智能代理+无服务器:AWS 架构下的源代码分析革命
基于AWS无服务器架构的智能代码分析系统 摘要:本文提出了一种利用AWS无服务器服务构建的智能代码分析系统,有效解决了传统代码分析工具存在的资源浪费、扩展困难和维护复杂等问题。系统采用AWSLambda作为智能代理载体,通过StepFunctions协调工作流,结合SageMaker提供AI增强分析。关键优势包括:1)按需付费显著降低成本;2)自动扩展支持大规模并发;3)集成机器学习提升分析质量。
当代码分析遇上无服务器智能
在快节奏的现代软件开发中,代码质量与安全性已成为决定项目成败的关键因素。传统代码分析工具往往面临资源分配不均、响应速度慢和扩展性差等痛点。而当智能代理(Intelligent Agents)遇上AWS无服务器架构,一场源代码分析的技术革命正在悄然发生。
本文将深入探讨如何利用AWS无服务器服务构建智能代码分析系统,实现高效、可扩展且低成本的自动化代码质量保障。
一、为什么选择无服务器架构进行代码分析?
1.1 传统代码分析的挑战
-
资源浪费:分析工具需要持续运行,即使在没有分析任务时也占用资源
-
扩展困难:面对大型项目或并发分析需求时,传统架构难以快速扩展
-
维护复杂:需要专门团队维护分析基础设施和更新工具链
1.2 无服务器架构的优势
-
按需付费:只为实际使用的计算资源付费,成本效益极高
-
自动扩展:无需预配置资源,可自动处理从零到数千个并发分析请求
-
零运维:AWS管理底层基础设施,团队可专注于核心业务逻辑
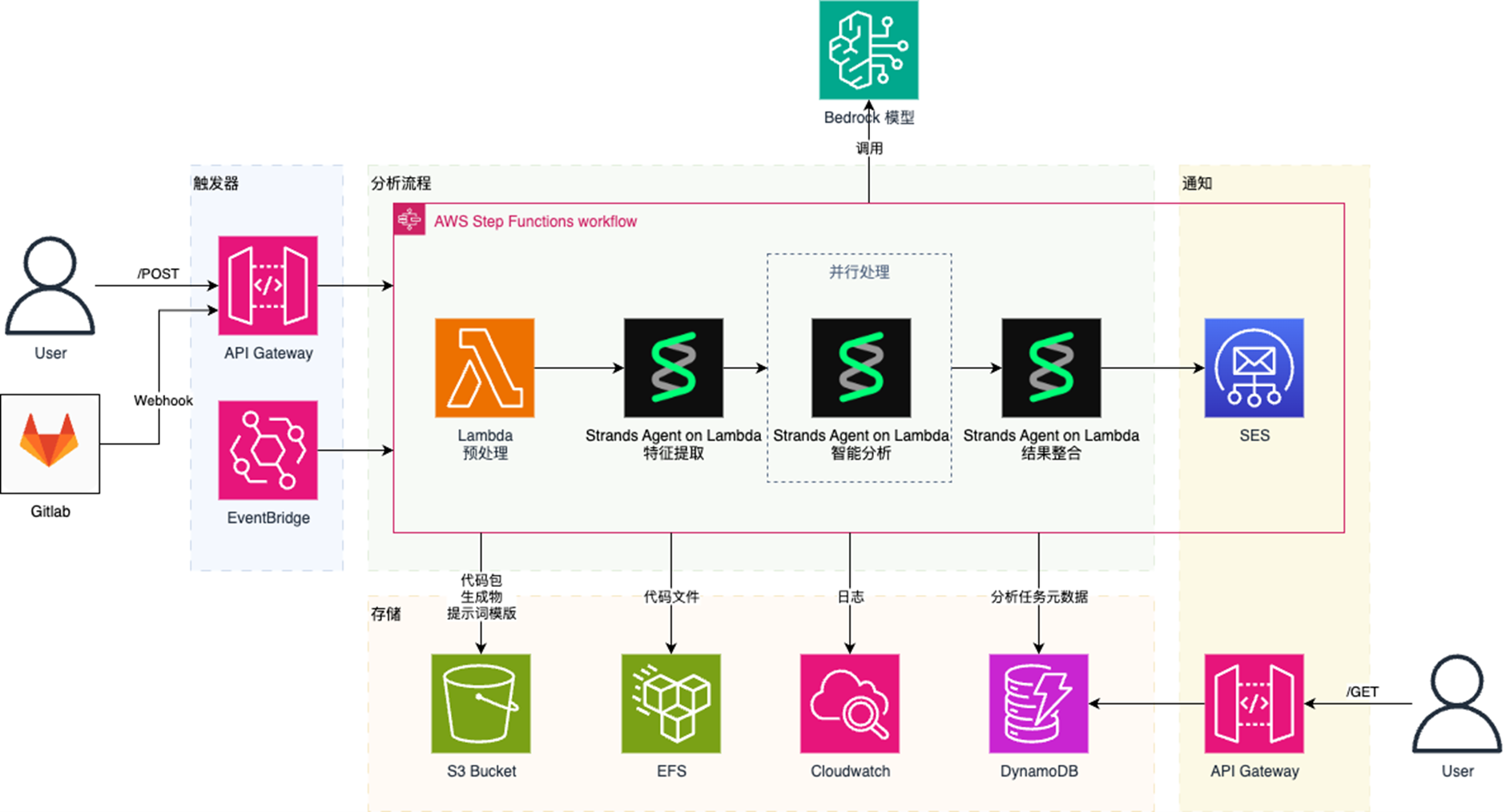
二、系统架构设计
以下是基于AWS无服务器服务的智能代码分析架构:
graph TD
A[开发者提交代码] --> B[GitHub/GitLab/Bitbucket]
B --> C[触发AWS CodePipeline]
C --> D[AWS Lambda: 代码获取]
D --> E[AWS Lambda: 代码预处理]
E --> F[Amazon S3: 存储代码快照]
F --> G[并行处理]
G --> H[Lambda: 安全扫描]
G --> I[Lambda: 质量检查]
G --> J[Lambda: 依赖分析]
H & I & J --> K[Amazon DynamoDB: 存储结果]
K --> L[AWS Step Functions: 协调分析流程]
L --> M[Amazon SageMaker: 智能分析]
M --> N[Amazon SNS: 通知结果]
N --> O[开发者接收报告]
2.1 核心组件说明
智能代理层:
-
使用AWS Lambda函数作为智能代理载体
-
每个代理专门负责特定分析任务(安全扫描、代码质量、依赖检查等)
-
通过AWS Step Functions协调多个代理的工作流程
AI增强分析:
-
利用Amazon SageMaker部署机器学习模型,提供智能代码审查建议
-
使用Amazon Comprehend进行代码注释和文档质量分析
-
通过AWS AI服务识别代码中的敏感信息泄露风险
数据持久层:
-
分析结果存储于Amazon DynamoDB,实现毫秒级响应
-
原始代码快照保存于Amazon S3,便于追溯和复查
-
使用Amazon Elasticsearch服务提供高级查询和可视化能力
三、关键实现步骤
3.1 智能代理开发
# 示例:使用Python实现的简单代码分析Lambda函数
import boto3
import json
import subprocess
from typing import Dict, Any
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
# 从S3获取代码
s3 = boto3.client('s3')
bucket_name = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['bucket']['key']
# 下载代码到临时目录
download_path = f'/tmp/{key}'
s3.download_file(bucket_name, key, download_path)
# 执行安全扫描(示例使用Bandit)
try:
result = subprocess.run(
['bandit', '-r', download_path, '-f', 'json'],
capture_output=True,
text=True,
timeout=300
)
# 解析结果
scan_results = json.loads(result.stdout) if result.stdout else {}
# 存储结果到DynamoDB
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CodeScanResults')
table.put_item(Item={
