LLaVA模型学习-周报十四
本周系统学习了LLaVA多模态大模型的理论框架与部署实践。深入解析了LLaVA的架构设计思想——通过CLIP视觉编码器提取图像特征,结合Projection层实现视觉-语言特征维度对齐,采用两阶段训练策略(先冻住主干网络单独训练映射层,再微调语言模型);完整实践了服务器环境下的模型部署流程,包括环境配置、权重下载、CLI推理与Web端服务搭建,解决了fastapi版本冲突等实际问题。研究建立了从多
摘要
本周系统学习了LLaVA多模态大模型的理论框架与部署实践。深入解析了LLaVA的架构设计思想——通过CLIP视觉编码器提取图像特征,结合Projection层实现视觉-语言特征维度对齐,采用两阶段训练策略(先冻住主干网络单独训练映射层,再微调语言模型);完整实践了服务器环境下的模型部署流程,包括环境配置、权重下载、CLI推理与Web端服务搭建,解决了fastapi版本冲突等实际问题。研究建立了从多模态理论理解到实际工程部署的完整能力闭环。
Abstract
This week systematically studied the theoretical framework and deployment practices of LLaVA multimodal large model. In-depth analysis was conducted on LLaVA’s architectural design—using CLIP visual encoder for image feature extraction, Projection layer for vision-language feature alignment, and two-phase training strategy (first freezing backbone to train mapping layer, then fine-tuning language model). Completed end-to-end model deployment in server environment, covering environment configuration, weight downloading, CLI inference, and web service setup, while resolving practical issues like fastapi version conflicts. The research established a complete capability闭环 from multimodal theory understanding to practical engineering deployment.
1、LLaVA模型学习
1.1 基本信息
论文:https://arxiv.org/pdf/2304.08485.pdf
项目:https://llava-vl.github.io/
