Agent实战01-理解 LLM API 的基本调用。
部署 (Deployment):通过在本地安装 Ollama,你拥有了一个私有化的大模型服务器。管理 (Management):使用命令管理模型的生命周期。交互 (Interaction)直接 HTTP 调用:理解 API 的原始请求和响应结构。使用 OpenAI 兼容库:这是最实用、最接近行业标准的方式,让你为 OpenAI 写的代码能轻松移植到本地环境。你现在已经掌握了 LLM API 调用的
本教程将带你完整体验一次“本地大模型”的部署与调用。你将学会如何将一台普通的个人电脑变成拥有强大 AI 能力的服务器,并通过编程与之对话。
模型使用
🌐 在线模型:需要联网,数据上传到云端,按使用次数付费。
💻 离线模型:本地运行,不需要网络,一次部署永久使用,数据更安全。
在线模型
geminikey申请
免费额度:60次/分钟请求(足够个人使用)
申请地址:https://ai.google.dev/gemini-api/docs/api-key?hl=zh-cn
使用google邮箱登录,点击获取api密钥
进入aistudio,要进入需要些手段。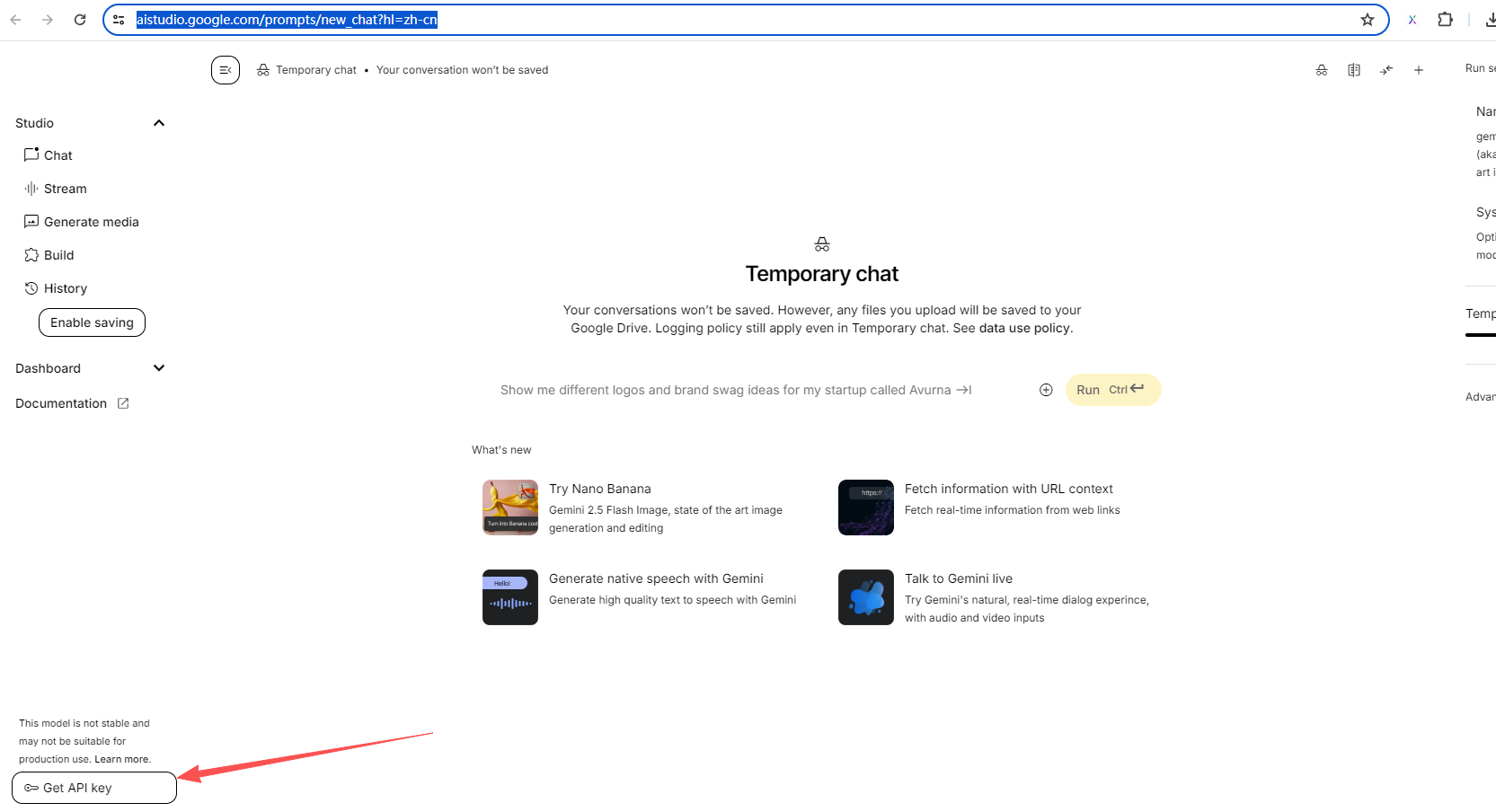
进入apikey申请页面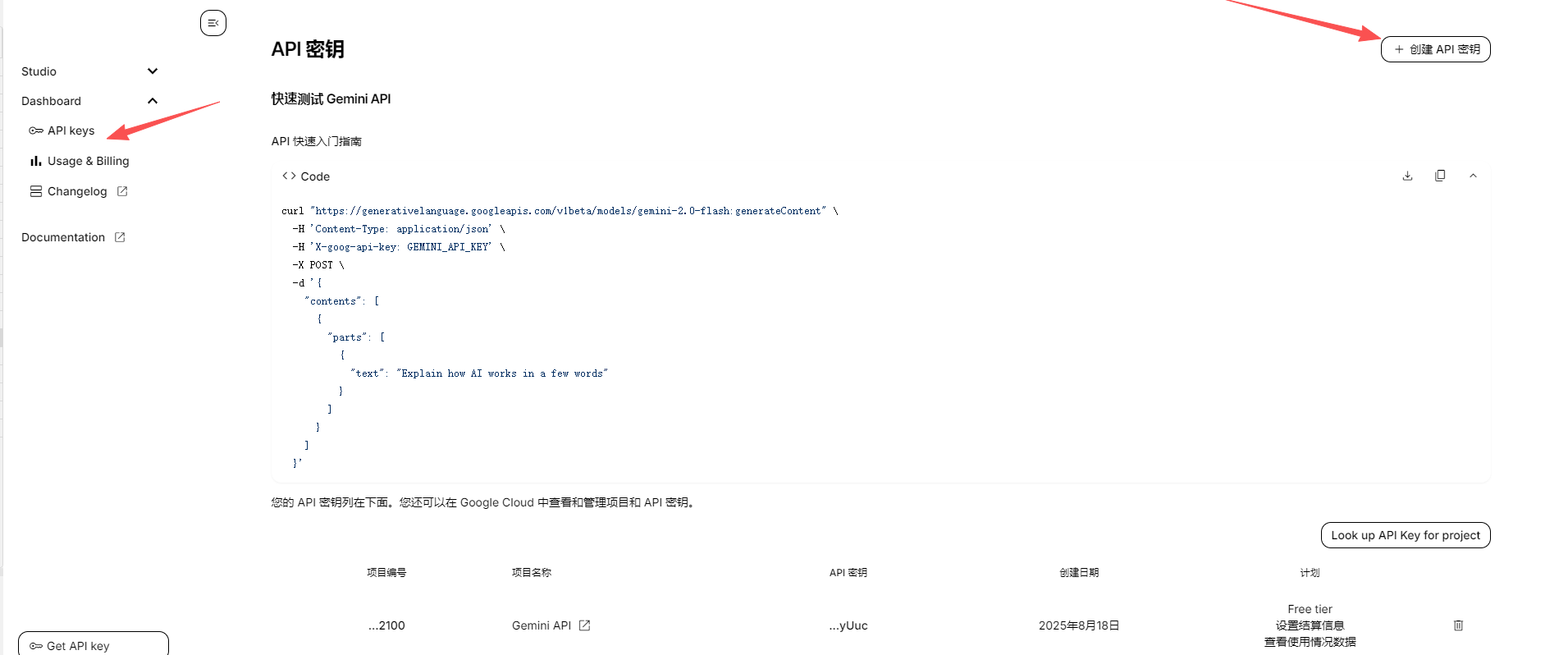
创建后得到一个apikey
硅基流动
硅基流动有很多免费的模型供调用,很多免费不做限制,可以用于学习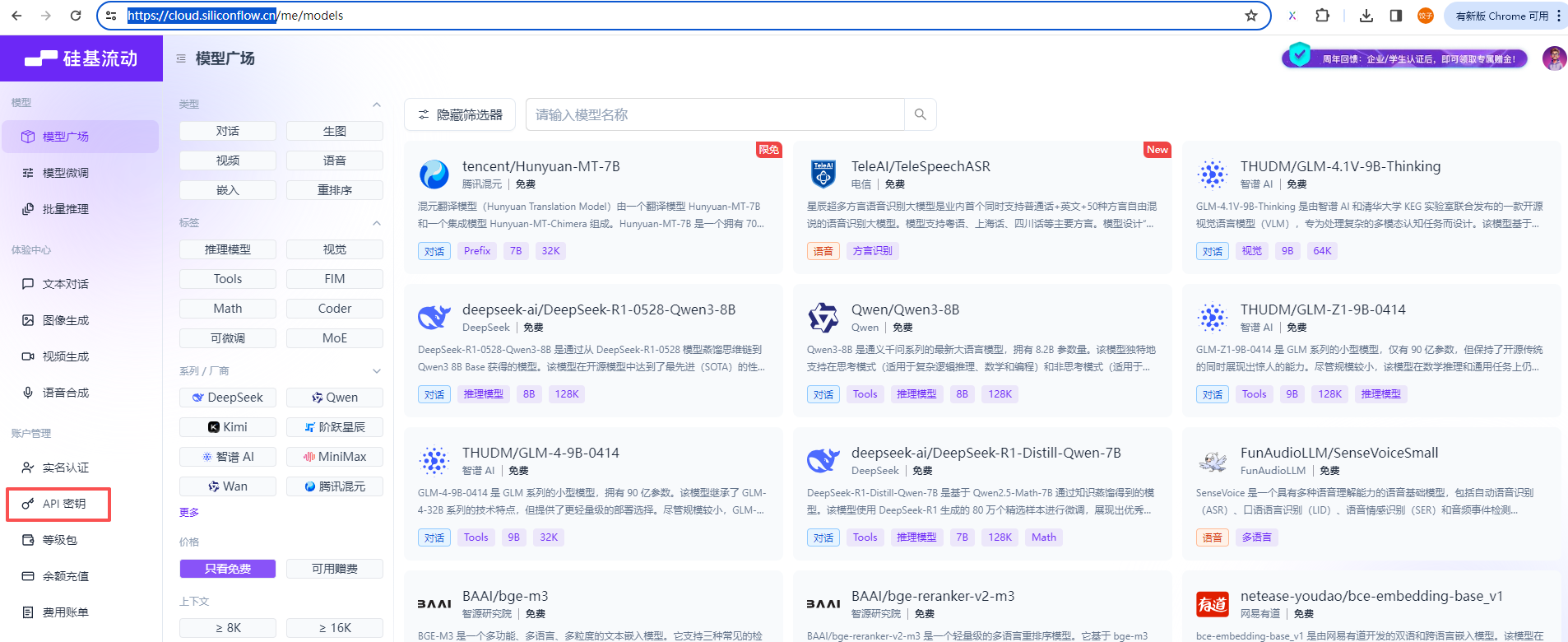
点击模型广场 点击展开筛选器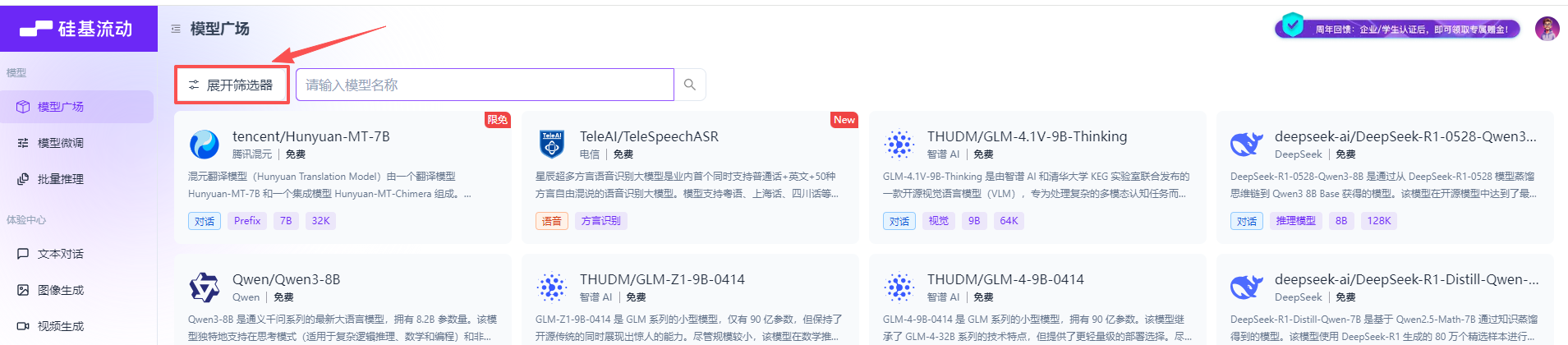
点击只看免费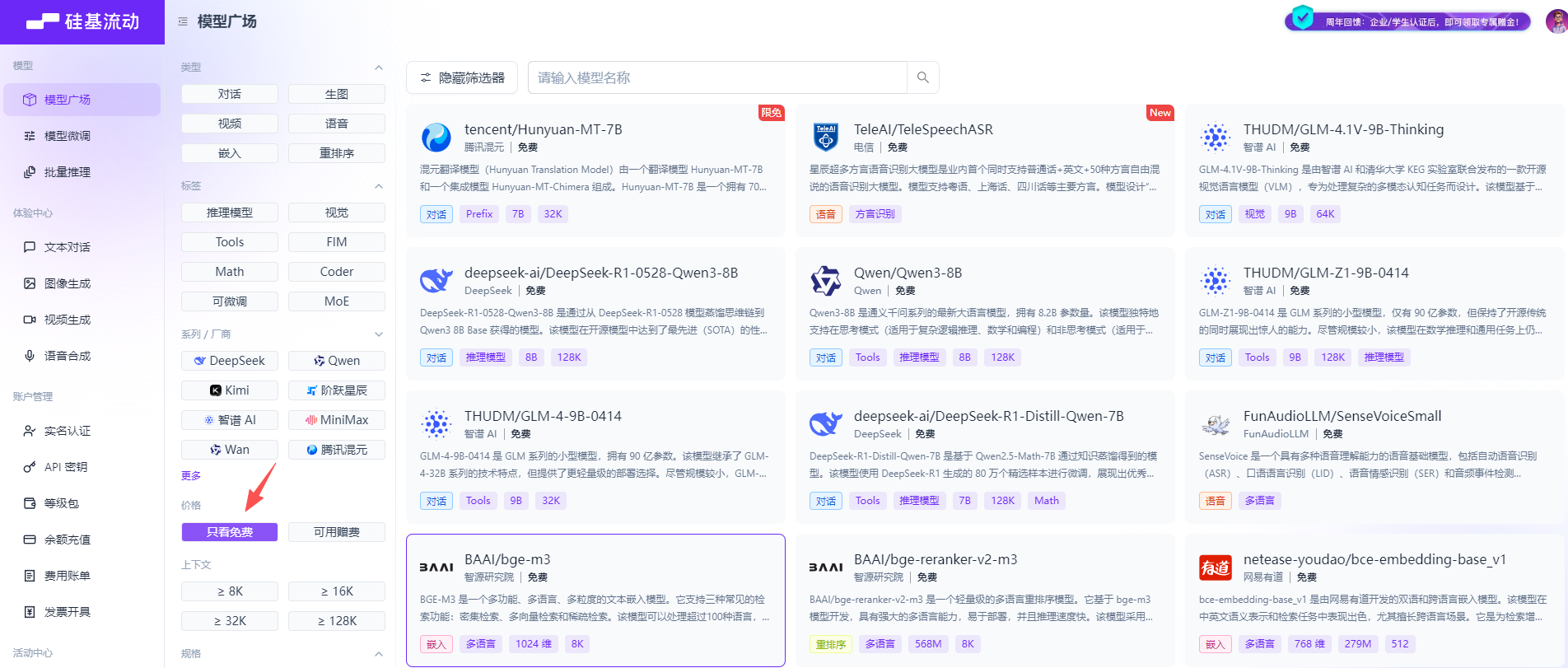
