联邦学习论文分享:Diffusion Model-Based Data Synthesis AidedFederated Semi-Supervised Learning
人工标注的标签,比如在图像分类中:一张猫的照片 → 标签是 “cat”一张狗的照片 → 标签是 “dog”
摘要
-
问题背景
-
联邦半监督学习(FSSL)面临两大挑战:
-
客户端标注数据稀缺;
-
各客户端数据分布非独立同分布(non-IID)。
-
-
-
提出的方法
-
提出一种基于扩散模型(diffusion model, DM)的数据合成方法 —— DDSA-FSSL。
-
思路是用扩散模型生成合成数据,缓解本地数据分布和全局分布的差异。
-
-
方法流程
-
客户端先用联邦训练得到的分类器对未标注数据做伪标签(pseudo labeling)。
-
扩散模型利用标注数据和经过优化的伪标注数据进行联合训练。
-
这样客户端能生成在本地数据中缺失类别的样本,从而构建更完整、接近全局分布的合成数据集。
-
-
实验结果
-
在多个数据集和不同程度的 non-IID 分布下验证有效性。
-
举例:在 CIFAR-10 数据集、只有 10% 有标注数据的情况下,准确率从 38.46% 提升到 52.14%
-
引言
1. 背景和问题
-
联邦学习 (FL):让多个客户端协作训练模型而不共享原始数据,保障隐私并利用分布式数据。
-
挑战:
-
客户端数据分布异质性(non-IID),导致全局模型和本地模型出现偏移(client drift)。
-
标注数据稀缺,获取标注成本高,而无标注数据相对充足。
-
2. 现有研究方向
-
联邦半监督学习 (FSSL):结合 FL 与半监督学习,利用未标注数据来缓解标注不足的问题。
-
SemiFed:通过一致性正则化和伪标签提高伪标签质量。
-
FedMatch:提出客户端有标签和服务端有标签两种场景,引入跨客户端一致性损失。
-
FedDure:用双调节器管理 non-IID 数据。
-
-
合成数据辅助联邦学习 (SDA-FL):利用生成模型合成数据来辅助训练。
-
SDA-FL:客户端用 GAN 生成数据,并结合伪标签机制提高一致性。
-
全局生成器方法:在 FL 框架下协作训练生成器来合成数据。
-
FedDISC:把预训练的扩散模型 (DM) 引入 FL,用原型和领域表示生成高质量数据。
-
3. 现有方法的不足
-
FSSL 和 SDA-FL 各有优点,但直接结合会有问题:
-
依赖预训练大模型可能存在 领域不匹配;
-
在 FSSL 场景下,训练高质量生成模型很困难,因为标注数据不足。
-
4. 本文贡献 (DDSA-FSSL)
-
提出 基于扩散模型的合成数据辅助联邦半监督学习 (DDSA-FSSL):
-
用全局分类器给无标签数据打伪标签;
-
通过 精度驱动的优化过程 提高伪标签质量;
-
用标注数据 + 优化后的伪标签数据来协作训练全局扩散模型;
-
扩散模型可生成本地缺失类别的样本,缓解 non-IID 问题。
-
5. 实验结果
-
DDSA-FSSL 显著提升分类性能。
-
在 CIFAR-10 上:
-
仅 10% 标注数据 + 双重异质性时,准确率从 38.46% 提升到 47.72%(10% 合成数据),
-
进一步到 53.01%(90% 合成数据)。
-
系统模型
1. 问题设定
-
考虑 联邦半监督学习 (FSSL) 场景,采用 labels-at-clients 设置(即只有客户端有标签数据,服务端没有)。
-
系统包含:
-
K 个客户端:各自持有本地数据;