LLaVA的模型结构就是CLIP+LLM(Vicuna,LLaMA结构),利用Vison Encoder将图片转换为[N=1, grid_H x grid_W, hidden_dim]的feature map,然后接一个插值层Projection W,将图像特征和文本特征进行维度对齐。经过Projection后,得到[N=1, grid_H x grid_W=image_seqlen, emb_dim]。然后将 image token embedding和text token embedding合并到一起,作为语言模型的输入,生成描述的文本。
1.2 核心
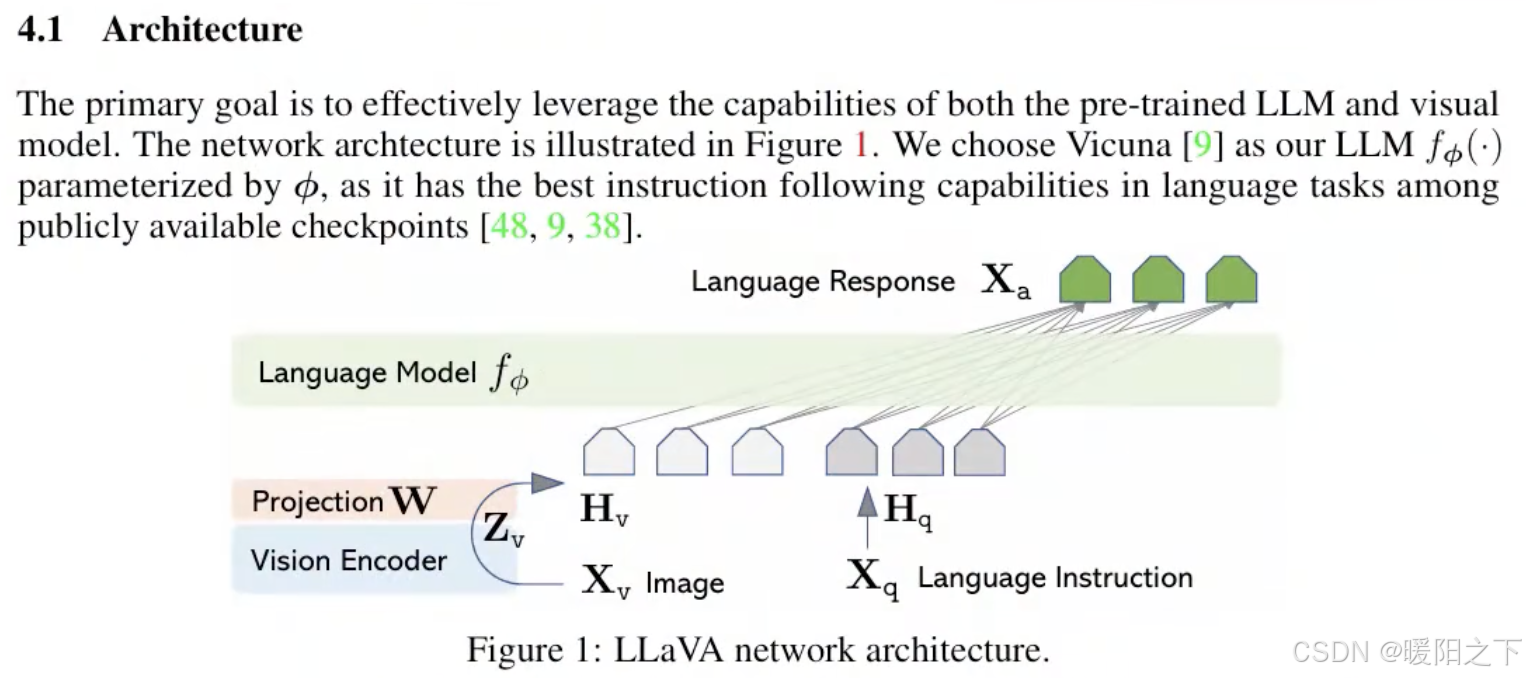
图像和语言的向量不能直接拼在一起,因为维度是不一样的。
举个例子:我去你家住一个月,我得先学习一下你家的规则,让我去理解你的生活方式。所以这一块有一个维度转换的问题。
所以先把视觉特征进过Projection W去训练,然后再和文本特征进行合并。
举个🌰:我搬去你家住,以后要一起工作,肯定不是一上来就直接工作,我得先适应你的生活方式(比如几起床、用啥东西等)。但是如果你的生活方式在变,我学的都没你变的快,那肯定学不好。所以大模型的训练会分为两阶段:先适应这个模型,再跟着这个模型去学。
第一阶段:Language和Vision层全部冻住,只学映射层Projection W。因为如果大模型在微调,Projection W也在微调,肯定学不好。
为什么视觉层不需要学?因为视觉层不是用来输出结果,它只是把一张图像编码成一个向量,即视觉特征提取。所以第一阶段单独训练Projection层。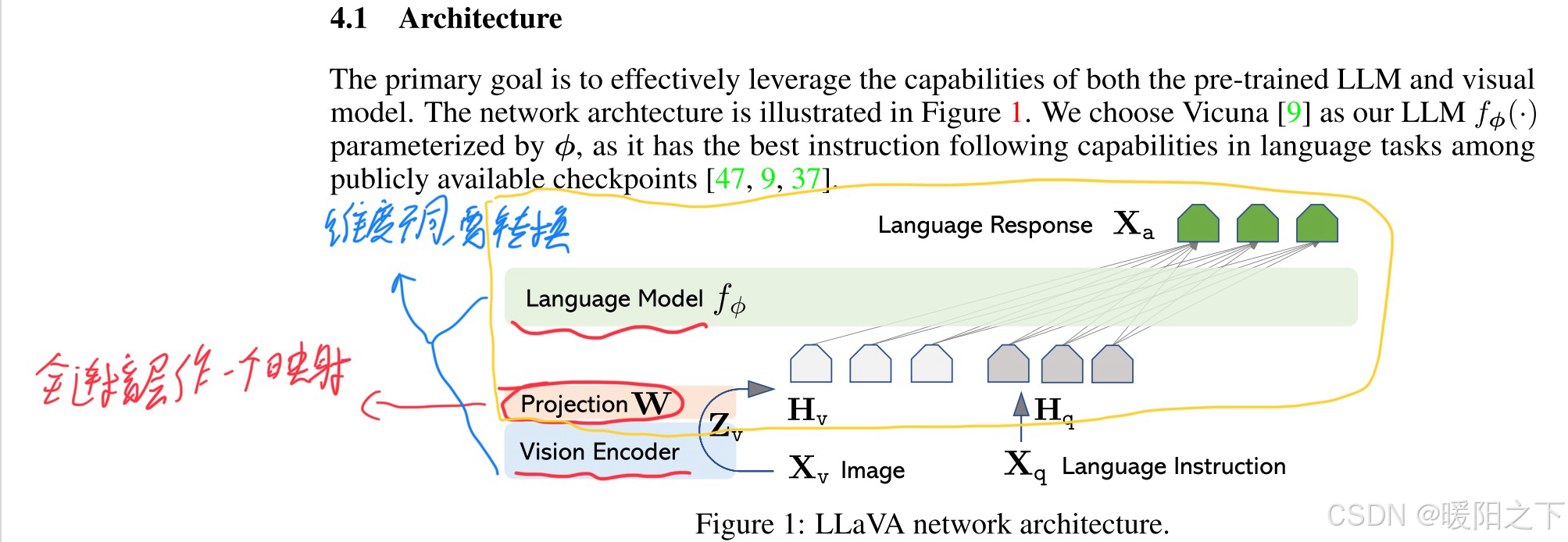
第二阶段:训练大模型层(上图黄色部分圈起来部分),因为这部分要做输出。
文本向量和图片向量不是按照A的形式,而是按照B的形式进行拼接的,这点要注意。
2、LLaVA模型服务器部署
Step1:环境配置
1、克隆仓库
git clone git@github.com:haotian-liu/LLaVA.git
cd LLaVA
2、安装package
conda create -n llava python=3.10 -y
conda activate llava
pip install -e .
3、安装训练所需的package(若无需进一步训练,只是部署,则可暂时跳过本步骤)
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
Step2:LLAVA模型下载
由于服务器联网问题,无法直接使用git clone https://huggingface.co/liuhaotian/llava-v1.5-7b下载对应的模型。因此这里先在本地下载好模型,再上传到服务器。模型下载网址:
- 7B:https://huggingface.co/liuhaotian/llava-v1.5-7b/tree/main
- 13B:https://huggingface.co/liuhaotian/llava-v1.5-13b
注意别下成了hf版本
下载完模型后,把模型上传到服务器当中。在创建一个文件夹保存权重,命名为llava-v1.5-7b(如果是13B就是llava-v1.5-13b,注意这里的命名不要错了,后面有代码会解析这个名字)