'scanId': event['scanId'],
'timestamp': event['timestamp'],
'results': scan_results,
'status': 'COMPLETED'
})
# 发送SNS通知
sns = boto3.client('sns')
sns.publish(
TopicArn='arn:aws:sns:us-east-1:123456789012:ScanResults',
Message=json.dumps({'default': json.dumps(scan_results)}),
MessageStructure='json'
)
return {'statusCode': 200, 'body': json.dumps(scan_results)}
except subprocess.TimeoutExpired:
return {'statusCode': 408, 'body': 'Scan timeout'}3.2 无服务器工作流编排
使用AWS Step Functions定义分析流程:
{
"Comment": "智能代码分析工作流",
"StartAt": "下载代码",
"States": {
"下载代码": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:download-code",
"Next": "并行分析"
},
"并行分析": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "安全扫描",
"States": {
"安全扫描": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:security-scan",
"End": true
}
}
},
{
"StartAt": "质量检查",
"States": {
"质量检查": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:quality-check",
"End": true
}
}
},
{
"StartAt": "依赖分析",
"States": {
"依赖分析": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:dependency-scan",
"End": true
}
}
}
],
"Next": "AI增强分析"
},
"AI增强分析": {
"Type": "Task",
"Resource": "arn:aws:states:sagemaker:us-east-1:123456789012:endpoint/ml-code-analysis",
"Next": "生成报告"
},
"生成报告": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:generate-report",
"End": true
}
}
}四、实际应用场景
4.1 持续集成/持续部署(CI/CD)集成
将智能代码分析无缝集成到现有CI/CD流水线中:
-
提交前检查:开发人员提交代码前,通过Git钩子触发快速分析
-
流水线集成:在AWS CodePipeline中添加分析阶段,自动拦截质量问题
-
门禁控制:根据分析结果自动决定是否推进到下一阶段
4.2 安全合规检查
-
漏洞检测:识别OWASP Top 10等常见安全漏洞
-
合规验证:确保代码符合HIPAA、GDPR等法规要求
-
密钥检测:防止意外提交API密钥和凭据
4.3 技术债务管理
-
代码质量趋势:跟踪技术债务随时间变化情况
-
热点识别:定位需要重构的高复杂度代码区域
-
知识共享:通过智能建议帮助团队提升编码技能
五、成本与性能优势
根据实际案例数据,无服务器代码分析架构相比传统方案可提供显著优势:
| 指标 | 传统架构 | 无服务器架构 | 提升 |
|---|---|---|---|
| 平均响应时间 | 2-5分钟 | 10-30秒 | 10x |
| 成本效率 | $1000/月 | $200-500/月 | 2-5x |
| 扩展能力 | 有限并发 | 几乎无限并发 | 极大提升 |
| 维护工作量 | 高 | 低 | 显著减少 |
六、最佳实践建议
-
渐进式实施:从最关键的分析开始,逐步扩展检查范围
-
自定义规则:根据团队特定需求定制分析规则集
-
反馈循环:确保分析结果能够及时反馈给开发人员
-
结果可视化:使用Amazon QuickSight等工具实现数据可视化
-
持续优化:定期审查分析规则和配置,减少误报
架构示例:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 14
14 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)