五、基于LlamaIndex开发第一个RAG示例
Agent根据用户的查询去搜索相关的信息,可能是通过互联网或者特定的数据库来寻找相关文档或数据。:最后,LangChain Agent将大模型生成的答案提供给用户。这个答案是基于用户的原始查询和从相关数据源检索到的信息生成的。:从搜索结果中检索具体的信息,这些信息将用于生成响应用户查询的上下文。:Agent将检索到的信息和用户的原始查询一起提供给大模型。:用户向系统提出一个查询,例如一个问题或者一
RAG的实现流程
LlamaIndex中的Agent实现RAG检索和增强生成的流程如下:
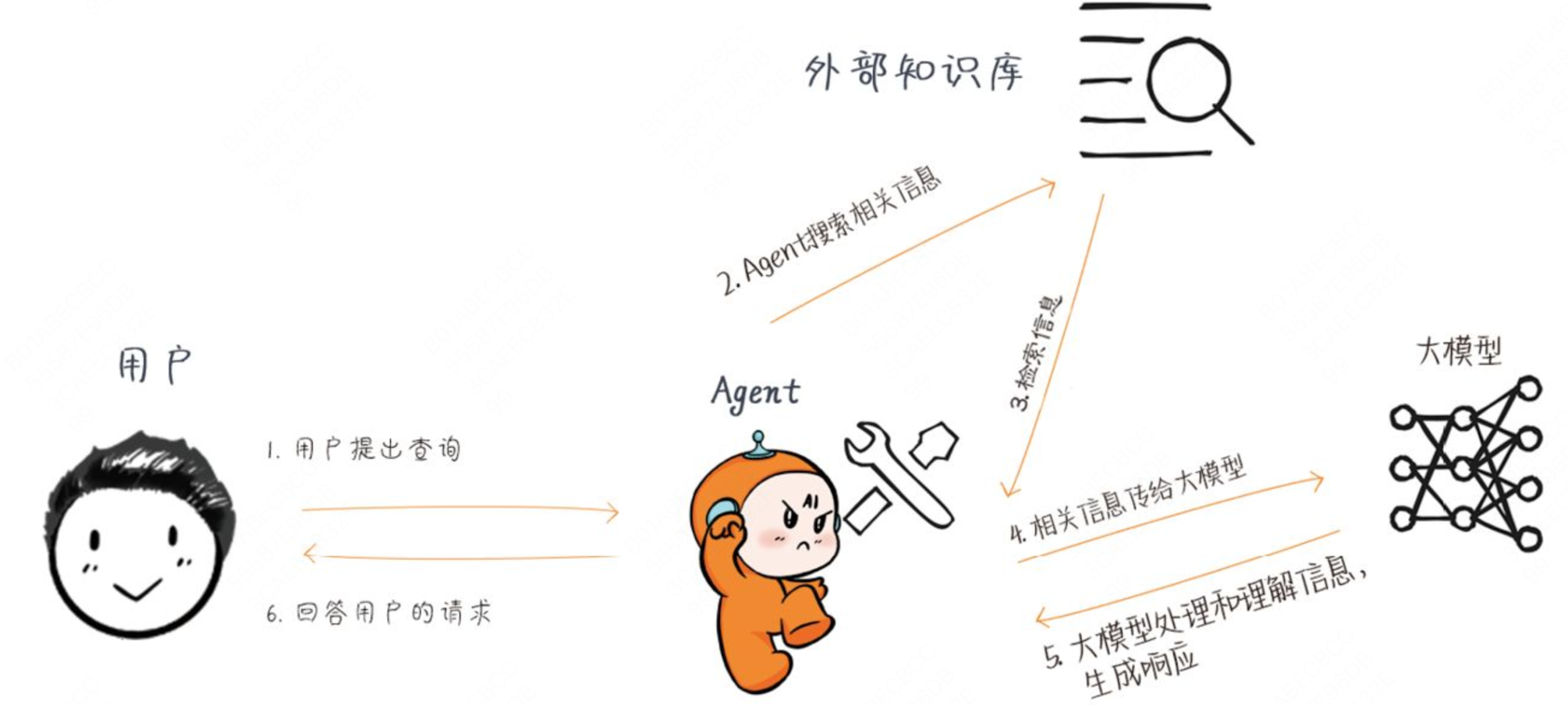
整个过程共6步。
1.用户提出查询(Query):用户向系统提出一个查询,例如一个问题或者一个请求。
2.Agent搜索相关信息:Agent根据用户的查询去搜索相关的信息,可能是通过互联网或者特定的数据库来寻找相关文档或数据。通常我们会把企业内部信息放到向量数据库中。
3.检索(Retrieval)信息:从搜索结果中检索具体的信息,这些信息将用于生成响应用户查询的上下文。
4.相关信息传给大模型:Agent将检索到的信息和用户的原始查询一起提供给大模型。
5.大模型生成(Generate)响应:大模型使用这些信息来生成一个丰富的、信息性的答案。
6.回答用户的请求(Response):最后,LangChain Agent将大模型生成的答案提供给用户。这个答案是基于用户的原始查询和从相关数据源检索到的信息生成的。
基于LlamaIndex实现RAG
第1步,安装LlamaIndex
pip install llama-index
第2步,导入环境变量
import os
# 配置豆包API
# 豆包APIKEY控制台:https://console.volcengine.com/ark/region:ark+cn-beijing/apiKey?apikey=%7B%7D
BASE_URL = "https://ark.cn-beijing.volces.com/api/v3/"
API_KEY = "你的豆包API KEY"
os.environ["OPENAI_API_KEY"] = API_KEY # 设置环境变量 OPENAI_API_KEY
os.environ["OPENAI_API_BASE"] = BASE_URL # 设置环境变量 OPENAI_API_BASE
# 文本处理大模型
MODEL_NAME = "doubao-seed-1-6-vision-250815"
# 向量化大模型
EMBEDDING_MODEL_NAME = "doubao-embedding-large-text-250515"第3步,加载本地数据,在data目录下存放文档。
#导入文档