Step3:vit模型下载
如果服务器可以正常连接hugging face,那么直接跳过本步骤即可。但如果脚本报了与openai/clip-vit-large-patch14-336相关的错误,就是连接hugging face的问题,导致代码无法自动下载vit模型,则需要按照下面的步骤执行:
1、在电脑主机下载下面链接的文件:
https://huggingface.co/openai/clip-vit-large-patch14-336
2、在服务器中创建一个名为clip-vit-large-patch14-336的文件夹,并把刚刚下载好的文件上传到这个文件夹下。

3、修改在Step2中llava-v1.5-7b/config.json文件,把"mm_vision_tower"修改为刚刚上传的clip-vit-large-patch14-336文件夹路径。

Step4:启动demo
在做完上述准备工作,我们就可以来测试部署的LLaVA了。总共有两种测试方法:
- CLI推理
- 网页端测试
1、CLI推理
运行下面的命令:
python -m llava.serve.cli --model-path {模型权重路径} --image-file "https://llava-vl.github.io/static/images/view.jpg" --load-4bit
注意,这个–model-path要换成你在Step2中权重文件夹的路径,–image-file后面可以换成你自己想要交流的图片,–load-4bit,是使用量化位(4 位)启动模型工作线程,减少GPU内存占用的情况下运行推理。
2、网页端测试
1.在第一个终端中启动控制器:
python3 -m llava.serve.controller --host 0.0.0.0 --port 20000

2.在第二个终端启动 gradio [Web 服务器](https://so.csdn.net/so/search?q=Web 服务器&spm=1001.2101.3001.7020):
python3 -m llava.serve.gradio_web_server --controller http://localhost:20000 --model-list-mode reload --share

注意上面标红的URL,最后是在这里测试LLaVA的网页的。(注意:如果是在服务器中运行,主机上打开网页,应当用服务器网址替换0:0:0:0,即在主机浏览器中网页输入的网址应该是:服务器ip:端口号,端口号在图中为7861)
运行了这两行代码之后终端1会出现一个连接(我的是http://127.0.0.1:7860). 但是我尝试打开这个连接时失败了,关闭了防火墙也不行。在平台上查找之后找到了一个能行的解决方案:
在本地电脑的cmd上运行:
ssh -CNg -L 7860:127.0.0.1:7860 root@password -p 42354
这里root@password -p 42354需要替换成目标服务器的实际端口,并且 7860:127.0.0.1:7860 也要替换成目标访问地址。
3.在第三个终端启动model worker
python3 -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:20000 --port 40000 --worker http://localhost:40000 --model-path {模型权重路径} --load-4bit

注意model-path需要替换成实际的路径
这里我又遇到了error: pydantic.errors.PydanticSchemaGenerationError: Unable to generate pydantic-core schema for
查找资料后发现降级fastapi即可:
pip install -U fastapi==0.112.4
最后打开前面说的测试LLaVA的网页

就能开启相关服务了。
至此,LLaVA模型部署完毕。
总结
本周通过理论与实践相结合的方式,深度掌握了LLaVA多模态模型的核心机制与部署方法:在理论层面,重点理解了LLaVA的创新训练策略——第一阶段冻结视觉编码器(CLIP)和语言模型(Vicuna),单独训练Projection映射层实现视觉特征到语言空间的维度转换;第二阶段解锁语言模型进行端到端微调,使模型学会结合视觉信息生成准确描述;在实践层面,完整走通了服务器部署全流程:从环境配置、模型权重获取,到三种服务启动方式,并解决了实际部署中的关键问题。下周将深入研究代码核心设计以及其他多模态模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 29
29 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)