LangChain4j + 加入检索增加生成 RAG(知识库)
大模型是基于网络公开的数据信息资料,回答你的,但是一些行业专业术语,以及公司内部的数据资料,大模型是无法获取到的,而我们的 RAG(小抄)就解决了,这个问题。我们可以将我们的内部资料设置为(RAG 小抄),让大模型回答的时候,根据我们给它提供的 RAG(小抄)回答我们的问题。RAG技术就像给AI大模型装上了「实时百科大脑」,为了让大模型获取足够的上下文,以便获得更加广泛的信息源,通过先查资料后回答

核心设计理念: RAG技术就像给AI大模型装上了「实时百科大脑」,为了让大模型获取足够的上下文,以便获得更加广泛的信息源,通过先查资料后回答的机制,让AI摆脱传统模型的"知识遗忘和幻觉回复"困境。
一句话简单的说:就是让大模型有一个类似于小抄的,当大模型在回答你的问题的时候,先检索你给大模型提供的(RAG 小抄的资料),结合你提供的小抄的资料,在回答你的问题,减少了大模型的“幻觉”,同时也让大模型更加专业,准确。 大模型是基于网络公开的数据信息资料,回答你的,但是一些行业专业术语,以及公司内部的数据资料,大模型是无法获取到的,而我们的 RAG(小抄)就解决了,这个问题。我们可以将我们的内部资料设置为(RAG 小抄),让大模型回答的时候,根据我们给它提供的 RAG(小抄)回答我们的问题。
LangChain4j RAG 的使用理论
RAG 流程分为两个不同的阶段:索引 + 检索
在索引阶段,文档会被预处理,以便在检索阶段进行高效搜索。
这个过程可能因使用的信息检索方法而异。 对于向量搜索,这通常涉及清理文档、用额外数据和元数据丰富文档、 将文档分割成更小的片段(也称为分块)、嵌入这些片段,最后将它们存储在嵌入存储(也称为向量数据库)中。
索引阶段通常是离线进行的,这意味着最终用户不需要等待其完成。 例如,可以通过定时任务在周末每周重新索引一次公司内部文档来实现。 负责索引的代码也可以是一个单独的应用程序,只处理索引任务。
然而,在某些情况下,最终用户可能希望上传自己的自定义文档,使 LLM 能够访问这些文档。 在这种情况下,索引应该在线进行,并成为主应用程序的一部分。
以下是索引阶段的简化图表:
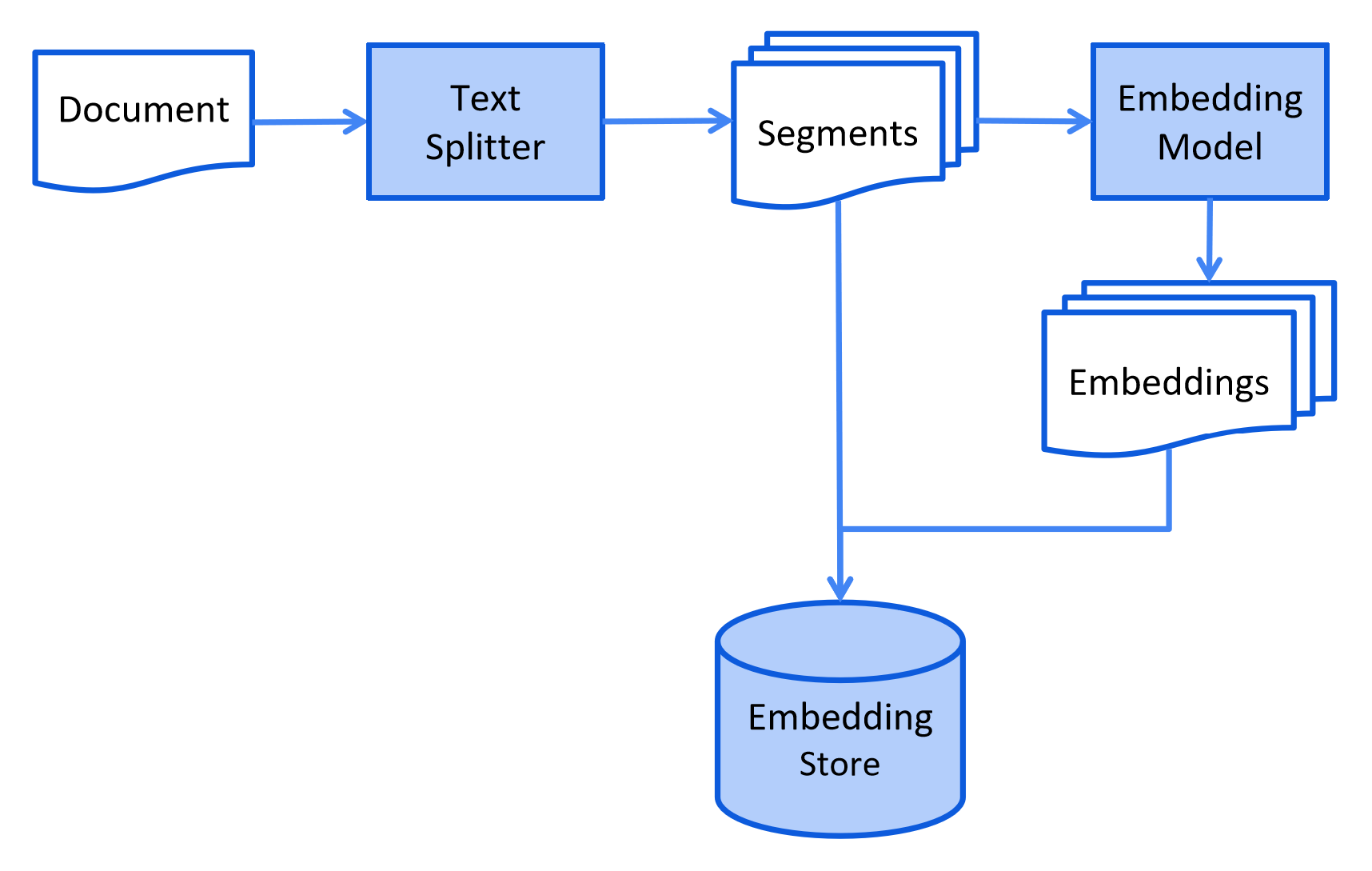
简单的理解就是:一般我们的提供给大模型的 RAG(小抄)的内容是很大的,数据量大,同时要提高大模型查找我们的 RAG(小抄),我们就需要将我们的 RAG(小抄),通过向量大模型将 RAG(小抄)转换为向量数据,存储到向量数据库当中。减少空间的占用,以及提高效率。
同时:索引阶段通常是离线进行的,这意味着最终用户不需要等待其完成。 例如,可以通过定时任务在周末每周重新索引一次公司内部文档来实现。 负责索引的代码也可以是一个单独的应用程序,只处理索引任务。
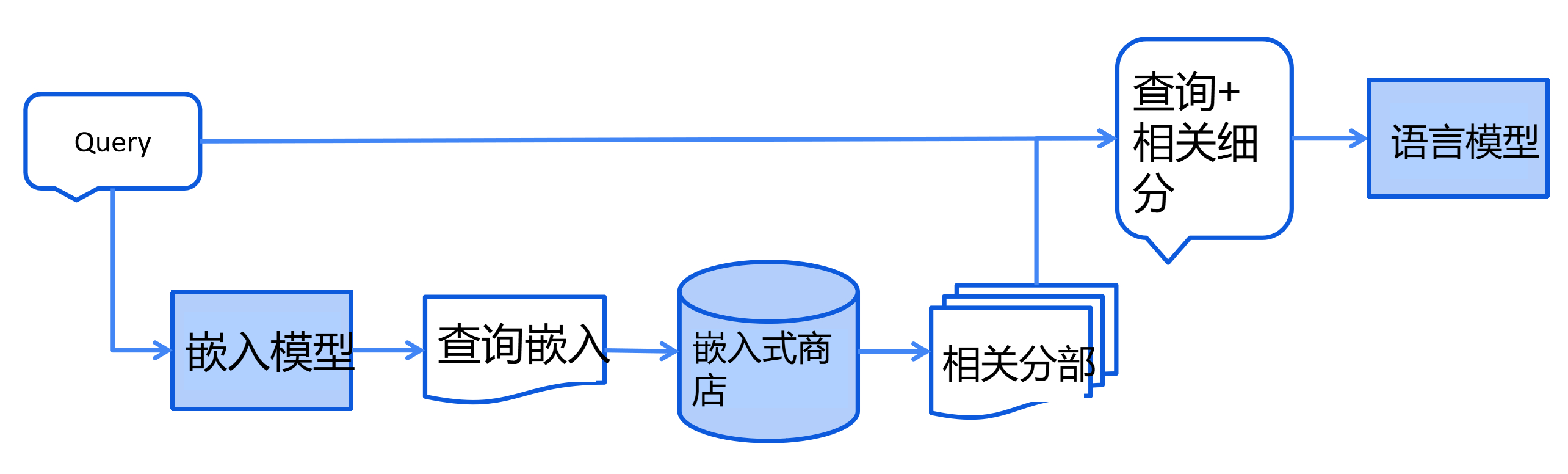
检索阶段通常在线进行,当用户提交一个应该使用索引文档回答的问题时。
这个过程可能因使用的信息检索方法而异。 对于向量搜索,这通常涉及嵌入用户的查询(问题) 并在嵌入存储中执行相似度搜索。 然后将相关片段(原始文档的片段)注入到提示中并发送给 LLM。
以下是检索阶段的简化图表:

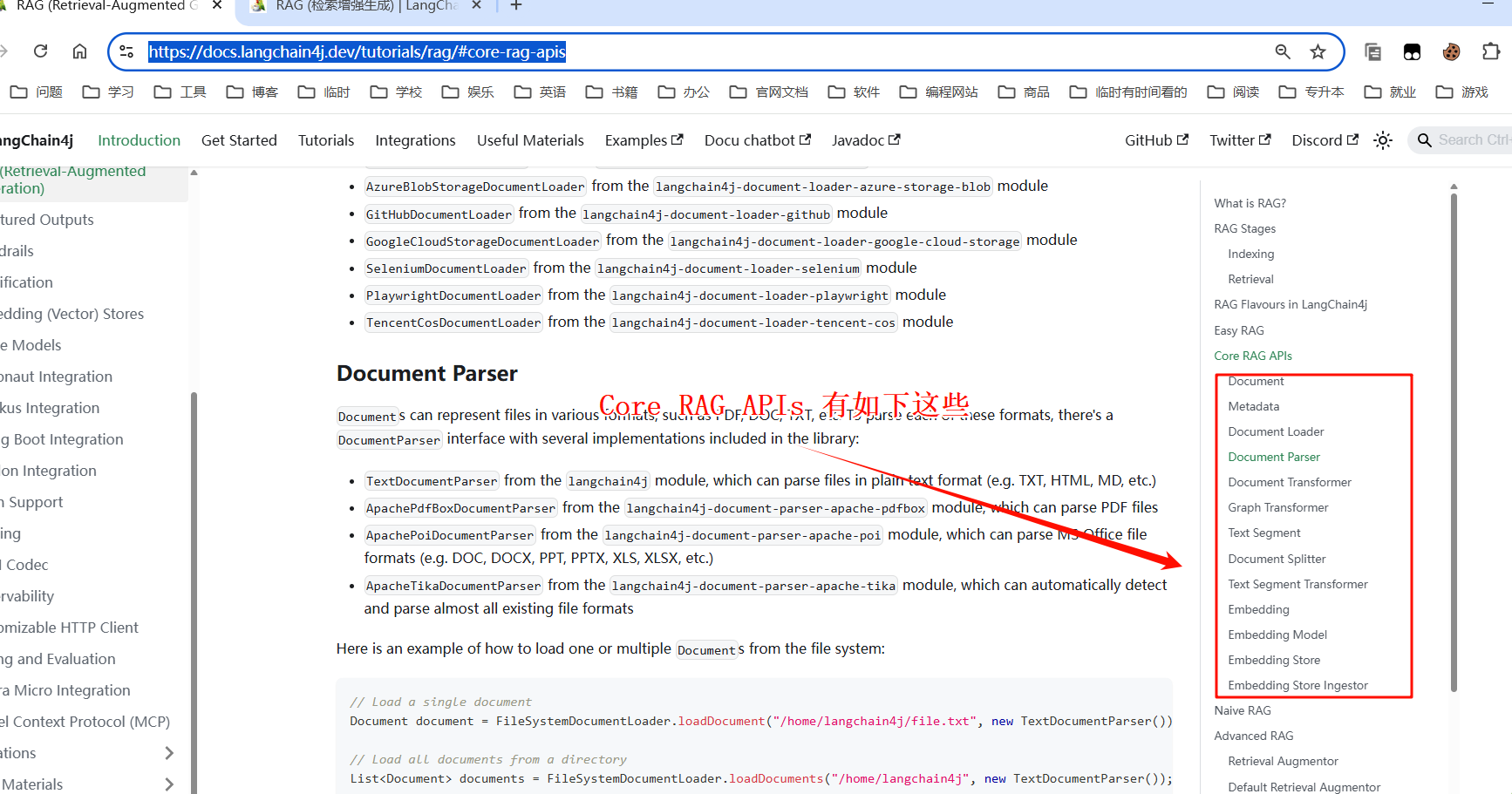

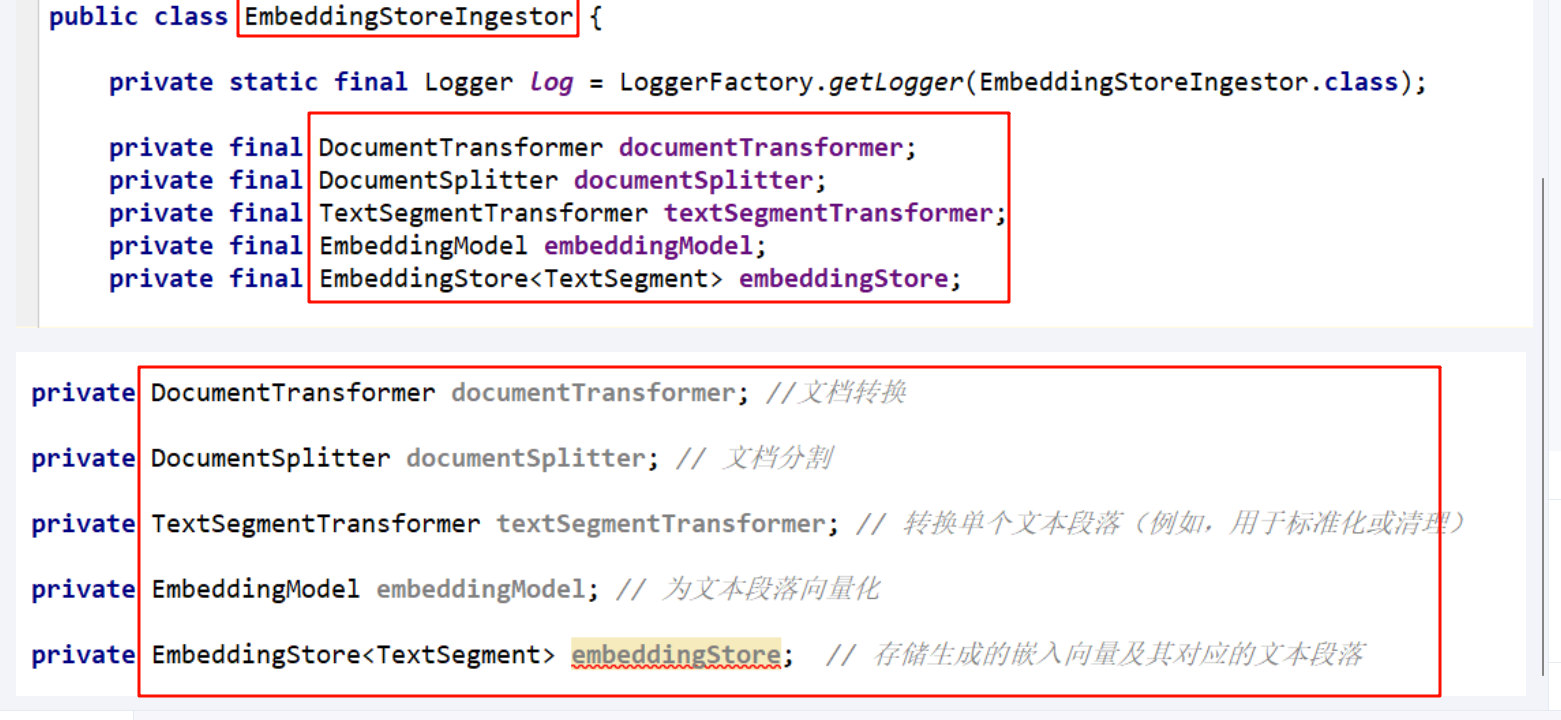
- EmbeddingStorelngestor组织结构分析:
- Document Loader(文档加载器):
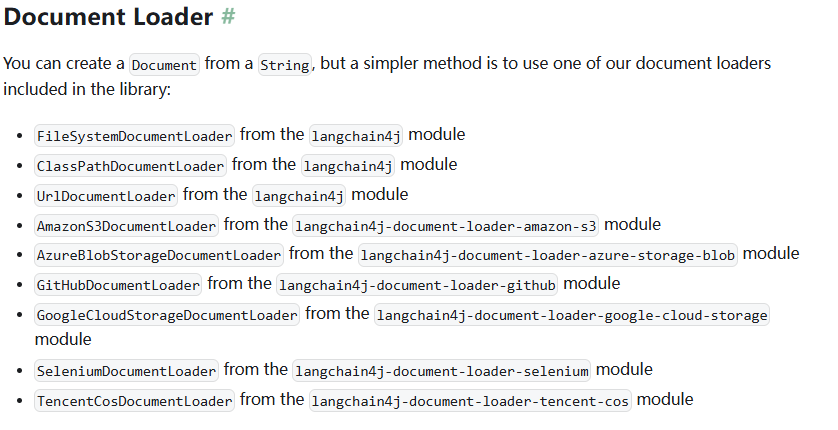
<span style="color:#000000"><span style="background-color:#fefef2"><code class="language-java">FileSystemDocumentLoader: 从文件系统加载文档