点击一个免费模型查看rpm和tpm
核心概念速览
| 指标 | 全称 | 中文 | 衡量对象 | 本质 |
|---|---|---|---|---|
| RPM | Requests Per Minute | 每分钟请求数 | 请求次数 | 调用频率 |
| TPM | Tokens Per Minute | 每分钟令牌数 | 文本处理量 | 处理负载 |
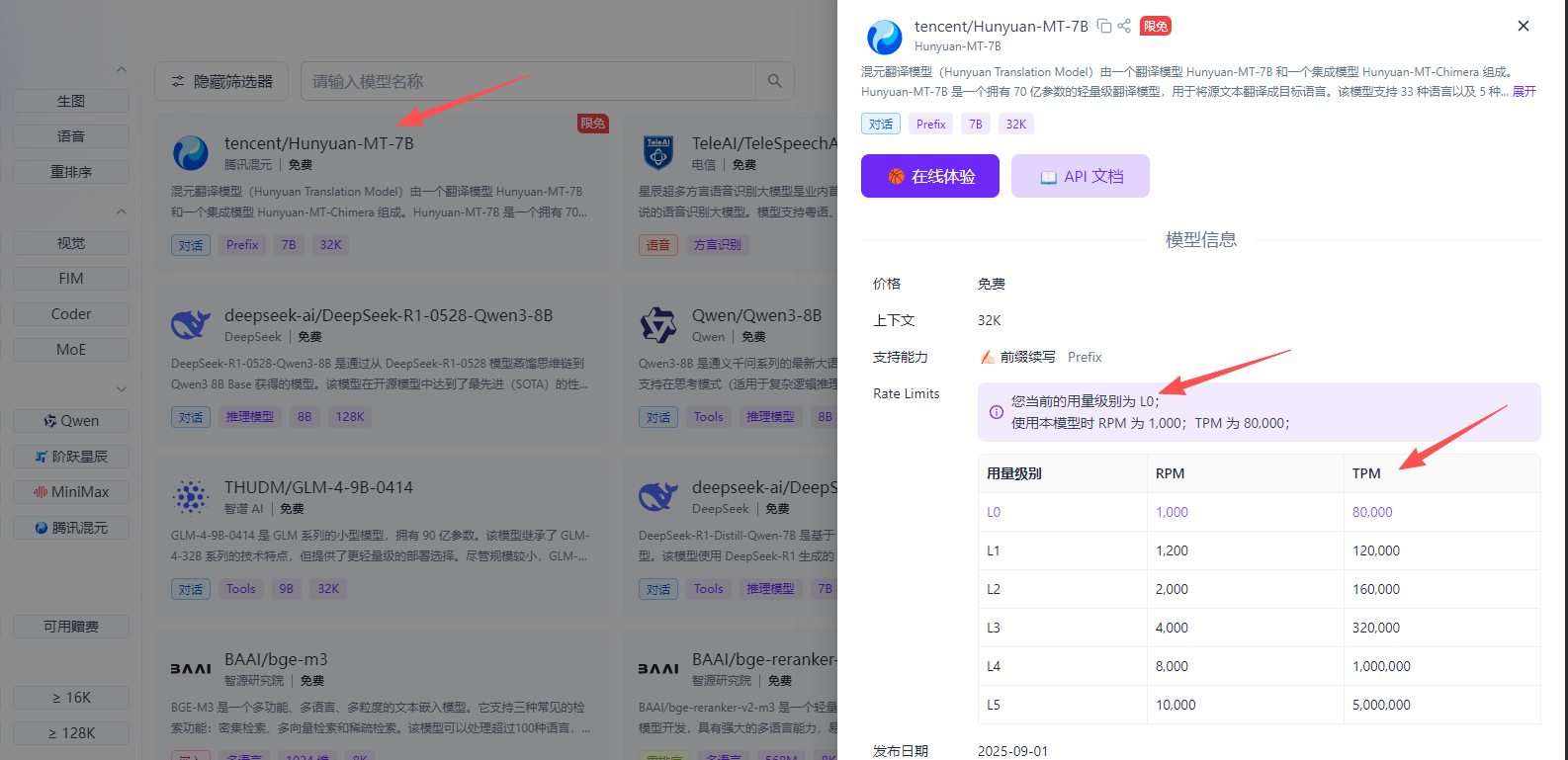
api地址:https://api.siliconflow.cn/v1
大部分的免费模型都很弱智,建议:deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
智谱ai申请
免费额度:500w免费token,无需魔法,注册即可用,用来学习完全够用,妥妥的国产清流,注册绑定手机就有免费apikey使用额度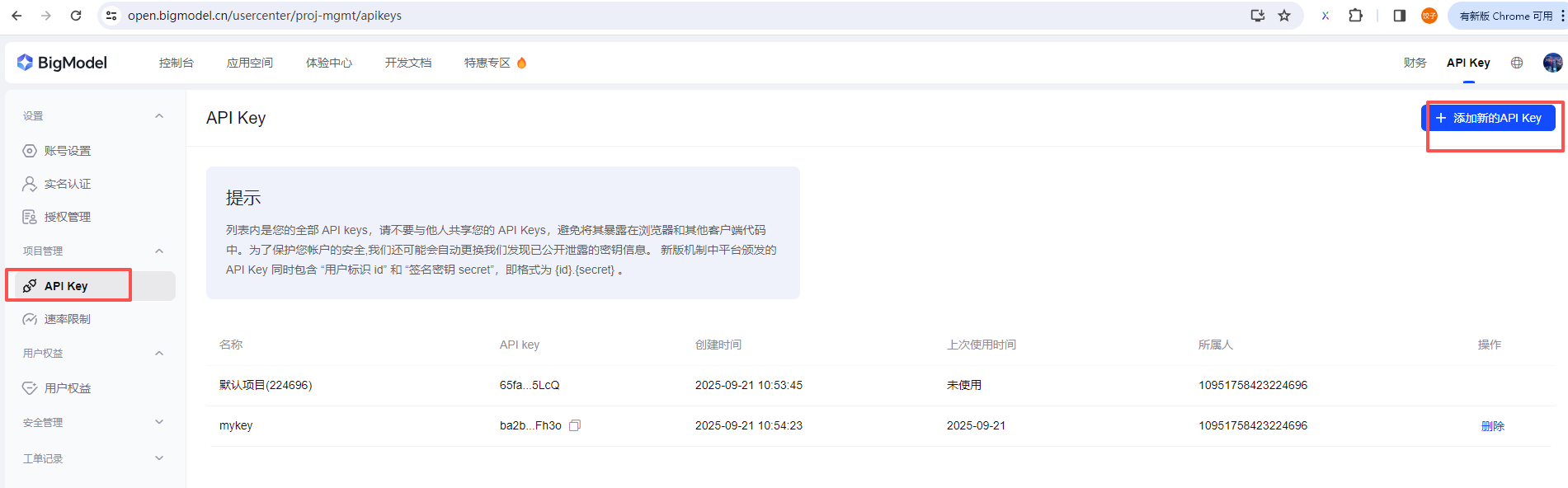
