【Agent】通义DeepResearch之通过CPT Scaling Agents
首次将智能体持续预训练 (Agentic CPT) 的概念引入研究型智能体的训练中。为此,他们提出了 AgentFounder,一个系统化、可扩展的大规模数据合成方案,它通过整个后训练流程的数据,创造了一个数据飞轮。提出了First-order Action Synthesis (FAS) 和 Higher-order Action Synthesis (HAS),并采用两阶段训练策略,系统地生成
note
- 首次将智能体持续预训练 (Agentic CPT) 的概念引入研究型智能体的训练中。为此,他们提出了 AgentFounder,一个系统化、可扩展的大规模数据合成方案,它通过整个后训练流程的数据,创造了一个数据飞轮。
- 提出了First-order Action Synthesis (FAS) 和 Higher-order Action Synthesis (HAS),并采用两阶段训练策略,系统地生成大规模agent数据。
- 核心点合成数据策略,也就是多阶段数据生成与优化方案,涵盖 Agentic 持续预训练数据(AgentFounder方案,核心点是收集文档、公开爬取数据、知识图谱、历史轨迹等多源数据,然后基于随机采样的实体及对应知识生成多风格
<问题,答案>对)和后训练数据。里面的技术点还是图谱网络,利用实体的多跳信息走复杂推理数据。也切合我们近期一直说的基于图谱来合成数据问题的思路
文章目录
一、Scaling Agents via Continual Pre-training
链接:https://huggingface.co/papers/2509.13310
GitHub:https://tongyi-agent.github.io
模型链接:https://modelscope.cn/models/iic/Tongyi-DeepResearch-30B-A3B
技术博客:https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