UrlDocumentLoader: 从 URL 加载文档
AmazonS3DocumentLoader: 从 Amazon S3 加载文档
AzureBlobStorageDocumentLoader: 从 Azure Blob 存储加载文档
GitHubDocumentLoader: 从 GitHub 仓库加载文档
TencentCosDocumentLoader: 从腾讯云 COS 加载文档
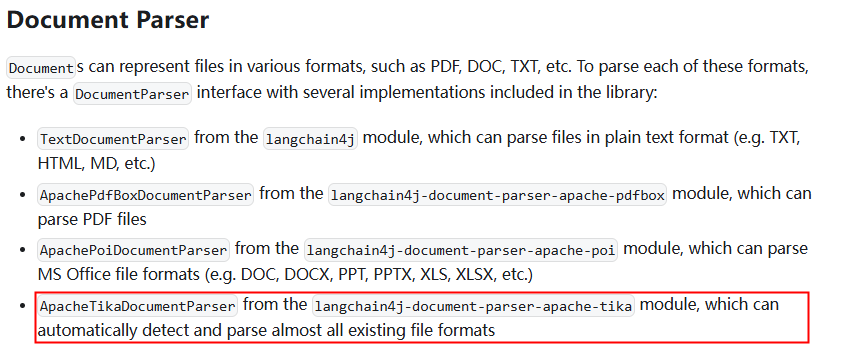
</code></span></span>- Document Parser(文档解析器):
- Document Transformer(文档转换器):
DocumentTransformer 用于对文档执行各种转换,如清理、过滤、增强或总结。
- Document Splitter(文档拆分器):
<span style="color:#000000"><span style="background-color:#fefef2"><code class="language-java">DocumentByParagraphSplitter: 按段落拆分
DocumentBySentenceSplitter: 按句子拆分
DocumentByWordSplitter: 按单词拆分
DocumentByCharacterSplitter: 按字符拆分
DocumentByRegexSplitter: 按正则表达式拆分
</code></span></span>使用 LangChain4j 构建 RAG 的一般步骤:
- 加载文档:使用适当的DocumentLoader和DocumentParser加载文档
- 转换文档:使用DocumentTransformer清理或增强文档(可选)
- 拆分文档:使用DocumentSplitter将文档拆分为更小的片段(可选)
- 嵌入文档:使用EmbeddingModel将文档片段转换为嵌入向量
- 存储嵌入:使用EmbeddingStoreIngestor存储嵌入向量
- 检索相关内容:根据用户查询,从EmbeddingStore检索最相关的文档片段
- 生成响应:将检索到的相关内容与用户查询一起提供给语言模型,生成最终响应

LangChain4j RAG 的实战
LangChain4j 提供了三种 RAG 风格:
- Easy RAG:开始使用 RAG 的最简单方式
- Naive RAG:使用向量搜索的基本 RAG 实现
- Advanced RAG:一个模块化的 RAG 框架,允许额外的步骤,如 查询转换、从多个来源检索和重新排序
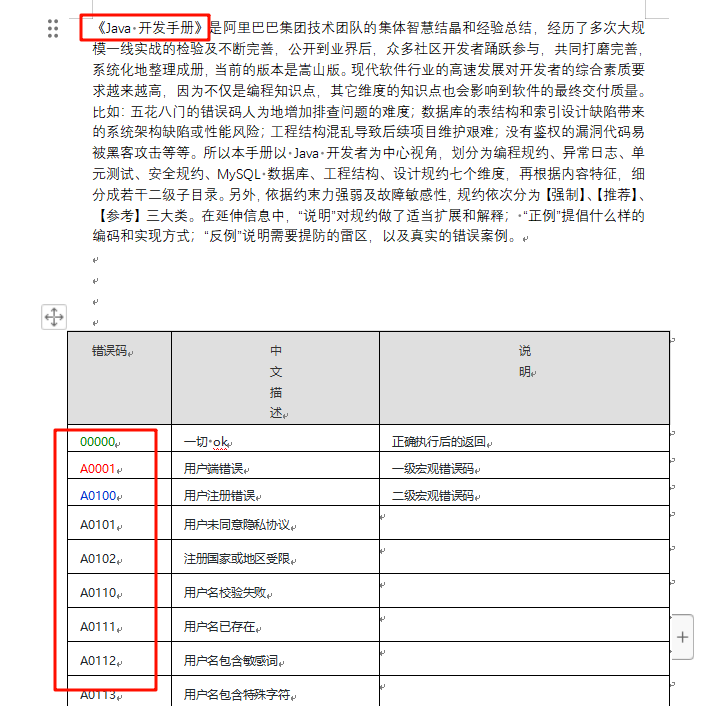
这里我们使用 Easy RAG ,同时这里我们在使用“内存向量”,作为向量数据库,存储我们 RAG(小抄)转化为的向量数据。我们设计给大模型提供一个 RAG(内容是:阿里巴巴 Java 开发手册当中的错误码),配置好后,问大模型 错误码:00000,A0001 是什么含义。
- 创建对应项目的 module 模块内容:
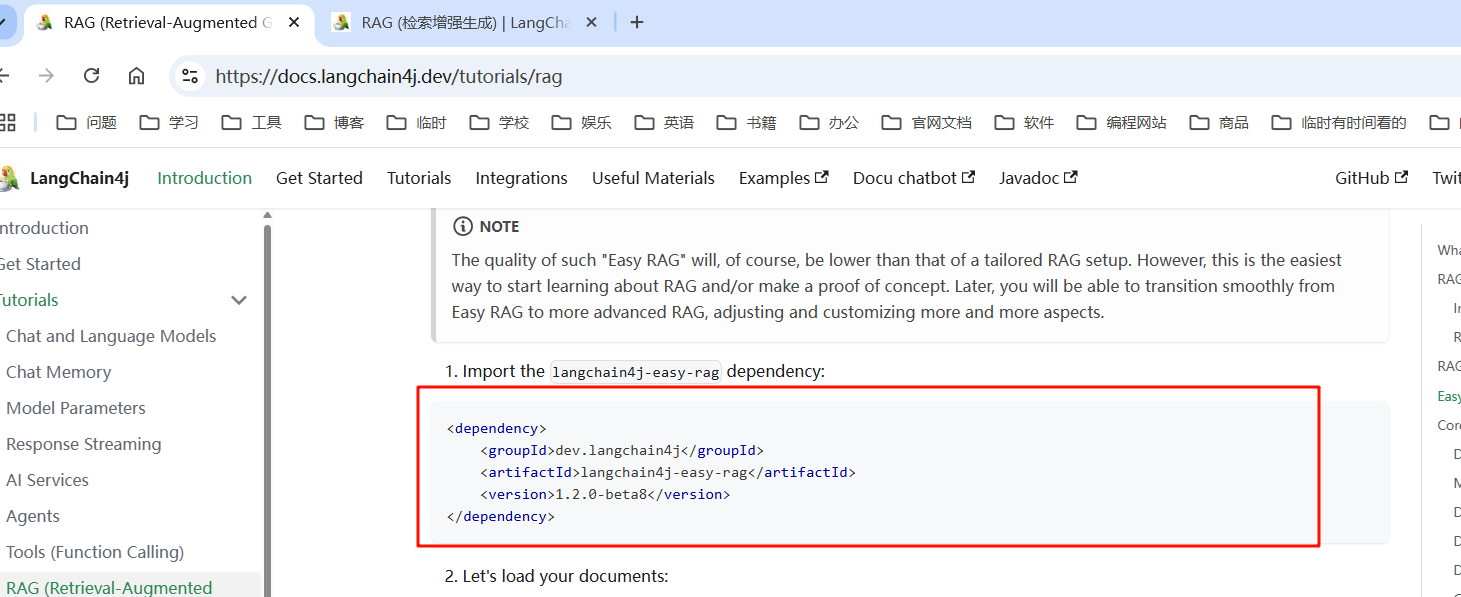
- 导入相关的 pom.xml 的依赖,这里我们采用流式输出的方式,导入_ 整合 Spring Boot ,
langchain4j-open-ai-spring-boot-starter,langchain4j-spring-boot-starter,同时我们加入我们的操作 RAG 的 jak 依赖。因为我们这里使用的是“内存的向量数据库”所以不需要额外的引入其他的向量数据库包。这里我们不指定版本,而是通过继承的 pom.xml 当中获取。_
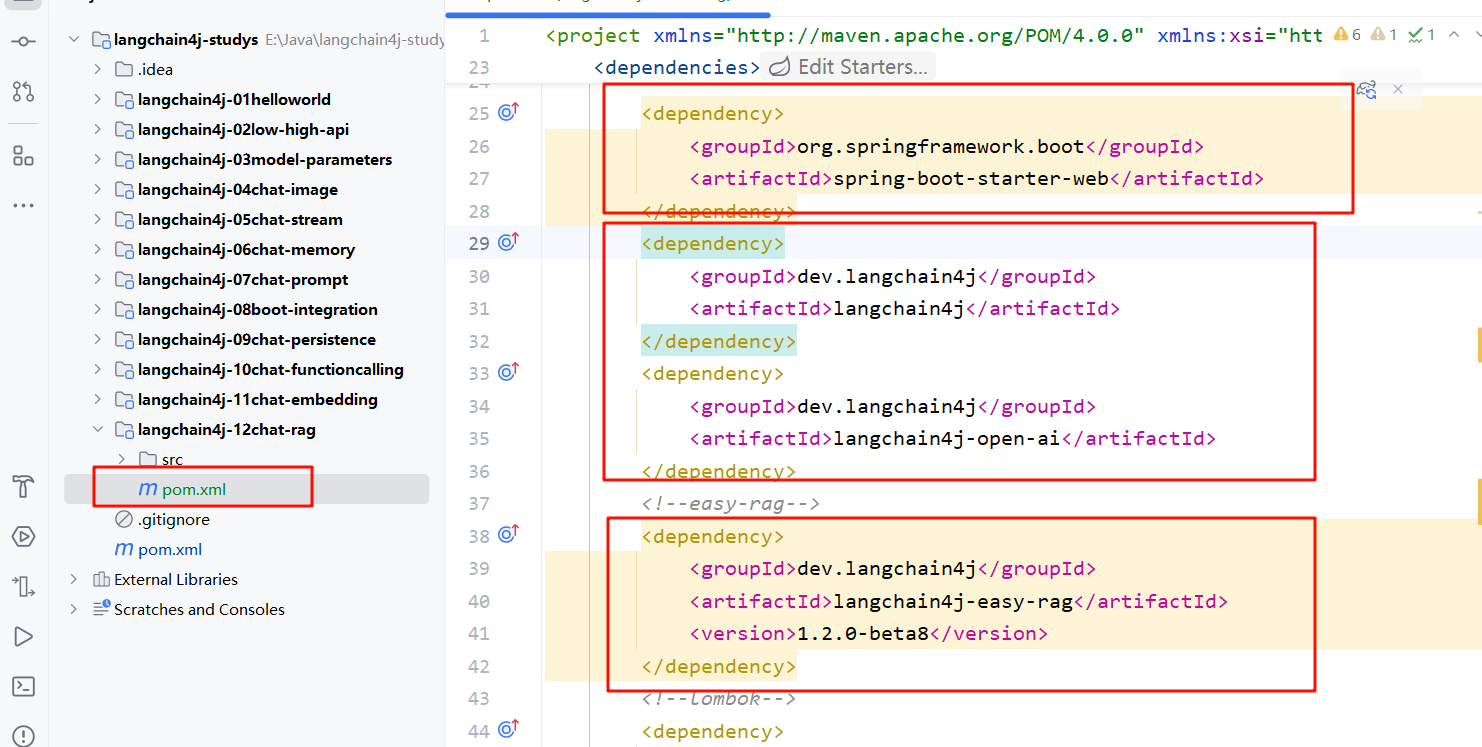
