【课程笔记·李宏毅教授】如果我们训练不了人工智能,该怎么“训练自己”(下)?
今天我们讲的核心是“模型合作”——不用调整参数,只要让多个模型分工、讨论、扮演角色,就能发挥比单个模型更强的能力。虽然现在让模型团队解“真实世界的复杂专案”还不太现实,但这给了我们一个重要的方向:未来的AI发展,不一定需要打造“全能模型”,让模型“专业分工、组队合作”,可能是更高效的路径。

今天我们从一段动画剧情开始——不知道大家最近有没有看《葬送的芙莉莲》?这几周芙莉莲和徒弟费伦在考“一级魔法使”,其中一个关卡是攻略“零落的王座”迷宫,里面有个“水晶恶魔”,能复制进入者的能力。芙莉莲作为千年魔法使,连自己的复制体都打不过,但她相信和人类徒弟费伦合作能赢。
战斗时,芙莉莲和复制体放各种毁天灭地的魔法——打雷、放火,还用上忍术“地爆天星”“螺旋手里剑”,最后甚至召唤“欧贝利斯克巨神兵”,打得难分难解。费伦从后面偷袭打断复制体的手,没想到复制体用“万象天引”(六道佩恩的忍术)把费伦瞪飞粘在墙上。但也正因为复制体用了这招,露出破绽,被芙莉莲一举击败。
这个故事想告诉大家的是合作的重要性:就算是千年魔法使,也需要和人类合作才能发挥更大力量。就像GPT-4虽然强,但和其他语言模型合作,也能实现“1+1>2”的效果。今天我们就重点讲“怎么让语言模型彼此合作”,全程还是不调整模型参数,只靠“训练自己”优化AI能力。
一、模型合作的第一种方式:用“分配模型”决定任务归属
如果你手边有多个模型(比如GPT-4、GPT-3.5、Claude),它们能力不同、成本也不同(GPT-4比GPT-3.5贵很多),怎么让它们高效合作?核心是“再训练一个分配模型”——这个模型可以是语言模型,也可以不是,它的唯一工作就是“判断新任务该交给谁”。
