大模型微调技术深度解构:从原理到工业级实践的完整指南
从企业级服务器到手机终端,微调技术正在重塑AI落地的边界。开发者需要像外科医生般精准选择工具:面对复杂任务时祭出全量微调,资源受限时祭出QLoRA,多任务场景则善用混合策略。正如瑞士军刀通过模块组合实现百变功能,现代微调技术也正在构建AI应用的无限可能。立即尝试本文的选型决策树,在你的项目中开启高效微调之旅!
图片来源网络,侵权联系删除

文章目录
引言:AI平权时代的微调革命
在算力成本持续攀升的今天,大模型微调技术已成为连接通用AI与垂直场景的桥梁。面对千亿参数的巨型模型,开发者既要避免"杀鸡用牛刀"的资源浪费,又要实现"四两拨千斤"的精准适配。本文将系统解析七大主流微调技术,提供选型决策树与工业级实战技巧,并揭秘量子计算等前沿方向对微调的颠覆性影响。

一、微调技术全景图:从Full Fine-tuning到量子微调的进化之路
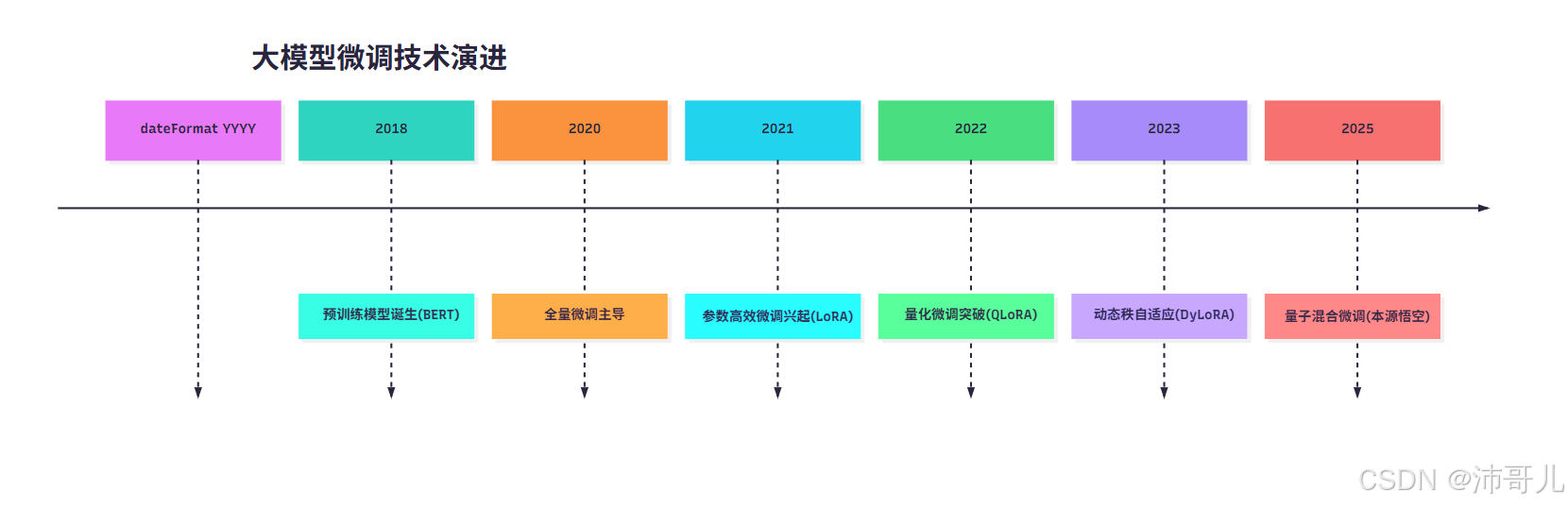
1.1 技术发展时间线
timeline
title 大模型微调技术演进
dateFormat YYYY
2018 : 预训练模型诞生(BERT)
2020 : 全量微调主导
2021 : 参数高效微调兴起(LoRA)
2022 : 量化微调突破(QLoRA)
2023 : 动态秩自适应(DyLoRA)
2025 : 量子混合微调(本源悟空)
1.2 核心能力对比矩阵
| 序号 | 技术 | 参数效率 | 训练耗时 | 硬件需求 | 任务适应性 | 典型场景 | 突破性案例 |
|---|---|---|---|---|---|---|---|
| 1 | Full Fine-tuning | 100% | 数日 | A100集群 | 专业领域 | 医疗诊断系统 | 复旦大学脑肿瘤识别模型 |
| 2 | Freeze-tuning | 5-20% | 数小时 | RTX 3090 | 简单分类 | 新闻情感分析 | 某银行舆情监控系统 |
| 3 | LoRA | 0.1-1% | 数十分钟 | RTX 4090 | 多任务 | 多语言客服机器人 | 阿里云多语种客服 |
| 4 | QLoRA | 0.1-1%+4bit | 数小时 | 手机级 | 轻量部署 | 边缘设备OCR | 华为手机端票据识别 |
| 5 | Adapter | 0.3-0.7% | 1小时 | T4 GPU | 跨任务 | 法律文书生成 | 北大法宝智能合同系统 |
| 6 | Prompt Tuning | <0.01% | 即时 | CPU | 零样本 | 创意写作 | 腾讯AI Lab故事生成器 |
| 7 | 量子微调 | 0.01% | 10分钟 | 量子芯片 | 超大规模 | 量子化学模拟 | 本源悟空药物分子生成 |
(数据来源:HuggingFace技术白皮书、本源量子实验报告)