<span style="color:#000000"><span style="background-color:#fefef2"><code class="language-xml"> <<span style="color:#b75501">dependency</span>>
<<span style="color:#b75501">groupId</span>>org.springframework.boot</<span style="color:#b75501">groupId</span>>
<<span style="color:#b75501">artifactId</span>>spring-boot-starter-web</<span style="color:#b75501">artifactId</span>>
</<span style="color:#b75501">dependency</span>>
<<span style="color:#b75501">dependency</span>>
<<span style="color:#b75501">groupId</span>>dev.langchain4j</<span style="color:#b75501">groupId</span>>
<<span style="color:#b75501">artifactId</span>>langchain4j</<span style="color:#b75501">artifactId</span>>
</<span style="color:#b75501">dependency</span>>
<<span style="color:#b75501">dependency</span>>
<<span style="color:#b75501">groupId</span>>dev.langchain4j</<span style="color:#b75501">groupId</span>>
<<span style="color:#b75501">artifactId</span>>langchain4j-open-ai</<span style="color:#b75501">artifactId</span>>
</<span style="color:#b75501">dependency</span>>
<span style="color:#656e77"><!--easy-rag--></span>
<<span style="color:#b75501">dependency</span>>
<<span style="color:#b75501">groupId</span>>dev.langchain4j</<span style="color:#b75501">groupId</span>>
<<span style="color:#b75501">artifactId</span>>langchain4j-easy-rag</<span style="color:#b75501">artifactId</span>>
<<span style="color:#b75501">version</span>>1.2.0-beta8</<span style="color:#b75501">version</span>>
</<span style="color:#b75501">dependency</span>>
</code></span></span>- 设置 applcation.yaml / properties 配置文件,其中指明我们的输出响应的编码格式,因为如果不指定的话,存在返回的中文,就是乱码了。
<span style="color:#000000"><span style="background-color:#fefef2"><code class="language-properties"><span style="color:#015692">server.port</span>=<span style="color:#54790d">9012</span>
