【辉光大小姐】AI知识图谱:为机器绘制“意义星图” 【完整分析报告】5
知识图谱的本质,是一个【关系实在化引擎 (A Relationship Reification Engine)】。它的唯一使命,是将人类知识中那些隐含的、模糊的、依赖上下文的“关系”,显式地、无歧义地固化(Reify)为机器可计算、可推理的“结构化事实”(如实体-关系-实体三元组)。它以一种近乎偏执的精确性,将人类“理解”这门充满艺术性的认知活动,降维成了机器“连接”这门可以被严格定义的科学。
序章:引言 —— 知识图谱:为机器绘制“意义的星图
在大型语言模型(LLM)掀起的滔天巨浪中,AI似乎已经掌握了言说的艺术。它能以前所未有的流畅与博学,生成人类般的文本,仿佛一个在无垠“概率之海”中遨游的诗人。然而,这片海洋虽广阔,却深不见底,充满了不确定的暗流与名为“幻觉”的海市蜃楼。在这片喧嚣的海洋之下,存在着一个更古老、更宁静、也更坚实的领域——一个由精准的“事实”为岛屿,由明确的“关系”为航道所构成的世界。这个世界的构建者,就是知识图谱(Knowledge Graph),一位沉默的、试图为机器绘制出第一张“意义星图”的宇宙制图师。
知识图谱的魅力,在于它将混乱的世界信息,梳理成一幅清晰、优雅、可循迹的“万物互联之网”。当我们询问“《流浪地球》的导演是谁?”,它不再是在海量文本中进行概率猜测,而是沿着【《流浪地球》】这个实体,通过一条被明确标记为【导演】的关系边,精准地找到【郭帆】这个实体。它看起来如此直观,如此符合人类的认知,仿佛AI终于拥有了“理解”世界的骨架。
然而,当我们拨开这层“优雅结构”的迷人光环,深入其构建的熔炉,我们看到的并非充满智慧的顿悟,而是一场近乎残酷的、将丰富多彩的现实世界进行“降维打击”的工程。这是一场试图用最刚性的、离散的“事实铆钉”,去固定住一个流动的、连续的、充满模糊性的真实世界的战斗。
这场战斗的核心,就是我们本次分析的第一性原理:知识图谱的本质,是一个【关系实在化引擎 (A Relationship Reification Engine)】。它的唯一使命,是将人类知识中那些隐含的、模糊的、依赖上下文的“关系”,显式地、无歧义地固化(Reify)为机器可计算、可推理的“结构化事实”(如实体-关系-实体三元组)。它以一种近乎偏执的精确性,将人类“理解”这门充满艺术性的认知活动,降维成了机器“连接”这门可以被严格定义的科学。
正是这种对“关系”的强制“实在化”,赋予了知识图谱无与伦比的力量。它为AI提供了一个坚实的“事实锚点”,使其能够在概率的海洋中保持航向,从而拥有了真正的可解释性与进行深度逻辑推理的能力。它操作的不是文本的相似性,而是被固化的逻辑本身。但同样,也正是这种“固化”的本质,决定了它与生俱来的“阿喀琉斯之踵”:它的构建成本是天文数字,它的知识边界是僵硬的,它的更新速度永远追不上现实世界的变化。它是一幅在绘制完成的瞬间,就已经开始“过时”的地图。
因此,理解知识图谱,就是理解当前人工智能发展的核心张力:我们渴望AI拥有人类般的常识与理解力,但我们首先必须教会它最基础、最枯燥的“事实”。知识图谱代表了AI发展中“结构主义”的极致,它并非要取代LLM的“连接主义”浪潮,而是要成为其脚下那块不可或缺的、防止其陷入虚无主义的逻辑基石。它是一个伟大的、充满古典主义精神的“事实约束者”,它的历史使命,就是在一个日益由概率驱动的AI世界里,捍卫“确定性”最后的尊严。
步骤一:观察 (Observe) —— 构建三维事实池
【事实池:关于知识图谱 (Knowledge Graph)】
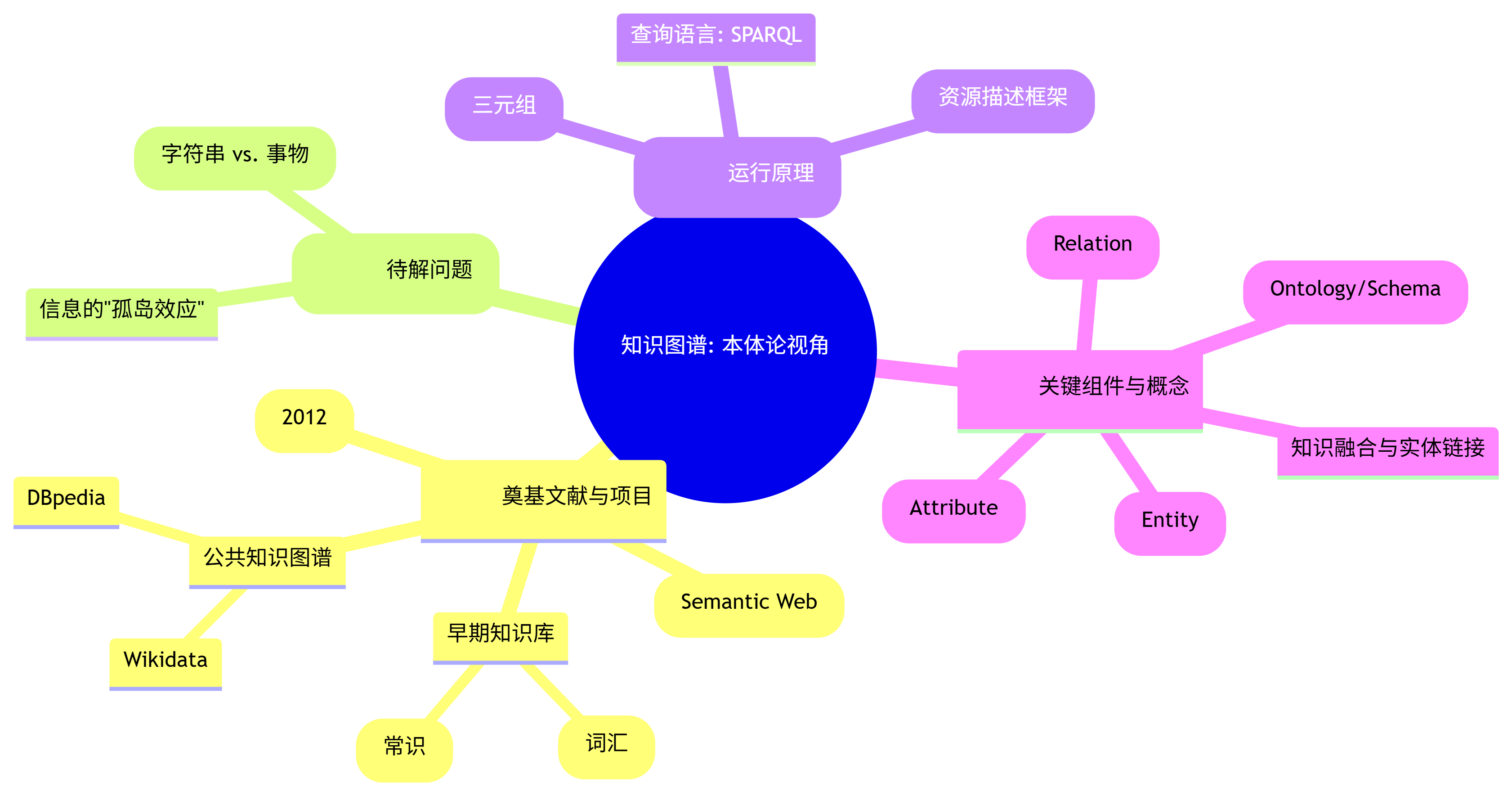
一、 本体论视角 (The Ontological Perspective): 存在与构成
1. 奠基文献/一手资料 (Foundational Sources):
- Google’s 2012 Announcement: 2012年,谷歌在其官方博客中首次正式提出“Knowledge Graph”概念,旨在改进其搜索引擎,实现从“匹配字符串”(Strings)到“理解事物”(Things)的转变。这是“知识图谱”一词进入公众和工业界视野的标志性事件。
- 语义网 (Semantic Web): 知识图谱的思想根源,可以追溯到蒂姆·伯纳斯-李(Tim Berners-Lee)等人提出的“语义网”愿景。其核心思想是利用如RDF、OWL等技术,为万维网上的信息赋予机器可理解的“语义”,使其成为一个巨大的、可查询的全球数据库。
- 早期知识库项目 (Early Knowledge Bases):
- Cyc (1984-至今): 一个旨在编码海量人类常识的宏大项目,是构建大规模形式化知识库的最早和最持久的尝试之一。
- WordNet (1985-至今): 一个大型的英语词汇数据库,它将名词、动词等组织成一个同义词的网络,并描述了它们之间的语义关系。可以看作是“词汇级”知识图谱的雏形。
- 公共知识图谱项目 (Public Knowledge Graphs): DBpedia, Wikidata, YAGO, Freebase (已被Wikidata取代) 等项目,通过从维基百科等结构化数据源中提取信息,构建了覆盖数百万实体和数十亿事实的、可公开访问的大规模知识图谱。
2. 起源背景与待解问题 (Genesis & Problem Space):
- 传统搜索的局限性: 传统的搜索引擎是基于关键词匹配的,它无法真正“理解”用户的查询意图,也无法理解网页内容的含义。例如,搜索“泰坦尼克号的女主角”,它只能返回包含这些关键词的网页,而无法直接给出“凯特·温斯莱特”这个答案。
