【视觉理解大模型】Visual Instruction Tuning(LLaVA)
视觉理解大模型LLaVA简介
·
LLaVA 简介
LLaVA是一个开创性的开源多模态大模型,它旨在让大型语言模型(LLM)具备理解和分析视觉信息的能力。其核心思想是,将一个预训练的视觉编码器(如CLIP的ViT)和一个预训练的大语言模型(如Vicuna或LLaMA)通过一个简单的投影层连接起来,从而“教会”LLM理解图像。
你可以把它想象成给一个盲人(LLM)配了一个能描述世界的“电子眼”(视觉编码器),并通过一个“翻译官”(投影层)将看到的信息转换成盲人能理解的语言。
LLaVA 的详细结构
LLaVA的结构可以分为三个主要部分,其框架如下图所示: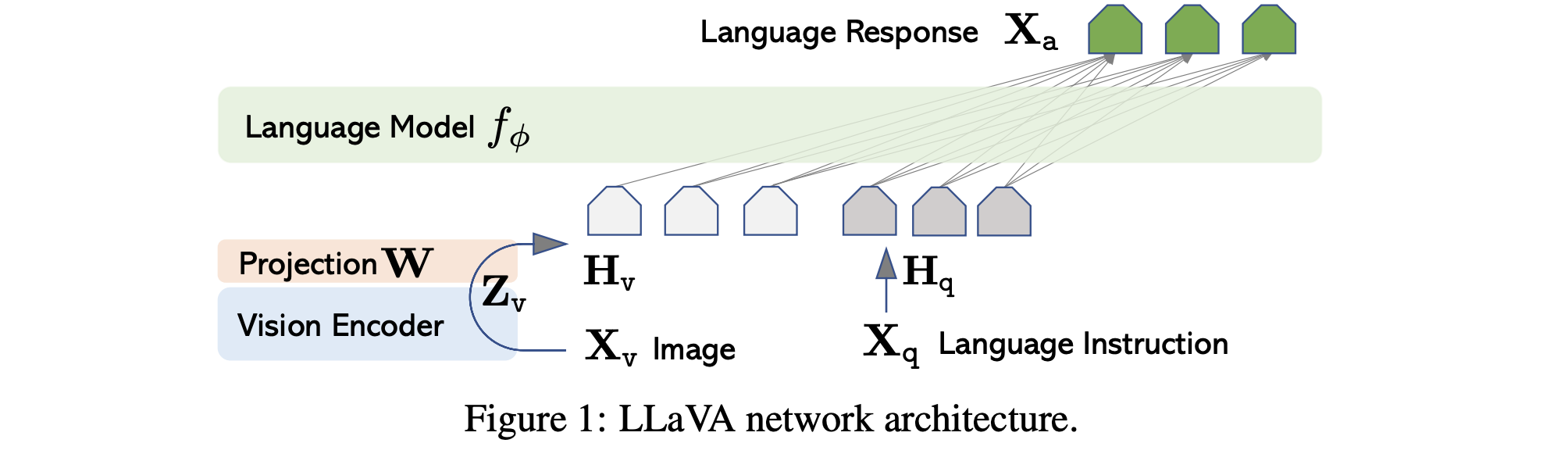
下面我们逐一分解每个部分:
1. 视觉编码器
- 作用: 将输入图像从像素空间转换到一个高维的、具有语义信息的特征空间。简单来说,就是将图片变成计算机能理解的“数字向量”。
- 具体实现: LLaVA通常使用CLIP模型的视觉编码器部分(Visual Encoder),其本身是一个ViT(Vision Transformer)。
- 处理过程: 一张图片会被分割成多个图像块(Patches),然后送入ViT。ViT的输出是一个由特征向量组成的网格(例如 14x14 = 196个特征向量),每个向量都包含了图像局部和全局的信息。这些特征通常被称为视觉令牌。
2. 投影层
- 作用: 这是LLaVA最巧妙也最关键的部分。视觉编码器输出的特征空间和LLM所理解的语言特征空间是完全不同的。投影层的作用就是将视觉特征“对齐”或“映射”到语言模型的特征空间中,让LLM能够“读懂”这些视觉信息。
- 具体实现: 在LLaVA v1中,这个投影层通常是一个简单的线性层(全连接层) 或一个小型的多层感知机。
- 处理过程: 视觉编码器输出的196个视觉令牌会分别通过这个投影层,被转换成196个与文本令牌维度相同的特征向量。此时,这些向量可以被视为**“伪语言令牌”**。它们本身不是文字,但LLM会像处理文字一样处理它们。
3. 大语言模型
- 作用: 作为模型的大脑,负责理解和推理。它接收由文本指令和投影后的视觉令牌组成的完整序列,并生成人类可读的文本回答。
- 具体实现: 早期版本使用Vicuna(一个基于LLaMA微调的对话模型),后续版本也支持其他LLaMA架构的模型。
- 处理过程:
- 令牌化: 用户的文本指令(例如“请描述这张图片”)被LLM的令牌化器转换成一系列文本令牌。
- 序列拼接: 投影层输出的“伪语言令牌”(视觉特征)和文本令牌被拼接成一个长的序列。这个序列的结构通常是:
<视觉令牌1> <视觉令牌2> ... <视觉令牌N> <文本令牌1> <文本令牌2> ...。 - 推理生成: 这个完整的序列被送入LLM。LLM基于其强大的上下文理解能力,将视觉令牌和文本令牌结合起来进行推理,并以自回归的方式(根据上文生成下一个词)产生流畅、准确的回答。
训练过程(两阶段)
LLaVA的训练分为两个阶段,这是其成功的关键:
-
预对齐阶段(特征对齐):
- 目标: 只训练投影层的参数,冻结视觉编码器和LLM。