<span style="color:#015692">spring.application.name</span>=<span style="color:#54790d">langchain4j-12chat-rag</span>
<span style="color:#656e77">
# 设置响应的字符编码,避免流式返回输出乱码</span>
<span style="color:#015692">server.servlet.encoding.charset</span>=<span style="color:#54790d">utf-8</span>
<span style="color:#015692">server.servlet.encoding.enabled</span>=<span style="color:#54790d">true</span>
<span style="color:#015692">server.servlet.encoding.force</span>=<span style="color:#54790d">true</span>
<span style="color:#656e77">
# https://docs.langchain4j.dev/tutorials/spring-boot-integration</span>
<span style="color:#656e77">#langchain4j.open-ai.chat-model.api-key=${aliQwen-api}</span>
<span style="color:#656e77">#langchain4j.open-ai.chat-model.model-name=qwen-plus</span>
<span style="color:#656e77">#langchain4j.open-ai.chat-model.base-url=https://dashscope.aliyuncs.com/compatible-mode/v1</span>
<span style="color:#656e77"># 大模型调用不可以明文配置,你如何解决该问题</span>
<span style="color:#656e77"># 1 yml: ${aliQwen-api},从环境变量读取</span>
<span style="color:#656e77"># 2 config配置类: System.getenv("aliQwen-api")从环境变量读取</span>
</code></span></span>- 编写让大模型做什么事情——>这里是聊天的,接口类 ChatAssistant
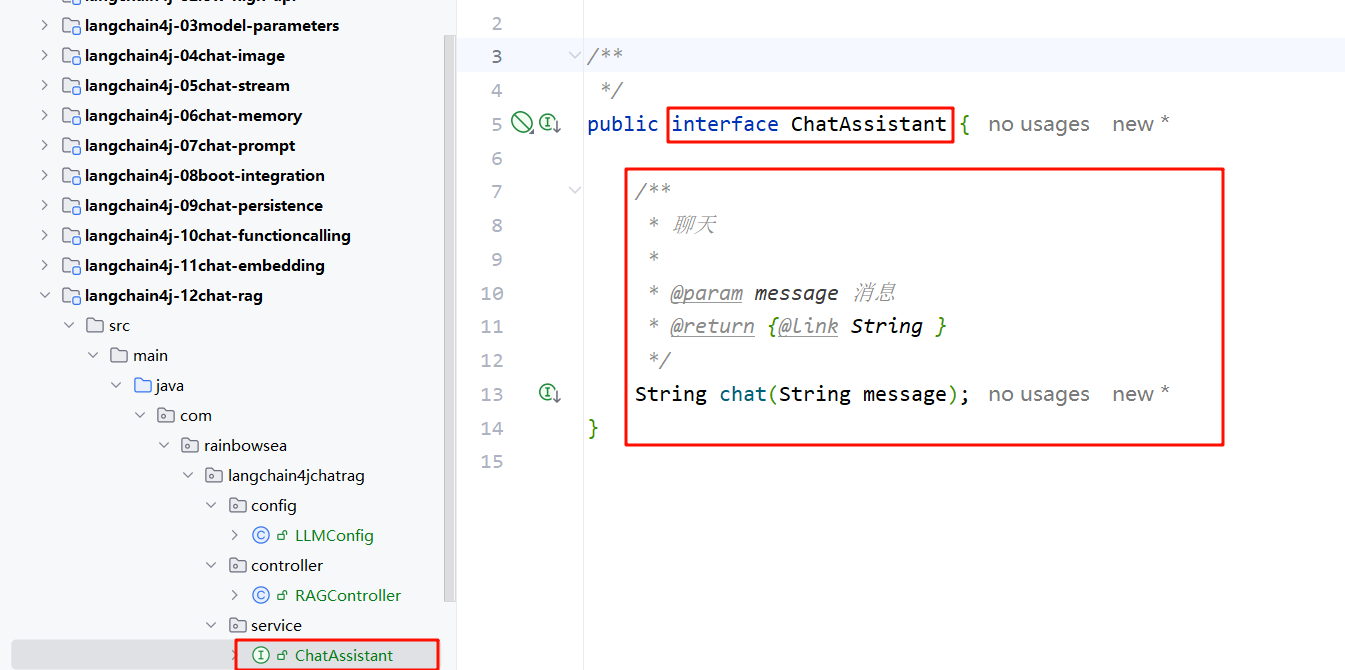
<span style="color:#000000"><span style="background-color:#fefef2"><code class="language-java"><span style="color:#015692">package</span> com.rainbowsea.langchain4jchatrag.service;
<span style="color:#656e77">/**
*/</span>
<span style="color:#015692">public</span> <span style="color:#015692">interface</span> <span style="color:#b75501">ChatAssistant</span> {
<span style="color:#656e77">/**
* 聊天
*
* <span style="color:#015692">@param</span> message 消息