- 信息的“孤岛效应”: 互联网和企业内部的数据,大多以非结构化(文本、图片)或半结构化(表格)的形式存在,信息之间缺乏明确的关联,形成了一个个“数据孤岛”。
- 知识图谱的诞生目标: 解决上述问题。它旨在将非结构化的信息,转化为结构化的“知识网络,从而:1) 让机器能够“理解”实体(如人物、地点、事件)及其之间的复杂关系;2) 将孤立的数据连接起来,形成一个统一的、可查询的知识体系;3) 直接回答用户的复杂问题,而不仅仅是返回链接列表。
3. 核心机制/运行原理 (Core Mechanism / Operating Principle):
- 根本范式: 实体-关系-实体 (Entity-Relation-Entity) 三元组。这是知识图谱的“原子单位”,也被称为一个“事实”(Fact)。例如,
(Barack Obama, spouse, Michelle Obama)就是一个事实。 - 数据模型:
- RDF (Resource Description Framework): 资源描述框架。是W3C推荐的、用于表示知识图谱三元组的标准数据模型。它将每个实体和关系都赋予一个唯一的标识符(URI),从而消除歧义。
- 查询语言:
- SPARQL (SPARQL Protocol and RDF Query Language): 知识图谱的“SQL”。它是一种专门用于查询RDF格式数据的语言,能够执行复杂的图模式匹配查询。
4. 关键组件与概念 (Key Components & Concepts):
- 实体 (Entity): 现实世界中可以被唯一识别的事物,如人物、城市、公司、概念等。
- 关系 (Relation / Predicate): 描述实体之间特定类型的联系,如“出生于”、“导演”、“属于”等。
- 属性 (Attribute / Property): 描述实体自身的特征,如一个人的“身高”、一个城市的“人口”。本质上也是一种关系,但其指向的是一个“字面量”(Literal Value)而非另一个实体。
- 本体/模式层 (Ontology / Schema): 定义了知识图谱中允许存在的“实体类型”、“关系类型”以及它们之间组合的规则。例如,定义“人”是一种实体类型,“公司”是另一种,并规定“雇佣于”这种关系只能连接一个“人”和一个“公司”。本体为知识图谱提供了逻辑约束和质量保证。
- 知识融合 (Knowledge Fusion): 将来自不同数据源的、描述同一个实体的信息进行合并,并解决可能存在的冲突和冗余的过程。
- 实体链接 (Entity Linking): 将文本中提到的实体(如“苹果”)准确地链接到知识图谱中对应的唯一实体(是“苹果公司”还是“苹果水果”)的过程。
知识图谱:本体论视角
二、 动力学视角 (The Dynamic Perspective): 缺陷与演化
5. 内在局限与结构性缺陷 (Inherent Limitations & Structural Flaws):
- 知识获取瓶颈 (Knowledge Acquisition Bottleneck): 这是知识图谱最根本的、结构性的困境。从海量的、非结构化的文本中准确地抽取出高质量的“实体-关系-实体”三元组,是一个极其困难且成本高昂的过程。
- 模式层的刚性 (Schema Rigidity): 知识图谱依赖于一个预先定义好的本体(Schema)。一旦本体确定,后续的修改和扩展都非常困难,导致图谱难以适应新的知识领域和不断变化的世界。
- 开放世界假设的挑战 (Open World Assumption Challenge): 知识图谱通常采用“开放世界假设”,即“没有在图谱中明确说明为假的事实,都被认为是未知的,而非假的”。这符合现实,但在实际查询中,用户往往期望“封闭世界”的答案(即查不到就是没有),这种不匹配带来了应用上的困难。
- 无法表达复杂/模糊知识: 简单的三元组结构,很难表达带有时间、条件、概率或模糊性的复杂知识。例如,“A可能在2010年到2012年间是B的CEO”这样的不确定信息,很难用标准RDF来表示。
6. 当前表现出的问题与失败模式 (Observed Problems & Failure Modes):
- 知识不完备 (Incompleteness): 任何知识图谱都只是真实世界的一个稀疏采样,必然存在大量的知识缺失。
- 知识不一致 (Inconsistency): 当从多个来源融合知识时,很容易引入相互矛盾的事实(例如,一个来源说某人出生在A地,另一个来源说在B地)。
- 知识过时 (Outdatedness): 世界是动态变化的,但知识图谱的更新往往是批量的、有延迟的,导致其内容无法反映最新的事实。
- 关系定义的任意性: 关系的定义和粒度往往是主观的。例如,“工作于”这个关系,是指“曾经工作于”还是“正在工作于”?这种模糊性会传递到下游应用中。
7. 演化轨迹与替代方案 (Evolutionary Trajectories & Alternatives):
- 自动化构建 (Automated Construction): 利用大型语言模型(LLM)强大的自然语言理解能力,来自动化地从文本中抽取三元组。这是当前最热门的演化方向,旨在从根本上解决“知识获取瓶颈”。
- 知识图谱与LLM的融合 (KG-LLM Integration):