-
一个中央服务器(基站/BS):协调联邦训练,但 不能直接访问客户端数据。
-
-
目标:通过 联邦聚合 算法训练一个全局分类器,参数记为 θ_g。
2. 客户端数据划分
每个客户端的数据分为两部分:
-
有标签数据集:
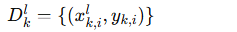
-
无标签数据集:

-
实际场景中,标注比例 λ 较小(因为标注很昂贵)。
-
数据分布特点:
-
每个客户端的有标签和无标签数据 只覆盖部分类别;
-
不同客户端之间的数据分布也高度 异质。
-
-
这种 少量标注 + 数据异质性 会严重影响 FL 的性能。
3. 提出的解决方案:c-LDM
-
在每个客户端引入 条件潜变量扩散模型 (c-LDM, conditional Latent Diffusion Model)。
-
对比:
-
传统 无监督 GAN → 无法生成特定类别的数据。
-
c-LDM → 能生成目标类别的数据,训练更稳定,生成质量和多样性更高。
-
-
为什么不用预训练的大模型(如 Stable Diffusion):
-
预训练模型基于大规模通用数据集,难以适配客户端的特定分布;
-
计算开销大,对资源有限的 FL 场景不友好。
-
补充
1. 核心思想
-
潜变量空间(Latent space):把原始数据(比如图像)先压缩成一个小的潜变量表示
z(通过 VAE 编码器)。 -
扩散过程(Diffusion):
-
正向过程:在潜变量上逐步加噪声,把清晰的图像表示变成随机噪声。
-
反向过程:训练一个网络(通常是 U-Net)学会逐步去噪声,把噪声还原成原来的潜变量表示。
-
-
条件生成(Conditional):模型可以根据输入的类别标签
c,只生成指定类别的样本(比如“生成数字 3”或者“生成猫的图片”)。
“ 每一步去噪的预测不仅依赖 z_t(噪声潜变量),也依赖 y ” 在去噪训练模型的时候,就已经训练了 模型 是在 类别xxx的条件下 去噪的,所以训练完的模型才会根据类别生成图像
2. 与传统 GAN 的对比
| 特性 | GAN | c-LDM |
|---|---|---|
| 控制生成类别 | 不容易(通常需要特定结构,如 cGAN) | 内置条件机制,可直接指定类别 |
| 稳定性 | 训练容易崩溃 | 更稳定,因为扩散过程本质上是逐步生成 |
| 多样性 | 可能模式坍缩 | 高,多样性更好 |
| 应用 | 生成全局分布 | 可生成缺失类别的样本,解决联邦学习中数据异质性问题 |
3. 通俗例子
假设你在做数字识别任务(MNIST),你的客户端数据只有 0、1、2 三类,但全局分布还包括 3、4、5……9。
-
目标:生成缺失的 3、4、5 类样本,让本地数据更全面。
-
c-LDM 做法:
-
把现有数字 0、1、2 编码成潜变量
z。 -
训练扩散模型学会从噪声逐步还原潜变量,同时加入类别条件
c=3。 -
模型就可以“想象”出类别 3 的潜变量,然后通过 VAE 解码器生成对应的图像。
-
结果:客户端现在拥有更多类别的样本,解决了数据缺失和分布不均问题。
总结:
-
c-LDM = 条件生成 + 扩散模型 + 潜变量表示
-
优势:
-
可以指定类别生成样本。
-
训练稳定,生成高质量、丰富多样的数据。
-
不依赖预训练的大模型,适合资源有限的 FL 场景。
-
补充
1. 通俗理解
假设你有一张猫的照片,图片是 64×64×3 的 RGB 图像,总共 12,288 个像素点。
-
直接用像素表示:每个像素是独立的特征,信息很冗余,训练模型很困难。