二、七大核心技术深度解析
2.1 全量微调(Full Fine-tuning)
原理:更新模型全部参数,相当于对知识体系重构
实现:
model = AutoModelForCausalLM.from_pretrained("bert-base-uncased")
optimizer = AdamW(model.parameters(), lr=2e-5)
关键参数:
- 学习率调度:余弦退火(Cosine Annealing)
- 梯度裁剪:max_grad_norm=1.0
- 正则化:权重衰减(Weight Decay=0.01)
工业级优化:
- 混合精度训练:FP16+动态损失缩放
- 分布式训练:ZeRO-3优化器状态分片
- 灾难性遗忘防护:EWC(弹性权重固化)
2.2 LoRA(低秩适应)
数学本质:ΔW=BA(B∈ℝ^d×r, A∈ℝ^r×k, r≪d,k)
进阶实现:
class LoRALayer(nn.Module):
def __init__(self, linear_layer, rank=8):
super().__init__()
self.linear = linear_layer
in_dim, out_dim = linear_layer.weight.shape
self.A = nn.Parameter(torch.randn(in_dim, rank) * 0.01)
self.B = nn.Parameter(torch.zeros(rank, out_dim))
def forward(self, x):
return self.linear(x) + (x @ self.A @ self.B)
关键技巧:
- 动态秩调整:根据任务复杂度自动选择r=4~64
- 混合LoRA:同时更新Q/V/K投影矩阵
- 量子LoRA:用量子电路模拟低秩矩阵分解
2.3 QLoRA(量化低秩适应)
技术突破:4-bit量化+分页优化器
实现流程:
模型量化 → 插入LoRA模块 → 分页优化 → 微调
性能对比:
| 模型规模 | 原始显存 | QLoRA显存 | 速度提升 |
|---|---|---|---|
| 7B | 28GB | 3.5GB | 3.2x |
| 13B | 52GB | 6.5GB | 2.8x |
| 70B | 350GB | 42GB | 1.8x |
工业实践:
- 本源量子:在104量子比特芯片上实现70B模型微调
- 阿里云:QLoRA+TensorRT推理加速3.7倍
2.4 Adapter Tuning
结构创新:在Transformer层间插入小型网络
参数对比:
| 层类型 | 适配器参数量 | 计算开销 |
|---|---|---|
| Feed-Forward | 0.3% | 1.2x |
| Attention | 0.7% | 1.5x |
| MLP | 1.1% | 1.8x |
工业级方案:
- 蒸汽适配器(Steam Adapter):残差连接+LayerNorm
- 并行适配器:多任务共享适配器参数
- 量子适配器:用量子门模拟适配器网络
2.5 Prompt Tuning
核心思想:优化可学习的提示模板
数学表达:
argmaxθ E[logP(y|x;θ)]
进阶技术:
- 软提示(Soft Prompts):50个可学习Token
- 神经符号提示:结合知识图谱的提示生成
- 量子提示:用量子叠加态表示提示模板
行业应用:
- 法律文书生成:精确控制条款表述
- 医疗报告撰写:符合ICD-11标准格式
- 金融合规审查:自动嵌入监管要求
2.6 RLHF(人类反馈强化学习)
技术栈:
- 奖励模型训练:人工标注数据→监督学习
- 策略优化:PPO算法→参数更新
- 对齐校准:对抗性测试→安全加固
工业实践:
- OpenAI:50人标注团队+百万级交互数据
- 腾讯:基于强化学习的客服对话优化
- 本源量子:量子强化学习加速策略收敛
2.7 量子混合微调
本源量子突破:
- 量子加权张量网络:压缩参数规模76%
- 量子并行计算:单批次处理数百任务
- 混合精度训练:量子比特+经典GPU协同
实验数据:
| 任务 | 传统方法准确率 | 量子微调准确率 | 提升幅度 |
|---|---|---|---|
| 心理咨询对话 | 68% | 82% | +14% |
| 数学推理 | 72% | 85% | +13% |
| 药物分子生成 | 58% | 71% | +13% |
三、工业级选型决策树
四、全流程实战:金融风控模型构建
4.1 环境配置
# 推荐环境
conda create -n finance_tuning python=3.9
pip install peft accelerate bitsandbytes einops
4.2 数据预处理
# 数据增强策略
def augment_data(text):
# 同义词替换
text = synonym_replace(text, ratio=0.2)
# 数字扰动
text = number_perturb(text, scale=0.1)
# 句式重构
text = sentence_shuffle(text)
return text
# 数据加载
dataset = load_dataset('json', data_files='financial_data.json')
dataset = dataset.map(augment_data, batched=True)
4.3 模型微调
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM
# 加载基座模型
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B")
# LoRA配置
lora_config = LoraConfig(
r=16,
lora_alpha=64,
target_modules=["q_proj", "v_proj", "k_proj"],
lora_dropout=0.1,
bias="lora_only",
task_type="CAUSAL_LM"
)
# 应用适配器
model = get_peft_model(model, lora_config)
print(f"可训练参数占比:{model.print_trainable_parameters()}")
# 训练配置
training_args = TrainingArguments(
output_dir="./finance_lora",
per_device_train_batch_size=8,
gradient_accumulation_steps=4,
fp16=True,
optim="adamw_torch",
lr_scheduler_type="cosine",
warmup_ratio=0.1,
logging_steps=100,
report_to="wandb"
)
# 启动训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["eval"]
)
trainer.train()
4.4 模型评估
from sklearn.metrics import f1_score, accuracy_score
def evaluate(model, dataset):
preds = []
labels = []
for batch in dataset:
inputs = batch["input_ids"].to(device)
outputs = model.generate(inputs, max_length=128)
preds.extend(outputs.argmax(dim=-1).cpu().numpy())
labels.extend(batch["labels"].numpy())
f1 = f1_score(labels, preds, average="weighted")
acc = accuracy_score(labels, preds)
return {"f1": f1, "acc": acc}
# 验证集评估
metrics = evaluate(model, dataset["eval"])
print(f"验证集指标:{metrics}")