* <span style="color:#015692">@return</span> {<span style="color:#015692">@link</span> String }
*/</span>
String <span style="color:#b75501">chat</span>(String message);
}
</code></span></span>- 编写大模型三件套(大模型 key,大模型 name,大模型 url) 三件套的大模型配置类。同时也需要配置,我们的向量数据库(内存向量数据库),将我们的 RAG(小抄(Alibaba Java 开发手册)) 信息存储到内存向量数据库当中,供大模型读取使用。
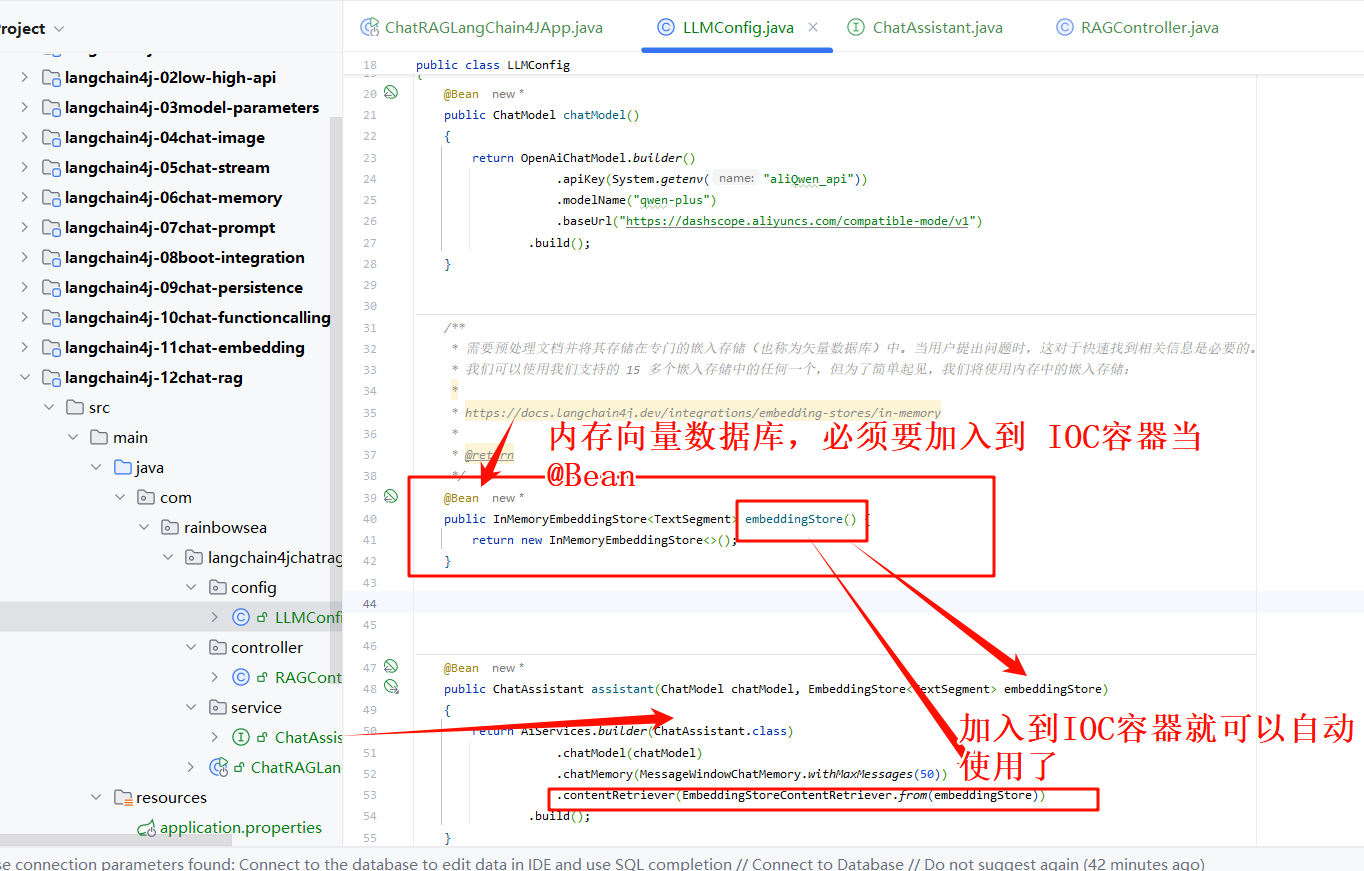
<span style="color:#000000"><span style="background-color:#fefef2"><code class="language-java"><span style="color:#015692">package</span> com.rainbowsea.langchain4jchatrag.config;
<span style="color:#015692">import</span> com.rainbowsea.langchain4jchatrag.service.ChatAssistant;
<span style="color:#015692">import</span> dev.langchain4j.data.segment.TextSegment;
<span style="color:#015692">import</span> dev.langchain4j.memory.chat.MessageWindowChatMemory;
<span style="color:#015692">import</span> dev.langchain4j.model.chat.ChatModel;
<span style="color:#015692">import</span> dev.langchain4j.model.openai.OpenAiChatModel;
<span style="color:#015692">import</span> dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
<span style="color:#015692">import</span> dev.langchain4j.service.AiServices;
<span style="color:#015692">import</span> dev.langchain4j.store.embedding.EmbeddingStore;
<span style="color:#015692">import</span> dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
<span style="color:#015692">import</span> org.springframework.context.annotation.Bean;
<span style="color:#015692">import</span> org.springframework.context.annotation.Configuration;
<span style="color:#656e77">/**
*/</span>
<span style="color:#015692">@Configuration</span>