研究问题:LLMs虽然已经演变成能够自主使用工具和进行多步推理的代理系统,但基于通用基础模型的后训练方法在这些任务中表现不尽如人意。
效果:在 Humanity’s Last Exam、BrowseComp、BrowseComp-ZH、GAIA、xbench-DeepSearch, WebWalkerQA 以及 FRAMES 等多个 Benchmark 上,相比于基于基础模型的 ReAct Agent 和闭源 Deep Research Agent,其 30B-A3B 轻量级 tongyi DeepResearch,达到了 SOTA 效果。
通义 DeepResearch 团队也在 Blog 和 Github 完整分享了一套可落地的 DeepResearch Agent 构建方法论,系统性地覆盖了从数据合成、Agentic 增量预训练 (CPT)、有监督微调 (SFT) 冷启动,到强化学习 (RL) 的端到端全流程。尤其在 RL 阶段,该团队提供了集算法创新、自动化数据构建与高稳定性基础设施于一体的全栈式解决方案。在推理层面,模型展现出双重优势:基础的 ReAct 模式无需提示工程即可充分释放模型固有能力;而深度模式 (test-time scaling) 则进一步探索了其在复杂推理与规划能力上的上限。
二、Tongyi-DeepResearch
1、增量预训练数据构建
(1)一阶动作合成(FAS)
一阶动作合成(FAS):FAS在没有监督信号的情况下运行,依赖于多样化的数据源。FAS包括情境场景构建和两种类型的动作合成:规划动作和推理动作。
- 知识到问题的转换:通过将静态知识转换为动态问题解决情境,生成多样化的训练上下文。

- 规划动作合成:生成多个推理-动作数据,每个问题生成K个不同的分析视角,扩展动作空间探索。
- 推理动作合成:通过分解问题并生成初步答案和最终答案,生成高质量的逻辑推理链式思维数据。
在一阶动作合成(FAS)中,知识到问题的转换主要通过以下两个步骤实现:
- 实体锚定的开放世界知识内存:将不断更新的非结构化文本从各种来源转换为开放世界内存,其中实体作为索引键映射到其关联的声明性语句。这种方法不仅保留了关键信息,还通过重新格式化增强了知识语句的密度。
- 多风格问题合成:从实体锚定的开放世界内存中采样实体簇及其关联的知识语句,合成多样化的问题。这些问题涵盖事实检索、数值计算、多跳推理和合成任务。通过这种方式,静态知识被转换为动态问题解决情境,迫使模型进行主动的信息检索、集成和工具创新,从而增强代理行为。
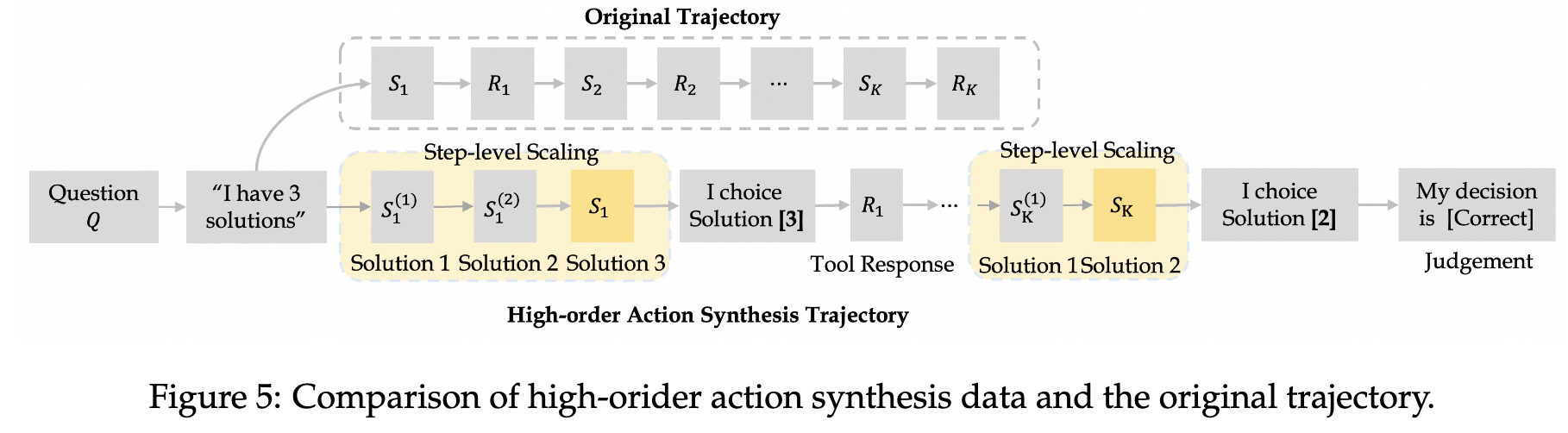
(2)高阶动作合成(HAS)
高阶动作合成(HAS):HAS通过逐步扩展每个步骤的推理和动作选项集,将原始轨迹和探索的推理-动作空间转换为决策处理。具体步骤包括:
- 步骤级扩展:在每个步骤生成N个替代的“思考和调用”候选,形成序列。
- 对比决策-动作合成:模拟多选项选择和决策过程,记录每一步的判断文本。
高阶动作合成(HAS)如何通过逐步扩展每个步骤的推理和动作选项集来增强模型的能力?高阶动作合成(HAS)通过以下步骤增强模型的能力:
- 步骤级扩展:在每个步骤生成N个替代的“思考和调用”候选,形成序列。具体来说,给定一个问题和一个步骤的上下文,模型生成多个可能的下一步推理和工具调用,这些候选被合并到一个新的序列中,形成一个扩展的决策路径。
- 对比决策-动作合成:将扩展的决策路径转换为渐进式的决策过程。具体步骤包括:
- 多选项选择:在每个步骤,枚举所有可能的候选,并插入一个局部动作决策语句:“我将选择选项N”。
- 真实响应:记录每个步骤的真实响应(如工具返回的结果)。
- 判断文本:在每个步骤后,添加一个判断文本:“我的判断是{正确/错误}”。
2、SFT微调
高质量的合成问答对:为了突破 AI 智能体的性能极限,团队开发了一套端到端的全自动化数据合成解决方案。这个过程无需任何人工干预,就能构建出超高质量的数据集。这套方法经过了长期的探索和迭代——从早期通过逆向工程从点击流生成问答对(WebWalker),到更系统的基于图谱的合成方法(WebSailor),再到形式化的任务建模(WebShaper),最终确保了卓越的数据质量和大规模的可扩展性。