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()data目录要跟代码目录同一级
第4步,为数据建立索引。
# 为文档建立索引
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(documents)第5步,查询本地数据。
# 查询事例
query_engine = index.as_query_engine()
response = query_engine.query("乘客营销领域需要解决的问题")
print(response)查询结果:
全部代码如下:
import os
import requests
from typing import Any, List
from llama_index.core.llms import (
CustomLLM,
CompletionResponse,
CompletionResponseGen,
LLMMetadata,
)
from llama_index.core.embeddings import BaseEmbedding
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
# 配置豆包API
BASE_URL = "https://ark.cn-beijing.volces.com/api/v3/"
API_KEY = "你的API KEY"
# 文本大模型
MODEL_NAME = "doubao-seed-1-6-vision-250815"
# 向量化大模型
EMBEDDING_MODEL_NAME = "doubao-embedding-large-text-250515"
os.environ["OPENAI_API_KEY"] = API_KEY # 设置环境变量 OPENAI_API_KEY
os.environ["OPENAI_API_BASE"] = BASE_URL # 设置环境变量 OPENAI_API_BASE
# 自定义豆包LLM类#
class CustomDoubaoLLM(CustomLLM):
model_name: str
temperature: float
api_key: str
base_url: str
def __init__(
self,
model_name: str = MODEL_NAME,
temperature: float = 0.7,
):
super().__init__(
model_name=model_name,
temperature=temperature,
api_key=API_KEY,
base_url=BASE_URL
)
@property
def metadata(self) -> LLMMetadata:
"""Get LLM metadata."""