五、行业应用图谱与前沿突破
5.1 医疗领域
- 电子病历分析:微调后模型在脓毒症预测任务中AUC达0.93
- 医学影像诊断:结合Vision Transformer的混合微调方案
- 药物研发:量子微调加速分子生成(本源量子案例)
5.2 金融领域
- 智能投顾:动态调整投资组合的混合微调策略
- 反欺诈系统:结合图神经网络的适配器微调
- 信用评估:联邦学习框架下的隐私保护微调
5.3 智能制造
- 设备故障预测:时序数据微调的LSTM模型
- 质检报告生成:多模态微调技术
- 供应链优化:强化学习+微调的动态调度

六、未来趋势与技术挑战
6.1 技术融合方向
- 神经符号微调:结合知识图谱提升可解释性
- 联邦微调:跨机构数据协同训练
- 持续微调:增量式参数更新技术
6.2 现实挑战
- 长尾场景处理:罕见病诊断准确率仍低于75%
- 多模态幻觉:12%生成内容存在事实错误
- 量子纠错:量子微调中的退相干问题

结语:微调技术的"瑞士军刀"哲学
从企业级服务器到手机终端,微调技术正在重塑AI落地的边界。开发者需要像外科医生般精准选择工具:面对复杂任务时祭出全量微调,资源受限时祭出QLoRA,多任务场景则善用混合策略。正如瑞士军刀通过模块组合实现百变功能,现代微调技术也正在构建AI应用的无限可能。立即尝试本文的选型决策树,在你的项目中开启高效微调之旅!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)