<span style="color:#015692">public</span> <span style="color:#015692">class</span> <span style="color:#b75501">LLMConfig</span>
{
<span style="color:#015692">@Bean</span>
<span style="color:#015692">public</span> ChatModel <span style="color:#b75501">chatModel</span>()
{
<span style="color:#015692">return</span> OpenAiChatModel.builder()
.apiKey(System.getenv(<span style="color:#54790d">"aliQwen_api"</span>))
.modelName(<span style="color:#54790d">"qwen-plus"</span>)
.baseUrl(<span style="color:#54790d">"https://dashscope.aliyuncs.com/compatible-mode/v1"</span>)
.build();
}
<span style="color:#656e77">/**
* 需要预处理文档并将其存储在专门的嵌入存储(也称为矢量数据库)中。当用户提出问题时,这对于快速找到相关信息是必要的。
* 我们可以使用我们支持的 15 多个嵌入存储中的任何一个,但为了简单起见,我们将使用内存中的嵌入存储:
*
* https://docs.langchain4j.dev/integrations/embedding-stores/in-memory
*
* <span style="color:#015692">@return</span>
*/</span>
<span style="color:#015692">@Bean</span>
<span style="color:#015692">public</span> InMemoryEmbeddingStore<TextSegment> <span style="color:#b75501">embeddingStore</span>() {
<span style="color:#015692">return</span> <span style="color:#015692">new</span> <span style="color:#b75501">InMemoryEmbeddingStore</span><>();
}
<span style="color:#015692">@Bean</span>
<span style="color:#015692">public</span> ChatAssistant <span style="color:#b75501">assistant</span>(ChatModel chatModel, EmbeddingStore<TextSegment> embeddingStore)
{
<span style="color:#015692">return</span> AiServices.builder(ChatAssistant.class)
.chatModel(chatModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(<span style="color:#b75501">50</span>))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
}
}
</code></span></span>- 编写对外访问的 ctroller 层:将我们的将我们的 RAG(小抄(Alibaba Java 开发手册)) 信息存储到内存向量数据库当中,供大模型读取使用。再向大模型提问,大模型就会结合其中 Alibaba Java 开发手册当中的内容回答。