- 数据: 使用大量“图像-描述文本”对(如CC3M数据集)。
- 目的: 让投影层学会如何将视觉特征准确地映射到LLM的输入空间。训练完成后,LLM看到投影后的视觉令牌,就能大致理解图像的内容。这可以看作是“教会LLM识字(图)”。
-
端到端微调阶段(指令跟随):
- 目标: 同时微调投影层和LLM的参数(视觉编码器通常仍被冻结)。
- 数据: 使用人工精心标注的“图像-复杂指令-回答”数据。例如,不仅描述图片内容,还包括回答问题、推理、推理等。
- 目的: 让模型学会根据人类的复杂指令与多模态上下文进行交互,成为一个真正有用的“助手”,而不仅仅是一个图像描述器。
输入输出举例
假设我们有以下图片和指令:
图片: 一张照片,照片里一只可爱的柯基犬正在公园的草地上追逐一个飞盘。
示例1: 简单描述
- 用户输入(文本指令): “请描述一下这张图片。”
- 模型内部序列:
[视觉令牌1] ... [视觉令牌196] [请] [描述] [一下] [这张] [图片] [。] - LLaVA可能的输出: “图片中,一只棕白色的柯基犬在绿油油的草地上奔跑,正跳起来试图接住空中飞来的一个红色飞盘。天气看起来很好,背景有树木和天空。”
示例2: 视觉问答
- 用户输入(文本指令): “这只狗是什么品种?”
- 模型内部序列:
[视觉令牌1] ... [视觉令牌196] [这只] [狗] [是] [什么] [品种] [?] - LLaVA可能的输出: “这是一只柯基犬。”
示例3: 复杂推理
- 用户输入(文本指令): “这只狗的心情怎么样?为什么?”
- 模型内部序列:
[视觉令牌1] ... [视觉令牌196] [这只] [狗] [的] [心情] [怎么样] [?] [为什么] [?] - LLaVA可能的输出: “这只柯基犬看起来非常开心和兴奋。因为它正在草地上自由地奔跑玩耍,追逐飞盘,这是一种常见的让狗感到快乐的活动。”
示例4: 多图像输入(LLaVA-1.5及以后版本支持)
- 用户输入(两张图片 + 文本指令): (图片1:一个干净的房间)(图片2:一个杂乱的房间)“比较一下这两个房间。”
- 模型内部序列:
[图片1的视觉令牌] [图片2的视觉令牌] [比较] [一下] [这] [两个] [房间] [。] - LLaVA可能的输出: “第一张图片中的房间非常整洁,床铺铺好了,书桌上的物品摆放有序。而第二张图片中的房间则较为杂乱,床上和地上有散落的衣物和物品。两者形成了鲜明的对比。”
总结
LLaVA的结构精髓在于其简洁而有效的设计:
- 视觉编码器: 负责“看”图。
- 投影层: 负责“翻译”视觉信号为语言信号。
- 大语言模型: 负责“思考”和“回答”。
通过两阶段训练,LLaVA成功地将其强大的语言能力扩展到了视觉领域,成为了一个通用的视觉-语言对话助手,为开源多模态AI的发展奠定了坚实的基础。后续的LLaVA-1.5等版本主要是在此结构上改进投影层(如使用MLP而非线性层)、引入更细粒度的图像特征、并使用更大规模的高质量数据进行训练,从而持续提升性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)