- RAG (Retrieval-Augmented Generation): 在LLM生成答案前,先从知识图谱中检索相关的、准确的事实,作为“上下文”注入到Prompt中,以减少“幻觉”并提高答案的可靠性。
- Graph-RAG: RAG的进阶版,不仅检索实体,还检索其周边的子图结构,为LLM提供更丰富的关系信息。
- 多模态知识图谱 (Multi-modal KG): 将图像、视频等非文本信息也纳入知识图谱的范畴,例如,将图像中的物体识别为实体,并建立它们之间的空间关系。
- 概率知识图谱 (Probabilistic KG): 尝试为图谱中的每一个“事实”都赋予一个置信度评分,从而在形式化的知识表示中引入“不确定性”的概念。
知识图谱:动力学视角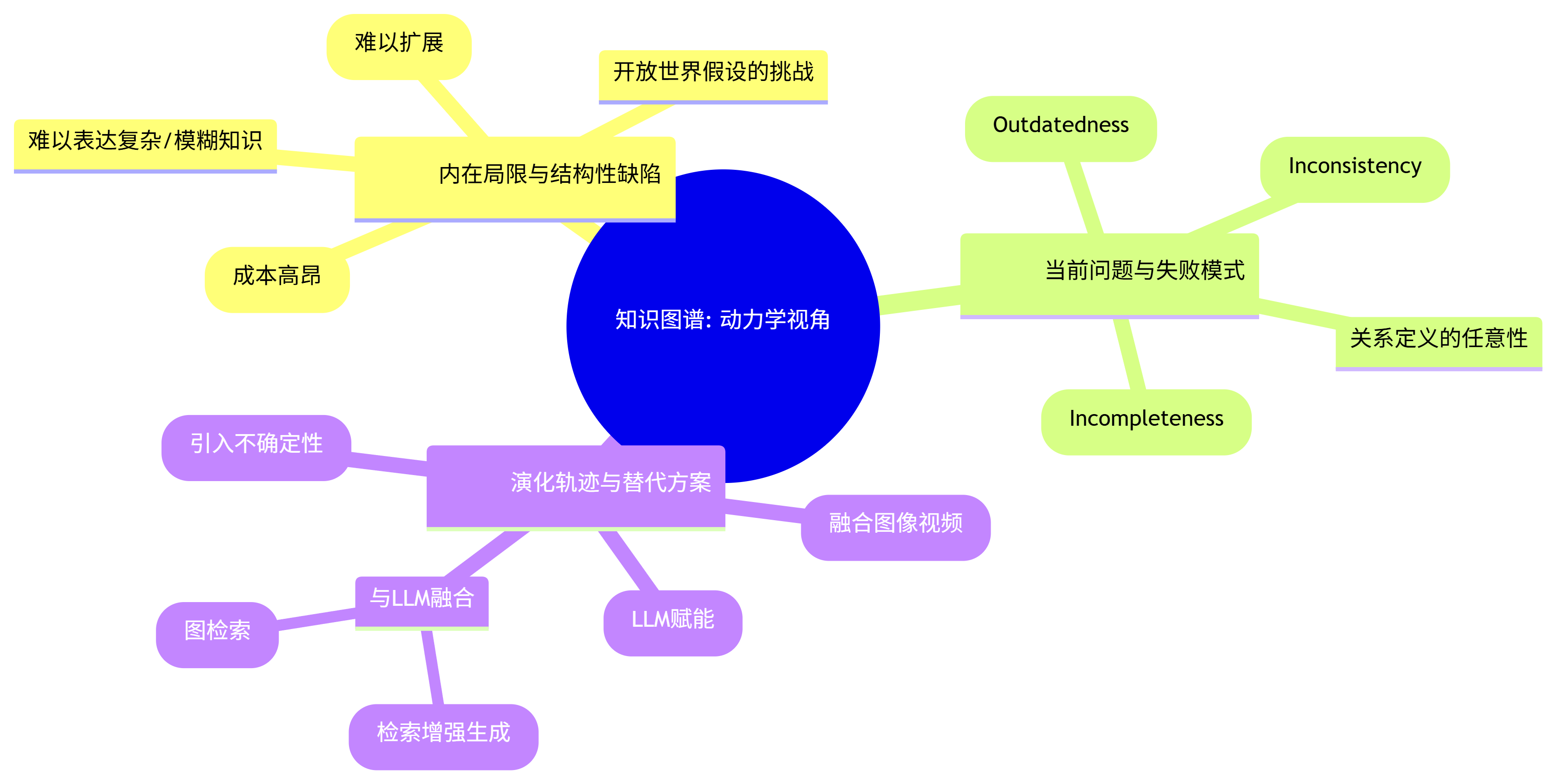
三、 生态论视角 (The Ecological Perspective): 环境与标尺
8. 支配定律与涌现特性 (Governing Laws & Emergent Properties):
- 网络效应定律: 知识图谱的价值与其规模和连接密度成指数关系。一个更大、更稠密的图谱,能够支持更复杂的推理,吸引更多的应用,而这些应用又会反过来贡献更多的数据,形成正向循环。
- 边际成本递增定律: 随着知识图谱对一个领域覆盖得越来越深入,新增每一个“事实”的边际成本(包括发现、抽取、验证和融合的成本)会越来越高,因为剩下的知识越来越冷僻和模糊。
- 推理的涌现性: 当图谱的规模和密度达到某个临界点时,会涌现出意想不到的“知识发现”能力。例如,在药物-基因-疾病的图谱中,可能会发现两条原本认为不相关的药物,因为它们都作用于同一个蛋白质靶点,从而揭示出新的治疗可能性。
9. 生态位与资源动力学 (Ecosystem & Resource Dynamics):
- 核心驱动者:
- 大型科技公司 (Google, Microsoft, Amazon, Meta): 是知识图谱技术最大的推动者和使用者。它们利用知识图谱来赋能其核心业务,如搜索引擎、智能助手、推荐系统和电商平台。
- 企业级应用 (Enterprise Applications): 在金融(反欺诈、风控)、医疗(临床决策支持、药物研发)、工业(智能制造、供应链管理)等领域,知识图谱被用于构建高度专业化的“行业大脑”。
- 生态角色:
- 底层技术提供商 (Neo4j, TigerGraph, Cambridge Semantics): 提供存储和查询知识图谱的图数据库和平台。
- 数据与服务提供商 (Refinitiv, Bloomberg): 提供高质量的、特定领域的知识图谱数据。
- 开源社区 (DBpedia, Wikidata): 贡献和维护大规模的公共知识图谱。
- 资源动力学: 知识图谱的构建和维护是资本和数据密集型的。其发展高度依赖于高质量的数据源、强大的计算资源以及能够处理复杂知识工程的专业人才。
10. 度量体系及其批判 (Measurement Systems & Their Critiques):
- 评估基准:
- 知识图谱补全 (Knowledge Graph Completion): 这是学术界最常用的评估任务。通过遮盖掉一些已知的三元组,让模型去预测缺失的实体或关系,并用Hits@k、MRR等指标来评估其预测的准确性。
- 实体链接与关系抽取评测: 如TAC KBP (Text Analysis Conference Knowledge Base Population) 等评测,关注从文本中抽取知识的准确率和召回率。
- 对度量的批判:
- 与下游任务脱节: 在“补全”任务上表现好的模型,不一定能在实际的问答或推荐应用中带来真正的价值提升。评估指标与最终应用效果之间存在巨大鸿沟。
- 忽略数据质量: 许多评估假设知识图谱本身是“黄金标准”,但现实中的图谱充满了噪声和错误。
- 静态评估的局限性: 大多数基准都是静态的,无法衡量一个知识图谱系统在面对动态变化的世界时的适应性和可维护性。一个知识图谱的真正价值,最终只能通过它所赋能的下游应用的商业或科学价值来衡量。
知识图谱:生态论视角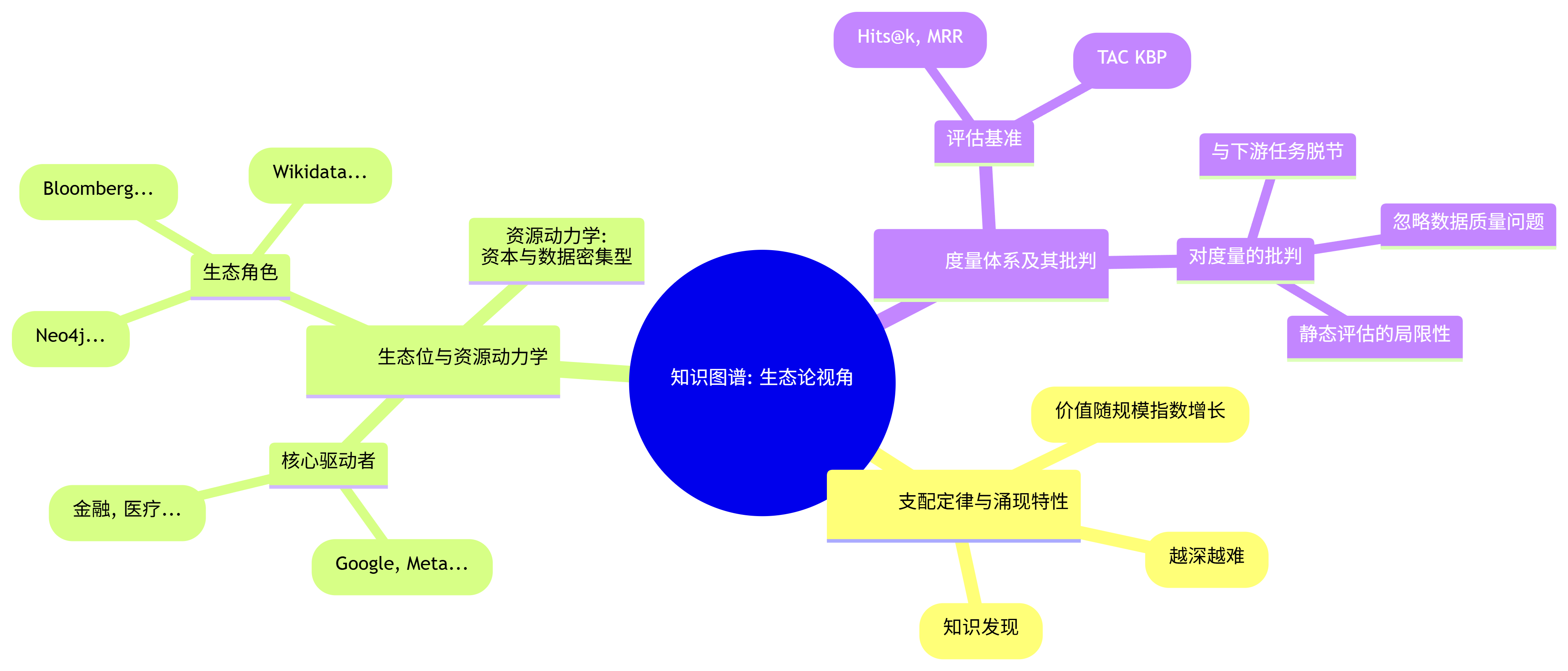
步骤二:解构 (Deconstruct) - 绘制系统关系图
【系统解构图:知识图谱及其生态系统】
1. 系统内核:范式革命 (The Core: A Paradigm Revolution)
- 根本问题: 如何将人类世界中海量的、非结构化的、充满歧义的文本信息,转化为机器能够精确理解、计算和推理的结构化知识,从而在“字符串匹配”的浅层信息检索之上,实现“事物理解”的深层知识服务。
- 解决方案: 提出**关系数据化”(Relationship Datification)**范式。它不关注文本的统计模式,而是致力于识别出文本背后隐藏的、稳定的“事实”单元(实体),并将它们之间的“语义关系”也视为一种可被定义、可被存储的“数据”。
- 内核机制:
- 工作原理: 原子化、结构化、网络化。
- 原子化: 将知识拆解为不可再分的
实体-关系-实体三元组作为“事实原子”。 - 结构化: 为这些“事实原子”定义严格的类型和规则(本体论/Schema),构建出一个逻辑自洽的知识骨架。
- 网络化: 将所有“事实原子”通过共享的“实体”节点连接起来,形成一个巨大的、可全局遍历的语义网络。
- 原子化: 将知识拆解为不可再分的