-
潜变量表示:把整张猫的图片压缩成一个 128 维的向量
z,这个向量隐藏了关键特征,例如:-
毛色深浅
-
耳朵形状
-
猫的姿势
-
-
你可以用这个 128 维向量 重建原图(通过解码器)或做其他操作(生成新猫、修改姿势等)。
潜变量 = “压缩后的核心特征向量”
2. 为什么有用
-
降维:减少数据复杂度,便于训练。
-
抽象语义:潜变量捕捉高维数据的本质特征,而非像素级细节。
-
生成能力:在潜变量空间进行操作,比直接操作原图更容易控制生成内容(比如改变类别、风格等)。
3. 类比生活中的例子
-
潜变量就像 人的 DNA 或图纸:
-
DNA 是生物体的潜在信息,可以决定头发颜色、身高等特征。
-
图纸是建筑的潜在信息,可以决定房子的形状、大小、结构。
-
-
虽然 DNA 或图纸本身不是成品,但可以通过“解码”生成真实的生物或房子。
-
潜变量
z就是模型的 DNA / 图纸,解码器就是建造实际图片的机器。
模型框架
利用伪标签增强数据
1. 问题背景
-
由于 标注数据稀缺 + c-LDM(条件扩散模型)训练复杂,无法直接训练一个高质量的生成器。
-
所以需要先利用 未标注数据 和 全局分类器 做伪标签生成,扩充可用数据。
2. 全局分类器的训练(FedAvg 过程)
-
客户端先基于各自的有标签数据
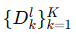 协同训练一个 全局分类器。
协同训练一个 全局分类器。 -
使用 FedAvg 算法进行参数更新:
-
每个客户端在本地做多轮梯度下降,得到本地参数 θrk。
-
服务端按数据量权重聚合各客户端参数:
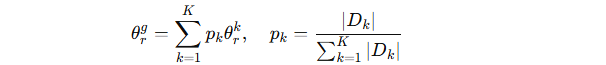
-
反复迭代,最终得到全局参数 θg。
-
3. 伪标签生成
-
训练好的全局分类器用来给客户端的无标签数据 Dku 打伪标签。
-
得到伪标签数据集:

4. 训练 c-LDM 的数据来源
-
训练 c-LDM 的数据由两部分组成:
-
有标签数据 {Dkl}
-
伪标签数据 {Dkp}
-
5. 问题与改进
-
伪标签可能存在错误 → 会导致 c-LDM 生成的数据偏离真实分布,降低合成数据质量。
-
改进措施:提出基于 precision optimization(精度优化) 的数据筛选方法,过滤掉低质量伪标签样本,从而提升训练数据的可靠性和最终合成数据的质量。
补充
1. 什么是伪标签?
-
真实标签 (true label):人工标注的标签,比如在图像分类中:
-
一张猫的照片 → 标签是 “cat”
-
一张狗的照片 → 标签是 “dog”
-
-
伪标签 (pseudo label):当数据 没有人工标注 时,先用一个已经训练好的模型来预测类别,并把预测结果当作“临时标签”。
-
本质上:伪标签 = 模型给出的预测标签
-
它可能是正确的,也可能是错误的。
-
2. 伪标签是否和真实标签一致?
-
名称/类别必须 来自同一个标签空间。
-
比如你训练的是一个 10分类的 CIFAR-10 模型(类别:cat, dog, car, plane...),
-
那么伪标签只能是这 10 个类别之一。
-
-
不会出现模型随便给个新名字(比如 “unknown animal”),因为训练时标签空间已经固定了。
3. 举个例子
假设我们在做 CIFAR-10 分类(10类:cat, dog, car, plane...),
有些数据 没有标签:
-
无标签图片 A:是一只猫的照片
-
无标签图片 B:是一辆汽车的照片
