【AI论文】FlowRL:为大型语言模型(LLM)推理匹配奖励分布
摘要:本研究提出FlowRL方法,通过流量平衡匹配完整奖励分布(而非仅最大化奖励)来解决大语言模型强化学习中多样性不足的问题。传统方法(如PPO/GRPO)易过度优化主导奖励信号而忽略低频有效路径。FlowRL将标量奖励转换为归一化目标分布,通过最小化反向KL散度促进多样化探索。实验显示,在数学推理任务中FlowRL比GRPO/PPO分别提升10.0%/5.1%,在代码推理任务中持续表现更优。该方
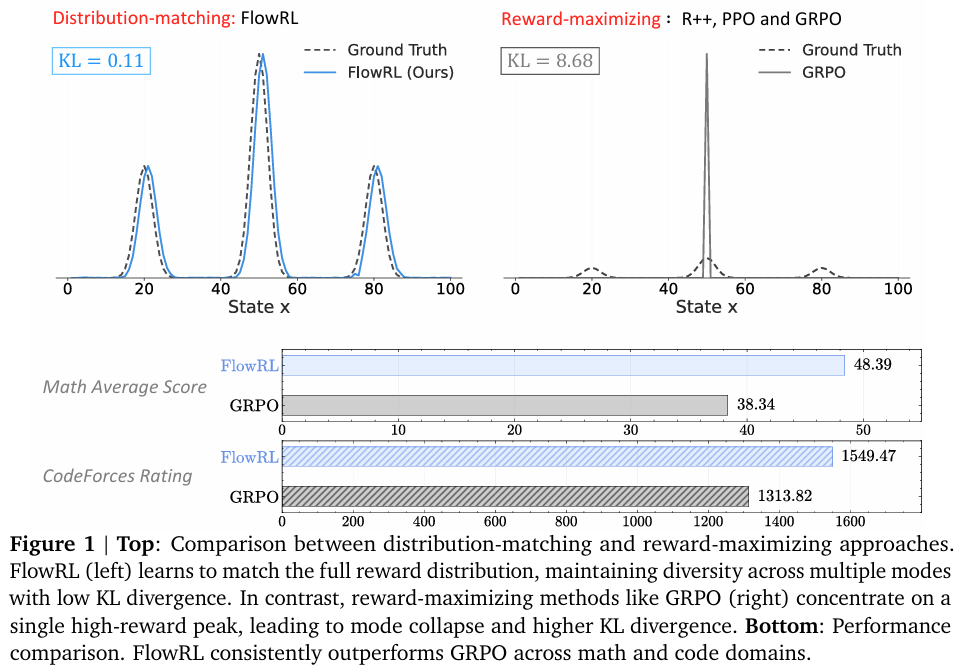
摘要:我们提出FlowRL:在大语言模型(Large Language Model,LLM)强化学习(Reinforcement Learning,RL)中,通过流量平衡(flow balancing)来匹配完整的奖励分布,而非最大化奖励。近期先进的推理模型采用奖励最大化方法(如近端策略优化算法PPO和群体相对策略优化算法GRPO),这些方法倾向于过度优化占主导地位的奖励信号,同时忽略出现频率较低但有效的推理路径,从而降低了多样性。与之相反,我们利用可学习的划分函数将标量奖励转换为归一化的目标分布,然后最小化策略分布与目标分布之间的反向KL散度(reverse KL divergence)。我们将这一思路实现为一种流量平衡优化方法,该方法可促进多样化的探索并生成可泛化的推理轨迹。我们在数学推理和代码推理任务上进行了实验:在数学基准测试中,FlowRL相较于GRPO平均提升了10.0%,相较于PPO平均提升了5.1%,并且在代码推理任务上表现持续更优。这些结果凸显了奖励分布匹配在实现大语言模型强化学习中高效探索和多样化推理方面的关键作用。Huggingface链接:Paper page,论文链接:2509.15207
研究背景和目的
研究背景:
随着大型语言模型(LLMs)在自然语言处理领域的广泛应用,其在推理任务上的表现尤为引人注目。然而,传统的强化学习(RL)方法在训练LLMs进行推理时,往往侧重于奖励最大化,即优化模型以产生高奖励的单一输出。这种方法虽然有效,但容易导致模型忽略那些虽然奖励较低但同样有效且多样化的推理路径,从而限制了模型的泛化能力和推理多样性。这种现象在复杂的长链推理(Chain-of-Thought, CoT)任务中尤为明显,因为这类任务通常需要探索多种可能的解决方案。
为了应对这一挑战,研究者们开始探索新的RL方法,旨在通过匹配完整的奖励分布而非仅仅最大化奖励,来促进模型在推理过程中的多样性和泛化能力。FlowRL作为一种新兴的RL方法,通过将标量奖励转换为归一化的目标分布,并最小化策略与目标分布之间的反向KL散度,实现了对多样化推理路径的探索。
研究目的:
本研究旨在通过提出FlowRL这一新的RL框架,解决传统奖励最大化方法在LLMs推理训练中导致的模式崩溃(mode collapse)和多样性缺失问题。具体目标包括:
- 提升推理多样性:通过匹配完整的奖励分布,鼓励模型探索多种有效的推理路径,而不仅仅是优化单一的高奖励路径。
- 增强泛化能力:通过多样化的推理路径探索,使模型能够更好地适应未见过的推理场景,提高泛化能力。
- 优化强化学习训练:提出一种新的RL优化方法,通过流平衡(flow balancing)来匹配完整的奖励分布,而非仅仅最大化奖励。
研究方法
1. 理论基础:
- 奖励分布匹配:FlowRL的核心思想是将标量奖励转换为归一化的目标分布,通过引入一个可学习的划分函数Zϕ(x)将标量奖励归一化为目标分布,并最小化策略与目标分布之间的反向KL散度。
- 梯度等价证明:证明了在期望梯度意义上,最小化KL目标等价于GFlowNets中的轨迹平衡损失,为生成建模和策略优化提供了理论桥梁。
2. 技术解决方案:
- 长度归一化:针对长链推理(CoT)训练中的梯度爆炸问题,引入长度归一化方法,通过将log概率项除以序列长度来平衡长短序列的贡献,稳定学习信号。
- 重要性采样:为了解决微批次更新和旧策略重用轨迹带来的采样不匹配问题,采用重要性采样方法,通过重要性比率w来重新加权过时轨迹,并采用PPO风格的裁剪来稳定政策更新,防止过度策略漂移。
3. 实验设计:
- 基准测试:选择数学和代码推理任务作为基准测试,包括AIME 2024/2025、AMC2023、MATH-500、Minerva、Olympiad等数学基准测试,以及LiveCodeBench、CodeForces、HumanEval+等代码基准测试。
- 基线模型:选择REINFORCE++(R++)、PPO和GRPO作为基线模型进行比较,这些模型代表了当前先进的奖励最大化RL方法。
- 实验配置:使用Qwen-2.5-7B/32B和DeepSeek-R1-Distill-Qwen-7B作为基础模型,在数学和代码任务上进行实验。对于每个模型,使用相同的学习率、批次大小和训练步骤数进行公平比较。
4. 评估方法:
- 数学推理任务:在六个具有挑战性的数学基准测试上评估模型性能,包括AIME 2024/2025、AMC2023、MATH-500、Minerva和Olympiad等。
- 代码推理任务:在LiveCodeBench、CodeForces和HumanEval+等基准测试上评估模型的代码推理能力。
- 多样性评估:使用GPT-4o-mini评估模型生成答案的多样性,以验证FlowRL在促进多样化推理路径方面的有效性。
研究结果
1. 数学推理任务上的表现:
- FlowRL在数学基准测试上的平均准确率显著高于GRPO和PPO,特别是在32B模型规模下,FlowRL的平均准确率达到了48.4%,较GRPO和PPO有显著提升。
- 在六项具有挑战性的数学基准测试中,FlowRL均表现出色,展示了其广泛的适用性和稳定性。
2. 代码推理任务上的表现:
- FlowRL在三个具有挑战性的编码基准测试上表现出色,平均准确率达到37.43%,在LiveCodeBench上更是达到了最高分,展示了其强大的代码推理能力。
3. 多样性分析:
- 通过对生成推理路径的多样性分析,发现FlowRL生成的推理路径多样性显著高于基线方法,验证了FlowRL在促进多样化推理方面的有效性。
研究局限
- 数据依赖:FlowRL的性能高度依赖于训练数据的质量和多样性。如果训练数据存在偏差或不足,可能会影响模型的泛化能力和推理多样性。
- 模型复杂度:FlowRL方法相对于传统RL方法更为复杂,可能需要更高的计算资源和更长的训练时间。
未来研究方向:
- 优化数据收集与标注:进一步扩大数据收集范围,特别是针对特定任务的高质量指令数据,确保数据的多样性和覆盖性。同时,引入更先进的标注技术和质量控制机制,提高数据标注的准确性和可靠性。
- 模型架构优化:探索更高效的模型架构和训练策略,如基于Transformer的变体或混合架构,以进一步提高模型性能和效率。同时,加强模型对复杂任务和长序列任务的处理能力,如通过引入更先进的推理机制或记忆机制。
- 跨语言与跨文化研究:探索阿拉伯语与其他语言的跨语言模型,研究不同语言之间的迁移学习和知识共享机制,提高模型在阿拉伯语上的表现。同时,考虑文化差异和语言习惯,优化模型在不同阿拉伯语地区的表现。
- 强化模型安全性与鲁棒性:研究模型在面对对抗性攻击时的鲁棒性,引入对抗性训练技术,提高模型在面对对抗性样本时的稳定性和安全性。同时,开发模型解释和调试工具,帮助研究人员和开发者更好地理解和调试模型行为。
- 持续监测与评估:建立一个持续的模型评估和反馈系统,定期评估模型在真实场景下的表现,并根据用户反馈进行迭代优化。同时,加强模型的可解释性研究,提高用户对模型决策的信任度。
总结
本研究通过引入FlowRL方法,将传统强化学习中的奖励最大化目标转变为奖励分布匹配,有效解决了奖励最大化方法导致的模式崩溃问题,提高了大型语言模型在数学和代码推理任务上的多样性和泛化能力。实验结果表明,FlowRL在多个基准测试中均显著优于传统RL方法,特别是在需要复杂推理的长链思维(CoT)推理任务中表现尤为突出。未来研究可进一步优化模型架构、提升模型性能,并探索更广泛的应用场景和任务类型,同时关注模型的可解释性、安全性和伦理问题,推动大型语言模型在推理任务上的持续进步。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献146条内容
已为社区贡献146条内容

所有评论(0)