【建议收藏】大模型预训练全流程:从小白到专家的进阶之路
文章系统介绍大模型预训练全流程,包括Transformer架构设计、分词器选择、高质量数据收集与处理、训练参数优化等关键技术环节。详细阐述语言建模任务作为预训练基础,以及如何通过数据清洗、混合和分词提升模型性能。同时强调学习大模型技术的重要性和就业前景,提供从基础理论到实战应用的学习路径,帮助读者掌握AI时代的核心技能。
一、预训练简介
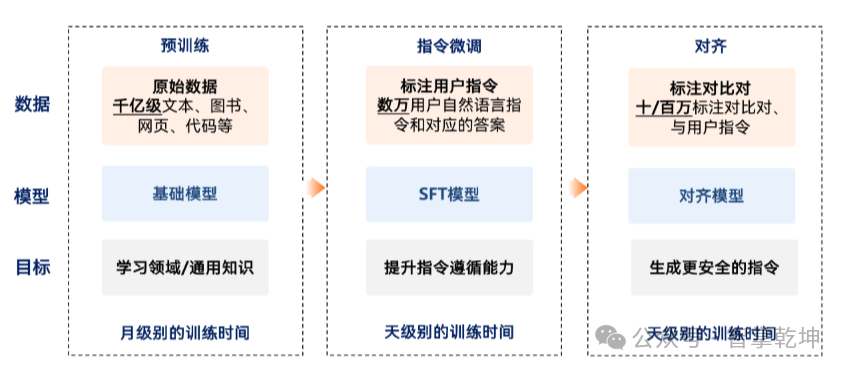
1、大模型的构建流程
大规模无标注数据预训练+指令微调+对齐。
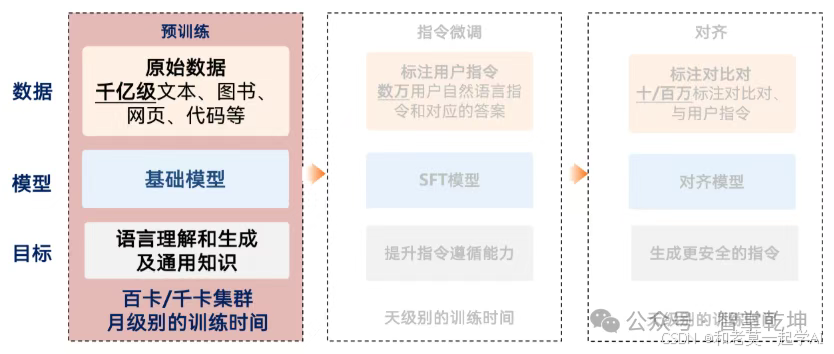
2、预训练是大模型构建的基础环节
3、大模型预训练任务
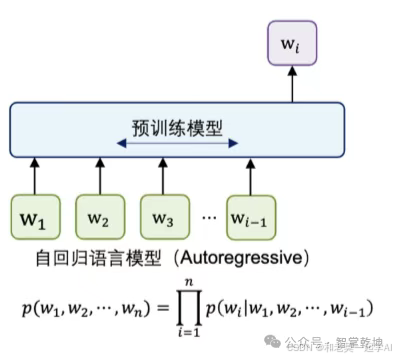
1)语言建模 (Language Modeling)
- = Next Token Prediction下一个词元预测。
- 形式化:给定一个词元序列w_{1} , w_{2} , \dotsc , w_{i - 1} ,进行最大似然估计,预测下一个词元w_{i}。
2)语言建模对预训练的意义
- 形式通用、便于扩展,因而可以采集到足量数据。
- 当预训练数据足够丰富时,大语言模型便能够学习到自然语言的生成规律与表达模式。
- 通过对词元更精准的预测,模型就可以更好地理解文本、建模世界语义知识。
二、预训练过程
1、确定模型结构
1)Tranformer解码器架构
- 主流大模型均采用Transformer架构
Transformer是由多层的多头自注意力(Multi-head Self-attention)模块堆叠而成的神经网络模型
- 大模型均采用Transformer解码器架构
原始的Transformer模型由编码器和解码器两个部分构成,而由于解码器架构对于任务的可扩展性,即生成式模型的语言建模任务和解码器适配,便于模型和数据的扩张。
2)Llama
不同大模型仅在局部有所区别,以Llama[1]为例,相比原Transformer架构,加入了以下结构:
- Grouped Query Attention(GQA)分组查询注意力
减少存储键和值的内存开销,提高推理效率。
- RMS Normalization均方根标准化
提高计算效率和训练的稳定性。
- SwiGLU激活函数
以计算为代价优化结果。
3)Meta-Llama-3-8B
从huggingface下载Meta-Llama-3-8B,配置文件config.json:

config. json即定义了模型参数,对关键参数解释如下:
- architectures: LlamaForCausalLM //CausalLM即语言建模的预训练任务
- model type: llama,//从huggingface库加载lLLaMA模型结构
- hidden size:4096,//隐藏层大小
- intermediate size:14336,//每个隐藏层中间层的大小
- num attention heads:32,//注意力头数
- num hidden layers:32,//隐藏层数
- vocab size:128256//词表大小
2、确定分词器:Llama3分词器
1)分词器Tokenizer
基于tiktoken分词器。
采用BPE字节对编码 (Byte-Pair Encoding) 算法。
2)词表
- 大小:128256
- 包含特殊token
<| begin of text|>序列开始
<| end of text|>序列结束
未知token
3、数据准备
高质量预训练数据的准备包括数据收集、数据清洗、数据混合、分词。
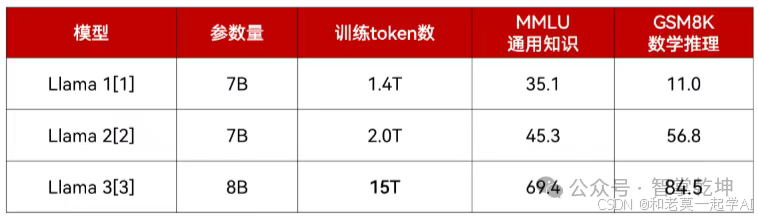
预训练数据的数量、质量和多样性对于模型性能具有重要影响。