我们用训练好的全局分类器去预测:
-
对图片 A,模型预测类别 = “cat”
-
对图片 B,模型预测类别 = “car”
于是我们就把预测结果当作 伪标签:
-
(图片 A, cat) → 伪标签
-
(图片 B, car) → 伪标签
4. 可能的错误伪标签
但模型可能预测错:
-
真实:图片 A = “cat”
-
模型预测:图片 A = “dog”
-
那么伪标签就是 (图片 A, dog) —— 它是“伪”的,因为可能和真实标签不一致。
精度优化筛选伪标签
1. 背景问题
-
伪标签可能有错误 → 会污染训练数据。
-
所以需要一种方法来“挑选”更可靠的伪标签。
2. 方法核心
-
用 混淆矩阵 (confusion matrix) 来估计伪标签的质量。
-
对于 真实标注数据 Dkl,混淆矩阵是对角矩阵(预测和真实完全一致)。
-
对于 伪标签数据 Dkp,真实标签未知,所以需要用 全局混淆矩阵 来估计。
-
-
构建步骤:
-
每个客户端用全局分类器在本地测试集上跑出混淆矩阵 Mkt。
-
上传到服务器聚合,得到全局混淆矩阵 Mgt。
-
每个客户端下载 Mgt,用它来估算自己伪标签数据的混淆矩阵 Mkp。
-
3. 精度优化目标
客户端希望 在保证标签精度的情况下,尽量多保留伪标签数据。
-
定义了一个 平均标签精度
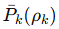 ,用来衡量选出来的数据有多“靠谱”。
,用来衡量选出来的数据有多“靠谱”。 -
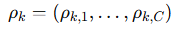 表示在每个类别中保留伪标签的比例。
表示在每个类别中保留伪标签的比例。
4. 优化问题 (P1)
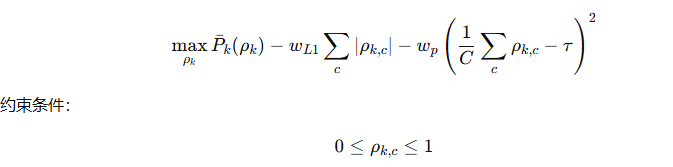
解释:
-
第一项:最大化伪标签的平均精度。
-
第二项:L1 正则化 → 促使结果稀疏(去掉更多低质量伪标签)。
-
第三项:惩罚项 → 控制各类之间保留比例不要差异太大,维持平衡。
用 SLSQP (顺序最小二乘规划) 求解。
5. 最终结果
-
得到最优解 ρk∗,即每个类别伪标签该保留的比例。
-
客户端随机删掉对应比例的伪标签样本,得到 优化后的伪标签数据集
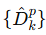
模型结构
1. 模型结构 (c-LDM)
c-LDM = 编码器 (En) + 解码器 (De) + 条件扩散模型 (CDM)
-
En/De:用 VAE 实现,把输入数据 x 映射到潜在空间 z,再解码重建。
-
CDM:在潜在空间里做扩散 (diffusion),包括:
-
正向过程:逐步给潜在表示 z0 加高斯噪声,得到 zt。
-
反向过程:训练一个 U-Net 去预测噪声 ϵt,逐步去噪,恢复原始 z0。
-
加入 cross-attention,让生成结果能对应指定类别。
-
2. 损失函数
-
扩散模型训练损失:
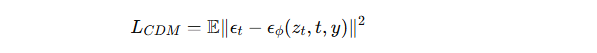
(预测噪声的均方误差,条件标签是 yyy)。
-
VAE训练损失:
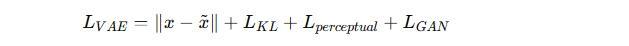
包括重建损失、KL散度、感知损失和对抗损失,确保生成质量。
3. 联邦训练方式
-
第一阶段 (训练VAE)
-
每个客户端在本地用有标签 + 无标签数据训练 VAE。
-
通过 FedAvg 聚合得到全局 VAE 参数 Φg。
-
-
第二阶段 (训练CDM)
-