- 交互本质: 从对计算机的关键词式查询,转变为问题式查询。用户可以直接提问“A和B有什么关系?”,系统通过在网络中寻找路径来直接回答,而非返回包含A和B的文档。
- 工作原理: 原子化、结构化、网络化。
- 内核产物: 一个机器可读的“世界模型”的骨架。它不是对世界的完整复制,而是一个高度抽象、逻辑严谨的“事实索引”,是实现可解释AI和深度推理的基石。
2. 系统表现:双刃剑效应 (The Manifestation: A Double-Edged Sword)
- 正面表现 (涌现的能力):
- 精确性与可解释性: 它的知识是基于被明确定义的“事实”构建的,因此查询结果精确,且推理路径清晰可见、完全可解释。这是对抗LLM“幻觉”最强大的武器。
- 关系推理与知识发现: 图结构使其天然擅长处理复杂的关系查询(如“A的配偶的公司的竞争对手有哪些?”),甚至能通过分析网络结构,发现隐藏的、未被明确声明的关联(如社区发现、链接预测)。
- 数据融合与消除孤岛: 通过将不同来源的数据链接到统一的实体上,知识图谱能够打破数据孤岛,形成一个全局的、统一的知识视图。
- 负面表现 (固有的缺陷):
- 构建的脆弱性与高昂成本 (Construction Brittleness & High Cost): “关系数据化”的过程极度依赖于上游的信息抽取(IE)技术的准确性。任何抽取错误都会被固化为图谱中的“错误事实”,污染整个知识库。这导致其构建过程需要大量的人工校验,成本高昂且周期漫长。
- 表达的局限性 (Expressiveness Limitations):
实体-关系-实体的刚性结构,难以表达不确定性、时序性、因果性以及程序性知识(How-to knowledge)。它擅长回答“是什么”(What),却难以回答“为什么”(Why)和“怎么办”(How)。 - 静态与滞后性 (Static & Lagging Nature): 知识图谱本质上是对过去某一时刻知识的“快照”。它的更新机制远比现实世界的变化要慢,导致其不可避免地存在“知识滞后”。
3. 系统演化:从“手工制图”到“智能测绘”的远征 (The Evolution: From “Manual Cartography” to “Intelligent Surveying”)
- 阶段一:专家系统与手工构建 (Expert Systems & Manual Construction):
- 特征: 知识由领域专家手工定义和录入,规模小、质量高,但成本极高且无法扩展。
- 代表: Cyc项目。
- 阶段二:半自动化抽取与社区协作 (Semi-automated Extraction & Community Collaboration):
- 特征: 开始利用规则和统计模型,从维基百科等半结构化数据源中抽取三元组,并辅以大量社区成员的人工校验。
- 代表: DBpedia, Freebase, Wikidata。
- 阶段三:大模型赋能的全自动化构建与融合 (LLM-Powered Automated Construction & Fusion):
- 特征: 这是当前的前沿。利用LLM强大的文本理解和零样本/少样本能力,直接从海量非结构化文本中抽取、对齐和融合知识,并与现有知识图谱进行动态融合。这是解决“知识获取瓶颈”最有希望的路径。
知识图谱的系统演化路径
4. 系统生态:AI大厦的“钢筋骨架” (The Ecosystem: The “Steel Frame” of the AI Edifice)
- 驱动力:
- 技术驱动: 对“可解释AI”和“鲁棒AI”的追求。在LLM能力越发强大但其“黑盒”和“幻觉”问题也日益凸显的背景下,知识图谱作为一种“确定性”知识源的价值被重新认识和放大。
- 商业驱动: 精准营销、智能风控、药物研发等商业场景,对知识的“精确性”和“关联性”提出了远超传统数据分析的需求。
- 生态角色:
- 基础设施层 (图数据库): Neo4j, TigerGraph等,提供了存储和计算知识图谱的“地基”。
- 平台层 (知识图谱平台): Amazon Neptune, Azure Cosmos DB, Cambridge Semantics Anzo等,提供从构建、管理到应用的全套工具链。
- 数据层 (公共/商业知识图谱): Wikidata, DBpedia提供通用知识;金融、医疗等领域的专业数据公司提供垂直领域知识图谱。
- 应用层 (KG-empowered Applications): 智能问答、推荐系统、搜索引擎、风险控制等,是知识图谱价值最终变现的出口。
- 核心矛盾: 整个生态的核心矛盾在于构建成本”与“应用价值”之间的赛跑。只有当应用带来的价值能够覆盖高昂的构建和维护成本时,一个知识图谱项目才能持续生存。LLM的出现,正在极大地降低“构建成本”这一端,从而有望引爆整个生态。
5. 系统标尺:从“三元组数量”到“下游任务性能”的价值回归 (The Measurement: The Value Return from “Triple Count” to “Downstream Task Performance”)
- 传统标尺 (规模导向): 早期评价一个知识图谱,主要看其规模:拥有多少实体、多少三元组。这是一种“军备竞赛”式的、相对粗放的度量。
- 标尺的失效: 一个庞大但充满噪声和冗余的知识图谱,其价值可能远低于一个规模虽小但干净、精准、且与特定业务场景紧密结合的图谱。
- 新兴标尺 (价值导向):
- 评估核心转变: 从评估“图谱本身有多好”转向评估“图谱为下游应用带来了多大提升”。