三代Llama逐步提高预训练数据的数量和质量,性能提升显著。
1)数据收集
- 常见预训练数据集
- 通用文本数据:训练语言理解和生成能力、通用知识
CommonCrawl[67%]: 从互联网上爬取的网页数据,多样、非结构化。
C4[15%]: 基于CommonCrawl进行了过滤,文本质量更高、更干净。
- 专业文本数据:扩充专业知识,提升任务解决能力
Github[4.5%]: 代码。
Wikipedia [4.5%]: 知识、且结构化。
Gutenberg and Books3[4.5%]: 书籍。
ArXiv[2.5%]: 学术论文。
Stack Exchange[2%]: 高质量问答,涵盖计算机科学、化学等多样领域。
2)清洗与混合
-
数据清洗:为了提高文本质量,需要一套数据清洗流程和方法,包括
-
过滤
质量过滤:过滤低质量文本
脱敏:删除含个人隐私的数据、有毒内容等
HTML处理:去除 tag提取文本、部分文本保留结构信息等
-
去重
去除重复文本:包括不同文档、文档内部、不同行等层级
-
数据混合:确定预训练数据组合中不同数据源的比例[1]
-
知识分类:对文本进行知识分类,以确定不同类别 (例如艺术和娱乐)文本的比例
-
在小参数量下进行试验得到较优比例:经过实验,Llama3选择的数据混合比例为大约50%通用知识、25%的数学和推理、17%的代码和8%的多语言
-
分词:将原始文本分割成模型可识别和建模的词元 (token)序列,作为大语言模型的输入数据。
4、训练参数设置
与传统神经网络的优化类似,大模型训练通常使用批次梯度下降算法来进行模型参数的更新,因此,训练参数对模型结果影响大。
关键参数包括批次大小、学习率及其调整策略、优化器及其参数、稳定训练技术等等。
下表展示了现有大语言模型的详细优化设置。
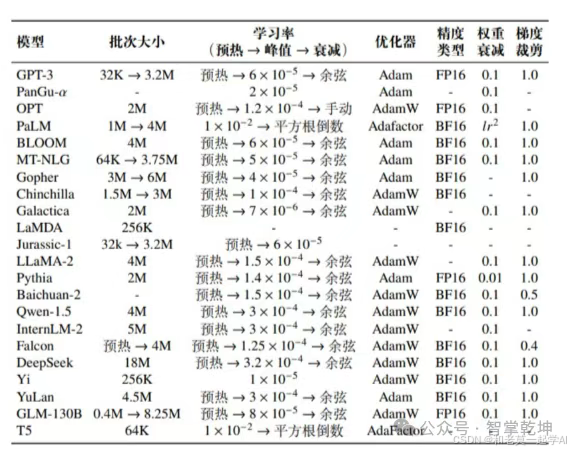
1)批次大小 (Batch Size)
在大模型预训练中,通常将批次大小设置为较大的数值,例如1M到4M个词元,从而提高训练的稳定性和吞吐量。
动态批次调整策略:在训练过程中逐渐增加批次大小,最终达到百万级别。
2)学习率 (Learning Rate)
- 预热阶段:通常采用线性预热策略,学习率将从一个非常小的数值 (例如0或者1 × 1 0^{ - 8})线性平稳增加,直到达到预设的最大阈值,一般占整个训练步骤的0.1%至0.5%。
- 衰减阶段:达到最大阈值之后学习率会开始逐渐衰减,以避免在较优点附近来回震荡。最后,学习率一般会衰减到其最大阈值的10%。常见的衰减策略有线性衰减,余弦衰减,平方根倒数衰减等。
3)优化器 (Optimizer)
- 常用Adam,AdamW:在优化中引入了三个超参数,在大模型训练中通常采用以下设置:β1=0.9,β2=0.95和epsilon = 1 0^{ - 8}。
- β1,β2分别表示一阶矩估计和二阶矩估计的指数衰减率。一阶矩估计和二阶矩估计用于计算梯度的移动平均值和平方的移动平均值,这两个参数的值决定了这两个移动平均值的更新速度;∈防止除以0。
4)稳定训练技术
- 梯度裁剪 (Gradient Clipping):防止梯度由于累乘效应而趋于0或无穷。
- 权重衰减 (Weight Decay):对损失函数做正则化,防止过拟合。
5、根据损失和评测结果调整数据和训练参数
1)观察损失 (loss)
2)语言模型基本能力评测指标
即生成文本和目标文本的拟合程度、符合人类语言使用习惯的程度(语言流畅通顺)。
使用困惑度 (Perplexity) 等指标。
3)大模型各维度能力评测基准 (benchmark)
- 通用知识:MMLU(英文) 、C-EVAL (中文) 等。
- 数学推理:GSM8K、Math。
- 代码:HumanEval。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献292条内容
已为社区贡献292条内容

所有评论(0)