每个客户端用全局编码器 En 把本地的真实数据和优化过的伪标签数据转成潜在表示。
-
在潜在空间里训练条件扩散模型。
-
通过 FedAvg 聚合得到全局扩散模型参数 ϕg。
-
4. 方法优势
-
避免了上传整套合成数据(减少通信量),只需要传参数。
-
统一的潜在空间让所有客户端共享一致的表征,能更好拟合全局分布。
-
即使本地数据类别不全,客户端也能生成 缺失类别的合成数据。
合成数据增强

1. 上传 & 聚合数据分布
-
每个客户端 k 先把自己的 有标签数据分布 ∣Dkl 上传到服务器。
-
服务器汇总得到全局分布 ∣Dgl,然后下发给所有客户端。
2. 引入增强强度 α
-
定义一个 增强强度参数 α:
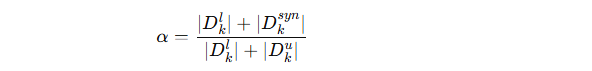
-
分子:客户端的有标签数据 + 生成的合成数据量。
-
分母:客户端的有标签 + 无标签数据量。
-
-
α决定了客户端要生成多少合成数据 Dksyn。
3. 合成数据生成约束
-
希望增强后的数据分布
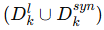 能和全局分布 ∣Dgl 对齐。
能和全局分布 ∣Dgl 对齐。 -
在数据极端不平衡的情况下(如某个客户端只有 1-2 类数据,缺少其他类),单纯依赖 α 无法满足条件。
4. 两阶段策略
为了解决数据严重缺失的情况,采用两步:
-
根据 α 确定合成 + 原始数据总量。
-
按照全局分布 ∣Dgl 分配到各类,得到目标分布
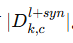 。
。
最终,合成数据量为:
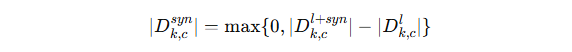
(即:只在本地缺少某类数据时才生成对应的合成样本)。
补充
输入
-
本地有标签数据分布 ∣Dkl∣
-
全局数据分布 ∣Dgl∣
-
增强强度参数 α
-
扩散过程步数 T
-
全局训练好的 VAE 解码器 De(⋅)
输出
-
客户端 k 的合成数据集 Dksyn
流程拆解
Step 1:决定每类需要多少合成样本
公式:
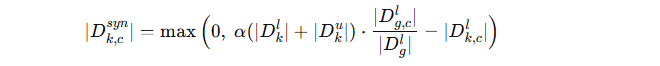
含义:
-
目标:让增强后的本地数据 (Dkl∪Dksyn) 接近全局分布 ∣Dgl∣。
-
如果某类 c 在本地不足,就生成额外样本来补齐。
-
如果本地已经足够,则该类不需要合成(因为取 max(0,⋅))。
Step 2:扩散模型逆过程生成潜在向量
对于每一个需要生成的样本:
-
初始化:
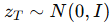 ,即高斯噪声。
,即高斯噪声。 -
反向扩散过程(从 t=T 到 1):
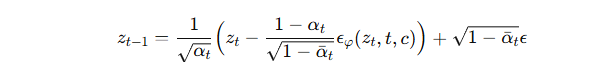
-
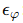 :全局训练好的 U-Net 噪声预测器(条件输入类别 ccc)。
:全局训练好的 U-Net 噪声预测器(条件输入类别 ccc)。 -
本质上:逐步去噪,把噪声 zT 还原成带有类别语义的潜在向量 z0。
-
Step 3:解码生成合成数据
-
通过全局 VAE 的解码器:
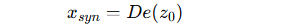
-
得到合成样本 xsyn,并打上类别标签 c。
-
存入合成数据集:
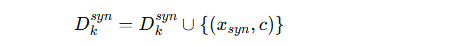
总结
-