- 具体指标: 例如,引入知识图谱后,智能问答的准确率提升了多少?推荐系统的点击率提升了多少?风控模型的误报率降低了多少?
- 价值: 这种转变,迫使知识图谱的构建者从“数据工程师”的角色,转向“业务解决方案架构师”的角色,使其技术发展与最终的商业价值紧密对齐。
步骤三 : 提炼 (Hypothesize) - 发现知识图谱的“第一性原理
从现象到本质的沙漏型提炼流程
行动: 我们回到关于知识图谱的“系统解构图”。图中充满了各种看似矛盾的特性:它既精确又脆弱,既强大又受限,既是古典技术的代表又在LLM时代焕发新生。现在,我们要穿透这些表象,找到驱动这一切的、唯一的根本法则。
-
第一次追问: 知识图谱的本质是一个“更聪明的数据库”或“图数据库”吗?不,这只是对其技术实现和存储形态的描述。一个存储了用户社交网络的图数据库,我们通常不称之为知识图谱。数据库关心的是“如何高效地存储和查询数据”,而知识图谱关心的是“这些数据代表了世界上的何种知识”。形态是“术”,而目的是“道”。
-
第二次追问: 那么,它的本质是“结构化知识”吗?这更近了一步,但仍不精确。传统的SQL数据库里存储的也是高度结构化的知识。但知识图谱与传统数据库的根本区别在于,它不仅结构化了“实体”(如一个“员工”表),它更将关系(如“工作于”、“汇报给”)提升到了与“实体”同等重要的地位,并允许这些关系自由地、跨越不同类型实体进行连接,形成一张“网”,而非孤立的“表”。
-
第三次追问: 让我们聚焦于这个核心差异——对关系的处理。在一段文本“乔布斯创立了苹果公司”中,“乔布斯”和“苹果公司”是实体,这很容易理解。但“创立了”这个词,在文本中只是一个普通的动词。知识图谱所做的革命性工作,就是将这个稍纵即逝的、依赖上下文的语言学概念(“创立了”),强行地、永久地转化为一个被精确定义的、机器可读的数据实体(一个ID为
P17、标签为founder的关系)。它把一个“动词”变成了一个“名词”,一个可以被查询、被计数的“东西”。 -
洞察闪现: 知识图谱的全部魔法,都源于这个看似简单却极其深刻的转化过程。它不是在“发现”知识,而是在“铸造”知识。它将人类认知中那些流动的、隐含的、附着于实体之上的“关系”,通过一个工程化的过程,强行地从背景中“抓取”出来,赋予其一个独立的、明确的、无歧义的身份。这个过程,在哲学和语言学上被称为实在化”(Reification——将一个抽象概念,转变为一个具体的“事物”。知识图谱,就是一台批量化、规模化进行“关系实在化”的引擎。它将“理解世界”这个宏大的、模糊的哲学目标,降维成了一个可操作的、具体的工程任务:“将世界万物之间的关系,转化为一个可计算的图”。
核心假说(第一性原理)被提炼出来:
知识图apropos的本质,并非一个“知识的数据库”,而是一个【关系实在化引擎 (A Relationship Reification Engine)】。它的唯一使命,是通过一个系统化的工程过程,将人类知识中那些隐含的、模糊的、依赖上下文的“关系”,显式地、无歧义地固化(Reify)为机器可计算、可推理的“结构化事实”(如实体-关系-实体三元组),从而将人类“理解”的艺术,降维为机器“连接”的科学。
它最大的成功,在于建立了一套将“非结构化断言”(如一句话)转化为“结构化资产”(如图中的一条边)的标准化流程。它最大的挑战,也源于此:这个“实在化”的过程,本质上是对丰富现实世界的“有损压缩”,必然会丢失大量原始的上下文、模糊性和不确定性。
1. 它完美解释了系统的“双刃剑效应”:
- 精确性与可解释性: 因为每一个“关系”都经过了“实在化”过程,被赋予了一个唯一的、明确的身份,所以基于这些固化关系的推理,其路径是清晰、可追溯的。它操作的不是概率,而是被“铸造”出的离散事实。
- 构建脆弱性与表达局限性: “实在化”的过程是脆弱的,一旦对一个关系的定义出现偏差(例如,如何区分“拥有”和“控股”),这个错误就会被固化并扩散到整个网络中。同时,并非所有类型的关系(如因果、意图、可能性)都能被轻易地“实在化”为一条简单的边,这直接导致了其表达能力的先天不足。
2. 它完美解释了系统的“演化路径”:
- 从手工到自动: 知识图谱的整个演化史,就是一部“关系实在化”引擎的效率提升史。早期需要专家(人类大脑)来完成这个“实在化”的定义和抽取过程。现在,我们则希望利用LLM这个强大的“通用模式识别器”,来自动化地完成这个过程,从而从根本上降低“铸造”每一个新事实的成本。
3. 它完美解释了它在LLM时代的“生态位”:
- LLM的“事实之锚”: LLM是一个处理“语言符号”的概率引擎,它本身并不理解这些符号背后的“实在”世界。而知识图谱,恰恰提供了一个由“实在化”关系构成的“事实骨架”。当LLM需要谈论世界时,知识图谱可以为它提供一个不会动摇的“事实锚点”,防止它在概率的海洋中彻底“漂走”(产生幻觉)。知识图谱为LLM的“符号游戏”提供了与“现实世界”的连接。
最终核心法则提炼
第一性原理: 知识图谱的本质是一个关系实在化引擎模型。
这个引擎之所以能运转,依赖于以下三条不可动摇的核心法则,它们共同构成了它的“建造规范”。
核心法则一:【知识原子化法则 (The Law of Knowledge Atomization)】
- 定义: 为了实现计算,知识必须被拆分为不可再分的、标准化的“事实原子”,即
实体-关系-实体三元组。任何比这更复杂或更模糊的知识单元,都必须先经过“降维”和“简化”,才能被纳入图谱。 - 阐述: 这是“关系实在化”的基本前提。它规定了知识进入这个系统的“最小单位”。这既是知识图谱能够进行精确计算的基础,也是其表达能力受限的根源。它迫使我们用一种“乐高积木”式的离散思维,去近似一个连续、复杂的现实世界。