为了解决那些复杂且不确定性高的问题,团队通过一个新颖的流程来合成基于网络的问答数据。
- 首先,通过随机游走和同构表构建,从真实网站数据中建立高度互联的知识图谱,确保了信息的真实结构。
- 然后,对子图和子表进行采样,生成初始的问题和答案。
- 最关键的一步,是通过巧妙地模糊或混淆问题中的信息来刻意增加难度。这种方法背后有完整的理论框架支撑,将问答难度形式化建模为实体关系上的一系列可控“原子操作”(例如,合并属性相似的实体),从而能够系统地提升问题的复杂度。
通过 SFT 冷启动提升智能体能力:
为了提升模型的初始能力,团队基于 ReAct 和新提出的 IterResearch 框架(下文会详述),通过拒绝采样构建了一批 SFT 轨迹数据。
- 一方面,ReAct 作为经典的多轮推理格式,为模型注入了丰富的推理行为,并强化了其遵循结构化格式的能力。
- 另一方面,团队引入了
IterResearch,这是一种创新的智能体范式。它通过在每一轮动态重建一个精简的工作空间,来释放模型的全部推理潜力,确保每个决策都经过深思熟虑。利用IterResearch,团队构建了一批融合了推理、规划和工具使用的轨迹,从而增强了模型在面对复杂任务时持续规划的能力。
3、模型的RL训练
从一个原始模型开始,通过 CPT 预训练初始化工具使用技能,然后用专家级数据进行 SFT 冷启动,最后进行在线强化学习。端到端 Agent 训练流程:
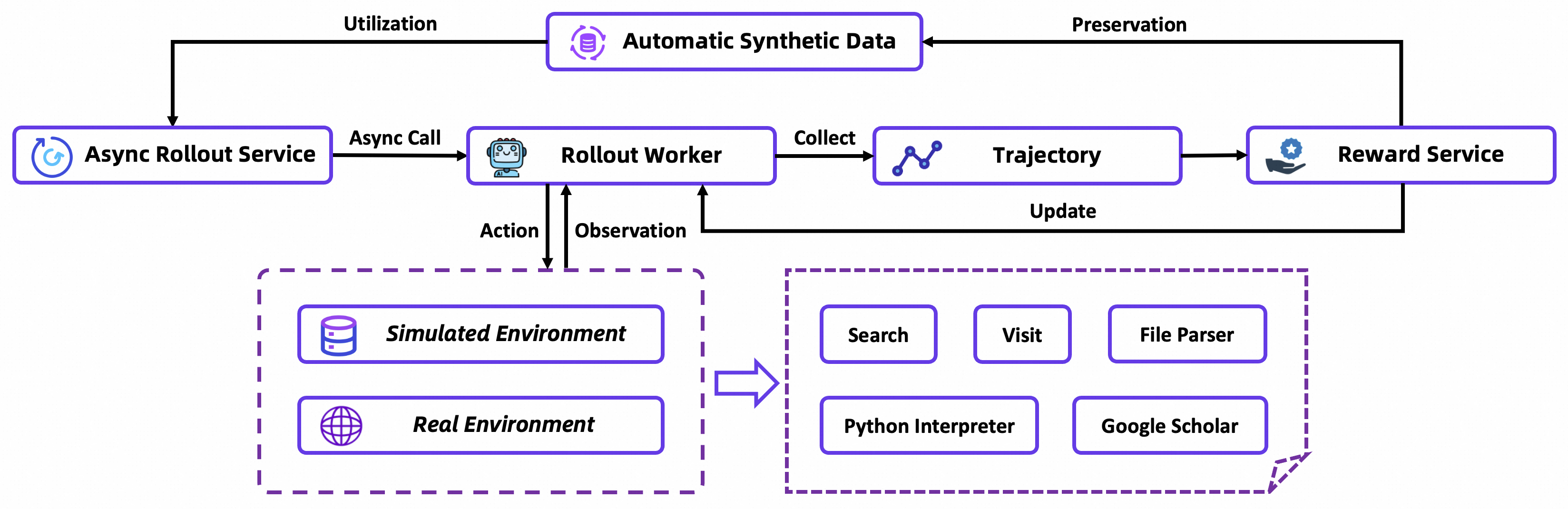
Tongyi DeepResearch Agent 建立了一套连接 Agentic CPT → Agentic SFT → Agentic RL 的训练范式。
使用组相对策略优化 (Group Relative Policy Optimization, GRPO) 算法。
- 首先,采用严格的在线训练方案,确保学习信号始终与模型当前的能力相关。