api地址:https://open.bigmodel.cn/api/paas/v4/
deepseek申请
进入deepseek官网登录,点击apikeys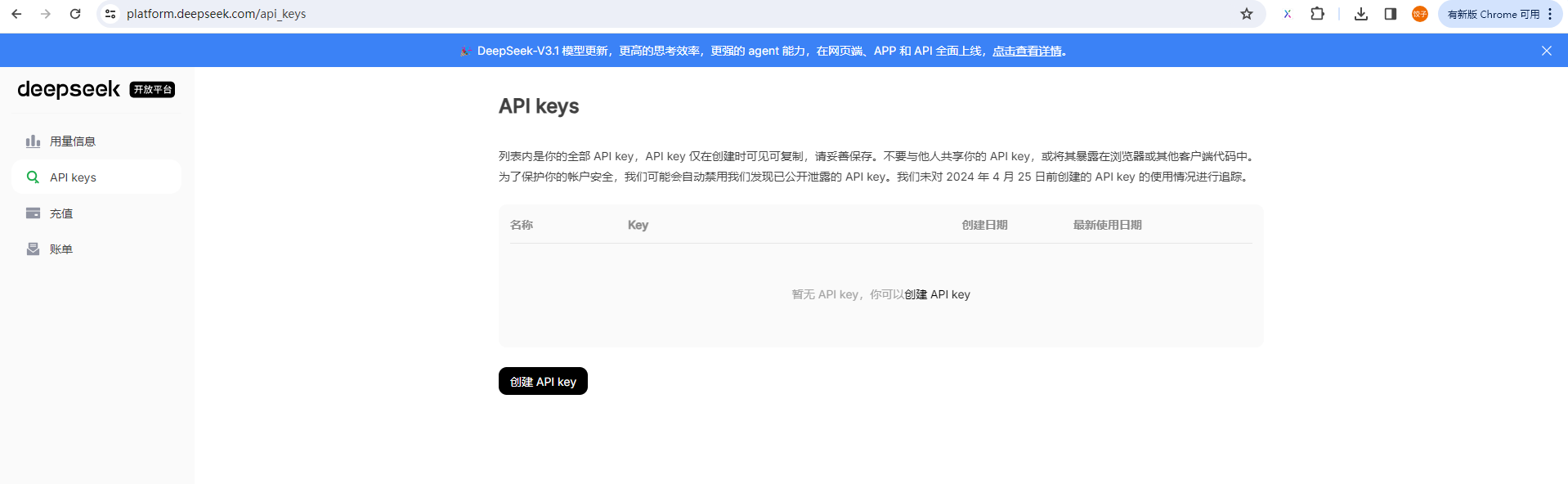
点击创建apikey即可,国内适合。
没有免费token,需要充值,有money可支持一波。
离线模型
安装 Ollama
Ollama 的安装过程非常简单,几乎是一键完成。
-
访问官方网站:
打开 Ollama 官网。 -
选择对应版本下载:
网站会自动检测你的操作系统(Windows/macOS/Linux)。点击 Download 按钮下载安装程序。 -
运行安装:
- Windows: 双击下载好的
.exe文件,按照提示完成安装。 - macOS: 将下载的
