大模型初识(微调Fine-tuning+对齐Alignment+推理优化Inference Optimization)
大模型初识
微调(Fine-tuning): 使用领域数据教会模型“如何工作”
微调是指在一个预先训练好的大型语言模型(基础模型,如 Llama、GPT、BERT)的基础上,使用特定领域或任务的数据集进行额外的训练。
其目的是让模型适应特定场景,提升在该场景下的性能和效果,而无需从头开始训练,从而节省巨大的计算成本和时间。
- 全量微调 (Full Fine-tuning): 更新模型的所有参数。效果通常最好,但计算成本高,需要大量显存。
- 参数高效微调 (Parameter-Efficient Fine-Tuning, PEFT): 只更新一小部分参数(例如通过 LoRA、Adapter 等方法),大大降低计算和存储需求,是目前的主流方式
智能客服问答系统
背景:电商公司希望构建一个能理解其特定商品、促销规则、售后政策的智能客服机器人。通用大模型(如 ChatGPT)可能不了解公司内部的专有名词和流程。
解决方案: 使用公司的历史客服对话记录、产品知识库文档和政策文档,对开源大模型(如 Llama 3)进行微调。
目标: 让模型学会用公司特有的风格和准确的信息来回答用户问题。
# 导入必要的库
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling
)
from peft import LoraConfig, get_peft_model, TaskType
from datasets import load_dataset
import torch
# 1. 加载预训练模型和分词器
model_name = "meta-llama/Meta-Llama-3-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 注意:需要从Meta官网申请许可才能下载Llama权重
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True, # 使用QLoRA,4位量化加载以节省显存
device_map="auto",
torch_dtype=torch.bfloat16
)
# 添加pad_token,如果不存在
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 2. 准备数据集 (示例:假设已处理成JSONL格式)
# 数据格式: {"text": "用户: 请问iPhone 15什么时候发货?\n客服: 尊敬的客户,预售商品通常在支付后7天内发货,请关注订单详情页。\n"}
dataset = load_dataset("json", data_files={"train": "customer_service_train.jsonl"})
def tokenize_function(examples):
# 对文本进行分词,并添加labels(与input_ids相同,用于因果语言建模)
tokenized = tokenizer(
examples["text"],
truncation=True,
padding=False,
max_length=512
)
tokenized["labels"] = tokenized["input_ids"].copy()
return tokenized
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 3. 配置 LoRA
lora_config = LoraConfig(
r=8, # LoRA rank
lora_alpha=32, # 缩放参数
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"], # 针对LLaMA的Attention模块
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 打印可训练参数量,会发现只占很小一部分
# 4. 设置训练参数
training_args = TrainingArguments(
output_dir="./llama3-customer-service-lora",
per_device_train_batch_size=2, # 根据GPU显存调整
gradient_accumulation_steps=4, # 梯度累积,模拟更大batch size
learning_rate=2e-4,
num_train_epochs=3,
logging_dir="./logs",
logging_steps=10,
save_strategy="epoch",
fp16=True, # 使用混合精度训练
)
# 5. 创建 Trainer 并开始训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
trainer.train()
# trainer.save_model() 训练完成后保存模型
# 6. 推理测试
def generate_response(prompt, model, tokenizer, max_length=200):
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_length=max_length,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# 加载微调后的模型进行测试
# fine_tuned_model = PeftModel.from_pretrained(model, "./llama3-customer-service-lora")
test_prompt = "用户: 我买的鞋子尺码不对,可以退换货吗?\n客服:"
response = generate_response(test_prompt, model, tokenizer)
print(response)
对齐(Alignment): 使用人类偏好数据教会模型“如何安全、有用、符合期望地工作”
对齐旨在使大模型的行为符合人类的价值观、意图和偏好。一个能力强但不受控制的模型可能会生成有害、偏见或不有用的内容。微调让模型“学会做事”,而对齐让模型“学会做人”
- RLHF (Reinforcement Learning from Human Feedback): 这是 ChatGPT成功的核心。它通过人类反馈来训练一个奖励模型(Reward Model),然后使用强化学习(如PPO)来优化语言模型,使其输出能获得高奖励(即符合人类偏好)。
- DPO (Direct Preference Optimization):一种更直接、更稳定的替代方案,它绕过了奖励模型的训练步骤,直接使用偏好数据来优化模型,目前非常流行。
安全可靠的内容生成助手
背景: 一家新闻媒体公司希望部署一个内部用的内容创作助手,要求其生成的内容不仅相关、流畅,还必须事实准确、中立且符合媒体的安全准则。