- 其次,为了进一步减少优势估计的方差,采用了留一法 (leave-one-out) 策略。
- 此外,对负样本采取保守策略,因为未经筛选的负样本轨迹会显著降低训练稳定性,甚至在长时间训练后导致“格式崩溃”。为此,团队会选择性地将某些负样本排除在损失计算之外(例如,那些因超长而未能产生最终答案的样本)。
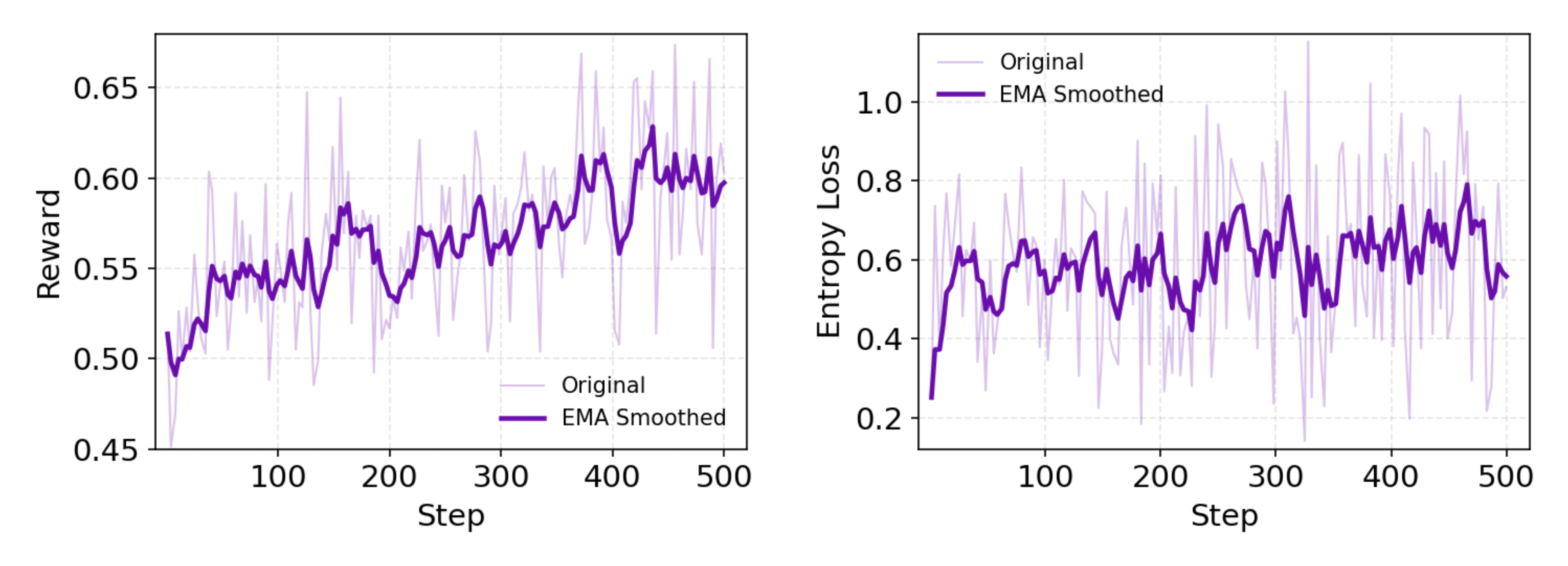
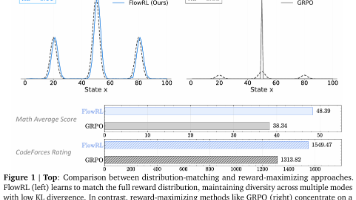
分析:上图表明学习有效,因为reward持续增加,另外policy entropy持续保持较高数值(说明在持续探索中,防止过拟合)。我们把这归因于web环境的不稳定特性,有助于自适应性策略的形成,无需进行显式的熵正则化。
4、推理模式
Tongyi DeepResearch 既有原生的 ReAct Mode,又有进行上下文管理的 Heavy Mode。
(1)ReAct Mode
ReAct Mode:严格遵循“思考-行动-观察”的循环,通过多次迭代来解决问题
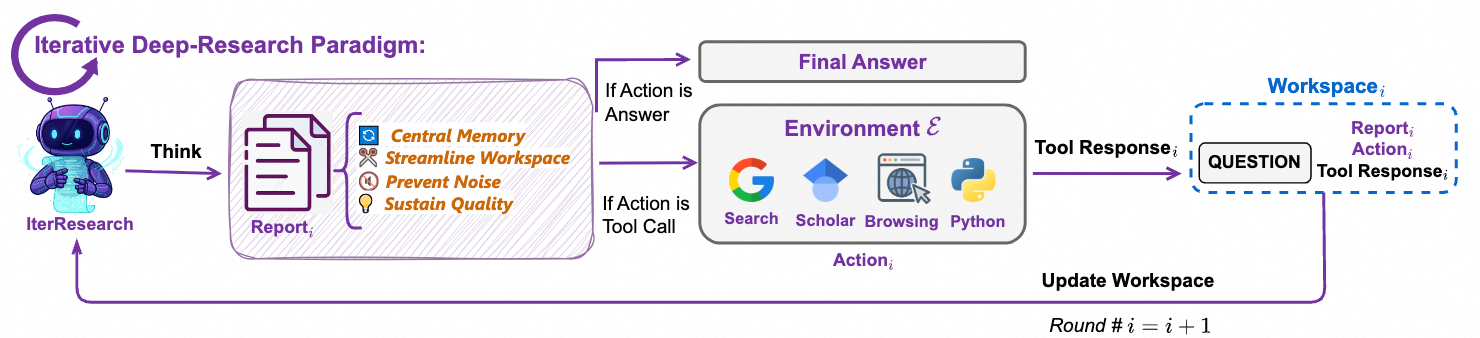
(2)重度模式 (Heavy Mode)
团队还开发了专为复杂、多步研究任务设计的“重度模式” (Heavy Mode)。该模式基于新的 IterResearch 范式构建。IterResearch 范式的提出是为了解决一个痛点:当智能体把所有信息都堆积在一个不断膨胀的上下文中时,容易出现“认知窒息”和“噪音污染”。而 IterResearch 则将任务分解为一系列的“研究回合”。
三、实验设计
数据收集:Agentic CPT的持续预训练语料库包括高质量的网络爬取数据、历史工具调用记录、离线维基数据和之前后期训练迭代中丢弃的轨迹。
实验设置:评估AgentFounder-30B在10个基准测试上的性能,并与现有的最先进的深度研究代理模型进行比较。实验使用了三种不同的SFT配置:SFT-A、SFT-B和SFT-C。