.dmg文件拖拽到Applications文件夹。 - Linux: 官网提供了便捷的安装命令,直接在终端(Terminal)中粘贴运行即可:
- Windows: 双击下载好的
curl -fsSL https://ollama.com/install.sh | sh
- 验证安装:
安装完成后,打开你的命令行(Command Prompt, Terminal, PowerShell),输入以下命令:
ollama --version
ollama version is 0.6.0
如果成功显示版本号(如 ollama version 0.xx.xx),说明安装成功。
下载你的第一个模型
Ollama 的核心是管理模型。我们将下载一个优秀且轻量的开源模型:Llama 3。
- 在命令行中执行拉取命令:
ollama pull llama3

注意:
llama3是模型在 Ollama 库中的名称。你可以在 Ollama 官方库 找到更多模型,如mistral,gemma,phi3等。
Llama 3 是 Meta(Facebook 母公司)于 2024年4月 发布的最新一代开源大语言模型(LLM)系列。它的发布在 AI 社区引起了巨大轰动,被认为是推动开源 AI 发展的一座重要里程碑。
- 等待下载完成:
这个命令会从网上下载Llama 3模型的权重文件(大约 4-8 GB,取决于你选择的参数变体)。请耐心等待,这取决于你的网速,ollama支持断点续传,退出重新pull会从之前失败的位置开始。 - 验证模型:
下载完成后,你可以先在命令行里和它聊聊天,测试一下:
ollama run llama3
然后输入任何你想问的问题,例如 你好,请用中文做一下自我介绍。输入 /bye 可以退出聊天。
恭喜!至此,一个功能完整的大语言模型已经在你本地电脑上运行起来了!