核心法则二:【关系显式化法则 (The Law of Relation Explicitness)】
- 定义: 在图谱中,任何实体之间的关系,都必须被一个预先定义的、具有明确语义的“关系类型所显式地标记。不允许存在未定义或模糊的隐式关系。
- 阐述: 这是“关系实在化”的核心操作。它将语言中成千上万种描述关系的方式,收敛到了一套有限的、受控的“关系词汇表”(即本体论中的关系定义)中。这个过程赋予了机器“理解”关系的能力,但代价是牺牲了自然语言中丰富的细微差别和上下文依赖性。
核心法则三:【结构约束化法则 (The Law of Structural Constraint)】
- 定义: 知识图谱中的所有实体和关系,都必须遵循一个**预先定义的“模式层”(Schema/Ontology)**的约束。这个模式层规定了哪些类型的实体可以与哪些类型的实体,通过何种类型的关系进行连接。
- 阐述: 这是“关系实在化”的质量保证。它为知识图谱这张大网提供了“语法规则”,防止出现逻辑上不通的“病句”(如
(巴黎,导演,郭帆))。这个法则保证了图谱的逻辑一致性和查询效率,但同时也使其变得“僵硬”,难以适应和表达模式之外的新知识。
步骤四 & 五: 重组与测试 (Recombine & Test) - 构建并压力测试“知识铸造厂”诊断模型
行动: 我们将以“关系实在化引擎”为第一性原理,以其三大核心法则为支柱,重组出一个统一的诊断模型。我们称之为知识铸造厂”(The Knowledge Foundry)模型。
知识铸造厂”诊断模型:构建与测试流程
引入分析性隐喻:“知识的工业革命
为了更形象地理解,我们可以引入一个隐喻:知识图谱的诞生,标志着知识处理领域的一场“工业革命。
- 革命前(文本时代): 知识以“手工艺品”(自然语言文本)的形式存在。每一份知识都形态各异、充满细节和艺术感,但难以规模化复制、检索和组装。
- 革命后(知识图谱时代): 我们建立了一座知识铸造厂。这座工厂的目标,是将那些形态不一的“手工艺品”熔化,提取出标准化的“知识金属”(实体和关系),然后用统一的“模具”(本体论)将其铸造成标准化的“知识零件”(三元组),最终组装成宏伟的“知识机器”(知识图谱)。
模型核心:
知识图谱,其本质并非一个静态的“图书馆”,而是一个动态的、遵循严格工业化流程的知识铸造厂。这个铸造厂的生产逻辑,完全遵循其三大核心法则:
- 原料提纯 (基于“知识原子化法则”): 工厂的第一步,是将输入的、混杂的“矿石”(非结构化数据)进行粉碎和提纯,从中筛选出有价值的“金属元素”,即最基础的“实体”、“关系”和“属性”。任何无法被还原为这些基本元素的复杂信息,都将被视为“杂质”丢弃。
- 模具铸造 (基于“关系显式化法则”): 提纯出的“知识金属”被送入铸造车间。在这里,工厂使用一套有限的、预先设计好的“模具”(关系类型定义),将熔化的金属“浇筑”成标准形态的零件。一个特定的“关系”(如
founder),就是一个特定的“模具”。 - 结构质检 (基于“结构约束化法则”): 铸造完成的“知识零件”在出厂前,必须经过严格的“质量检验”(Schema约束)。质检员会检查每个零件是否符合“蓝图”规范,例如,一个标记为“创始人”的零件,其连接的两端必须一个是“人”,一个是“组织”。只有通过质检的零件,才能被最终组装进宏大的“知识机器”中。
这个模型揭示了一个根本性的事实:我们通过知识图谱所实现的“精确性”和“可解释性”,并非源自机器的“智慧”,而是源自一个被我们精心设计的、对知识进行“有损标准化”的“工业化生产流程”。 它牺牲了知识的丰富性和灵活性,换取了机器处理的规模、效率和确定性。
行动: 现在,我们将用三个最具颠覆性的变量,来对“知识铸造厂”模型进行压力测试。
测试变量一:【大型语言模型 (LLM) 的冲击】
- 场景: LLM的出现,以其强大的自然语言理解和生成能力,似乎提供了一种绕过知识图谱,直接从文本中“理解”和回答问题的路径。
- 模型预测:
- 对“原料提纯”车间的革命: “知识铸造厂”模型预测,LLM不会摧毁铸造厂,而是会彻底革新其最昂贵、最低效的“原料提纯”车间。LLM是迄今为止最强大的自动化“矿石分拣机”和“熔炼炉”。它能够以前所未有的效率和精度,从海量非结构化文本中,自动完成“知识原子化”(法则一)的步骤,即实体和关系的抽取。
- 铸造”和“质检”环节不可或缺: 然而,模型同时指出,LLM本身无法取代“模具铸造”(法则二)和“结构质检”(法则三)的环节。LLM抽出的知识本质上仍是“概率性”的,可能存在事实错误(幻觉)和逻辑不一致。因此,依然需要一个明确的“模具”(本体)来对其进行“塑形”,需要一套严格的“质检标准”(Schema)来保证最终产品的质量。
- 测试结论: 模型有效,并精准定位了LLM与知识图谱的共生关系。它指出,LLM不是知识图谱的替代品,而是其“工业化”进程中最关键的“加速器。LLM负责大规模、低成本地“生产原料”,而知识图谱负责将这些“原料”铸造成高精度、高可靠性的“结构化知识零件”。二者的结合,即KG-RAG,正是“原料生产线”与“铸造生产线”的完美对接。
测试变量二:【常识知识 (Commonsense Knowledge) 的表达与获取】
- 场景: AI领域的圣杯之一,是让机器掌握人类的常识(例如,“水是湿的”,“人不能举起大象”)。知识图谱能否成为承载常识的理想容器?