return LLMMetadata(
model_name=self.model_name,
temperature=self.temperature,
)
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
data = {
"model": self.model_name,
"messages": [{"role": "user", "content": prompt}],
"temperature": self.temperature,
"max_tokens": 1024
}
response = requests.post(
f"{self.base_url}chat/completions",
headers=headers,
json=data
)
if response.status_code != 200:
raise Exception(f"API请求失败: {response.text}")
result = response.json()
return CompletionResponse(
text=result["choices"][0]["message"]["content"],
raw=result
)
def stream_complete(self, prompt: str,** kwargs: Any) -> CompletionResponseGen:
# 实现流式响应(如果需要)
response = self.complete(prompt, **kwargs)
yield response
# 自定义豆包Embedding类
class CustomDoubaoEmbedding(BaseEmbedding):
model_name: str
api_key: str
base_url: str
def __init__(self, model_name: str = EMBEDDING_MODEL_NAME):
super().__init__(
model_name=model_name,
api_key=API_KEY,
base_url=BASE_URL
)
def _get_embedding(self, text: str) -> List[float]:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
data = {
"model": self.model_name,
"input": text
}
response = requests.post(
f"{self.base_url}embeddings",
headers=headers,
json=data
)
if response.status_code != 200:
raise Exception(f"Embedding请求失败: {response.text}")
result = response.json()
return result["data"][0]["embedding"]
def _embed(self, texts: List[str]) -> List[List[float]]:
# 批量处理文本嵌入
return [self._get_embedding(text) for text in texts]
async def _aembed(self, texts: List[str]) -> List[List[float]]:
# 异步版本(如果需要)
return self._embed(texts)
def _get_text_embedding(self, text: str) -> List[float]:
return self._get_embedding(text)
def _get_query_embedding(self, text: str) -> List[float]:
return self._get_embedding(text)
async def _aget_query_embedding(self, text: str) -> List[float]:
return await self.aembed_query(text)
# 初始化自定义模型
llm = CustomDoubaoLLM(
model_name=MODEL_NAME,
temperature=0.7
)
# 初始化向量模型
embed_model = CustomDoubaoEmbedding(
model_name=EMBEDDING_MODEL_NAME
)
# 设置全局 Settings
Settings.llm = llm
Settings.embed_model = embed_model
Settings.chunk_size = 512
# 加载文档
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("乘客营销领域需要解决的问题")
print(response)
几个注意事项
- 我们国内无法访问Open AI,无法使用Open AI的API_KEY,需要替换为国内的大模型。或者可以通过mo fa上网直接访问。
- 使用国内大模型的话,DeepSeek没有找到支持向量化的大模型,只有deepseek-chat(对话)和
deepseek-reasoner(推理)两类模型,没有向量化大模型
- 使用豆包大模型,需要自定义豆包LLM类和Embedding类,如代码中的CustomDoubaoLLM类和CustomDoubaoEmbedding类,并设置全局Settings。
- 如果缺少【3】中的自定义运行代码时会报错如下,默认使用text-embedding-ada-002模型,并提示:The model or endpoint text-embedding-ada-002 does not exist or you do not have access to it。
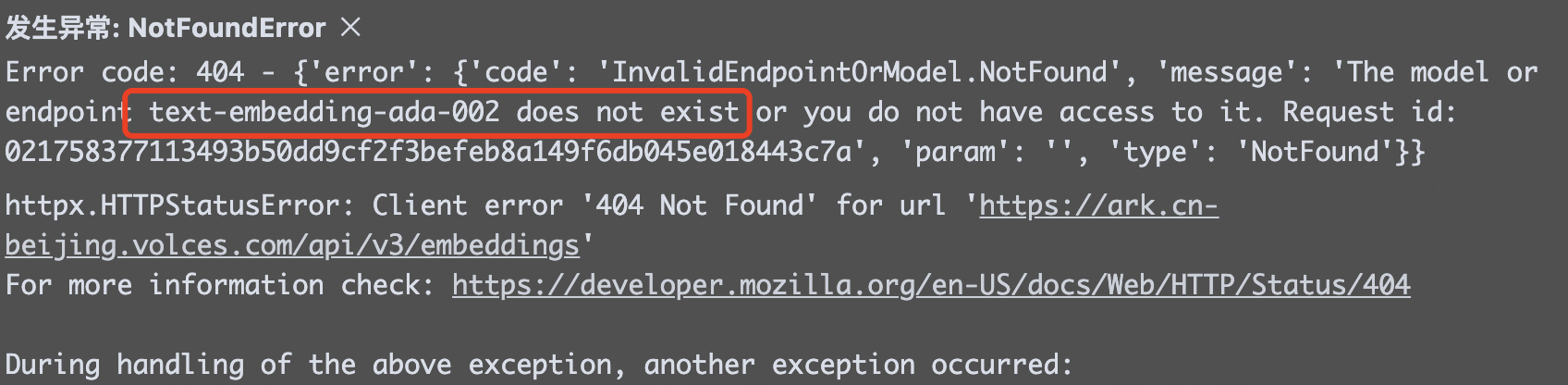 PS:text-embedding-ada-002是Open AI提供的一个embedding模型。
PS:text-embedding-ada-002是Open AI提供的一个embedding模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 33
33 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)