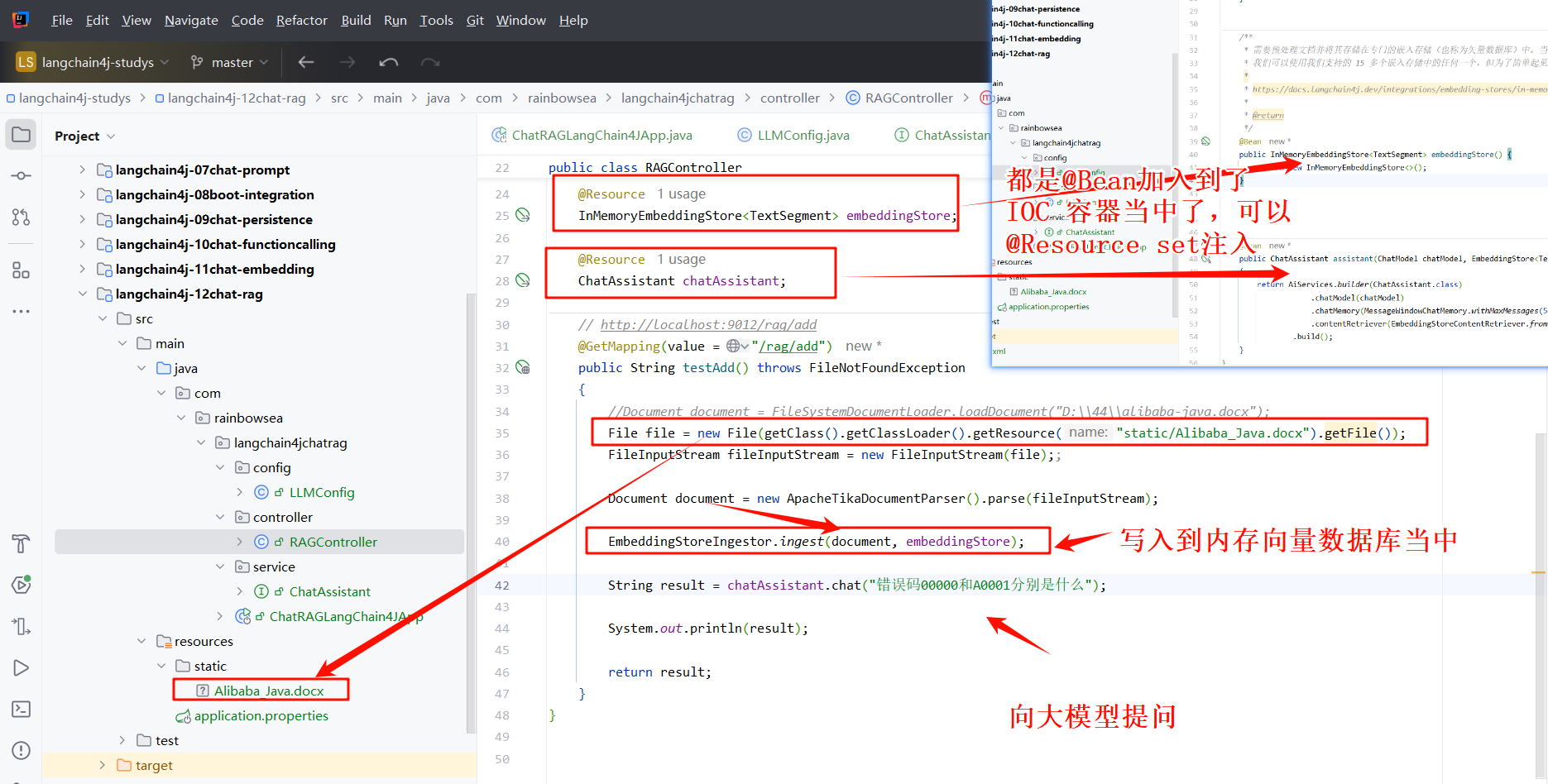
<span style="color:#000000"><span style="background-color:#fefef2"><code class="language-java"><span style="color:#015692">package</span> com.rainbowsea.langchain4jchatrag.controller;
<span style="color:#015692">import</span> com.rainbowsea.langchain4jchatrag.service.ChatAssistant;
<span style="color:#015692">import</span> dev.langchain4j.data.document.Document;
<span style="color:#015692">import</span> dev.langchain4j.data.document.parser.apache.tika.ApacheTikaDocumentParser;
<span style="color:#015692">import</span> dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
<span style="color:#015692">import</span> dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
<span style="color:#015692">import</span> jakarta.annotation.Resource;
<span style="color:#015692">import</span> lombok.extern.slf4j.Slf4j;
<span style="color:#015692">import</span> dev.langchain4j.data.segment.TextSegment;
<span style="color:#015692">import</span> org.springframework.web.bind.annotation.GetMapping;
<span style="color:#015692">import</span> org.springframework.web.bind.annotation.RestController;
<span style="color:#015692">import</span> java.io.File;
<span style="color:#015692">import</span> java.io.FileInputStream;
<span style="color:#015692">import</span> java.io.FileNotFoundException;
<span style="color:#656e77">/**
*/</span>
<span style="color:#015692">@RestController</span>
<span style="color:#015692">@Slf4j</span>
<span style="color:#015692">public</span> <span style="color:#015692">class</span> <span style="color:#b75501">RAGController</span>
{
<span style="color:#015692">@Resource</span>
InMemoryEmbeddingStore<TextSegment> embeddingStore;