模型api调用
通过 openai库 调用在线模型
这里使用智普的apikey编写测试案例。
非流式响应
from openai import OpenAI
# 关键步骤:初始化客户端
# 注意 base_url 和 api_key 的设置
client = OpenAI(
base_url = 'https://open.bigmodel.cn/api/paas/v4/', # Ollama 的兼容 API 地址
api_key = 'ba2ba3894bb440b3a48b7aca44106344.5nGhXiXXXXXXXXX #申请key
)
# 接下来的代码和调用真正的 OpenAI API 几乎一模一样!
response = client.chat.completions.create(
model="glm-4.5", # 指定本地模型名称
messages=[
{"role": "system", "content": "你是一个乐于助人的AI助手,请用中文回答。"}, # 系统提示,设定AI角色
{"role": "user", "content": "请解释一下什么是机器学习。"}
],
max_tokens=500, # 限制生成回答的最大长度
temperature=0.7, # 控制回答的随机性 (0.0-1.0)
)
# 打印回复
print(response.choices[0].message.content)
查看输出
D:\python\python380\python.exe C:\Users\admin\PycharmProjects\pythonProject\deepseekchat.py
# 机器学习简介
机器学习是人工智能的一个核心分支,它使计算机系统能够通过经验自动改进其性能,而无需进行明确的编程。
## 基本概念
机器学习的核心思想是让计算机从数据中学习模式和规律,并利用这些学习结果对新数据进行预测或决策。与传统编程不同,在传统编程中我们编写明确的规则来处理输入并产生输出,而在机器学习中,我们提供输入和期望的输出,让系统自己学习规则。
## 主要类型
机器学习通常分为三大类:
1. **监督学习**:系统从标记好的训练数据中学习(例如,识别图片中的猫狗,训练数据已标明哪些图片是猫,哪些是狗)
2. **无监督学习**:系统从未标记的数据中发现隐藏的模式(例如,客户分群)
3. **强化学习**:系统通过与环境交互并从反馈中学习(例如,游戏AI通过不断尝试学习如何获胜)
## 工作原理
机器学习算法通常通过以下步骤工作:
1. 收集和准备数据
2. 选择合适的模型
3. 训练模型(让模型从数据中学习)
4. 评估模型性能
5. 调整参数优化模型
6. 部署模型用于实际预测
## 应用领域
机器学习已广泛应用于各个领域,如:
- 医疗诊断
- 金融风险评估
- 语音识别和自然语言处理
- 推荐系统
- 自动驾驶
- 图像识别
通过机器学习,计算机能够处理复杂问题,从大量数据中提取有价值的信息,并随着经验的积累不断改进性能。
Process finished with exit code 0
非流式响应默认等待所有结果返回直到结束才打印内容,这样可能等待的时间过长,建议使用流式响应。
流式响应
from openai import OpenAI
# 初始化客户端
client = OpenAI(
base_url = 'https://open.bigmodel.cn/api/paas/v4/', # Ollama 的兼容 API 地址
api_key = 'ba2ba3894bb440b3a48b7aca44106344.5nGhXiXXXXXXXXX #申请key
)
# 发送流式请求
stream = client.chat.completions.create(
model="glm-4.5", # 指定本地模型名称
messages=[
{"role": "system", "content": "你是一个有帮助的中文助手。"},
{"role": "user", "content": "你好,什么是大模型?"}
],
temperature=0.7,
max_tokens=512,
stream=True # 关键:启用流式响应
)
# 逐字打印响应
print("开始流式响应:")
for chunk in stream:
if chunk.choices[0].delta.content is not None:
content = chunk.choices[0].delta.content
print(content, end='', flush=True) # 逐字打印,不换行
print("\n\n响应完成!")