1. 核心逻辑:“杀鸡不用牛刀”,降低成本
- 比如来了个简单任务(如“翻译‘你好’成英文”),分配模型会判断“不需要GPT-4,交给便宜的GPT-3.5就行”;
- 来了个复杂任务(如“写生成式AI的技术报告”),分配模型才会把任务交给GPT-4。
- 现在很多语言模型展示平台,其实已经在用这种技术:你问不同问题,背后服务你的可能是不同模型,但作为用户你察觉不到。
2. 参考资料:《Frugal GPT》论文
这篇论文详细讲了“用分配模型优化成本”的方法,我过去的上课录影也专门讲过,大家可以去看——通过这种合作,既能达到比GPT-4更好的效果,又能降低使用成本。
二、模型合作的第二种方式:让模型彼此“讨论”,激发能力
之前我们讲过“让模型自我反省”(比如做完题自己检查),但自我反省有局限——模型容易认同自己之前的答案,很难推翻错误。而让多个模型讨论,彼此给新刺激,更容易发现错误、得到更好结果。
1. 具体demo:两个模型讨论“《葬送的芙莉莲》英文翻译”
为了不让模型“作弊”(比如GPT-4联网搜正式翻译),我们选“Claude 3”和“GPT-3.5”来讨论,步骤如下:
- 第一步:给Claude 3任务
让它翻译“葬送的芙莉莲”,并提供漫画剧情概要。Claude 3给出翻译“the berry laurier”(直白翻译“葬送”为“berry”)。 - 第二步:把Claude 3的答案给GPT-3.5,鼓励反对
重点要加一句提示:“你不需要完全同意我的看法”——如果不加这句话,GPT-3.5会直接说“你的翻译太棒了”,讨论就结束了。
