【AI论文】Hala技术报告:大规模构建以阿拉伯语为中心的指令与翻译模型
摘要:本研究提出Hala系列阿拉伯语指令与翻译模型,采用创新的"翻译-调优"流程构建。通过FP8量化将AR↔EN教师模型压缩至近2倍吞吐量,生成高质量双语数据用于微调轻量级模型LFM2-1.2B,进而构建百万级阿拉伯语指令语料库。研发350M-9B不同参数规模的模型,结合球面线性插值技术优化性能。在阿拉伯语基准测试中,Hala在纳米级(≤2B)和小型(7-9B)类别均取得领先成
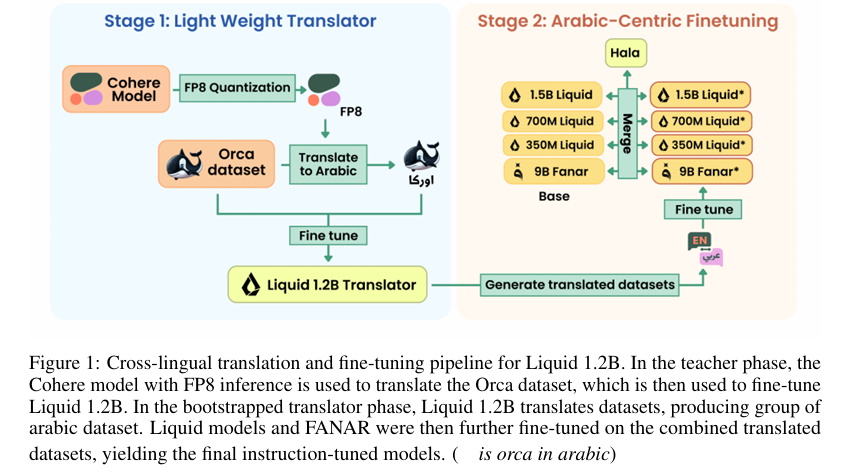
摘要:我们推出Hala——这是一系列以阿拉伯语为中心的指令与翻译模型,采用我们自主研发的“翻译-调优”流程构建而成。我们首先将一个性能强劲的阿拉伯语↔英语(AR↔EN)教师模型压缩至FP8格式(在保证质量无损的前提下,吞吐量提升至原来的近2倍),并利用该模型生成高保真双语监督数据。随后,我们使用这些数据对轻量级语言模型LFM2-1.2B进行微调,并借助其将高质量英文指令集翻译为阿拉伯语,从而构建出针对指令遵循任务的百万级语料库。我们训练了参数量分别为3.5亿、7亿、12亿和90亿的Hala模型,并采用球面线性插值(slerp)融合策略,在保持基础模型优势的同时强化阿拉伯语专项能力。在以阿拉伯语为核心的基准测试中,Hala在“纳米级”(≤20亿参数)和“小型”(70-90亿参数)两个类别中均取得领先成果,性能超越其基础模型。我们公开了模型、数据、评估工具及训练方案,以推动阿拉伯语自然语言处理领域的研究发展。Huggingface链接:Paper page,论文链接:2509.14008
研究背景和目的
研究背景:
近年来,大型语言模型(LLMs)在通用自然语言处理(NLP)领域取得了显著进展,展示了在少样本学习、指令跟随和复杂推理方面的强大能力。早期里程碑如GPT-3推动了这一进程,而后续家族如Gemini、Claude 3等不断扩展能力边界和可靠性。同时,开源模型如DeepSeek、LLaMA 3、Qwen等加速了社区对模型扩展、对齐和高效部署的研究。然而,在多语言建模方面,尽管有广泛覆盖的数据集和工程管道支持多语言语料库的构建,但特定语言(尤其是资源稀缺语言)的深度和文化适应性仍然不足。
阿拉伯语作为一种形态丰富、方言多样的语言,面临着独特的挑战。尽管已有一些阿拉伯语中心的预训练模型(如AraBERT)、基础模型和聊天模型(如JAIS、FANAR)以及主权AI努力(如Falcon),但高质量阿拉伯语指令数据的稀缺性仍然限制了指令微调和模型扩展的效果。现有基准测试如Arabic-MMLU为模型评估提供了初步框架,但其覆盖范围和难度仍相对有限。因此,开发专门针对阿拉伯语优化的语言模型成为迫切需求。
研究目的:
本研究旨在通过构建一个高效的翻译与微调管道,开发一系列阿拉伯语中心的指令和翻译模型(命名为Hala),以解决阿拉伯语指令数据稀缺的问题。具体目标包括:
- 压缩与量化:将一个强大的多语言翻译模型压缩至FP8精度,同时保持翻译质量,以提高推理效率。
- 构建双语监督数据:利用压缩后的翻译模型构建高质量的阿拉伯语-英语双语监督数据,以支持轻量级语言模型的微调。
- 翻译与生成指令数据:将多个高质量的英语指令数据集翻译成阿拉伯语,生成一个大规模的阿拉伯语指令遵循语料库。
- 训练与优化:在不同参数规模下训练Hala模型,并通过模型合并技术平衡阿拉伯语专业性与基础模型的能力。
- 评估与发布:在多个阿拉伯语中心基准测试上评估模型性能,并发布模型、数据、评估脚本和训练配方,以加速阿拉伯语NLP研究。
研究方法
1. 翻译模型的压缩与量化:
使用LLM Compressor将CohereLabs的高容量多语言翻译模型(command-a-translate-08-2025)压缩至FP8精度,并通过动态缩放确保翻译质量不受影响。压缩后的模型(hammh0a/command-a-translate-FP8-Dynamic)在保持翻译质量的同时,推理吞吐量提高了约两倍。
2. 构建双语监督数据:
从Open-Orca数据集中翻译前405K个指令-响应对到阿拉伯语,并与原始英语对形成双语元组。同时,从OPUS-100的阿拉伯语-英语子集中筛选出高质量的双语对,使用紧凑的判断模型(Qwen2.5-3B-Instruct)进行质量过滤,最终得到约126万双语例句。
3. 翻译与生成指令数据:
利用上述双语数据微调一个轻量级的多语言翻译模型(LiquidAI/LFM2-1.2B),使其成为专门用于指令风格输入的快速、稳定的阿拉伯语-英语翻译器。然后,将该翻译器应用于多个高质量英语指令数据集(如Hermes3、SCP-116K、ReAlign-Alpaca等)的翻译,生成一个包含约450万样本的阿拉伯语指令遵循语料库。
4. 训练与优化Hala模型:
在不同参数规模(350M、700M、1.2B和9B)下微调基础模型(基于LiquidAI检查点和FANAR架构),并使用球形线性插值(slerp)进行模型合并,以平衡阿拉伯语专业性与基础模型的能力。
5. 评估与发布:
在六个阿拉伯语中心基准测试(AlGhafa、AraTrust、ArabicMMLU、ArbMMLU-HT、EXAMS、MadinahQA)上评估模型性能,并使用LightEval框架和vLLM后端进行高效、可重复的推理。同时,发布模型、数据、评估脚本和训练配方,以促进社区研究和应用。
研究结果
1. 模型性能:
Hala模型在多个阿拉伯语中心基准测试上取得了显著提升。在纳米级(≤2B)模型中,Hala-1.2B相比基础模型(LiquidAI/LFM2-1.2B)在平均性能上有了显著提高,达到了同类最佳水平。在小型(7B-9B)模型中,Hala-9B持续超越之前的最先进基线(QCRI/Fanar-1-9B-Instruct),同时在单个任务上保持竞争力。
2. 翻译质量:
通过对比FP8和FP16版本的教师翻译模型,发现FP8模型在保持翻译质量的同时显著提高了推理效率。此外,轻量级翻译模型(基于LFM2-1.2B)在翻译指令风格数据时表现出色,显著提高了翻译质量。
3. 数据效率:
通过构建大规模的阿拉伯语指令遵循语料库,解决了阿拉伯语指令数据稀缺的问题。实验表明,即使在小规模模型上,基于高质量阿拉伯语指令数据的微调也能带来显著的性能提升。
研究局限
1. 数据覆盖范围和多样性:
尽管构建了大规模的阿拉伯语指令遵循语料库,但数据的覆盖范围和多样性仍可能有限。特别是某些特定领域或复杂场景的指令数据可能仍然不足,影响模型在这些任务上的表现。
2. 模型规模和效率的平衡:
虽然通过模型合并技术平衡了阿拉伯语专业性与基础模型的能力,但在更大规模模型上的扩展仍面临挑战。如何在保持模型效率的同时进一步提高性能,是未来研究需要解决的问题。
3. 方言和语体多样性:
阿拉伯语具有广泛的方言和语体变化,但当前模型主要针对现代标准阿拉伯语进行优化。如何更好地捕捉和适应不同方言和语体的特点,是提升模型实用性的关键。
未来研究方向
1. 扩展数据覆盖范围和多样性:
进一步收集和构建涵盖更多领域和场景的阿拉伯语指令数据,特别是那些当前数据集中缺失的部分。同时,考虑引入更多方言和语体的数据,以提高模型的适应性和实用性。
2. 优化模型规模和效率:
探索更高效的模型架构和训练策略,以在保持模型性能的同时降低计算成本。例如,可以研究模型剪枝、量化感知训练等技术,以进一步提高模型在资源受限环境下的部署能力。
3. 加强方言和语体适应性:
针对阿拉伯语的方言和语体多样性,开发专门的方言识别和适应模块。通过引入方言特定的语言特征和训练数据,提高模型在不同方言和语体上的表现。
4. 跨语言迁移学习:
利用跨语言迁移学习技术,将在其他语言上学习到的知识迁移到阿拉伯语模型中。通过共享底层表示和参数,提高模型在阿拉伯语上的表现,同时减少对大量阿拉伯语数据的依赖。
5. 持续评估和反馈循环:
建立一个持续的评估和反馈循环系统,定期评估模型在真实场景下的表现,并根据用户反馈进行迭代优化。通过引入更多实际应用场景的数据和评估指标,确保模型能够持续满足用户需求。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献147条内容
已为社区贡献147条内容

所有评论(0)