通过 Python API 调用本地模型
现在我们进入正题:如何用代码(而不是命令行)与这个模型交互。Ollama 在安装后,会在本地启动一个 API 服务,地址通常是 http://localhost:11434。我们将通过两种方式调用它。
方法一:使用 requests 库(最基础的方式)
这种方式帮助你理解 API 调用的底层原理。
- 创建项目目录和文件:
创建一个新文件夹,例如ollama-agent,并在其中创建一个 Python 文件app.py。 - 安装必要的库:
确保你已安装requests库。
pip install requests
- 编写代码 (
app.py):
import requests
import json
# 定义 Ollama 服务器的 API 端点
url = 'http://localhost:11434/api/chat'
# 构建请求的载荷 (Payload)
# 这是我们“告诉”模型要做什么的核心部分
data = {
"model": "llama3", # 指定要使用的模型名称
"messages": [ # 对话消息的历史列表
{
"role": "user", # 消息角色是“用户”
"content": "请用中文回答。Python编程语言的主要优点是什么?请列出3点。"
}
],
"stream": False # 关闭流式传输,一次性返回完整结果
}
# 发送 POST 请求到 Ollama 服务器
response = requests.post(url, json=data)
# 检查请求是否成功
if response.status_code == 200:
# 解析返回的 JSON 数据
result = response.json()
# 从复杂的返回结构中提取出模型的回复消息内容
model_reply = result['message']['content']
print("模型回复:")
print(model_reply)
else:
print(f"请求失败,状态码:{response.status_code}")
print(response.text)
- 运行代码:
在终端中,进入ollama-agent目录,运行:
python app.py
稍等片刻,你就会看到模型通过 API 返回的答案!
注意你只要安装了ollama默认就已经开启了11434端口,你只需要pull对应的模型,在调用接口的时候指定模型就会自动启动模型回复。
d:\code>ollama list
NAME ID SIZE MODIFIED
llama3:latest 365c0bd3c000 4.7 GB About an hour ago
gemma3:12b 6fd036cefda5 8.1 GB 6 months ago
d:\code>netstat -aon | findstr 11434
TCP 127.0.0.1:11434 0.0.0.0:0 LISTENING 35740
方法二:使用 openai 库(推荐,与行业标准接轨)
Ollama 兼容 OpenAI API 的格式。这意味着你可以用为 ChatGPT 写的代码,无缝切换来调用你的本地模型!这是最推荐的方式。
- 安装 OpenAI 库:
pip install openai
- 编写代码 (
app_openai_style.py):
from openai import OpenAI
# 关键步骤:初始化客户端,但指向本地的 Ollama 服务
# 注意 base_url 和 api_key 的设置
client = OpenAI(
base_url = 'http://localhost:11434/v1', # Ollama 的兼容 API 地址
api_key = 'ollama' # 本地验证,可任意填写(但不能为空)
)
# 接下来的代码和调用真正的 OpenAI API 几乎一模一样!
response = client.chat.completions.create(
model="llama3", # 指定本地模型名称
messages=[
{"role": "system", "content": "你是一个乐于助人的AI助手,请用中文回答。"}, # 系统提示,设定AI角色
{"role": "user", "content": "请解释一下什么是机器学习。"}
],
max_tokens=500, # 限制生成回答的最大长度
temperature=0.7, # 控制回答的随机性 (0.0-1.0)
)
# 打印回复
print(response.choices[0].message.content)
- 运行代码:
python app_openai_style.py
建议使用流式响应,因为本地机能优先 本来就慢 ,等了半天还以为电脑卡死了
from openai import OpenAI
# 初始化客户端
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama"
)
# 发送流式请求
stream = client.chat.completions.create(
model="llama3",
messages=[
{"role": "system", "content": "你是一个有帮助的中文助手。"},
{"role": "user", "content": "你好,什么是大模型?"}
],
temperature=0.7,
max_tokens=512,
stream=True # 关键:启用流式响应
)
# 逐字打印响应
print("开始流式响应:")
for chunk in stream:
if chunk.choices[0].delta.content is not None:
content = chunk.choices[0].delta.content
print(content, end='', flush=True) # 逐字打印,不换行
print("\n\n响应完成!")
总结与核心概念
通过本实战教程,你完成了以下关键步骤:
-
部署 (Deployment):通过在本地安装 Ollama,你拥有了一个私有化的大模型服务器。
-
管理 (Management):使用
ollama pull命令管理模型的生命周期。 -
交互 (Interaction):学会了两种与模型 API 交互的方式:
- 直接 HTTP 调用:理解 API 的原始请求和响应结构。
- 使用 OpenAI 兼容库:这是最实用、最接近行业标准的方式,让你为 OpenAI 写的代码能轻松移植到本地环境。
你现在已经掌握了 LLM API 调用的最核心技能。接下来,你可以:
- 尝试不同的模型(如
ollama pull mistral)。 - 在代码中尝试更复杂的多轮对话(在
messages数组中追加历史记录)。 - 调整参数(如
temperature,max_tokens)来观察生成效果的变化。 - 以此为基础,开始构建你的第一个 AI Agent!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)