。
- 常见问题:如果CPU资源不足,可能崩溃。建议结合梯度裁剪避免爆炸。
- 扩展建议:与DeepSpeed其他功能如MoE结合,用于长上下文训练。
测试时从小批次开始,监控内存使用。
6、结语:开启你的AI训练之旅
DeepSpeed ZeRO Offload彻底改变了大型模型训练的游戏规则,让有限资源也能创造无限可能。如果你正为GPU内存烦恼,不妨试试这项技术——从官网教程入手,快速上手。
想分享你的训练经验?在评论区留言!订阅博客获取更多AI优化技巧。如果你需要代码示例或自定义配置,欢迎联系。让我们一起推动AI前沿!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 8
8 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)