Step 1:算出每类要补多少样本。
-
Step 2:用扩散模型反向采样生成潜在向量。
-
Step 3:用 VAE 解码成图像,并标注类别。
最终,客户端 kkk 得到一份合成数据集 Dksyn,它能补齐本地缺失类别,使得分布更接近全局分布。
实验
设置
这一段主要讲了 实验设置(Experimental Settings),说明作者为了验证 DDSA-FSSL 方法的有效性,在 CIFAR-10 和 Fashion-MNIST 数据集上进行实验时的具体配置和参数选择。核心内容包括:
-
数据分布与非IID模拟:
-
引入两种非IID不平衡:
-
External imbalance:不同客户端之间的有标签数据分布不均衡。
-
Internal imbalance:每个客户端内部有标签和无标签数据分布不同。
-
-
实验分为三种场景:(IID, IID)、(IID, DIR)、(DIR, DIR),其中 DIR 表示使用 Dirichlet 分布模拟非IID,γ=0.1 控制数据异质性。
-
-
模型配置:
-
分类器:使用 ResNet-18,优化器 SGD,动量 0.9,权重衰减 1e-4,学习率 1e-4。
-
VAE:采用指定架构,编码器下采样因子 f=2,优化器 Adam,学习率 1e-4,指数衰减率 0.5 和 0.9。
-
条件扩散模型 (CDM):U-Net 网络预测噪声,使用 T=1000 步长,线性噪声调度 β1=1e-4,β1000=2e-2,优化器 AdamW,学习率 2e-4。
-
-
联邦学习设置:
-
采用 FedAvg 算法进行参数聚合,以评估生成合成数据对系统性能的影响。
-
说明参数聚合算法可以根据 FSSL 任务替换成其他算法。
-
-
结果分析
-
性能对比:
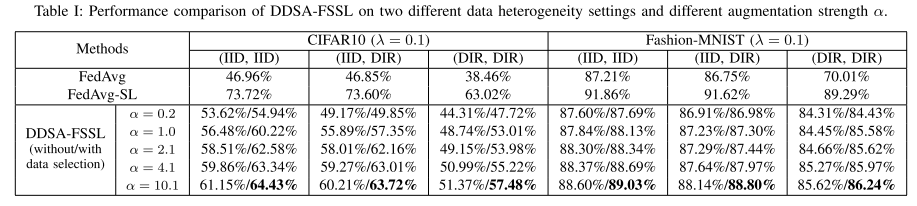
-
表格 I 显示 DDSA-FSSL 与 FedAvg 和 FedAvg-SL 的比较:
-
FedAvg-SL:全监督 FedAvg,用完整标注数据,作为性能上限。
-
FedAvg 和 DDSA-FSSL:只用 λ=0.1 的有标签数据训练。
-
-
DDSA-FSSL 在所有非IID场景下均优于 FedAvg。
-
随着合成数据增强强度 α 增大,分类准确率逐渐接近 FedAvg-SL。
-
-
精度优化数据选择的贡献:
-
消融实验显示 precision-optimized data selection 能进一步提升性能,尤其在双重数据异质性场景下效果明显。
-
-
有标签数据比例 λ 的影响:
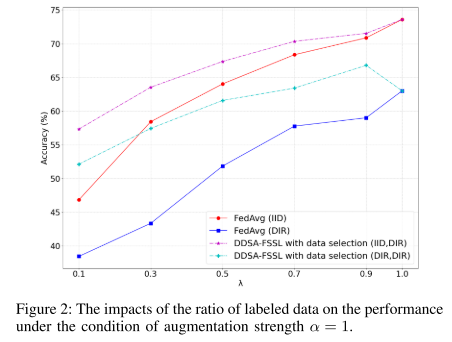
-
图 2 表明分类准确率与 λ 正相关。
-
DDSA-FSSL 在 λ<1 时也能超越基线,尤其在双异质性场景下,当 λ=0.7 和 0.9 时,性能甚至超过 FedAvg-SL。
-
说明通过生成特定的合成数据,可以缓解数据分布不均,提高性能。
-
-
各类召回率分析:
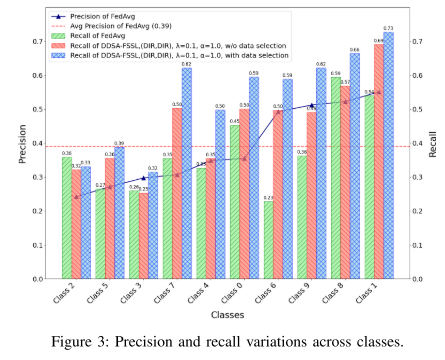
-
图 3 显示 CIFAR-10 10 个类在初始精度排序下的召回变化。
-
高精度类别的召回提升更大,而低精度类别变化小或略降。
-
原因:高精度伪标签降低错误率,使 c-LDM 生成的数据质量更高。
-
消融实验进一步验证,通过优化参与 c-LDM 训练的伪标签精度,可以提高所有类别的召回。
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)