<span style="color:#015692">@Resource</span>
ChatAssistant chatAssistant;
<span style="color:#656e77">// http://localhost:9012/rag/add</span>
<span style="color:#015692">@GetMapping(value = "/rag/add")</span>
<span style="color:#015692">public</span> String <span style="color:#b75501">testAdd</span>() <span style="color:#015692">throws</span> FileNotFoundException
{
<span style="color:#656e77">//Document document = FileSystemDocumentLoader.loadDocument("D:\\44\\alibaba-java.docx");</span>
<span style="color:#b75501">File</span> <span style="color:#54790d">file</span> <span style="color:#ab5656">=</span> <span style="color:#015692">new</span> <span style="color:#b75501">File</span>(getClass().getClassLoader().getResource(<span style="color:#54790d">"static/Alibaba_Java.docx"</span>).getFile());
<span style="color:#b75501">FileInputStream</span> <span style="color:#54790d">fileInputStream</span> <span style="color:#ab5656">=</span> <span style="color:#015692">new</span> <span style="color:#b75501">FileInputStream</span>(file);;
<span style="color:#b75501">Document</span> <span style="color:#54790d">document</span> <span style="color:#ab5656">=</span> <span style="color:#015692">new</span> <span style="color:#b75501">ApacheTikaDocumentParser</span>().parse(fileInputStream);
EmbeddingStoreIngestor.ingest(document, embeddingStore);
<span style="color:#b75501">String</span> <span style="color:#54790d">result</span> <span style="color:#ab5656">=</span> chatAssistant.chat(<span style="color:#54790d">"错误码00000和A0001分别是什么"</span>);
System.out.println(result);
<span style="color:#015692">return</span> result;
}</code></span></span>
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)