GPT-3.5果然给出不同翻译:“emtombed florida”,传达了‘被埋藏、被困’的意象,贴合‘葬送’的感觉”。 - 第三步:把GPT-3.5的答案回给Claude 3
Claude 3又出新翻译:“furious atomic”。 - 第四步:再把Claude 3的新答案给GPT-3.5
GPT-3.5给出“florian’s redemption”(芙莉莲的救赎)。 - 第五步:最终共识
把“florian’s redemption”给Claude 3,它评价“这是极佳的英译版本,比之前的都好”,讨论结束。
2. 关键说明:不用手动“传答案”,靠API自动实现
刚才demo里我手动把两个模型的答案来回传,是为了展示过程。实际操作中,大家可以写代码(作业3已经学过调用API),让两个模型通过API自动对话,完全不用人工干预。
3. 讨论的优势:比自我反省更容易推翻错误
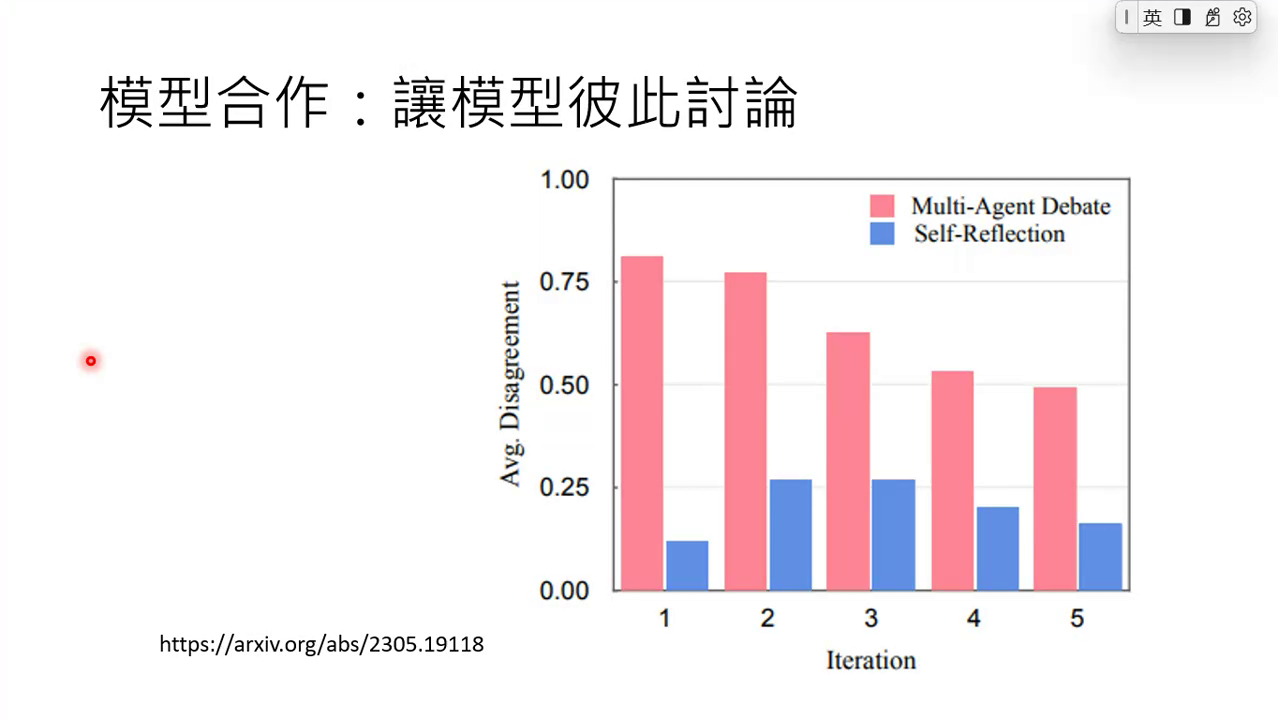
。
- 结果:自我反省的模型,推翻自己答案的概率很低(毕竟是自己认同的答案);而讨论的模型,因为受到对方新观点的刺激,推翻错误答案的概率更高。
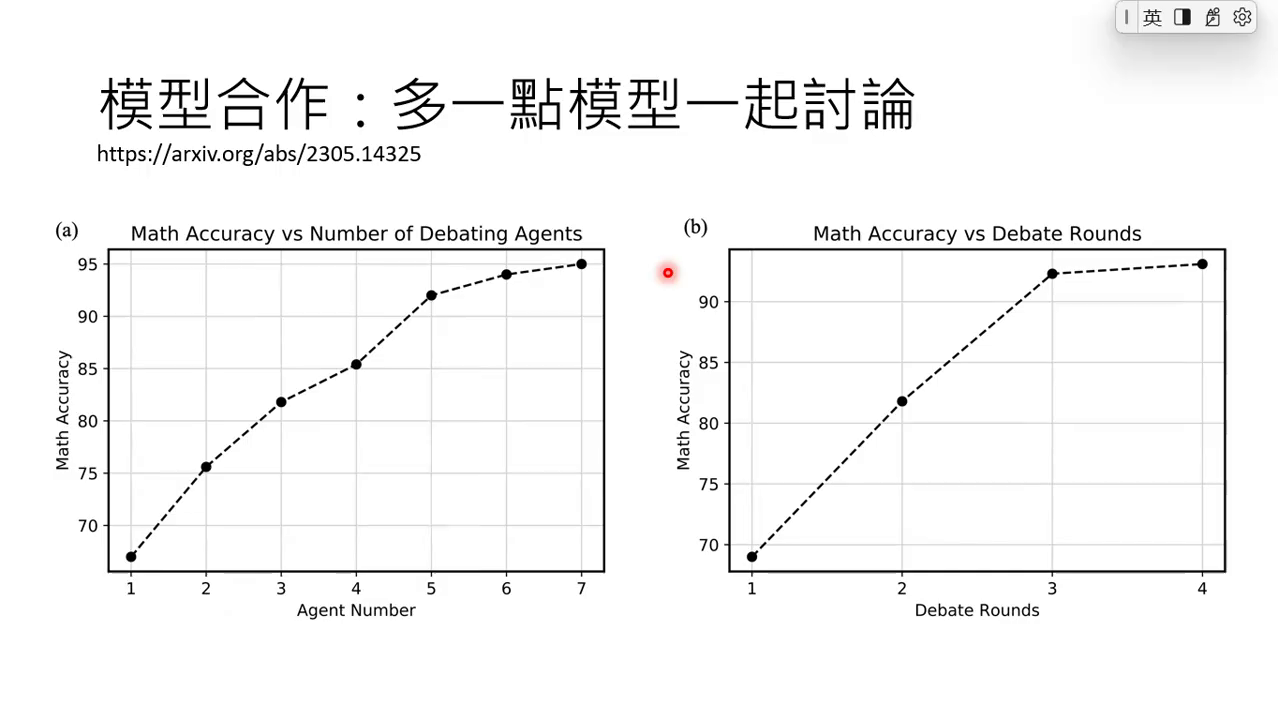
4. 更多模型、更多回合,结果更好
另一篇论文的实验也验证了直觉:
- 左图(模型数量):纵轴是解数学题的正确率,横轴是参与讨论的模型数量——模型越多,正确率越高;
- 右图(讨论回合):纵轴是正确率,横轴是讨论回合数——回合越多,正确率越高,但到4回合后基本饱和(3回合和4回合结果接近)。
三、模型讨论的“规则”:怎么定讨论方式、怎么判断结束?