基准测试:评估了通用网络搜索基准和场景定向网络搜索基准,包括BrowseComp-en、BrowseComp-zh、GAIA、Xbench-DeepSearch、WebWalkerQA、DeepResearch Bench、SEAL-0、Frames、HLE和Academic Browse。
工具:评估模型配备了五个核心工具:搜索、访问、Python解释器、Google Scholar和文件解析器。
超参数:评估AgentFounder模型时,使用特定的推理参数以确保稳定和可重复的结果:温度0.85,重复惩罚1.1,top-p 0.95。
训练数据总结
CPT训练数据:(1) 针对事实准确性过滤的高质量网络爬取数据,(2) 历史工具调用记录,例如搜索结果和网页内容 (3) 离线维基百科数据,以及 (4) 来自先前训练后迭代的混合质量丢弃轨迹。
SFT数据,三种训练策略:
- sft-a:两阶段训练,第一个阶段是用通用对话问答对数据,第二个阶段是Agent的React形式推理数据(带有reason内容)。
- sft-b:两阶段训练,但是每个阶段都是混合【通用对话问答对数据】和【Agent的React形式推理数据(带有reason内容)】的训练
- sft-c:和sft-b类似,但是agent react推理数据的推理内容是经过高度总结的
四、模型评测
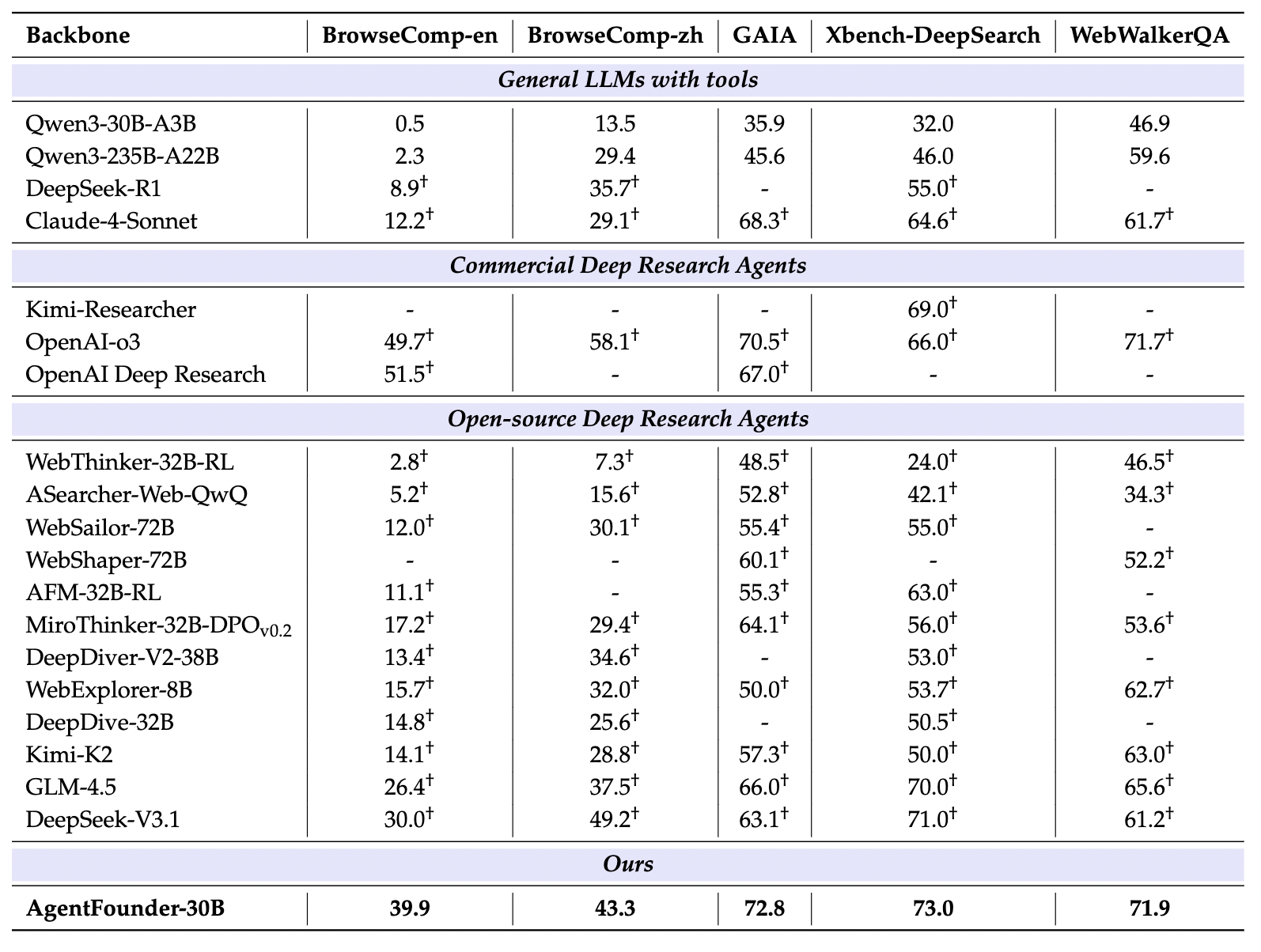
benchmark表现
- 通用web search benchmarks
- 特定场景的web search benchmarks
Reference
[1] Scaling Agents via Continual Pre-training
[2] 通义DeepResearch全面开源!同步分享可落地的高阶Agent构建方法论
[3] 通义DeepResearch震撼发布!性能比肩OpenAI,模型、框架、方案完全开源
[4] 首个全开源DeepResearch诞生,性能硬刚OpenAI!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)