解决方案: 在通用模型微调后,收集一组人类对模型多个回答的偏好排序数据(例如,A回复比B回复更好)。使用这些偏好数据,通过 DPO 方法对模型进行对齐训练。
# 假设我们已经有一个SFT(监督微调)后的模型
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import DPOTrainer, DPOConfig
from datasets import load_dataset
import torch
# 1. 加载SFT模型和分词器
model_name = "./sft-model" # 假设这是我们之前微调好的客服模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 2. 加载偏好数据集
# 格式: {"prompt": "...", "chosen": "...(人类偏好的回复)", "rejected": "...(人类拒绝的回复)"}
dpo_dataset = load_dataset("json", data_files={"train": "preference_data.jsonl"})
# 3. 定义 DPO 配置
dpo_config = DPOConfig(
output_dir="./dpo-aligned-model",
per_device_train_batch_size=2,
learning_rate=5e-5,
num_train_epochs=2,
beta=0.1, # DPO温度参数,控制偏离参考模型的强度
max_length=512,
max_prompt_length=256,
)
# 4. 创建 DPOTrainer
dpo_trainer = DPOTrainer(
model=model,
args=dpo_config,
tokenizer=tokenizer,
train_dataset=dpo_dataset["train"],
)
# 5. 进行 DPO 训练
dpo_trainer.train()
dpo_trainer.save_model()
# 训练后,模型生成的内容会更倾向于被人类偏好的风格和安全性。
推理优化(Inference Optimization): 使用量化和高性能运行时让模型“高效、快速、低成本地工作”
旨在提高模型在生产环境中推理速度、降低延迟和减少资源消耗(如显存占用)的技术。对于需要高并发、低延迟的企业应用至关重要。
主要技术:
- 量化(Quantization): 将模型权重从高精度(如 FP32)转换为低精度(如 INT8, INT4)。大大减少模型大小和显存占用,略微牺牲精度
GPTQ: 后训练量化,常用于 GPU
GGUF/llama.cpp: 适用于 CPU 和 GPU 的量化方案 - 模型编译与加速库
vLLM: 著名的 PagedAttention 技术,极大优化了自回归生成的吞吐量。
TensorRT: NVIDIA 的高性能深度学习推理优化器和运行时 - 投机采样 (Speculative Decoding): 使用一个小而快的“草稿模型”来预测多个 token,然后用原始大模型快速验证。可以大幅提升推理速度
高性能API服务
背景: 上述电商公司的智能客服模型需要部署为一个能同时处理成千上万用户请求的 API 服务,要求平均响应时间低于 500 毫秒。
解决方案: 使用 vLLM 部署经过量化后的模型。
# 首先安装 vLLM
# pip install vLLM
# 部署脚本 (api_server.py)
from vllm import SamplingParams, LLMEngine
from fastapi import FastAPI
import uvicorn
import asyncio
app = FastAPI(title="vLLM API Server")
# 1. 初始化优化后的 vLLM 引擎
# 假设我们已将模型转换为 GPTQ INT4 量化格式
model_id = "./llama3-customer-service-gptq-4bit"
# 使用 vLLM 的异步引擎
engine = LLMEngine.from_engine_args(
model=model_id,
quantization="gptq", # 指定量化方式
max_model_len=1024,
gpu_memory_utilization=0.9,
)
# 2. 定义异步推理函数
async def generate_async(prompt):
sampling_params = SamplingParams(
temperature=0.7,
max_tokens=200,
stop=["\n用户:", "</s>"] # 停止词
)
request_id = f"req-{hash(prompt)}"
results_generator = engine.generate(
prompt, sampling_params, request_id
)
final_output = None
async for request_output in results_generator:
final_output = request_output
return final_output.outputs[0].text
# 3. 创建 FastAPI 端点
@app.post("/generate")
async def generate_endpoint(data: dict):
prompt = data.get("prompt")
if not prompt:
return {"error": "No prompt provided"}
try:
generated_text = await generate_async(prompt)
return {"response": generated_text}
except Exception as e:
return {"error": str(e)}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
# 启动服务
python api_server.py
# 客户端测试 (test_client.py)
import requests
url = "http://localhost:8000/generate"
data = {"prompt": "用户: 我买的鞋子尺码不对,可以退换货吗?\n客服:"}
response = requests.post(url, json=data)
print(response.json())
补充:业务团队+算法团队+大模型团队,合作图例
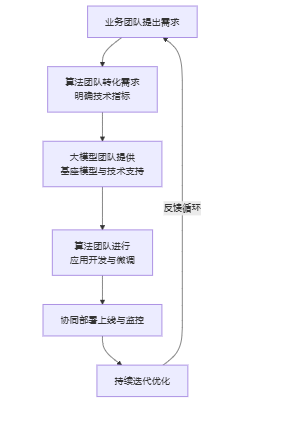
业务团队:智能客服系统需“更准确理解用户复杂问题并一次性解决”。
算法团队与大模型团队:将“准确理解”转化为“意图识别准确率从82%提升至88%”,并明确响应时间低于500ms
输出核心文档:形成包含项目背景、目标、预算、初步时间规划及技术可行性分析的立项申请书和可行性分析报告

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)