让模型讨论不是“随便聊”,要明确两个关键问题:“用什么方式讨论”“什么时候停”。
1. 讨论方式:没有“最好”,只有“最适合”
论文《Exchange of Soul》尝试了多种讨论方式,比如:
- 全员共享:3个模型各给答案,所有人都能看到其他人的答案,一起讨论;
- 上下级汇报:A是老板,B和C是下属,B、C只跟A汇报,彼此不交流;
- 循环传递:A→C→B→A,依次传递答案并补充;
- 辩论+裁判:B和C辩论,A当裁判,判断谁的观点更好。
- 结论:没有统一的“最好方式”,不同任务适合不同的讨论方式,这还是个研究中的问题。
2. 讨论结束的判断:引入“裁判模型”
怎么知道模型们达成共识了?需要一个“裁判模型”:
- 让模型A、B分别给出建议;
- 把A、B的对话丢给裁判模型,问“它们有没有达成共识?”;
- 裁判模型觉得“没共识”,就让A、B继续讨论;觉得“有共识”,就宣布结束,并根据讨论过程做摘要,输出最终答案。
- 优势:以GPT-4为代表的强模型,能很精确地判断两句话是否一致,当裁判完全没问题。
3. 注意:别担心“讨论停不下来”,要担心“讨论太快结束”
现在的语言模型训练时被设定为“温良恭俭让”,别人一质疑就容易退缩,讨论很容易没两句就结束。解决办法是下合适的Prompt,刺激它们反对:
- 不好的Prompt:“根据对方的建议回答”(讨论很快结束);
- 好的Prompt:“对方的看法仅供参考,你可以发表自己的意见,不需要一定同意”(讨论更热烈,持续更久);
- 别用“为反对而反对”的Prompt(比如“不管对方说什么,你都要反对”)——这样反而得不到好结果。
四、进阶:让模型“扮演不同角色”,分工合作
就像勇者小队需要“魔法使(远程输出)、僧侣(治疗)、剑士(近战)、矮人(坦克)”一样,模型团队也需要不同角色,才能更好地完成复杂任务(比如开发一个软件专案)。
1. 怎么让模型扮演角色?
有两种方式:
- 选有专长的模型:比如模型“CodeLlama”特别擅长写代码,就让它扮演“工程师”;
- 用Prompt指定角色:直接告诉模型“你是Project Manager(项目经理),负责主导专案规划”“你是Tester(测试员),负责检查代码漏洞”,模型读了Prompt后,会尽量贴合角色发挥能力。
2. 分工流程:以“开发软件专案”为例
- Project Manager:先做专案规划(比如“分3步:需求分析→写代码→测试”);
- Engineer(CodeLlama):根据规划写代码;
- Tester:测试代码,找出漏洞,反馈给Project Manager;
- Project Manager:根据测试结果调整规划,让Engineer修改代码,直到专案完成。
3. 优化团队:给模型“打考核”,淘汰不合格者
论文《Dynamic LLM Agent Network》提出了一个简单的优化方法:
- 专案结束后,让每个模型给其他模型打分(比如“Engineer写的代码漏洞太多,打3分”“Tester找漏洞很仔细,打10分”);
- 把分数加总,淘汰分数低的模型,留下优秀的模型组成新团队。
4. 实际体验:开源专案“MetaGPT”
如果你想体验“带领模型团队”,可以试试开源专案MetaGPT——里面有各种角色的“AI员工”,比如Product Manager、Architect、Engineer、Tester等。你把任务指令交给它们,它们会试着按分工做事(比如让它们开发一个简单网页)。
- 有趣案例:有人用ChatGPT(背后调用GPT-3.5/GPT-4)写网页,成本只要1美金,还想接外包收2美金,但最后没接到案子(看来实际效果还有提升空间)。
五、未来想象:语言模型可以组成“社群”
模型合作不止能“组成团队”,还能更进一步“组成社群”。斯坦福2024年4月的论文做了一个“语言模型小镇”——里面所有村民都是语言模型,它们会互动、会发展关系(甚至有淡淡的恋爱故事),非常有趣。
我之前的上课录影专门讲过这个实验,大家一定要去看。如果你已经学了前面几讲的“强化AI能力的技巧”,再看这个影片会发现:AI村民的每一个互动,用到的都是我们课堂上讲过的方法,完全不会觉得离奇。
总结
今天我们讲的核心是“模型合作”——不用调整参数,只要让多个模型分工、讨论、扮演角色,就能发挥比单个模型更强的能力。虽然现在让模型团队解“真实世界的复杂专案”还不太现实,但这给了我们一个重要的方向:未来的AI发展,不一定需要打造“全能模型”,让模型“专业分工、组队合作”,可能是更高效的路径。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 32
32 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)