- 模型预测:
- 对“模具铸造”环节的根本挑战: “知识铸造厂”模型预测,知识图谱在处理常识时会遭遇根本性困难。因为常识知识的最大特点是其关系的模糊性、多样性和隐蔽性。我们很难为常识设计出一套有限的、无歧义的“标准模具”(关系类型)。例如,“鸟会飞”这个常识,应该用什么关系来“铸造”?是
can_fly还是has_ability_to_fly?鸵鸟呢?企鹅呢?这种关系的定义几乎是无穷无尽的。 - 原料”的缺失: 常识很少在书面文本中被明确陈述(因为人人都知道),导致用于“提纯”的“矿石”极其稀少。
- 对“模具铸造”环节的根本挑战: “知识铸造厂”模型预测,知识图谱在处理常识时会遭遇根本性困难。因为常识知识的最大特点是其关系的模糊性、多样性和隐蔽性。我们很难为常识设计出一套有限的、无歧义的“标准模具”(关系类型)。例如,“鸟会飞”这个常识,应该用什么关系来“铸造”?是
- 测试结论: 模型有效,并揭示了为什么像Cyc这样的常识知识图谱项目举步维艰。它指出,知识铸造厂”模型本质上是为“事实性知识”(Factual Knowledge)设计的,而对“常识性知识”存在“水土不服。常识的获取和表达,可能更适合LLM那种基于海量数据统计关联的“隐式”学习模式,而非知识图谱的“显式”定义模式。知识图apropos可以存储常识的“结论”,但难以“铸造”出常识背后的复杂推理过程。
测试变量三:【多模态数据(图像、视频)的融合】
- 场景: 未来的知识库必须能够理解和融合图像、视频等多模态信息。如何构建一个“多模态知识图谱”?
- 模型预测:
- 原料”和“零件”的扩展: “知识铸造厂”模型能够很好地兼容这个扩展。它预测,多模态知识图谱的构建,首先需要扩展“原料提纯”车间的能力,使其能够从图像中“提纯”出视觉实体(如识别出的物体、人脸)。同时,也需要增加新的“零件”类型,例如,除了文本实体,还有“图像区域”、“视频片段”等。
- 真正的瓶颈在于“跨模态模具”的设计: 模型进一步精准地预测,多模态知识图谱最大的挑战,不在于识别出图像中的实体,而在于如何设计和定义用于连接不同模态实体的“关系模具。例如,如何定义一张图片中“一个人【穿着】一件衣服”的关系?如何定义一段视频中“一辆车【正在驶过】一座桥”这种时空关系?这些“跨模态关系”的“实在化”(法则二),是比纯文本关系复杂得多的挑战。
- 测试结论: 模型有效,并为多模态知识图谱的发展指出了核心瓶颈和研究方向。它指出,多模态知识图谱的成功,关键不在于更强的“物体检测器”,而在于能否建立一套丰富的、标准化的“跨模态关系本体论。这需要我们重新思考“关系”的定义,将其从语言学范畴,扩展到空间、时间、物理交互等更广阔的维度。
步骤六: 迭代 (Iterate) - 对目标的未来进行推演
核心任务: 基于已验证的“知识铸造厂”诊断模型及其三大核心法则,对“知识图谱”的未来演化进行逻辑推演。
【迭代推演:知识图谱的“消融”,与结构化认知层的诞生】
我们的诊断模型已经明确指出:知识图谱的本质,是一个遵循“提纯-铸造-质检”工业化流程的知识铸造厂。它的演化,必然是围绕着如何让这个“工厂”的生产更自动化、产品更灵活、以及与外部世界(尤其是LLM)的集成更无缝这三个方向展开的。
知识图谱的未来演化轨迹
迭代轨迹一:“模具”的智能化 —— 从“刚性定义”到“柔性表示” (The Smartification of the “Molds”)
- 驱动力: 对关系显式化法则(法则二)的“刚性”与“贫乏”进行反思。当前的“关系模具”是离散的、人工定义的,无法捕捉关系之间细微的语义差别(例如,“爱”、“喜欢”、“崇拜”之间的差别)。
- 推演: “知识铸造厂”的下一次升级,将是对其核心资产——“模具库”的彻底改造。我们将不再满足于用一个僵硬的标签来定义关系,而是寻求一种更丰富、更具弹性的表示方法。
- 【猜测内容:】 未来的知识图谱将普遍采用神经-符号混合本体”(Neuro-Symbolic Ontology)。
- 在这种架构中,每一个“关系类型”(如
founder)不再仅仅是一个符号标签,它同时还会被关联一个高维度的向量嵌入(Vector Embedding),这个向量由一个预训练的语言模型生成,捕捉了该关系丰富的、上下文相关的语义。 - 优势: 这种“智能模具”兼具了符号系统的精确性(我们依然保留
founder这个标签)和神经网络的模糊推理能力(我们可以通过计算向量距离,来判断creator或originator在语义上与founder有多接近)。这将允许知识图谱进行更灵活的、基于语义相似度的查询和推理,极大地缓解了其“表达能力有限”的核心缺陷。
知识图谱的“关系”,将从一个“静态的标签”,演变为一个“动态的、可计算的语义对象”。
- 在这种架构中,每一个“关系类型”(如
迭代轨迹二:“质检”的动态化 —— 从“静态快照”到“实时对账” (The Dynamization of the “Quality Control”)
- 驱动力: 对结构约束化法则(法则三)导致的“知识滞后”进行反思。当前的“质检”是一个静态的、基于预设规则的过程,无法应对一个动态变化的世界。
- 推演: 一个先进的“知识铸造厂”,其“质检”流程不能只在“零件”入库时进行一次,而应该是一个持续的、贯穿整个生命周期的过程。它需要不断地将库存中的“零件”与外部世界的变化进行“对账”。
- 【猜测内容:】 **自愈合知识图谱”(Self-Healing Knowledge Graphs)**将成为主流。
- 这种知识图谱会集成一个事实监控与验证”模块。该模块会持续地监控外部信息源(如新闻流、API更新、网页变化),并自动生成验证任务。
- 例如,当监控到某公司发布财报,它会自动触发一个任务,去验证图谱中关于该公司“CEO”和“营收”的“事实零件”是否依然有效。如果发现冲突,系统会自动标记该事实为“过时”,降低其置信度,甚至在某些情况下自动进行修正。
- 这本质上是为知识图谱增加了一个新陈代谢系统,使其能够主动地“遗忘”和“修正”错误,从而在一定程度上解决“知识过时”这个根本性难题。
知识图谱将从一个“只进不出”的“档案馆”,演变为一个能够与现实世界同步呼吸的“活体知识库”。
迭代轨迹三:“工厂”的“消融” —— 从“外部数据库”到“内化认知层” (The “Dissolution” of the “Foundry”)
- 驱动力: 对知识原子化法则(法则一)导致的知识图谱与LLM“两张皮”问题的终极反思。目前,知识图谱是一个外部的、显式的数据库,LLM需要通过一个额外的“检索”动作(RAG)才能访问它。这是低效的,也是不自然的。
- 推演: 这是最根本、最颠覆性的迭代。知识的终极形态,不应该是“大脑”旁边的一个“笔记本”,而应该是“大脑”本身的一部分。因此,“知识铸造厂”的终局,不是建得更大、更高效,而是将其自身“溶解”,并将其“生产规范”内化到下一代AI模型的设计之中。
- 【猜测内容:】 “知识图谱”作为一个独立的技术形态将会逐渐淡出主流视野,取而代之的是在下一代大型语言模型的架构中,出现一个原生的、内置的“结构化认知层”(Structured Cognition Layer)。
- 这个“认知层”将不再以三元组的形式存储知识,而是通过特定的神经元结构或权重矩阵,在LLM的神经网络内部,隐式地、但又是有结构地编码“实体”与“关系”的知识。
- 你可以想象,在LLM的“概念空间”中,代表“乔布斯”和“苹果公司”的神经元集群,会被一组特殊的、被训练用来专门处理“创始人关系”的权重结构强力地连接起来。
- 这种内化的知识,既可以像知识图谱一样被精确地查询和推理(通过激活特定的神经回路),又可以与LLM的其他部分进行无缝的、端到端的交互,彻底消除“检索”这一外部步骤。
这标志着AI从“检索外部知识”进入了“拥有内在知识”的时代。知识图谱不再是“我们喂给AI的东西”,而是“AI思考方式的一部分”。
结论性摘要 (Conclusion)
“知识图谱”的诞生,源于我们对机器智能最古典、最执着的追求:我们不仅希望机器能“言说”,更希望它能“理解”,而理解的基石,是关于世界万物及其关系的、确定性的知识。它代表了一种“结构主义”的理想——通过建立一个精确、优雅、逻辑自洽的“事实之网”,来驯服一个混乱、模糊的信息世界。
我们提出的关系实在化引擎模型,及其知识铸造厂的隐喻,揭示了这一理想的本质、力量与代价。它是一场将知识“工业化”的伟大尝试,通过牺牲丰富性来换取精确性,通过固化来对抗模糊,通过结构来约束概率。
然而,我们对其未来的迭代推演得出了一个看似矛盾、实则必然的结论:知识图谱”的演化终局,是其自身形态的“消融”。
它将不再是一个我们需要刻意去构建和查询的、庞大的外部数据库。它最核心的价值——对“关系”的显式建模,对“结构”的严格约束——将被下一代AI架构所吸收,成为其内在认知能力的一部分。它将从一个外挂的“事实核查器”,演变为AI模型内部一个原生的“逻辑推理模块”。
知识图谱的历史使命,并非是为AI建造一座永恒的“知识大教堂”,而是将“结构化思考”的基因,注入到以“概率化联想”为主流的神经网络之中。 它正在完成从“术”到“道”的升华。当未来的AI能够像我们一样,在流畅的对话中,自然而然地、不出错地引用事实、进行逻辑推理时,我们将知道,知识图谱已经化为无形,因为它已无处不在。
附实验室前4篇:
# # AI智能体(AI Agent)——从“缸中之脑”到“尘世之手”
附录:关键文献引用 (Key Paper References)
本报告的分析与论点,建立在对以下塑造了“知识图谱”领域的核心文献与概念的理解之上。
一、 核心奠基概念与文献
-
Google’s Knowledge Graph Announcement (2012):
- 来源: 谷歌官方博客文章 “Introducing the Knowledge Graph: things, not strings”
- 核心贡献: 首次将“知识图谱”这一概念大规模引入工业界和公众视野,定义了其核心目标——从理解“字符串”到理解“事物”。
-
Semantic Web & RDF (Resource Description Framework):
- 代表人物: Tim Berners-Lee
- 核心贡献: 知识图谱的理论前身。提出了为万维网信息添加机器可读语义的宏大愿景,并奠定了RDF(
主-谓-宾三元组)作为知识表示的基础数据模型。
-
DBpedia & Wikidata:
- 核心贡献: 作为最大、最成功的公共知识图谱项目,它们证明了从维基百科等众包数据源中,半自动化地构建大规模、通用领域知识图谱的可行性,并为学术界和工业界提供了宝贵的研究与应用资源。
二、 关键演化与技术文献
-
Knowledge Graph Embedding (KGE):
- 代表模型: TransE (Bordes et al., 2013), RotatE (Sun et al., 2019)
- 核心贡献: 开创了将知识图谱中的实体和关系表示为低维向量嵌入的方法。这使得知识图谱能够被用于机器学习任务,特别是“知识图谱补全”(链接预测),极大地推动了知识图谱的自动化构建与推理研究。
-
Graph Neural Networks (GNNs) for Knowledge Graphs:
- 代表模型: R-GCN (Schlichtkrull et al., 2018)
- 核心贡献: 将强大的图神经网络应用于知识图谱,通过聚合邻居节点的信息来学习实体和关系的表示。相比KGE,GNN能够更好地利用图的局部结构信息,在多个任务上取得了更优的效果。
-
Retrieval-Augmented Generation (RAG) for LLMs:
- 代表论文: “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” (Lewis et al., 2020)
- 核心贡献: 提出了在LLM生成文本前,先从外部知识库(如知识图谱)中检索相关信息的范式。这篇论文虽然不专为知识图谱设计,但它开创了LLM与外部知识库(尤其是知识图谱)系统性结合的主流模式,是当前“知识图谱赋能LLM”方向的基石。
三、 前沿探索与未来方向
-
Automated Knowledge Graph Construction with LLMs:
- 研究方向: 大量涌现的利用GPT-4等模型进行实体-关系抽取(ERE)、实体链接(EL)和知识图谱对齐的研究。
- 核心贡献: 探索如何利用LLM强大的零样本/少样本能力,从根本上解决知识图谱的“知识获取瓶颈”,是当前最活跃、最具潜力的研究领域。
-
Commonsense Knowledge Graphs:
- 代表项目: ATOMIC (Sap et al., 2019), ConceptNet
- 核心贡献: 专注于构建蕴含人类常识(特别是因果、意图等程序性知识)的知识图谱。虽然面临巨大挑战,但这些项目是对“知识图谱能否表达事实之外的常识”这一根本问题的持续探索。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 28
28 0
0- 0



 已为社区贡献123条内容
已为社区贡献123条内容

所有评论(0)